https://github.com/taojy123/sqlx
强大的 SQL 语法拓展,目标是打造 "易读易写 方便维护" 的 sql 脚本 | SQL Extension
https://github.com/taojy123/sqlx
database sql sql-extension sqlx
Last synced: about 1 year ago
JSON representation
强大的 SQL 语法拓展,目标是打造 "易读易写 方便维护" 的 sql 脚本 | SQL Extension
- Host: GitHub
- URL: https://github.com/taojy123/sqlx
- Owner: taojy123
- License: mit
- Created: 2019-10-23T03:10:26.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2020-04-10T15:16:21.000Z (over 6 years ago)
- Last Synced: 2025-04-17T22:44:16.949Z (about 1 year ago)
- Topics: database, sql, sql-extension, sqlx
- Language: Python
- Homepage:
- Size: 186 KB
- Stars: 29
- Watchers: 3
- Forks: 7
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# sqlx
SQL Extension
强大的 SQL 语法拓展,目标是打造 "易读易写 方便维护" 的 sql 脚本
## 应用场景
假设有一张商品价目表(product),每天价格变动的商品都会更新报价。
例如,苹果的最新价格为 10 元, 因为苹果最新的一次报价是在 20191211, 当时价格为 10 元。
name(商品名称)|price(价格)|date(报价日期)
-|-|-
苹果|15|20191208
香蕉|18|20191208
橘子|12|20191208
香蕉|16|20191209
橘子|11|20191209
苹果|11|20191210
橘子|13|20191210
苹果|10|20191211
香蕉|22|20191211
橘子|14|20191212
现在要求通过 sql 统计出 `20191212 这天的平均价格 比 20191209 那天涨了多少` ?
正常情况下我们可能会写出这样的 sql
```sql
SELECT
a1.avg_price AS `20191209 平均价格`,
a2.avg_price AS `20191212 平均价格`,
(a2.avg_price - a1.avg_price) AS `涨价金额`
FROM
(
-- 求出各类别 20191209 前最后一次报价的平均价格
SELECT
avg(product.price) AS avg_price
FROM
(
-- 求出各商品在 20191209 前最后一次报价的日期
SELECT
name,
max(date) AS max_date
FROM
product
WHERE
date <= '20191209'
GROUP BY
name
) AS t1
LEFT JOIN product
ON t1.name = product.name AND t1.max_date = product.date
) AS a1
LEFT JOIN
(
-- 再求出各类别 20191212 前最后一次报价的平均价格
SELECT
avg(product.price) AS avg_price
FROM
(
-- 先求出各商品在 20191212 前最后一次报价的日期
SELECT
name,
max(date) AS max_date
FROM
product
WHERE
date <= '20191212'
GROUP BY
name
) AS t2
LEFT JOIN product
ON t2.name = product.name AND t2.max_date = product.date
) AS a2
ON true
```
得到统计结果如下:
20191209 平均价格|20191212 平均价格|涨价金额
-|-|-
14.0000|15.3333|1.3333
传统做法虽然得到的结果是正确的,但同时暴露出以下问题:
1. 子查询多层嵌套,代码可读性极低
2. `t1` `t2` 两个子查询内容基本一致,也就说我们要维护两处相同的代码
3. `a1` `a2` 两个子查询也基本一致,并且其中相同的注释我们要写两遍,感觉太"蠢"了
4. 这只是个很简单的示例,在实际工作中,针对更复杂的统计需求,代码的复杂度将会以指数形式递增
下面看看如何使用 sqlx 来解决上述问题:
```sql
func product_max_date(day)
-- 子查询: 统计出各个商品在 {day} 前最后一次报价的日期
(
SELECT
name,
max(date) AS max_date
FROM
product
WHERE
date <= '{day}'
GROUP BY
name
)
end
func date_avg_price(day):
-- 子查询: 统计出 {day} 这天各个类别的平均价格
(
