https://github.com/steviecurran/interactive-customer-segmentation
Interactive Customer Segmentation Pipeline
https://github.com/steviecurran/interactive-customer-segmentation
clustering custumer-segmentation dendrogram elbow-plot hierarchical-clustering pricing principal-component-analysis python sklearn unsupervised-machine-learning
Last synced: about 2 months ago
JSON representation
Interactive Customer Segmentation Pipeline
- Host: GitHub
- URL: https://github.com/steviecurran/interactive-customer-segmentation
- Owner: steviecurran
- Created: 2026-05-18T16:39:11.000Z (2 months ago)
- Default Branch: main
- Last Pushed: 2026-05-18T17:58:00.000Z (2 months ago)
- Last Synced: 2026-05-18T19:33:28.773Z (2 months ago)
- Topics: clustering, custumer-segmentation, dendrogram, elbow-plot, hierarchical-clustering, pricing, principal-component-analysis, python, sklearn, unsupervised-machine-learning
- Language: Jupyter Notebook
- Homepage:
- Size: 1.01 MB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## Interactive Customer Segmentation Pipeline
An interactive machine learning workflow for customer segmentation using hierarchical clustering, K-means clustering, and Principal Component Analysis (PCA).
This project focuses on exploratory segmentation and interpretability rather than static clustering outputs. The notebook allows dynamic adjustment of clustering parameters, dimensionality reduction thresholds, and visualisation settings to investigate how customer populations separate into meaningful behavioural groups.
### Project Overview
Customer segmentation is widely used in:
- marketing and targeting
- customer retention
- pricing strategy
- behavioural analytics
- product personalisation
This project demonstrates an end-to-end unsupervised learning pipeline combining:
- exploratory analysis
- hierarchical clustering
- K-means clustering
- PCA dimensionality reduction
- interactive visualisation tools
Unlike standard clustering examples, this workflow emphasises:
- interactive exploration
- cluster interpretation
- dynamic parameter selection
- reusable analytical tooling
### Key Features
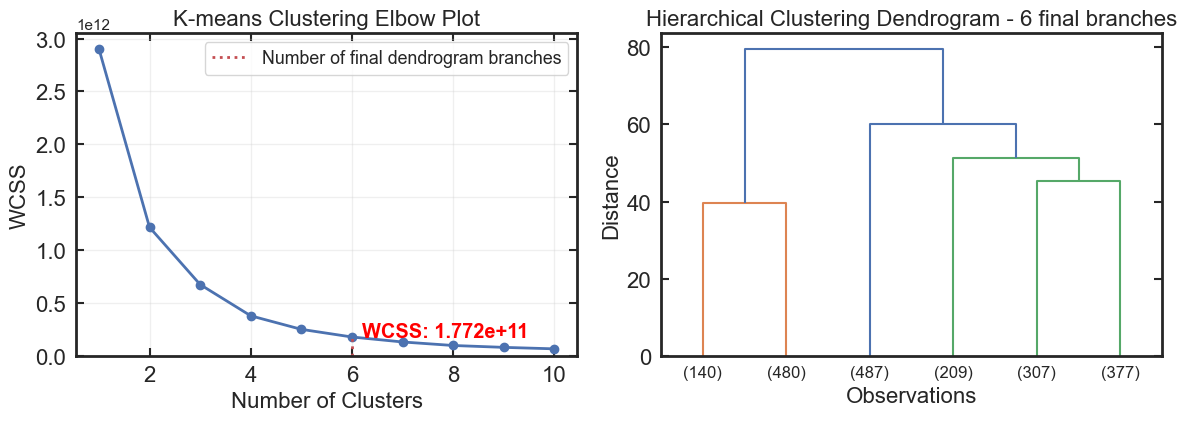
**Hierarchical Clustering**
- Ward linkage dendrogram visualisation
- Interactive branch selection
- Large-dataset sampling safeguards
**K-Means Segmentation**
- Dynamic cluster count selection
- Interactive feature comparison
