https://github.com/spotify/hype
Runs JVM closures in Docker containers on Kubernetes
https://github.com/spotify/hype
cpu disk docker kubernetes lambda memory workflow
Last synced: 9 months ago
JSON representation
Runs JVM closures in Docker containers on Kubernetes
- Host: GitHub
- URL: https://github.com/spotify/hype
- Owner: spotify
- License: apache-2.0
- Archived: true
- Created: 2017-03-09T16:52:29.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2018-03-23T17:46:09.000Z (over 8 years ago)
- Last Synced: 2024-09-28T21:01:26.244Z (almost 2 years ago)
- Topics: cpu, disk, docker, kubernetes, lambda, memory, workflow
- Language: Java
- Homepage:
- Size: 524 KB
- Stars: 36
- Watchers: 89
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-java - Hype
README
[DEPRECATED] hype
====
PLEASE NOTE: THIS REPO HAS BEEN DEPRECATED BECAUSE IT IS NO LONGER USED BY ANY PROJECTS AT SPOTIFY AND THERE ARE NO PLANS TO CONTINUE DEVELOPMENT.
IT WILL NOW BE ARCHIVED.
.ed"""" """$$$$be.
-" ^""**$$$e.
." '$$$c
/ "4$$b
d 3 $$$$
$ * .$$$$$$
.$ ^c $$$$$e$$$$$$$$.
d$L 4. 4$$$$$$$$$$$$$$b
$$$$b ^ceeeee. 4$$ECL.F*$$$$$$$
e$""=. $$$$P d$$$$F $ $$$$$$$$$- $$$$$$
z$$b. ^c 3$$$F "$$$$b $"$$$$$$$ $$$$*" .=""$c
4$$$$L \ $$P" "$$b .$ $$$$$...e$$ .= e$$$.
^*$$$$$c %.. *c .. $$ 3$$$$$$$$$$eF zP d$$$$$
"**$$$ec "\ %ce"" $$$ $$$$$$$$$$* .r" =$$$$P""
"*$b. "c *$e. *** d$$$$$"L$$ .d" e$$***"
^*$$c ^$c $$$ 4J$$$$$% $$$ .e*".eeP"
"$$$$$$"'$=e....$*$$**$cz$$" "..d$*"
"*$$$ *=%4.$ L L$ P3$$$F $$$P"
"$ "%*ebJLzb$e$$$$$b $P"
%.. 4$$$$$$$$$$ "
$$$e z$$$$$$$$$$%
"*$c "$$$$$$$P"
."""*$$$$$$$$bc
.-" .$***$$$"""*e.
.-" .e$" "*$c ^*b.
.=*"""" .e$*" "*bc "*$e..
.$" .z*" ^*$e. "*****e.
$$ee$c .d" "*$. 3.
^*$E")$..$" * .ee==d%
$.d$$$* * J$$$e*
""""" "$$$"
PREVIOUS DOCUMENTATION FOLLOWS
[](https://circleci.com/gh/spotify/hype)
[](https://codecov.io/github/spotify/hype?branch=master)
[](https://search.maven.org/#search%7Cga%7C1%7Cg%3A%22com.spotify%22%20hype*)
[](./LICENSE)
A library for seamlessly executing arbitrary JVM closures in [Docker] containers on [Kubernetes].
---
- [User guide](#user-guide)
* [Dependency](#dependecy)
* [Run functions](#run-functions)
* [Full example](#full-example)
* [Leveraging implicits](#leveraging-implicits)
* [Custom environment images](#custom-environment-images)
- [Process overview](#process-overview)
- [Persistent disk](#persistent-disk)
* [GCE Persistent Disk](#gce-persistent-disk)
+ [Volume re-use](#volume-re-use)
- [Environment Pod from YAML](#environment-pod-from-yaml)
---
# User guide
Hype lets you execute arbitrary JVM code in a distributed environment where different parts
might run concurrently in separate Docker containers, each using different amounts of memory,
CPU and disk. With the help of Kubernetes and a cloud provider such as Google Cloud Platform,
you'll have dynamically scheduled resources available for your code to utilize.
All this might sound a bit abstract, so let's run through a concrete example. We'll be using Scala
for the examples, but all the core functionality is available from Java as well.
## Dependency
SBT
```sbt
"com.spotify" %% "hype" %
```
## Run functions
In order to run functions on the cluster, you'll have to set up a `Submitter` value.
The submitter encapsulates "where" to submit your functions.