SELECT
avg(product.price) AS avg_price
FROM
{product_max_date($day)} AS t1
LEFT JOIN product
ON t1.name = product.name AND t1.max_date = product.date
)
end
SELECT
a1.avg_price AS `20191209 平均价格`,
a2.avg_price AS `20191212 平均价格`,
(a2.avg_price - a1.avg_price) AS `涨价金额`
FROM
{date_avg_price(20191209)} AS a1
LEFT JOIN
{date_avg_price(20191212)} AS a2
ON true
```
优势非常明显:
1. 核心代码是一段短小的 `SELECT`,外加两个子查询的定义就搞定了,代码逻辑清晰,可读性高
2. `a1` `a2` 使用类似 `函数` 的概念进行封装,通过传入不同的参数来生成不同的子查询内容
3. 相同逻辑的代码片段只需要写一遍,大大降低了代码维护的工作量
4. 使用 sqlx 提供的编译工具或插件,可快速编译成 sql 代码,在数据库中执行结果一致
## 语法简介
### 1. 通过 `var` 定义变量,可在脚本中反复引用
示例:
```sql
var field_name = age
var field_value = 30
SELECT {field_name} from students WHERE {field_name} < {field_value};
SELECT {field_name} from teachers WHERE {field_name} > {field_value};
```
编译生成 sql 为:
```sql
SELECT age from students WHERE age < 30;
SELECT age from teachers WHERE age > 30;
```
### 2. 通过 `func` 定义脚本片段,并反复引用
示例:
```sql
-- ! 定义片段
func good_students(score):
(
SELECT
*
FROM
students
WHERE
score > {score}
) AS good_students
end
SELECT name FROM {good_students(80)};
SELECT count(*) FROM {good_students(80)};
```
编译生成 sql 为:
```sql
SELECT name FROM
(
SELECT
*
FROM
students
WHERE
score > 80
) AS good_students
;
SELECT count(*) FROM
(
SELECT
*
FROM
students
WHERE
score > 80
) AS good_students
;
```
### 3. 循环
通过 `for` 批量循环生成脚本(暂不支持循环嵌套)
示例1:
```sql
{% for n in table1,table2,table3 %}
SELECT * FROM {n};
{% endfor %}
```
编译生成 sql 为:
```sql
SELECT * FROM table1;
SELECT * FROM table2;
SELECT * FROM table3;
```
示例2:
```sql
{% for n|m in table1|id,table2|name,table3|age %}
SELECT {m} FROM {n};
{% endfor %}
```
编译生成 sql 为:
```sql
SELECT id FROM table1;
SELECT name FROM table2;
SELECT age FROM table3;
```
### 4. 判断
通过 `if` 生成逻辑分支脚本(暂不支持 if 嵌套)
示例1:
```sql
var a 8
{% if $a > 4 %}
SELECT * FROM table1;
{% endif %}
```
编译生成 sql 为:
```sql
SELECT * FROM table1;
```
示例2:
```sql
{% for n in table1,table2,table3 %}
{% if $n == table1 %}
SELECT id, name FROM {n};
{% else %}
SELECT * FROM {n};
{% endif %}
{% endfor %}
```
编译生成 sql 为:
```sql
SELECT id, name FROM table1;
SELECT * FROM table2;
SELECT * FROM table3;
```
更多示例可参考 [demo.sqlx](https://github.com/taojy123/sqlx/blob/master/demo.sqlx)
### 5. 处理 `{` `}` 字符
如果你需要在生成的 sql 内容中包含 `{` `}` 这样的字符,不能直接在 sqlx 中写 `{` 或 `}`,因为这样会被认为是变量引用的起止标记
你需要在这些字符前加上一个转义符(默认是`\`),如 `\{` `\}` 这样即可
示例:
```sql