- Cluster visualisation with custom labels
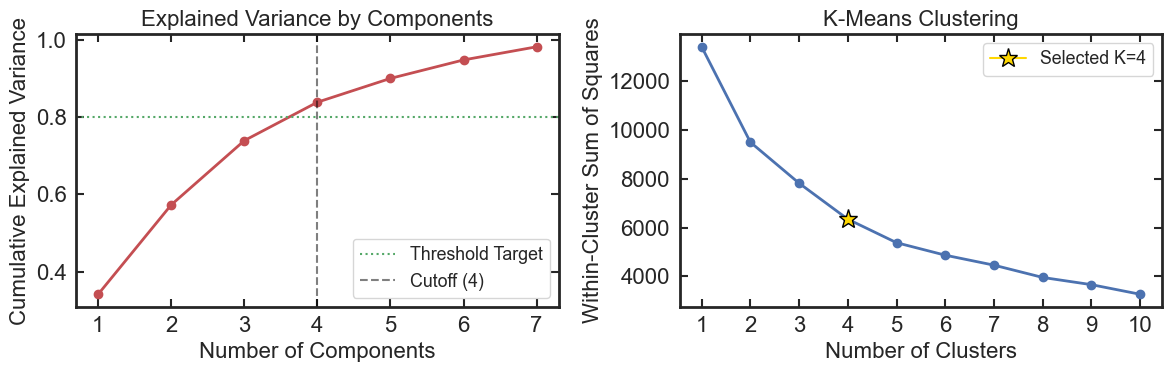
**Principal Component Analysis (PCA)**
- Automatic variance-threshold component selection
- Manual component override
- Explained variance diagnostics
- PCA-space cluster projection
**Interactive Workflow**
- Widget-driven exploration
- Dynamic cluster naming
- Adjustable visualisation axes
- Real-time recomputation of segmentation outputs
### Example Workflow
**1. Explore Dataset Structure**
Hierarchical clustering is first used to estimate the natural grouping structure within the dataset.
**2. Generate Customer Segments**
K-means clustering partitions the dataset into behavioural groups.
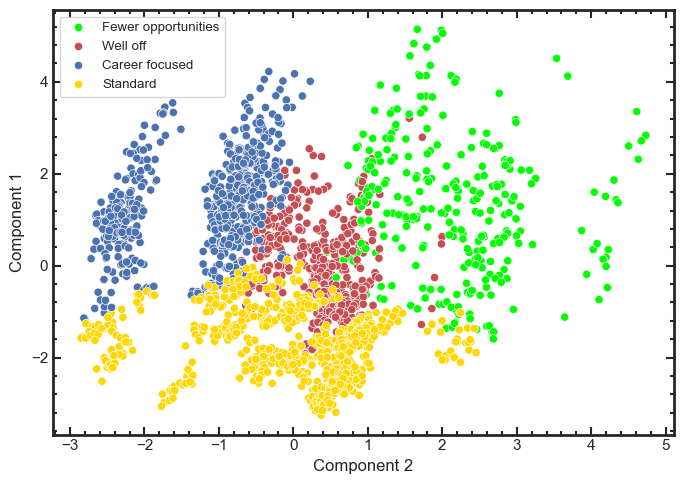
**3. Interpret Clusters**
Clusters are translated into meaningful customer profiles
**4. Reduce Dimensionality**
PCA compresses the feature space while preserving most of the dataset variance.
**5. Visualise Cluster Separation**
Clusters are projected into lower-dimensional PCA space for interpretability and exploratory analysis.
### Technologies Used
Python Libraries
- pandas
- numpy
- matplotlib
- seaborn
- scikit-learn
- scipy
- ipywidgets
### Example Outputs
The notebook includes:
- dendrogram visualisations
- elbow plots
- explained variance analysis
- interactive scatter plots
- PCA cluster projections
- labelled segmentation outputs
### Business Interpretation
The segmentation pipeline identifies statistically distinct customer groups with meaningful behavioural and demographic characteristics.
Potential applications include:
- targeted marketing campaigns
- customer retention strategies
- pricing differentiation
- behavioural profiling
- product recommendation systems
The interactive design allows rapid exploration of how segmentation changes under different assumptions and clustering configurations.
### Running the Notebook
Clone the repository:
git clone https://github.com/steviecurran/.git
Install dependencies:
pip install pandas numpy matplotlib seaborn scikit-learn scipy ipywidgets
Launch Jupyter Notebook:
jupyter notebook
### Notes
This project prioritises:
- interpretability
- exploratory analysis
- interactive workflow design
rather than production deployment or automated optimisation pipelines.
The notebook is intended as a reusable analytical framework for segmentation exploration and educational demonstration.