https://github.com/swistak35/uwr_bwt_compression
Compression & decompression programs made for Data Compression course on University of Wrocław. Use the same algorithms as bzip.
https://github.com/swistak35/uwr_bwt_compression
Last synced: 9 months ago
JSON representation
Compression & decompression programs made for Data Compression course on University of Wrocław. Use the same algorithms as bzip.
- Host: GitHub
- URL: https://github.com/swistak35/uwr_bwt_compression
- Owner: swistak35
- Created: 2015-06-15T20:41:36.000Z (over 10 years ago)
- Default Branch: master
- Last Pushed: 2015-06-15T20:54:43.000Z (over 10 years ago)
- Last Synced: 2023-03-12T07:12:18.641Z (almost 3 years ago)
- Language: C++
- Size: 395 KB
- Stars: 1
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Data compression program
These are simple programs written for 'Data compression' course on University of Wrocław.
Online (and prettier) version of this document is available here: https://github.com/swistak35/uwr_bwt_compression .
## Compilation
`make all` will build all programs.
## Usage
There are few versions of the programs, each one of them is using different sorting algorithm.
```
compress-{lexi,uni,suffix} input_file output_file block_size
```
Default block size is 256 bytes.
```
decompress{0,1} input_file output_file block_size
```
Default block size is 256 bytes.
## Compression
* `compress-lexi` is using **lexi**cographical sorting algorithm. Thus, if we are sorting all shifts of string of length n, it's roughly O(n^2).
* `compress-uni` is algorithm proposed on my **uni**versity course. It's O(n*logn) and it's kind of lexicographical sorting, but using the fact that all of sorted strings are just a shifts.
* `compress-suffix`. This algorithm just builts the **suffix** tree and by looking it left to right we get sorted strings.
### Suffix theoretical background
Suffix trees are built using Ukkonen's algorithm. As stated above, this algorithm just create suffix tree and read suffixes left to right.
However, we assume that there's a # letter at the end. By `#` we mean letter bigger than any other letter in used alphabet. Thus, this algorithm doesn't sort all shifts of the given string, but it sorts it's suffixes.
## Decompression
There are two programs for decompression:
* `decompress0` - use that one, when you are decompressing from `compress-lexi` or `compress-uni`.
* `decompress1` - use this one, when you are decompressing from `compress-suffix`.
Obviously, one could made only one decompression program, which detects which sorting algorithm was used. We just would have to include a fingerprint of the sorting algorithm in the beginning of compressed file.
However, remember that this is only a university project. Thus it doesn't have best file structure and somewhere DRY is violated (pretty much only in compress-* and decompress* files).
## Experiments
Whole purpose of this programs are experiments. That's why we have another script here, `runtests.rb`. It needs ruby to be ran. I was using Ruby 2.2.2, but all rubies >= 1.9.3 should be fine.
To run tests, run:
```
./runtests.rb
```
If test_suit_name is not provided, it's assumed to be one named `default`.
All test suites are defined in the top section of the file. Ruby is very readable language, so you should not have problems with understanding and modifying test suites.
Included test suites:
* `default` - test suite used to test correctness of my programs. Mostly tests with sizes crafted to detect different off-by-one errors. Runs all of the algorithms with small sizes (256, 1024 bytes)
* `rfc` - this test suite was created for purpose of testing how our programs compress bigger text files. There are 14 text files, each one of them include content of 500 RFC documents. These are pretty big files, most of them have 25-30MB. This was my favourite test for testing speed differences between `uni` and `suffix` algorithms.
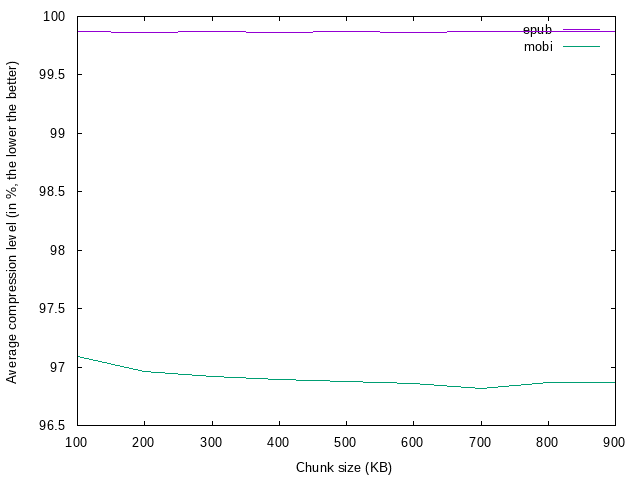
* `mobi`, `epub`, `pdf` - all of these are similar. Each one of them consists of 20 files in given format. I don't include in the repository as these were my personal ebooks. I used these plans to check efficiency (compression level) of given file formats.