```scala
val submitter = GkeSubmitter("gcp-project-id", "gce-zone-id", "gke-cluster-id", "gs://my-staging-bucket")
```
For testing, where you might want to run on a local Docker daemon, use `LocalSubmitter(...)`.
Writing functions that can be executed with Hype is simple, just wrap them up as an `HFn[T]`. An
`HFn[T]` is a closure that allows Hype to move the actual evaluation into a Docker container.
```scala
def example(arg: String) = HFn[String] {
arg + " world!"
}
```
In the previous example, the default Hype Docker image (`spotify/hype`) is used. If you wish to use
your own image, you can easily do so:
```scala
def example(arg: String) = HFn.withImage("us.gcr.io/my-image:42") {
arg + " world!"
}
```
Now we'll have to define the environment we want this function to run in.
```scala
val env = RunEnvironment()
```
Finally, use use the `Submitter` and `RunEnvironment` to execute an `HFn[T]`.
When execution is complete, it'll return the function value back to your local context.
```scala
val result = submitter.submit(example("hello"), env.withRequest("cpu", "750m"))
```
## Full example
This is a full example that runs a simple function that executes an arbitrary command and lists all
environment variables. It uses the Scala [sys.process] package to execute commands in the function.
Also see the [docs on how to create k8s secrets](https://kubernetes.io/docs/concepts/configuration/secret/#creating-your-own-secrets)
```scala
import sys.process._
import com.spotify.hype._
// A simple model for describing the runtime environment
case class EnvVar(name: String, value: String)
case class Res(cmdOutput: String, mounts: String, vars: List[EnvVar])
def extractEnv(cmd: String) = HFn[Res] {
val cmdOutput = cmd !!
val mounts = "df -h" !!
val vars = for ((key, value) <- sys.env.toList)
yield EnvVar(key, value)
Res(cmdOutput, mounts, vars)
}
val submitter = GkeSubmitter("gcp-project-id", "gce-zone-id", "gke-cluster-id", "gs://my-staging-bucket")
val env = RunEnvironment()
.withSecret("gcp-key", "/etc/gcloud") // a pre-created k8s secret volume named "gcp-key"
val res = submitter.submit(extractEnv("uname -a"), env)
println(res.cmdOutput)
println(res.mounts)
res.vars.foreach(println)
```
The `res.vars` list returned should contain the environment variables that were present in the
docker container while running on the cluster. Here's the output:
```
[info] Running HypeExample
[info] 22:15:14.211 | INFO | StagingUtil |> Uploading 69 files to staging location gs://my-staging-bucket to prepare for execution.
[info] 22:15:51.057 | INFO | StagingUtil |> Uploading complete: 4 files newly uploaded, 65 files cached
[info] 22:15:51.673 | INFO | Submitter |> Submitting gs://my-staging-bucket/manifest-9vhb5u18.txt to RunEnvironment{base=RunEnvironment.SimpleBase{image=gcr.io/gcp-project-id/env-image}, secretMounts=[Secret{name=gcp-key, mountPath=/etc/gcloud}], volumeMounts=[], resourceRequests={}}
[info] 22:15:52.221 | INFO | DockerRunner |> Created pod hype-run-mymlbuw8
[info] 22:15:52.351 | INFO | DockerRunner |> Pod hype-run-mymlbuw8 assigned to node gke-hype-test-default-pool-e1122946-fg9k
[info] 22:16:02.454 | INFO | DockerRunner |> Kubernetes pod hype-run-mymlbuw8 exited with status Succeeded
[info] 22:16:02.455 | INFO | DockerRunner |> Got termination message: gs://my-staging-bucket/continuation-993467547293976140-eUWBfwL9J2tHvWuJw0lU3g-hype-run-mymlbuw8-return.bin
[info] Linux hype-run-mymlbuw8 4.4.21+ #1 SMP Fri Feb 17 15:34:45 PST 2017 x86_64 GNU/Linux
[info]
[info] Filesystem Size Used Avail Use% Mounted on
[info] overlay 95G 4.1G 91G 5% /
[info] tmpfs 7.4G 0 7.4G 0% /dev
[info] tmpfs 7.4G 0 7.4G 0% /sys/fs/cgroup
[info] tmpfs 7.4G 4.0K 7.4G 1% /etc/gcloud
[info] /dev/sda1 95G 4.1G 91G 5% /etc/hosts
[info] tmpfs 7.4G 12K 7.4G 1% /run/secrets/kubernetes.io/serviceaccount
[info] shm 64M 0 64M 0% /dev/shm
[info]
[info] EnvVar(HYPE_EXECUTION_ID,hype-run-mymlbuw8)
[info] EnvVar(GOOGLE_APPLICATION_CREDENTIALS,/etc/gcloud/key.json)
[info] EnvVar(HOSTNAME,hype-run-cv7cln6y)
[info] EnvVar(PATH,/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin)
[info] EnvVar(JAVA_VERSION,8u121)
[info] EnvVar(KUBERNETES_SERVICE_HOST,xx.xx.xx.xx)
...
