Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/tansongchen/xxm
小兮码
https://github.com/tansongchen/xxm
Last synced: about 2 months ago
JSON representation
小兮码
- Host: GitHub
- URL: https://github.com/tansongchen/xxm
- Owner: tansongchen
- License: gpl-3.0
- Created: 2024-03-29T01:08:47.000Z (9 months ago)
- Default Branch: main
- Last Pushed: 2024-04-05T02:31:57.000Z (9 months ago)
- Last Synced: 2024-10-19T09:55:26.112Z (3 months ago)
- Size: 809 KB
- Stars: 4
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 小兮码
配方: ℞ **xxm**
小兮码是百度贴吧用户「7星校尉」和「mgcgogo」于 2015 年研发的音形二笔单字顶功输入方案。本仓库中存放的是经过个人改编之后的版本,与原版有一定的区别。
# 键盘图
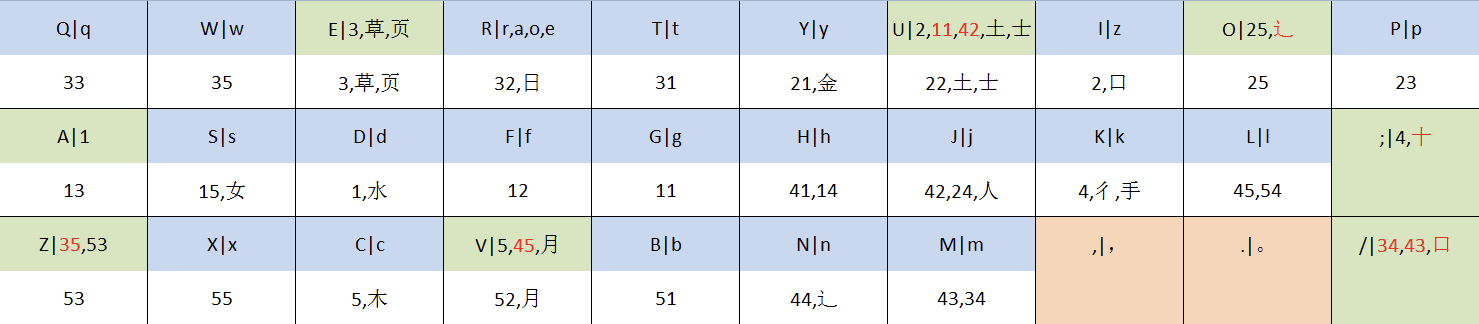
# 编码规则
## 第一码:拼音首字母
依照 20 个蓝色的键编码。其中,首字母为 aoe 的移位至 `r`,为 z 的移位至 `i`。
---
取完第一码后,我们需要开始拆分汉字,然后根据得到的各个部分来继续编码。我们将一个字拆分最多两次:
- 第一次将一个字拆成两半(得到的分别称为首部和次部),如:字 = 宀 + 子,哲 = 折 + 口,简 = 竹 + 间,如不能拆分,则称为独体字。反之,则称为合体字。
