Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/tanujdargan/scraper-uvic-data
https://github.com/tanujdargan/scraper-uvic-data
Last synced: about 2 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/tanujdargan/scraper-uvic-data
- Owner: tanujdargan
- Created: 2024-09-13T07:37:36.000Z (4 months ago)
- Default Branch: main
- Last Pushed: 2024-09-15T07:17:43.000Z (4 months ago)
- Last Synced: 2024-09-15T21:00:18.578Z (4 months ago)
- Language: Python
- Size: 970 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## Overview
A Python script designed to scrape course information from the University of Victoria's Class Schedule Listing (BAN1P). The script fetches and parses key course data, such as term, subject, course name, course number, CRN, section, schedule, instructor, instructional method, units, and additional information. It helps students and developers access course information programmatically.
**Note:** Currently, the script scrapes data from the Class Schedule Listing (BAN1P) for most data. The UVIC Calendar is only used for additional course information (description, notes, pre-requisites, recommendations)
## Table of Contents
- [Installation & Setup](#installation--setup)
- [Usage](#usage)
- [Performance Metrics](#performance-metrics)
- [Output](#output)
- [Detailed Course Information Scraper](#detailed-course-information-scraper)
- [Seat Capacity Data](#seat-capacity-data)
- [Development](#development)
- [Contributing](#contributing)
- [Planned Features](#planned-features)
- [Contact](#contact)
## Installation & Setup
### Prerequisites
- **Python 3.12.2:** Compatibility is tested with Python 3.12.2. While there should be no issues with older or newer versions, compatibility is not guaranteed.
- **Required Packages:**
- `requests`
- `beautifulsoup4`
If you plan to use concurrent requests, you will also need `aiohttp`. You can install the required packages using:
```bash
pip install requests beautifulsoup4 aiohttp
```
### Clone the Repository
To clone the repository, run:
```bash
git clone https://github.com/yourusername/scraper-uvic-data.git
```
### Prepare the Input File
Ensure the input CSV files are in place:
- `./courses-list.csv`: Used to generate URLs for scraping.
- `./data/course-list-test.csv`: A test file for development purposes.
Format of the CSV:
```csv
UVIC Course Description, Subject, Course Number, Course Name
```
For development, use the test file. Otherwise, leave the default file as is.
## Usage
Navigate to the directory containing the script and run one of the following scraper scripts based on your needs:
