https://github.com/techn0man1ac/toxiccommentclassification
This project aims to develop a model capable of identifying and classifying different levels of toxicity in comments, using the power of BERT(Bidirectional Encoder Representations from Transformers) for text analysis.
https://github.com/techn0man1ac/toxiccommentclassification
analysis bert-model classifying data-science docker machine-learning python streamlit text-classification transformers-models
Last synced: 11 months ago
JSON representation
This project aims to develop a model capable of identifying and classifying different levels of toxicity in comments, using the power of BERT(Bidirectional Encoder Representations from Transformers) for text analysis.
- Host: GitHub
- URL: https://github.com/techn0man1ac/toxiccommentclassification
- Owner: techn0man1ac
- License: mit
- Created: 2024-12-19T19:36:41.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-01-06T23:28:33.000Z (over 1 year ago)
- Last Synced: 2025-01-06T23:37:13.697Z (over 1 year ago)
- Topics: analysis, bert-model, classifying, data-science, docker, machine-learning, python, streamlit, text-classification, transformers-models
- Language: Jupyter Notebook
- Homepage:
- Size: 3.79 MB
- Stars: 6
- Watchers: 1
- Forks: 0
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Toxic Comment Classification system by "Team 16.6" 🛡️

In the modern era of social media, toxicity in online comments poses a significant challenge, creating a negative atmosphere for communication. From abuse to insults, toxic behavior discourages the free exchange of thoughts and ideas among users.
This project seeks to address this issue by developing a machine learning model to identify and classify varying levels of toxicity in comments. Leveraging the power of BERT (Bidirectional Encoder Representations from Transformers), this system aims to:
- Analyze text for signs of toxicity
- Classify toxicity levels effectively
- Support moderators and users in fostering healthier and safer online communities
- By implementing this technology, the project strives to make social media a more inclusive and positive space for interaction.
# 🤝 Team
`Team 16.6` means that each member has an equal contribution to the project ⚖ .
The project was divided into tasks, which in turn were assigned to the following roles:
`Desing director` - [Polina Mamchur](https://github.com/polinamamchur)
`Data science` - [Olena Mishchenko](https://github.com/Alena-Mishchenko)
`Backend` - [Ivan Shkvyr](https://github.com/IvanShkvyr), [Oleksandr Kovalenko](https://github.com/AlexandrSergeevichKovalenko)
`Frontend` - [Oleksii Yeromenko](https://github.com/oleksii-yer)
`Team Lead` - [Serhii Trush](https://github.com/techn0man1ac)
`Scrum Master` - [Oleksandr Kovalenko](https://github.com/AlexandrSergeevichKovalenko), [Polina Mamchur](https://github.com/polinamamchur)
# 🎨 Desing
The project started with design development. First, design a [prototype of user interface](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/design/Pages) was developed:
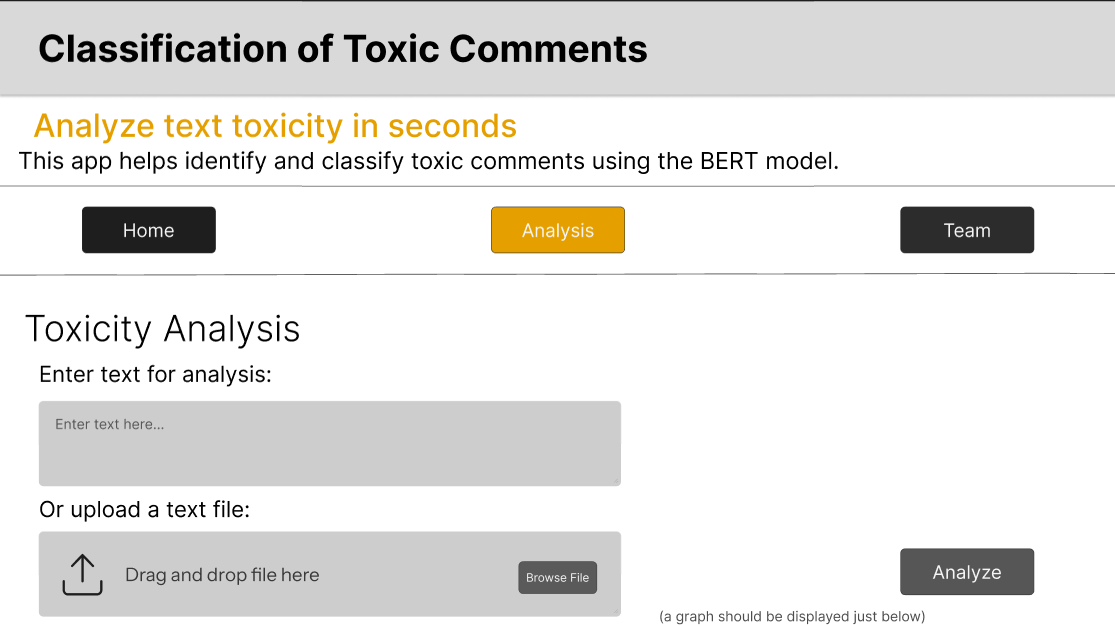
Creative director create a visually appealing application, as well as to ensure the presentation of the project to stakeholders. By focusing on both UI/UX and presentation design was able to bring the team's vision to life and effectively communicate the [value of the project](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/design).
A presentation on the project has been developed and can be viewed here(in PDF format):
https://github.com/techn0man1ac/ToxicCommentClassification/blob/main/design/Presentation/ToxicCommentClassification.pdf
# 🛠️ Technologies
- 🖼️ [Figma](https://www.figma.com/): Online interface development and prototyping service with the ability to organize collaborative work
- 🐍 [Python](https://www.python.org/): The application was developed in the [Python 3.11.8](https://www.python.org/downloads/release/python-3118/) programming language
- 🤗 [Transformers](https://huggingface.co/docs/transformers/index): A library that provides access to BERT and other advanced machine learning models
- 🔥 [PyTorch](https://pytorch.org/): Libraries for working with deep learning and support GPU computing
- 📖 [BERT](https://en.wikipedia.org/wiki/BERT_(language_model)): A text analysis model used to produce contextualized word embeddings
- ☁️ [Kaggle](https://www.kaggle.com/): To save time, we used cloud computing to train the models
- 🌐 [Streamlit](https://streamlit.io/): To develop the user interface, used the Streamlit package in the frontend
- 🐳 [Docker](https://www.docker.com/): A platform for building, deploying, and managing containerized applications
# 🖥 Data Science
Work was performed on dataset research and data processing to train machine learning models.
## 📊 Dataset(EDA)
To train the machine learning models, we used [Toxic Comment Classification Challenge](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/) dataset.
The dataset have types of toxicity:
- Toxic
- Severe Toxic
- Obscene
- Threat
- Insult
- Identity Hate
The primary datasets (`train.csv`, `test.csv`, and `sample_submission.csv`) are loaded into [Pandas](https://pandas.pydata.org/) `DataFrames`.
After that make [Exploratory Data Analysis](https://github.com/techn0man1ac/ToxicCommentClassification/blob/main/Data_science/data_science.ipynb) of dataframes and obtained the following results:
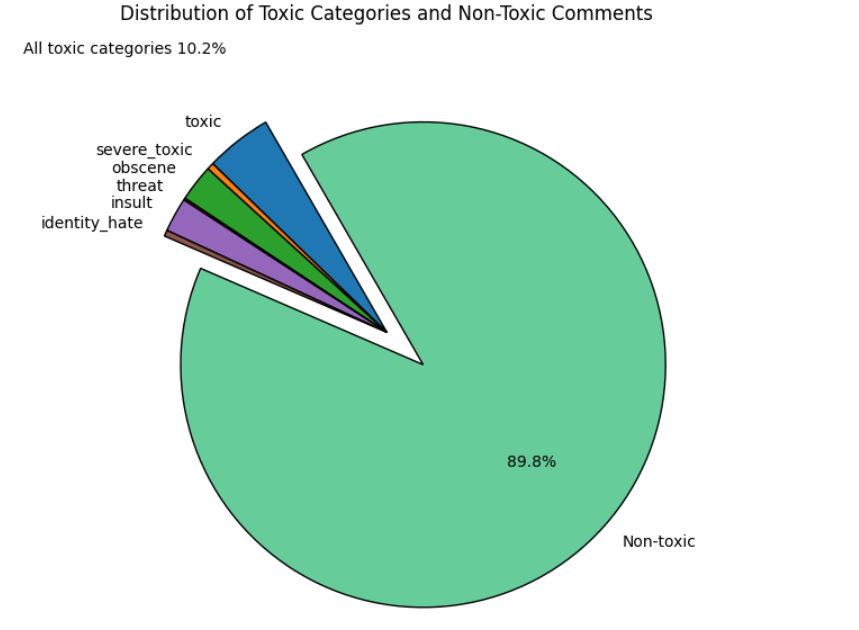
As you can seen from the data analysis, there is an `imbalance of classes` in the ratio of 1 to 10 (toxic/non-toxic).
Distribution of classes:
| Class | Count | Percentage |
|-----------------------------------------|-------------|-----------------|
| Toxic | 15,294 | 9.58% |
| Severe Toxic | 1,595 | 1.00% |
| Obscene | 8,449 | 5.29% |
| Threat | 478 | 0.30% |
| Insult | 7,877 | 4.94% |
| Identity Hate | 1,405 | 0.88% |
| Non-toxic | **143,346** | **89.83%** |
| Total comments | 159,571 | |
| Multiclass comments vs Total comments | 18,873 | 11.8% |
As you can see, this table shows that there is multiclassing in the data, the data of one category can belong to another category.
Here is a visualization of the data from the dataset research. Dataset in bargraph representation:

