https://github.com/ssine/pptx2md
a pptx to markdown converter
https://github.com/ssine/pptx2md
Last synced: 8 months ago
JSON representation
a pptx to markdown converter
- Host: GitHub
- URL: https://github.com/ssine/pptx2md
- Owner: ssine
- License: apache-2.0
- Created: 2018-11-02T16:09:54.000Z (about 7 years ago)
- Default Branch: master
- Last Pushed: 2024-12-03T17:41:42.000Z (about 1 year ago)
- Last Synced: 2025-04-28T18:27:45.043Z (8 months ago)
- Language: Python
- Size: 259 KB
- Stars: 967
- Watchers: 16
- Forks: 124
- Open Issues: 12
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- jimsghstars - ssine/pptx2md - a pptx to markdown converter (Python)
README
# PPTX2MD
[](https://pepy.tech/project/pptx2md)
A tool to convert Powerpoint pptx file into markdown.
**Preserved formats:**
* Titles. Custom table of contents with fuzzy matching is supported.
* Lists with arbitrary depth.
* Text with **bold**, _italic_, color and [hyperlink](https://github.com/ssine/pptx2md/blob/master/README.md)
* Pictures. They are extracted into image file and relative path is inserted.
* Tables with merged cells.
* Top-to-bottom then left-to-right block order.
**Supported output:**
* Markdown
* [Tiddlywiki](https://tiddlywiki.com/)'s wikitext
* [Madoko](https://www.madoko.net/)
* [Quarto](https://quarto.org/)
_Please star this repo if you like it!_
## Installation & Usage
### Installation
You need to have _[Python](https://www.python.org/)_ with version later than __3.10__ and _pip_ installed on your system, then run in the terminal:
```sh
pip install pptx2md
```
### Usage
Once you have installed it, use the command `pptx2md [pptx filename]` to convert _pptx file_ into markdown.
The default output filename is `out.md`, and any pictures extracted (and inserted into .md) will be placed in `/img/` folder.
__Note:__ older .ppt files are not supported, convert them to the new .pptx version first.
__Upgrade & Remove:__
```sh
pip install --upgrade pptx2md
pip uninstall pptx2md
```
## Custom Titles
By default, this tool parse all the pptx titles into `level 1` markdown titles, in order to get a hierarchical table of contents, provide your predefined title list in a file and provide it with `-t` argument.
This is a sample title file (titles.txt):
```
Heading 1
Heading 1.1
Heading 1.1.1
Heading 1.2
Heading 1.3
Heading 2
Heading 2.1
Heading 2.2
Heading 2.1.1
Heading 2.1.2
Heading 2.3
Heading 3
```
The first line with spaces in the begining is considered a second level heading and the number of spaces is the unit of indents. In this case, ` Heading 1.1` will be outputted as `## Heading 1.1` . As it has two spaces at the begining, 2 is the unit of heading indent, so ` Heading 1.1.1` with 4 spaces will be outputted as `### Heading 1.1.1`. Header texts are matched with fuzzy matching, unmatched pptx titles will be regarded as the deepest header.
Use it with `pptx2md [filename] -t titles.txt`.
## Full Arguments
* `-t [filename]` provide the title file
* `-o [filename]` path of the output file
* `-i [path]` directory of the extracted pictures
* `--image-width [width]` the maximum width of the pictures, in px. **If set, images are put as html img tag.**
* `--disable-image` disable the image extraction
* `--disable-escaping` do not attempt to escape special characters
* `--disable-notes` do not add presenter notes
* `--disable-wmf` keep wmf formatted image untouched (avoid exceptions under linux)
* `--disable-color` disable color tags in HTML
* `--enable-slides` deliniate slides `\n---\n`, this can help if you want to convert pptx slides to markdown slides
* `--try-multi-column` try to detect multi-column slides (very slow)
* `--min-block-size [size]` the minimum number of characters for a text block to be outputted
* `--wiki` / `--mdk` if you happen to be using tiddlywiki or madoko, this argument outputs the corresponding markup language
* `--qmd` outputs to the qmd markup language used for [quarto](https://quarto.org/docs/presentations/revealjs/) powered presentations
* `--page [number]` only convert the specified page
* `--keep-similar-titles` keep similar titles and add "(cont.)" to repeated slide titles
Note: install [wand](https://docs.wand-py.org/en/0.6.12/) for better chance of successfully converting wmf images, if needed.