var cc dd
SELECT * FROM table1 WHERE name = 'aa\{bb\}{cc}'
```
编译生成 sql 为:
```sql
SELECT * FROM table1 WHERE name = 'aa{bb}dd'
```
### 6. 使用 `import` 导入模块
通过 import 可以引入现有的 sqlx 脚本文件作,但只能导入其中的 var 和 func
如果在当前脚本有重复同名变量或 func,会被覆盖以当前脚本为准
示例:
```sql
-- mod.sqlx
var colume name
var colume2 score
func good_students(score):
(
SELECT
*
FROM
students
WHERE
score > {score}
) AS good_students
end
```
```sql
import mod
var colume2 age
SELECT {colume} from teachers WHERE {colume2} > 10;
SELECT name FROM {good_students(60)};
SELECT count(*) FROM {good_students(80)};
```
编译生成 sql 为:
```sql
SELECT name from teachers WHERE age > 10;
SELECT name FROM
(
SELECT
*
FROM
students
WHERE
score > 60
) AS good_students
;
SELECT count(*) FROM
(
SELECT
*
FROM
students
WHERE
score > 80
) AS good_students
;
```
-------
## 安装使用
Windows 64位系统,可以直接下载 [sqlx.exe](https://github.com/taojy123/sqlx/releases)
双击运行,即可将当前目录下的 `sqlx 脚本文件 `编译为 `sql`, 放置于 `dist` 目录中。
-------
## 使用 Sublime Text 插件
Sqlx 插件已被 `Sublime Text` 官方收录。
可搜索安装 `Sqlx Builder` 插件,在 Build System 中选择 `Sqlx`,可快捷将 sqlx 脚本编译为 sql。
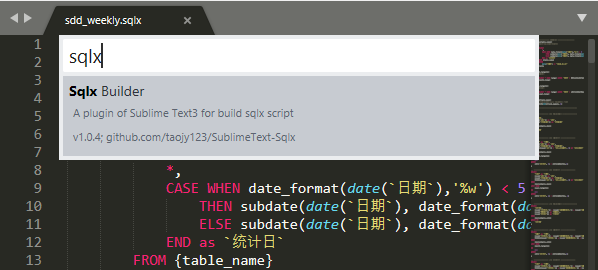
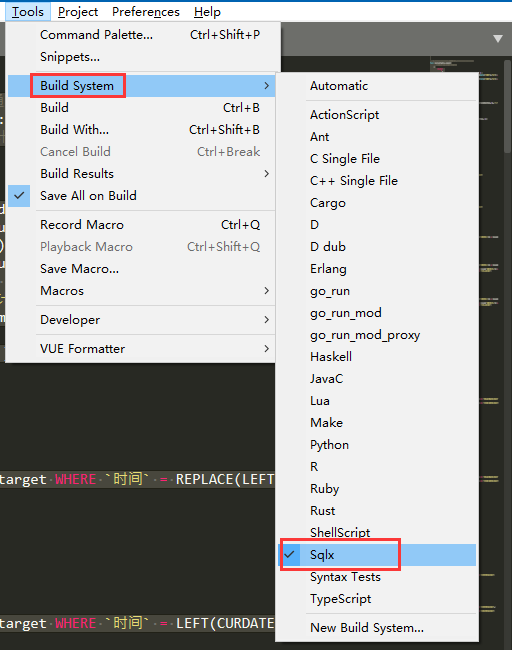
-------
## 其他系统平台,可通过 Python3 安装使用
如果你的系统无法运行 `sqlx.exe`,可以先安装 [Python3](https://www.python.org/downloads/),然后使用 `pip` 命令一键安装
```
pip install sqlx
```
### 使用 `sqlx` 命令行工具
1. 安装后直接执行 `sqlx` 命令,可一键编译当前目录下的所有 `.sqlx 脚本文件`
```
$ ls
test1.sqlx test2.sqlx
$ sqlx
dist/test1.sql built
dist/test2.sql built
Finish!
$ ls dist
test1.sql test2.sql
```
2. `sqlx` 命令后跟随目录路径参数,可编译指定路径下的所有脚本
```
$ ls test
test3.sqlx test4.sqlx
$ sqlx ./test/
test/dist/test3.sql built
test/dist/test4.sql built
Finish!
$ ls test/dist
test3.sql test4.sql
```
3. `sqlx` 命令后跟随文件路径参数,可编译指定的单个脚本
```
$ sqlx ./test/test3.sqlx
test/dist/test3.sql built
Finish!
$ ls test/dist
test3.sql
```
### 在 Python3 程序中使用 `sqlx.build` 方法
```python
import sqlx
my_script = """
{% for n in table1,table2,table3 %}
{% if $n == table1 %}
SELECT id, name FROM {n};
{% else %}
SELECT * FROM {n};
{% endif %}
{% endfor %}
"""
sql = sqlx.build(my_script, pretty=True)
print(sql)
```
-------
## 版本更新说明
### v0.2.0
为提高脚本书写体验,变更了语法关键词
- `define` 改成 `var`
- `block .. endblock` 改成 `func .. end`
老版本语法目前依旧兼容
### v0.1.1
第一个可用版本发布
- 支持 `escape` (默认`\`)
- 自动复制编译后的 `sql` 进剪切板
- 支持 import 导入 sqlx 脚本模块
### v0.1.0
第一个可用版本发布
- 支持 `var` 语法
- 支持 `func` 语法
- 支持 `for` 语法
- 支持 `if` 语法