https://github.com/sooftware/transformer
A PyTorch Implementation of "Attention Is All You Need"
https://github.com/sooftware/transformer
attention attention-is-all-you-need nlp seq2seq transformer
Last synced: 10 months ago
JSON representation
A PyTorch Implementation of "Attention Is All You Need"
- Host: GitHub
- URL: https://github.com/sooftware/transformer
- Owner: sooftware
- License: apache-2.0
- Created: 2020-07-04T11:44:01.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2021-10-03T08:30:53.000Z (almost 5 years ago)
- Last Synced: 2025-04-09T23:51:36.752Z (over 1 year ago)
- Topics: attention, attention-is-all-you-need, nlp, seq2seq, transformer
- Language: Python
- Homepage:
- Size: 6.27 MB
- Stars: 38
- Watchers: 2
- Forks: 9
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# transformer
A PyTorch Implementation of Transformer in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
This repository focused on implementing the contents of the paper as much as possible.
## Intro
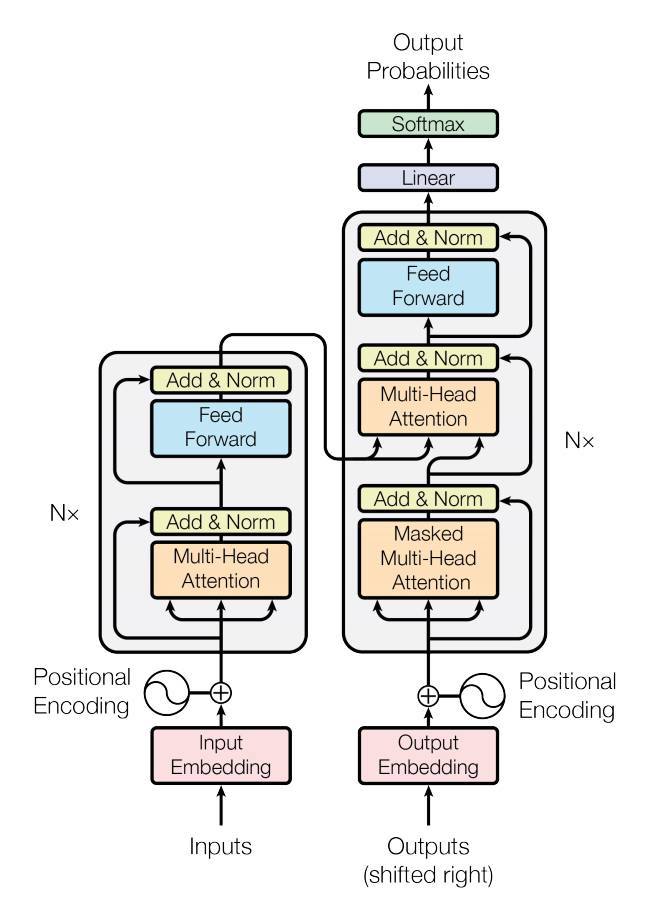
This repository focused on implementing the contents of the paper as much as possible,
while at the same time striving for a readable code. To improve readability,
I designed the model structure to fit as much as possible to the blocks in the above Transformers figure.
## Installation
This project recommends Python 3.7 or higher.
We recommend creating a new virtual environment for this project (using virtual env or conda).
### Prerequisites
* Numpy: `pip install numpy` (Refer [here](https://github.com/numpy/numpy) for problem installing Numpy).
* Pytorch: Refer to [PyTorch website](http://pytorch.org/) to install the version w.r.t. your environment.
### Install from source
Currently we only support installation from source code using setuptools. Checkout the source code and run the
following commands:
```
pip install -e .
```
## Usage
```python
import torch
import torch.nn as nn
from transformer import Transformer
BATCH_SIZE, SEQ_LENGTH, D_MODEL = 3, 10, 64
cuda = torch.cuda.is_available()
device = torch.device('cuda' if cuda else 'cpu')
inputs = torch.zeros(BATCH_SIZE, SEQ_LENGTH).long().to(device)
input_lengths = torch.LongTensor([12345, 12300, 12000])
targets = torch.LongTensor([[1, 3, 3, 3, 3, 3, 4, 5, 6, 2],
[1, 3, 3, 3, 3, 3, 4, 5, 2, 0],
[1, 3, 3, 3, 3, 3, 4, 2, 0, 0]]).to(device)
target_lengths = torch.LongTensor([9, 8, 7])
model = nn.DataParallel(Transformer(num_input_embeddings=30, num_output_embeddings=50,
d_model=64,
num_encoder_layers=3, num_decoder_layers=3)).to(device)
# Forward propagate
outputs = model(inputs, input_lengths, targets, target_lengths)
# Inference
outputs = model(inputs, input_lengths)
```
## Troubleshoots and Contributing
If you have any questions, bug reports, and feature requests, please [open an issue](https://github.com/sooftware/conformer/issues) on github or
contacts sh951011@gmail.com please.
I appreciate any kind of feedback or contribution. Feel free to proceed with small issues like bug fixes, documentation improvement. For major contributions and new features, please discuss with the collaborators in corresponding issues.
## Code Style
I follow [PEP-8](https://www.python.org/dev/peps/pep-0008/) for code style. Especially the style of docstrings is important to generate documentation.
## Author
* Soohwan Kim [@sooftware](https://github.com/sooftware)
* Contacts: sh951011@gmail.com