https://github.com/szagoruyko/binary-wide-resnet
PyTorch implementation of Wide Residual Networks with 1-bit weights by McDonnell (ICLR 2018)
https://github.com/szagoruyko/binary-wide-resnet
pytorch wide-residual-networks
Last synced: 11 months ago
JSON representation
PyTorch implementation of Wide Residual Networks with 1-bit weights by McDonnell (ICLR 2018)
- Host: GitHub
- URL: https://github.com/szagoruyko/binary-wide-resnet
- Owner: szagoruyko
- License: mit
- Created: 2018-08-26T16:03:17.000Z (almost 8 years ago)
- Default Branch: master
- Last Pushed: 2018-09-06T12:59:12.000Z (almost 8 years ago)
- Last Synced: 2025-04-07T01:40:07.956Z (about 1 year ago)
- Topics: pytorch, wide-residual-networks
- Language: Python
- Homepage:
- Size: 12.7 KB
- Stars: 123
- Watchers: 8
- Forks: 15
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- Awesome-pytorch-list-CNVersion - binary-wide-resnet - bit weights by McDonnel (ICLR 2018) (Paper implementations|论文实现 / Other libraries|其他库:)
- Awesome-pytorch-list - binary-wide-resnet - bit weights by McDonnel (ICLR 2018) (Paper implementations / Other libraries:)
README
1-bit Wide ResNet
===========
PyTorch implementation of training 1-bit Wide ResNets from this paper:
*Training wide residual networks for deployment using a single bit for each weight* by **Mark D. McDonnell** at ICLR 2018
The idea is very simple but surprisingly effective for training ResNets with binary weights. Here is the proposed weight parameterization as PyTorch autograd function:
```python
class ForwardSign(torch.autograd.Function):
@staticmethod
def forward(ctx, w):
return math.sqrt(2. / (w.shape[1] * w.shape[2] * w.shape[3])) * w.sign()
@staticmethod
def backward(ctx, g):
return g
```
On forward, we take sign of the weights and scale it by He-init constant. On backward, we propagate gradient without changes. WRN-20-10 trained with such parameterization is only slightly off from it's full precision variant, here is what I got myself with this code on CIFAR-100:
| network | accuracy (5 runs mean +- std) | checkpoint (Mb) |
|:---|:---:|:---:|
| WRN-20-10 | 80.5 +- 0.24 | 205 Mb |
| WRN-20-10-1bit | 80.0 +- 0.26 | 3.5 Mb |
## Details
Here are the differences with WRN code :
* BatchNorm has no affine weight and bias parameters
* First layer has 16 * width channels
* Last fc layer is removed in favor of 1x1 conv + F.avg_pool2d
* Downsample is done by F.avg_pool2d + torch.cat instead of strided conv
* SGD with cosine annealing and warm restarts
I used PyTorch 0.4.1 and Python 3.6 to run the code.
Reproduce WRN-20-10 with 1-bit training on CIFAR-100:
```bash
python main.py --binarize --save ./logs/WRN-20-10-1bit_$RANDOM --width 10 --dataset CIFAR100
```
Convergence plot (train error in dash):
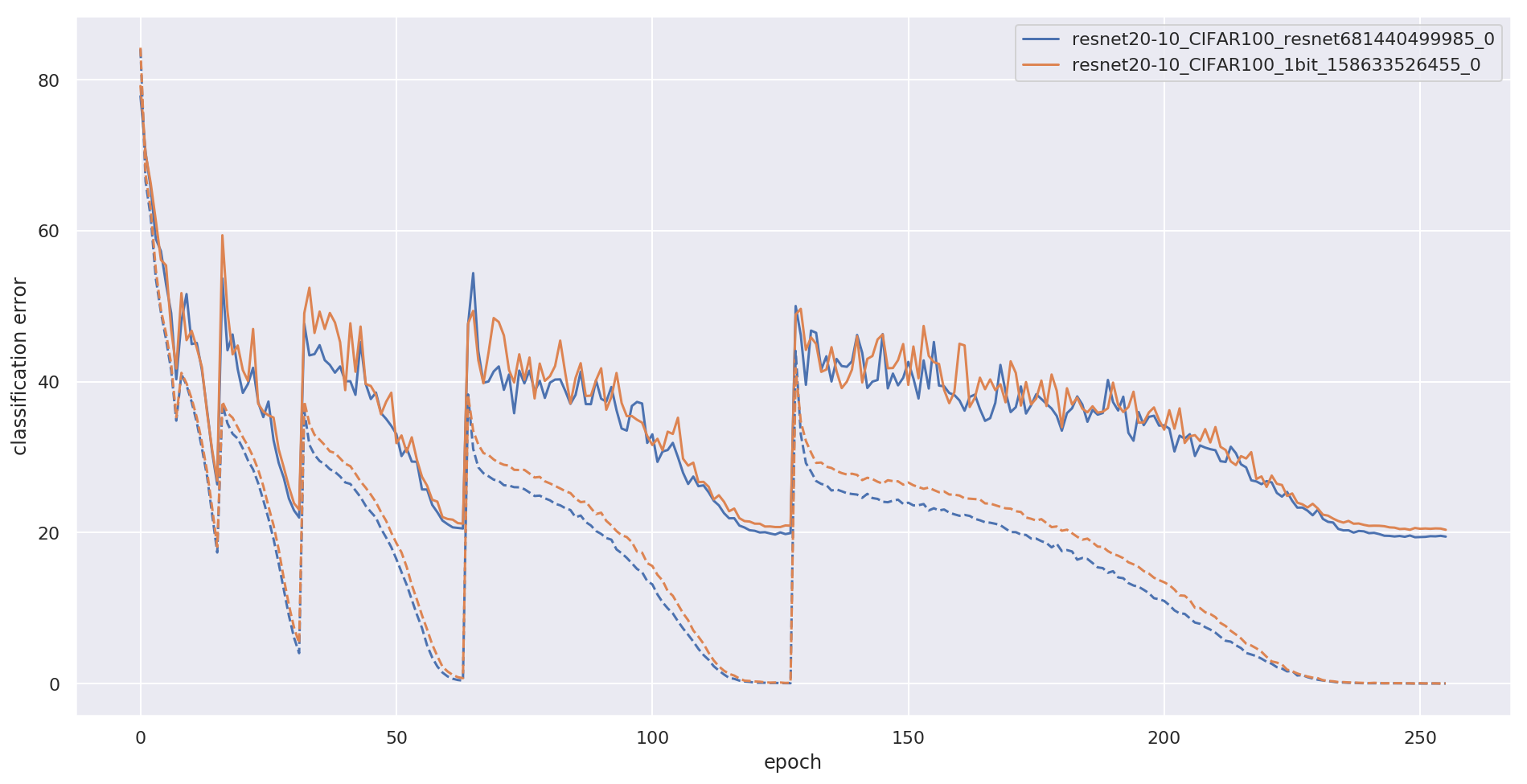
I've also put 3.5 Mb checkpoint with binary weights packed with `np.packbits`, and a very short script to evaluate it:
```bash
python evaluate_packed.py --checkpoint wrn20-10-1bit-packed.pth.tar --width 10 --dataset CIFAR100
```
S3 url to checkpoint: