Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/tansongchen/lxsp
落萧双拼:带调双拼单字二码顶方案
https://github.com/tansongchen/lxsp
Last synced: about 2 months ago
JSON representation
落萧双拼:带调双拼单字二码顶方案
- Host: GitHub
- URL: https://github.com/tansongchen/lxsp
- Owner: tansongchen
- License: gpl-3.0
- Created: 2024-03-19T01:18:52.000Z (10 months ago)
- Default Branch: main
- Last Pushed: 2024-03-19T02:59:22.000Z (10 months ago)
- Last Synced: 2024-10-19T09:55:31.195Z (3 months ago)
- Size: 814 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 落萧双拼
配方: ℞ **lxsp**
落萧双拼是单字前两码为带调双拼、后两码为二笔的音形码输入方案。本方案采用「二码顶」结构,在码表中凡是长度为 2 及更长的编码无需空格确认即可上屏。本方案以单字输入为主,词语输入为辅。
# 键盘图
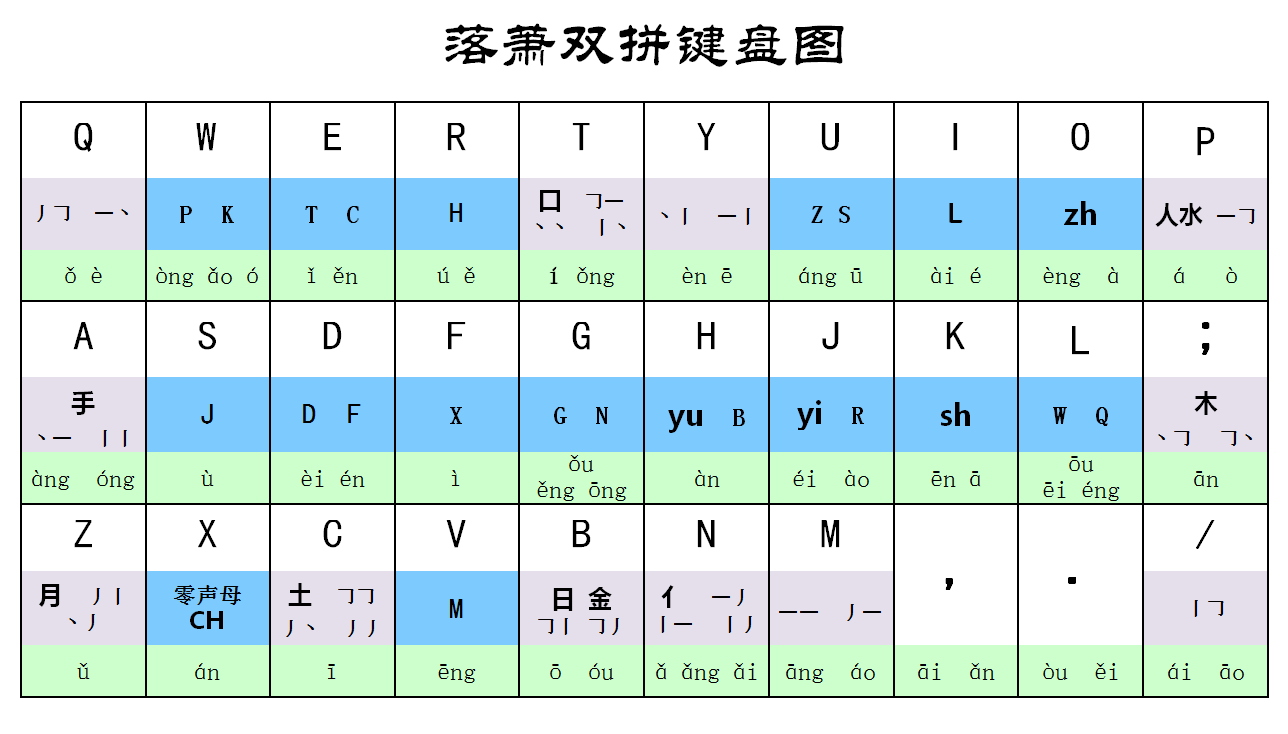
# 基本规则
## 第一码:声母
依照 16 个蓝色的键进行编码。
对于零声母音节来说,分为以下四种情况:
1. 开口呼(以 a, o, e 开头的音节):在键盘图上用「零声母」表示;
2. 合口呼(以 w 开头的音节):在键盘图上用 w 表示;
3. 齐齿呼(以 y 开头的音节):在键盘图上用 yi 表示;
4. 撮口呼(以 yu 开头的音节):在键盘图上用 yu 表示。
## 第二码:带调韵母
依照 30 个绿色的键进行编码。
由于带调韵母数量比较多,像 an, ian, uan 这种只有介音不同的韵母归并为一组处理,键盘上只标注了代表韵母:
- a 包括了 ia 和 ua
- ai 包括了 uai
- ao 包括了 iao
- an 包括了 ian, uan, üan
- ang 包括了 iang, uang
- e 包括了 ie, üe
- ei 包括了 uei
- en 包括了 in, uen, ün
- eng 包括了 ing 和 er
- o 包括了 uo
- ong 包括了 iong
- ou 包括了 iou
- u 包括了 ü
在写诗、写歌词的时候,这些韵母通常是可以互相押韵的,所以将它们合并在一起非常直观。编码时,只需要考虑声母和去掉介音的韵母即可,如
- zhuang4 = zh + ang4 → `oa`
- lian2 = l + an2 → `ix`
## 第三四码:二笔
依照 12 个灰色的键进行编码。
对于独体字,第三码取整个字的「特征」,无第四码;对于合体字,先将字分为两半,第三码取第一部分的「特征」,第四码取第二部分的「特征」。「特征」的意思是,如果键盘图上有相应的字根,则取字根;如无字根,但有该字或部分的前两笔,则取两笔;如只有一笔,则取两次该一笔作为两笔。最后,将取得的字根或两笔在键盘图上找到相应的按键。
例:
- 生:独体字,取前两笔「撇横」,第三码为 `m`,无第四码。
- 萧:合体字,第一部分为「艹」,取前两笔「横竖」,第三码为 `y`;第二部分为肃,取前两笔「折横」,第四码为 `t`。