## Screenshots
```
Data Link Layer Design Issues
Services Provided to the Network Layer
Framing
Error Control & Flow Control
Error Detection and Correction
Error Correcting Code (ECC)
Error Detecting Code
Elementary Data Link Protocols
Sliding Window Protocols
One-Bit Sliding Window Protocol
Protocol Using Go Back N
Using Selective Repeat
Performance of Sliding Window Protocols
Example Data Link Protocols
PPP
```

* **Top**: Title list file content.
* **Bottom**: The table of contents generated.
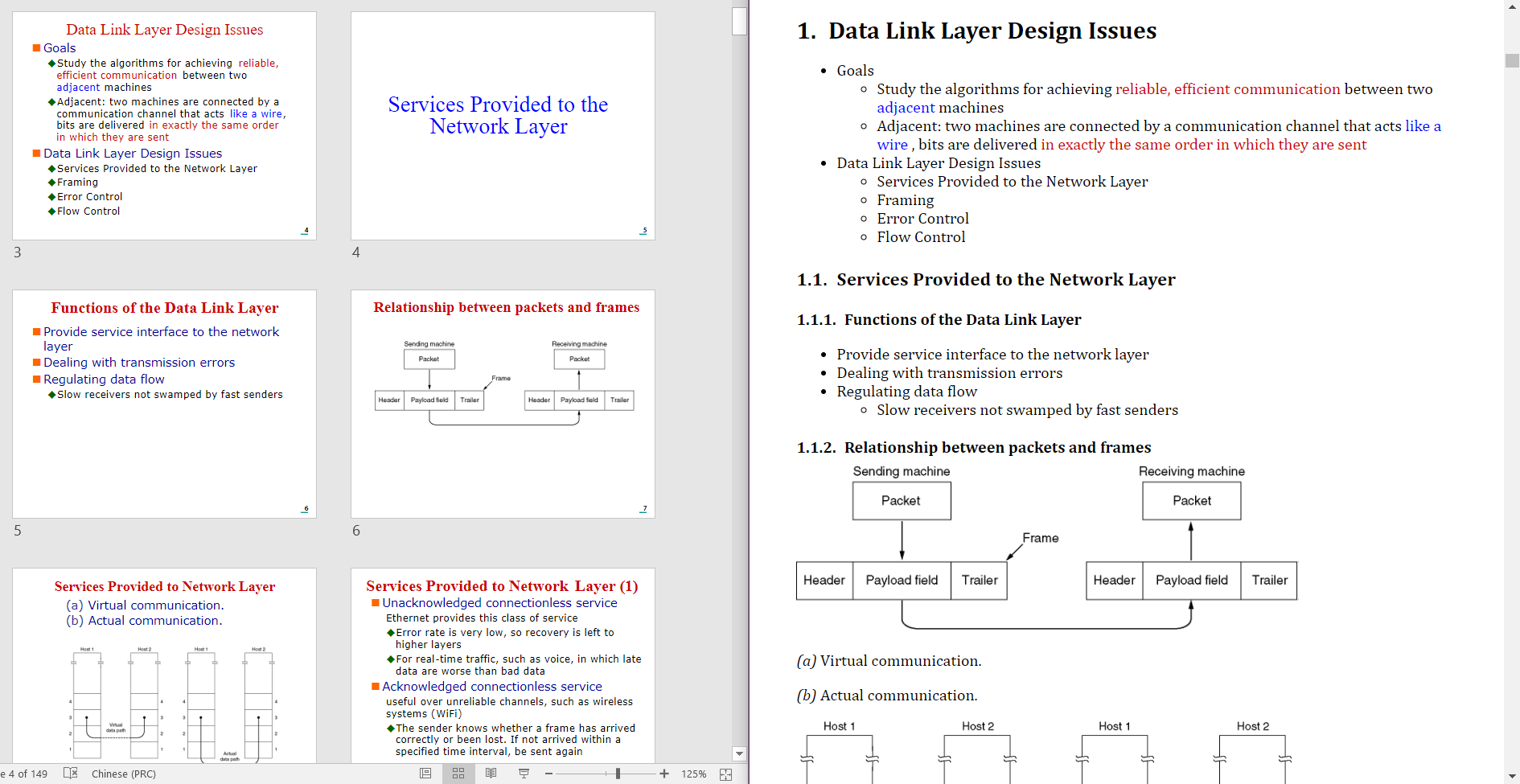
* **Left**: Source pptx file.
* **Right**: Generated markdown file (rendered by madoko).
## API Usage
You can also use pptx2md programmatically in your Python code:
```python
from pptx2md import convert, ConversionConfig
from pathlib import Path
# Basic usage
convert(
ConversionConfig(
pptx_path=Path('presentation.pptx'),
output_path=Path('output.md'),
image_dir=Path('img'),
disable_notes=True
)
)
```
The `ConversionConfig` class accepts the same parameters as the command line arguments:
- `pptx_path`: Path to the input PPTX file (required)
- `output_path`: Path for the output markdown file (required)
- `image_dir`: Directory for extracted images (required)
- `title_path`: Path to custom titles file
- `image_width`: Maximum width for images in px
- `disable_image`: Skip image extraction
- `disable_escaping`: Skip escaping special characters
- `disable_notes`: Skip presenter notes
- `disable_wmf`: Skip WMF image conversion
- `disable_color`: Skip color tags in HTML
- `enable_slides`: Add slide delimiters
- `try_multi_column`: Attempt to detect multi-column slides
- `min_block_size`: Minimum text block size
- `wiki`: Output in TiddlyWiki format
- `mdk`: Output in Madoko format
- `qmd`: Output in Quarto format
- `page`: Convert only specified page number
- `keep_similar_titles`: Keep similar titles with "(cont.)" suffix
## Detailed Parse Rules
### Text and Layout Processing
* Text blocks are identified in two ways:
* Paragraphs marked as "body" placeholders in the slide
* Text shapes containing more than the minimum block size (configurable)
* Lists are generated when paragraphs in a block have different indentation levels
* Single-level paragraphs are output as regular text blocks
* Multi-column layouts can be detected with `--try-multi-column` flag
* Grouped shapes are recursively flattened to process their contents
* Shapes are processed in top-to-bottom, left-to-right order
### Title Handling
* When using custom titles:
* Fuzzy matching is used to match slide titles with the provided title list
* Matching score must be > 92 for a match to be accepted
* Unmatched titles default to the deepest header level
* Similar titles (matching score > 92) are omitted by default unless `--keep-similar-titles` is used
### Formatting and Styling
* Text formatting is preserved through markdown syntax:
* Bold text from PPT is converted to `**bold**`
* Italic text is converted to `_italic_`
* Hyperlinks are preserved as `[text](url)`
* Color handling:
* Theme colors marked as "Accent 1-6" are preserved
* RGB colors are converted to HTML color codes
* Dark theme colors are converted to bold text
* Color tags can be disabled with `--disable-color`
### Special Elements
* Images:
* Extracted to specified image directory
* WMF images are converted to PNG when possible
* Image width can be constrained with `--image-width`
* HTML img tags are used when width is specified
* Tables:
* Merged cells are supported
* Complex formatting within cells is preserved
* Special characters are escaped by default (can be disabled with `--disable-escaping`)
* Presenter notes are included unless disabled with `--disable-notes`