- 若该字是合体字,第二次将拆出的两半的后半部分再次拆成两半(得到的分别称为次首部和次次部),如:简 = 竹 + 门 + 日。如不能拆分,则称为不可再分的合体字。反之,称为可以再分的合体字。
## 第二码:首部的编码
依照26个白色的键进行编码。如果键盘图上有该部分的首字根,则取字根的编码;如无字根,但有该部分的前两笔,则取两笔的编码;如取不到两笔,则取该部分的第一笔的编码。简便起见,键盘图中用12345代替横竖撇点折。例:
- 说:首部是讠,前两笔为点折(45),编码为 `l`,前两码为 `sl`。
- 旧:首部是丨,只有一笔为竖(2)(取不到两笔),编码为 `i`,前两码为 `ji`。
- 好:首部是女,前两笔为折撇(53),但「女」是字根,编码为 `s`,前两码为 `hs`。
- 照:首部是昭,前两笔为竖折(25),但「日」是字根,编码为 `r`,前两码为 `ir`。
## 第三至五码
依照8个绿色的键进行编码。若在编码过程中可以取到两笔,但这8个键上没有写对应的两笔时,取单笔。红色标出了由第二码到第三码发生了位置变化的字根或两笔,需要特别记忆。
- 独体字:第三码为末笔,第四码和第五码重复第三码。
- 不可再分的合体字:第三码为次部的编码,第四码为末笔,第五码重复第四码。
- 可以再分的合体字:第三码为次首部的编码,第四码为次次部的编码,第五码为末笔。
以下为几个示例:
- 末:独体字,取 `;`(末笔 4),重复 `;;`。
- 神:不可再分的合体字,先取 `o`(25),再取 `u`(末笔 2),重复 `u`。
- 修:可以再分的合体字,先取 `z`(35),再取 `e`(3,因为没有 33),再取 `e`(末笔 3)。
## 二分歧义的解决
大多数的字(和字的后部)都能容易地进行二分,但有些字出于各种各样的原因二分界限模糊,故需要另加规则确定。
> 总体原则:结构依据>读音依据>字形依据
### 结构依据
- 典型的上下/左右/包围结构,自然拆分。