- 旧:合体字,第一部分为「丨」只有一笔,取两次为「竖竖」,第三码为 `a`;第二部分为「日」,为字根,第四码为 `b`。
在将合体字分为两半的过程中,可能会遇到一些歧义,此时可以用以下的规则辅助判断:
> 总体原则:结构依据 > 读音依据 > 字形依据
1. 结构依据:典型的上下/左右/包围结构,自然拆分。具有框架性质的字,二分为框架/非框架部分,如「爽」=「大」+其余部分。
2. 读音依据:形声字按形旁/声旁拆分。界限不明时以有读音的部件作为第二部分的开始。
3. 字形依据:有常用部件者拆出该部件,如「弟」拆分为「丷」+下面部分;否则不拆分,算独体字,如「承」。
# 进阶规则
## 无理码
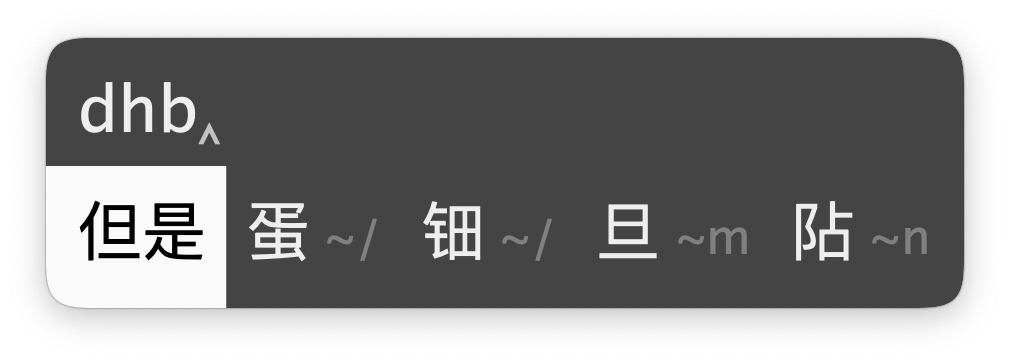
无理码是针对字频前 300 字中的 120 字设置的特殊编码,均为 2 码,主要用于提升打字手感和降低码长。打正常的编码(全码)时可以提示无理码。如:

这表示长可以用 `xm` 打出。
除了几个最高频的字之外,所有无理码的第一码都不变(仍然是该字的声母),并且其中有一些是取了声母和形码,因此并不难于记忆。
## 简码词
1. 极常用的词,一共有30多个,声母+空格或声母+声母两键打出。
2. 次常用的词,可以用第一字前两码和第二字的第三码(第一个形码)打出。适当打打这种三键词可以降低码长。

## 全码词
为了解决一些生僻词语不容易想到字形的问题,设置了一种只使用音码来打词语的办法,规则是取第一字前两码+末字前两码,但第三码需要用大写字母,以便不和二码顶冲突。

## 拼音反查
`a` 键引导,然后输入拼音,可反查落萧双拼编码(需要首先安装 Rime 的 [`pinyin_simp`](https://github.com/rime/rime-pinyin-simp) 方案)。

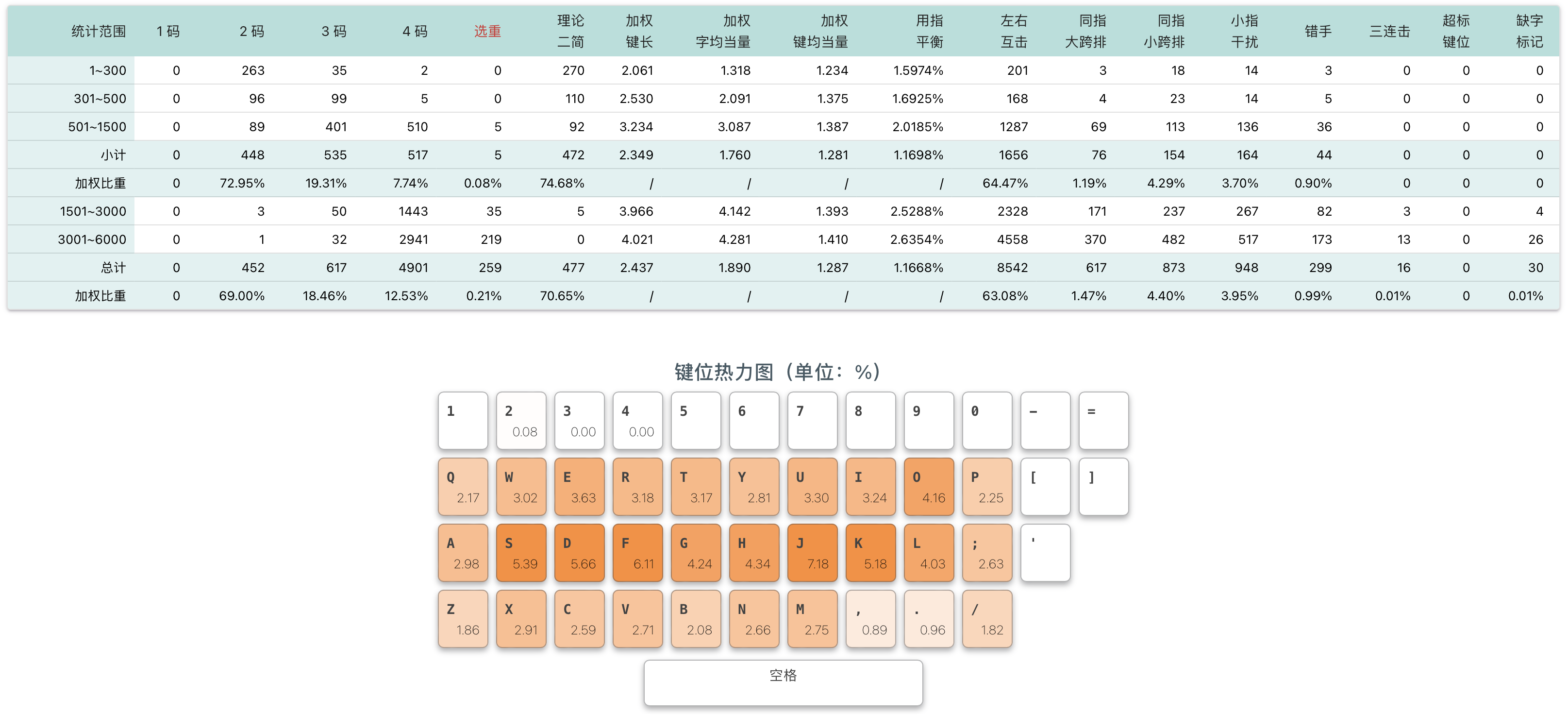
# 测评