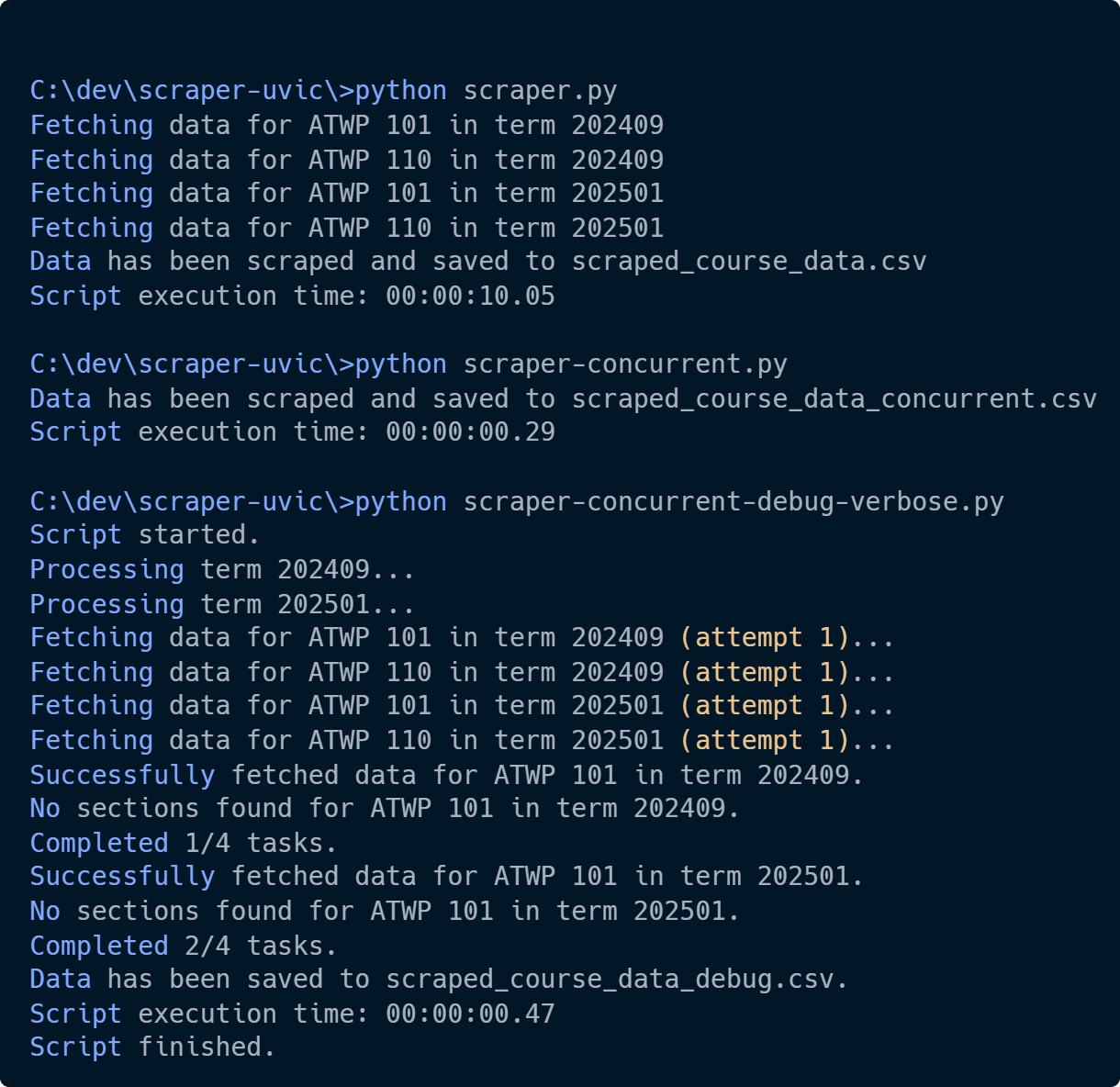
1) **scraper.py** (Conservative approach, no concurrency, slowest):
```bash
python scraper.py
```
*Test File Timing: 10,050 ms*
2) **scraper-concurrent.py** (Fastest, up to 10 concurrent requests, no verbose output):
```bash
python scraper-concurrent.py
```
*Test File Timing: 29 ms*
3) **scraper-concurrent-debug-verbose.py** (Same as concurrent, but includes verbose console output):
```bash
python scraper-concurrent-debug-verbose.py
```
*Test File Timing: 47 ms*
*Note: Script runtimes may vary based on hardware and UVIC server load.*
### Performance Metrics
## Output
The scraped course data will be saved in `scraped_course_data.csv`, with columns such as:
- `term`, `subject`, `course_name`, `course_number`, `crn`, `section`, `schedule`, `instructor`, `instructional_method`, `units`, and `additional_information`.
You can stop the script at any time by pressing the `q` key.
## Detailed Course Information Scraper
To fetch detailed course information from the UVIC Undergraduate Calendar, use the scraper located at `./description/scraper-calendar.py`.
Download the course information as a JSON file from the following Kuali link before running the scraper:
- [Kuali Course Information](https://uvic.kuali.co/api/v1/catalog/courses/65eb47906641d7001c157bc4/)
To fetch individual course information, modify the request URL by appending the course's `pid` to the endpoint.
## Seat Capacity Data
A separate script for scraping seat capacity data is available, though it is inefficient due to frequent data changes. Automating this process can be resource-intensive and inaccurate over time.
The seat capacity scraper is located under `./seat-capacity`, and the initial scraped data (as of 15/10/2024) is available in the corresponding CSV.
Script execution time:
```bash
Completed 5321/5321 tasks.
Data saved to course_capacity_data.csv.
Execution time: 00:03:27.49
```
## Development
This project is open for improvements. Feel free to fork the repository, make changes, and submit pull requests.
### Future Enhancements
- Adding class capacity and waitlist data.
- Improving performance and optimization.
## Contributing
Contributions are welcome! Here's how to contribute:
1. **Fork the repository**.
2. **Clone your fork** locally.
3. **Create a feature branch** for your changes.
4. Submit a **pull request** with your improvements.
## Planned Features
- Integration of seat capacity and waitlist data.
- API implementation for regular data updates and MongoDB integration.
## Contact
For questions or feedback, please open an issue in this repository or reach out via email.