- 具有框架性质的字,二分为框架部分/非框架部分,如:爽 = 大 + 其余部分。
- 多个字结构相似的时候,将不同的部分独立出来作为第二部分,如:赢 = 其余部分 + 贝,辩 = 其余部分 + 讠。
- 字中间夹有「冖」、「丨」,或「亠口」相连时,以其为划分界线,如:营 = 艹 + 吕,修 = 亻 + 㣊,京 = 亠 + 口小。
### 读音依据
- 明显提供了字的读音的部件独立出来作为第一或第二部分。
- 有两个或以上部分有读音,以第二读音为次部的起点,如:鹿(广、比有读音)拆分为上面部分 + 比;取第一读音的时候取大优先,如:章 = 音 + 十。
- 只有一部分有读音,以该部分为首部或次部的起点,其余为另外部分,如塞拆分为上面部分 + 土。
### 字形依据
如有常用部件,以常用部首为拆分依据,如弟拆分为丷 + 下面部分;否则不拆分,算独体字,如承。
# 无理码
总数200字左右,先打正码,正码上提示无理码。部分无理码可以通过以下规则帮助记忆:
1. 拼音首字母 + 首部字根(依照绿色键)
如:表 正码 bgz;; 无理码用bu(11)
2. 拼音首字母 + 次部字根(依照白色键)
如:传 正码 cju;; 无理码用cg(11)
3. 拼音首字母 + 次部字根(依照绿色键)
如:然 正码 rw;;; 无理码用r;(4)
4. 首部字根 + 次部字根(依照白色键)
如:音 正码 yhoaa 无理码为hr(41、日)
5. 拼音
如:呢 正码 nivzv 无理码为ne。
6. n + 首部字根(依照白色键)
如:想 正码 xcv;; 无理码为nc。
7. 标点简码:逗号代表横,句号代表点,顿号代表撇,分号代表点横
如:多 正码 dwz;; 无理码为d/。
# 词的输入
## 简码词(码长为 2)
极常用的词,一共有五十多个,两键打出。
## 全码词(码长为 5)
- 两字词:第一字前两码+9+第二字前两码
- 三字词:第一字首码+第二字首码+3+第三字前两码
- 四字及以上词:第一字首码+第二字首码+8+第三字首码+末字首码