```
## Leveraging implicits
In order to save some keystrokes, you can use our `implicit` operators:
```scala
import com.spotify.hype.magic._
```
Now you can set up an `implicit` `Submitter` value.
```scala
implicit val submitter = GkeSubmitter("gcp-project-id", "gce-zone-id", "gke-cluster-id", "gs://my-staging-bucket")
```
The environment value can also be declared `implicit`,
but this is not required as it can explicitly be referenced when submitting functions.
```scala
implicit val env = RunEnvironment().withSecret("gcp-key", "/etc/gcloud")
```
Finally, use the `#!` (hashbang) operator to execute an `HFn[T]` in a given environment. It will
use the `Submitter` and `RunEnvironment` which should be in scope.
```scala
val result = example("hello") #!
```
Using an `implicit` value as we did above works in most cases, but the hashbang (`#!`)
operator also allows you to specify an explicit environment.
```scala
val result = example("hello") #! env.withRequest("cpu", "750m")
```
## Custom environment images
In order for Hype to be able to execute functions in your custom Docker images, you'll have to
install the `hype-run` command by adding the following to your `Dockerfile`:
```dockerfile
# Install hype-run command
RUN /bin/sh -c "$(curl -fsSL https://goo.gl/kSogpF)"
ENTRYPOINT ["hype-run"]
```
It is important to have exactly this `ENTRYPOINT` as the Kubernetes Pods will expect to run the
`hype-run` command.
See example [`Dockerfile`](hype-docker/Dockerfile)
# Process overview
This describes what Hype does from a high level point of view.
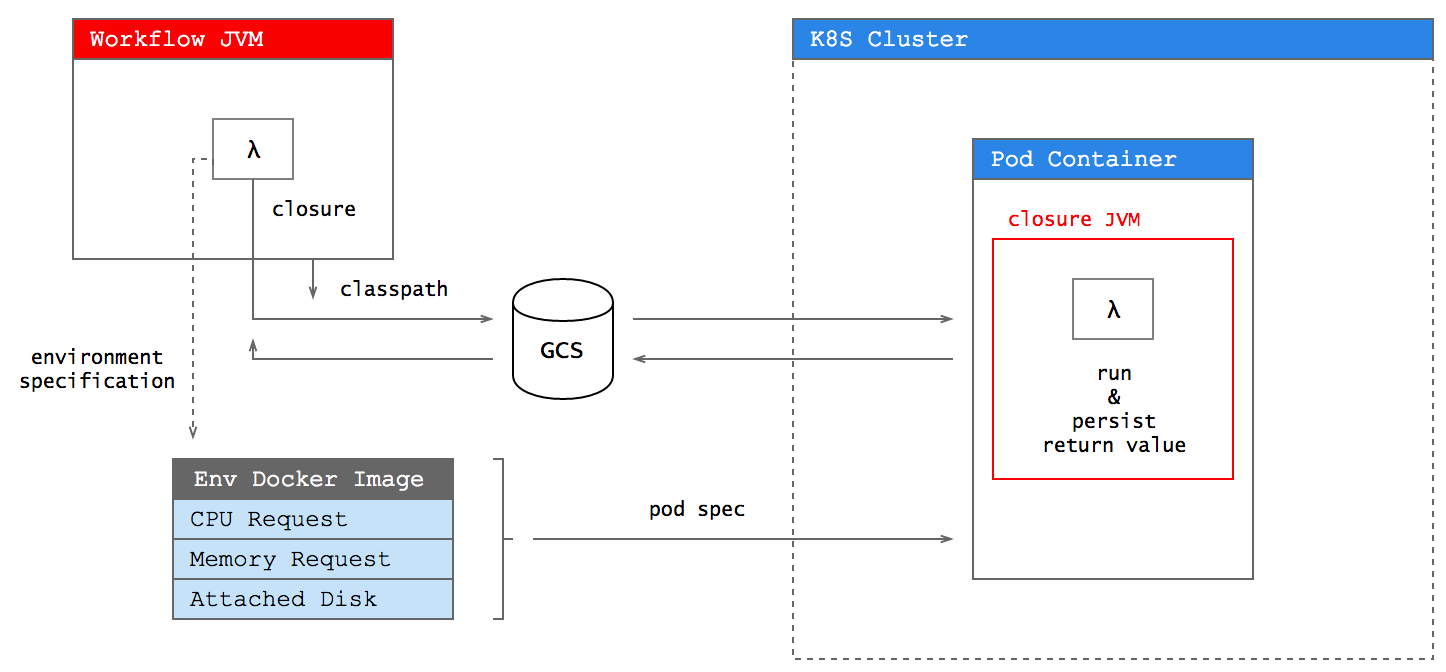
# Persistent disk
Hype makes it easy to schedule persistent disk volumes across different closures in a workflow.