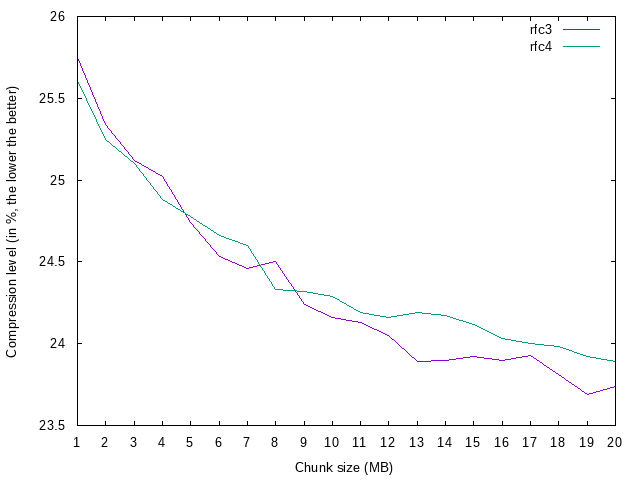
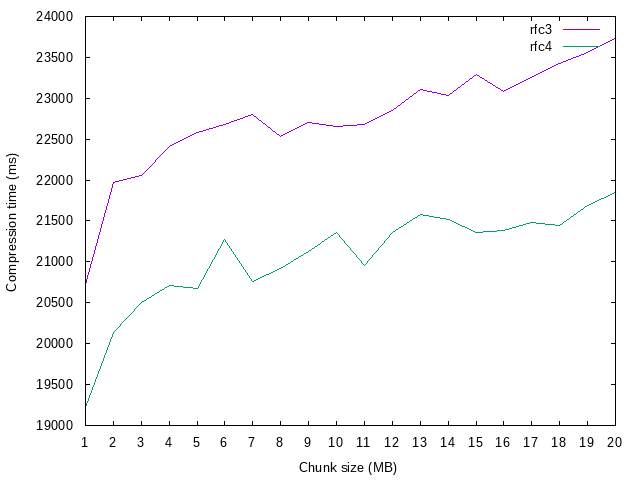
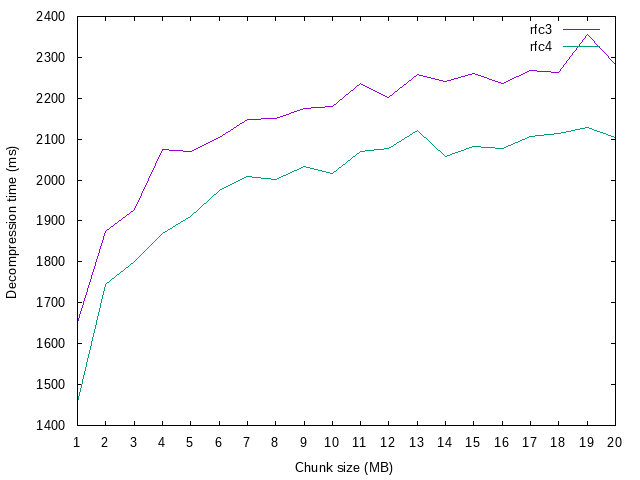
* `bigeff` - this test suite was for testing how efficiency changes when we start to use really big chunks (1..20 MB)
* `bin` - bunch of binary files generated with `dd` tool. I think I will prepare script for generating these. These were 3-5MB in size.
* `trzysta` - these also were generated by `dd`. However, they were all small (300B) files, I generated a thousand of them to have many random examples. I used them with hope that maybe they will show me some bugs.
## Possible optimizations
Here I include possible optimizations which come to my mind, but I didn't have enough time and/or enthusiasm to introduce.
* Dynamic huffman implementation which I am using here was found in the internet. It assumes that input is integers - rewriting it to accept one-byte-long unsigned chars could be beneficial.
* Most of the classes could be rewritten using templates
* Cache-line optimizations. Probably the suffix algorithm is the one which could gain here the most, as this is the one which access memory in pretty random way.
* inlining simple functions
* different MoveToFront implementation - it may be that implementation which use array instead of linked list will be much faster (both of them are O(n), but array have bigger constant) because of caching.
* uni sorting may be inefficient because of using vectors, if they are often reallocated
It should be noted that, for example in suffix implementation, sorting part of the algorithm and MTF phase take roughly similar amount of time. Huffman encoding takes a row of magnitude less time. Also, I am writing here about CPU time, not real time, so `Huffman <-> Filesystem` communication may be good place to seek for improvements.