注意:单字打法小于等于5键的二字词和单字打法小于等于6键的三字词不收。
# 反查功能
## 拼音反查
`a` 引导输入字的拼音,提示小兮码的编码。
## 二笔反查
`z` 引导,此后按第二、第三和第四码的位置取三个形码,均依照白色键编码,提示该字的拼音。
# 评论与分析
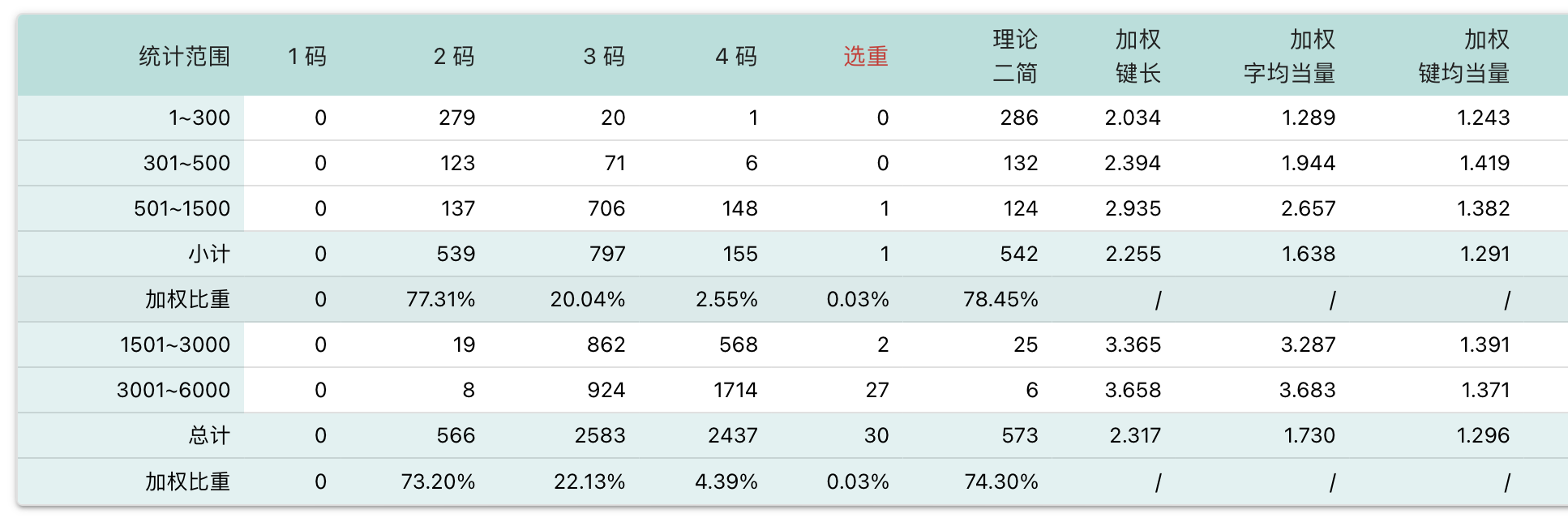
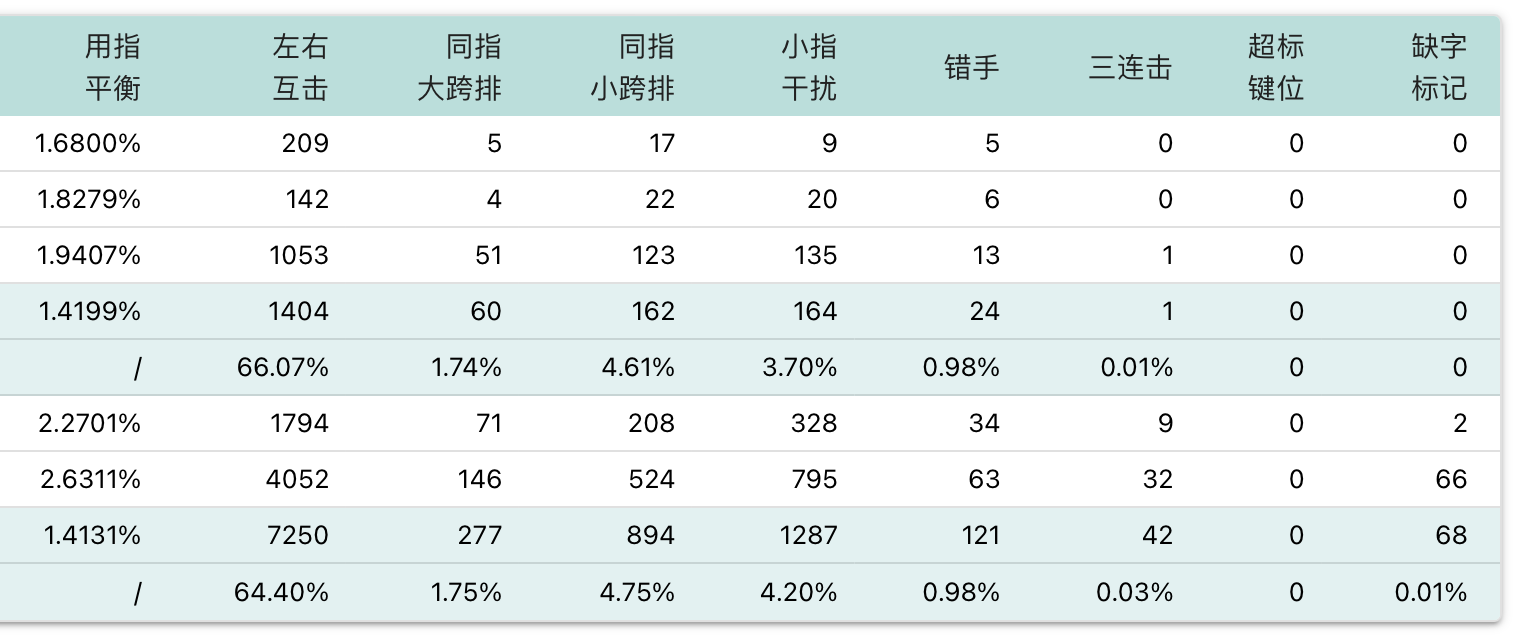
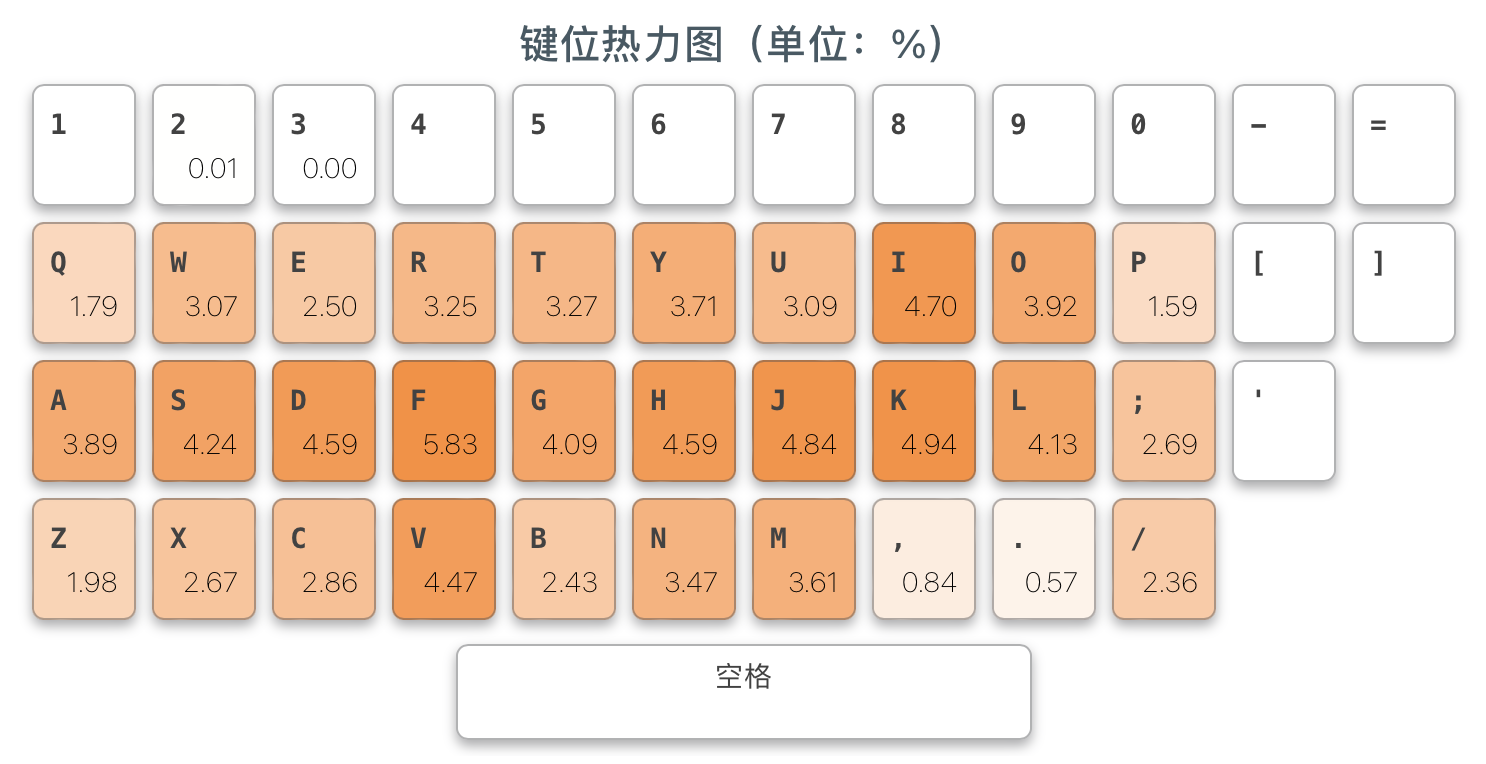
小兮码作为「二码顶功」,与传统四码定长类方案相比有着本质的区别。四码定长类方案中,编码长度最大为 4,除了四码可以自动上屏之外,一、二、三码字都需要空格上屏,因此单字输入的码长在 3.0 左右,比较长。而事实上,中文以字为单位的信息熵约为每字 9 bit,一个 26 键的输入方案每个键的信息量为 4.7 bit,那么单字输入理论上每字只需要 1.9 个键!3.0 比 1.9 多出来的部分,显然是由于一二三级简码要空格才能上屏,空格没承载任何编码信息,所以码长才长。
在小兮码中,第一码(20 键)和第三四五码(8 键)用到的键完全没有重叠的部分。这样一来,输入二码字的两个编码后,继续打下一字第一码时,输入引擎可以判断当前字的编码必然已经结束,由输入引擎将其自动上屏,只留刚打的那一码在候选栏。同样的道理,三码、四码和五码字也不用空格上屏。这样一来,75% 的字可以两键上屏,剩下的字基本上可以三键上屏,使得本方案在单字输入时码长很短(2.30,考虑上标点为 2.17)。
# 参考资料
如想了解更多小兮码的信息,或是对它的制作历程感兴趣,可以参考[贴吧发布贴](http://tieba.baidu.com/p/3485999115)。小兮码的其他版本也在这个贴子里,包括:
- 猎鹞版(链接在第二楼的首条回复)
- mgc 版(链接在第 80 楼,特点是有qp两个一码顶)
- mgc 规范版(也在 80 楼,特点是没有无理码)。