A typical pattern seen in many use cases is to first use a disk in read-write mode to download and
prepare some data, and then fork out to several parallel tasks that use the disk in read-only mode.

## GCE Persistent Disk
In this example, we're using a StorageClass for [GCE Persistent Disk] that we've already set up on
our cluster.
```yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: gce-ssd-pd
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
```
We can then request volumes from this StorageClass using the Hype API:
```scala
import sys.process._
import com.spotify.hype.magic._
implicit val submitter = GkeSubmitter("gcp-project-id",
"gce-zone-id",
"gke-cluster-id",
"gs://my-staging-bucket")
// Create a 10Gi volume from the 'gce-ssd-pd' storage class
val ssd10Gi = TransientVolume("gce-ssd-pd", "10Gi")
val mount = "/usr/share/volume"
val env = RunEnvironment()
val readWriteEnv = env.withMount(ssd10Gi.mountReadWrite(mount))
val readOnlyEnv = env.withMount(ssd10Gi.mountReadOnly(mount))
def write = HFn[Int] {
// get a random word and store it in the volume
s"curl -so $mount/word http://www.setgetgo.com/randomword/get.php" !
}
def read = HFn[String] {
// read the word file
s"cat $mount/word" !!
}
// Write to the volume
write #! readWriteEnv
// Run 10 parallel functions that have read only access to the volume
val results = for (_ <- Range(0, 10).par)
yield read #! readOnlyEnv
```
The submissions from the parallel range will each run concurrently in separate pods and have
read-only access to the `/usr/share/volume` mount. The volume should contain the random word that
was written to it from the `write` function.
Coordinating metadata and parameters across multiple submissions should be just as trivial as
passing values from function calls as arguments to other functions.
### Volume re-use
By default, the backing claim for a `TransientVolume` on Kubernetes is deleted when the JVM
terminates.
If you wish to persist the Volume between invocations, you can use:
```scala
val disk = PersistentVolume("my-persistent-volume", "gce-ssd-pd", "10Gi")
```
If the volume does not exist, it will be created. Subsequent invocations will return use already
created volume.
This is useful in use cases with larger volumes that take a significant amount of time to load,
or when there's some sort of workflow orchestration around the Hype code that might run
different parts in separate JVM invocations.
# Environment Pod from YAML
Sometimes more control over the Kubernetes Pod is desired. For these cases a regular Pod YAML file
can be used as a base for the `RunEnvironment`. Hype will still manage any used Volume Claims and
mounts, but will leave all other details as you've specified them.
Hype will expect at least this field to be specified:
- `spec.containers[name:hype-run]` - There must at least be a container named `hype-run`
Please note that the image field should *not* bet set (Hype requires each module to define its image).
_Hype will override the `spec.containers[name:hype-run].args` field, so don't set it._
Here's a minimal Pod YAML file with some custom settings, `./src/main/resources/pod.yaml`:
```yaml
apiVersion: v1
kind: Pod
spec:
restartPolicy: Never # do not retry on failure
containers:
- name: hype-run
imagePullPolicy: Always # pull the image on each run
env: # additional environment variables
- name: EXAMPLE
value: my-env-value
```
Any resource requests added through the `RunEnvironment` API will merge with, and override the ones
set in the YAML file.
Then simply load your `RunEnvironment` through
```scala
val env = RunEnvironmentFromYaml("/pod.yaml")
```
---
_This project is in early development stages, expect anything you see to change._
[Docker]: https://www.docker.com
[Kubernetes]: https://kubernetes.io/
[GCE Persistent Disk]: http://blog.kubernetes.io/2016/10/dynamic-provisioning-and-storage-in-kubernetes.html
[sys.process]: http://www.scala-lang.org/api/rc2/scala/sys/process/package.html