# Tests & charts
## 'Big chunk' test
## Ebooks test
## Text files test (RFC)
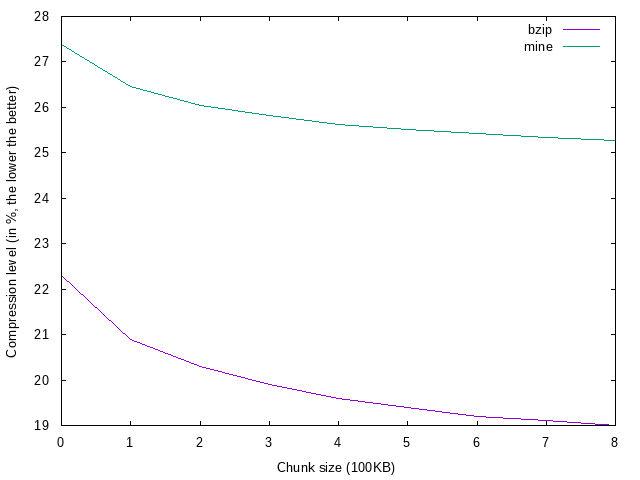
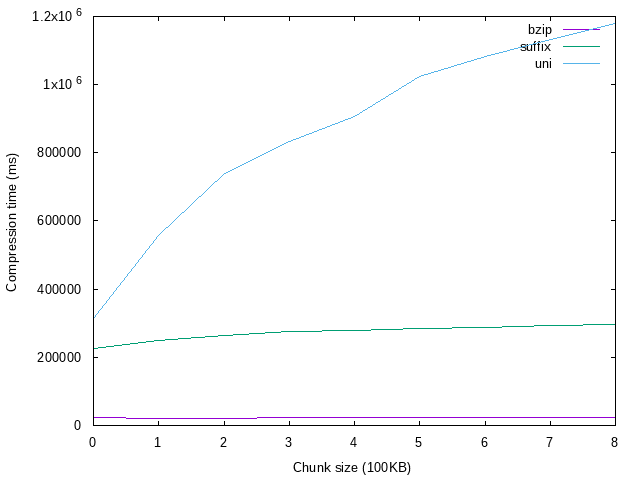
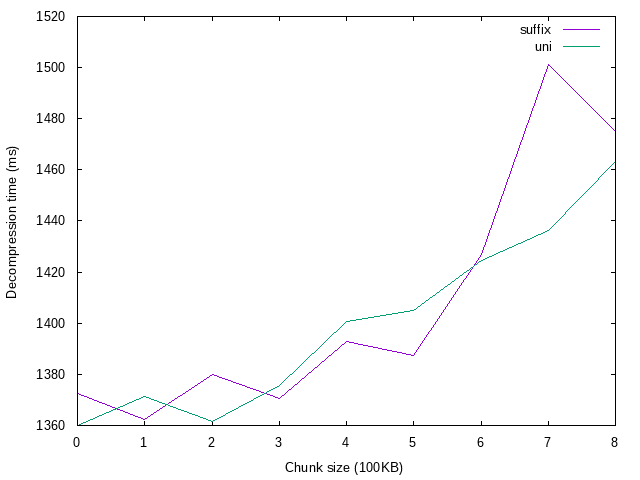
# Short notes & conclusions
* Before making this task I heard opinion that Suffix algorithm may be in the end slower than Uni algorithm because of very big constant in construction of suffix trees. From mine experiments, it looks that it's not true and Suffix algorithm is significantly better than Uni.
* As one could prefict...:
* ... packaged data (epub, mobi) are hard to compress effectively.
* ... ordinary text files compress very well.
* ... using bigger chunk gives better compression, but also prolongs compression time.
* ... decompression time is few orders of magnitude smaller than compression time.
# Implementation notes
Initially (and by accident) I started implementing McCreight algorithm, which is very similar. I tried to do it based on internet resources, but I failed with precise process how and when create suffix links in this algorithm. After that I implemented Ukkonen's algorithm, which I found quite easy to follow.
Uni algorithm may be significantly improved. Currently it uses vectors implementation from standard c++ library. It may be the case that this do some heavy reallocating. Substituting vectors by `n*n` array is not so easy, because if we'll use chunks with size even so small as 100KiB, it will need (100 * 1000)^2 = 10GB memory, at least. However, one could try to make some experiments and try to make array with n rows, but less than n columns (assume `k` columns), and if it happen to need more columns, we could just use linked list or vector for remaining elements.
Suffix implementation also probably may be improved. It represents string as a tree, so memory access to edges and branch nodes is very random. Waiting for data in our computers is estimated for 200 cycles, and if we are constantly missing the cache (because the data is scattered), we spend most time idling.
BWT algorithm which we are using here, is also used in compression format widely known as `bzip2`. Author of `bzip2` implementation also seems to agree with this statement. Quoting from bzip documentation:
> bzip2 usually allocates several megabytes of memory to operate in, and then charges all over it in a fairly random fashion. This means that performance, both for compressing and decompressing, is largely determined by the speed at which your machine can service cache misses. Because of this, small changes to the code to reduce the miss rate have been observed to give disproportionately large performance improvements. I imagine bzip2 will perform best on machines with very large caches."