Graphs show basic information about the dataset to understand the size and types of columns. Such a ratio in the data will have a very negative impact on the model's prediction accuracy.
## 📅 Data processing

Because the original dataset includes data imbalances, this will have a bad impact on the accuracy of machine learning models, so we applied oversampling using the [Sklearn](https://scikit-learn.org/) package(`resample` function) - copying data while maintaining the balance of classes to increase the importance in the context of models recognition of a particular class.
| Class | Original dataset | Data processing | Persentage about original |
|----------------|------------------|-----------------|---------------------------|
| Toxic | 15,294 | 40,216 | +262% |
| Severe Toxic | 1,595 | 16,889 | +1058% |
| Obscene | 8,449 | 38,009 | +449% |
| Threat | 478 | 16,829 | +3520% |
| Insult | 7,877 | 36,080 | +458% |
| Identity Hate | 1,405 | 19,744 | +1405% |
| None toxic | 143,346 | 143,346 | 0% |
| Total | 178,444 | 269,396 | +51% |
As a result, after processing the data, the balance of toxic and non-toxic for each class was ~50/50%. Thanks to this [data processing](https://github.com/techn0man1ac/ToxicCommentClassification/blob/main/Backend/Models/Model_0_bert-base-uncased/FOR_PROJECT_BERT_oversampling_with_optuna_correct_oversampling.ipynb), the accuracy of pattern recognition has increased by several percent.
# ⚙️ Machine learning(Back End)
To solve the challenge, we have chosen 3 popular architectures, such as [BERT](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/Backend/Models/Model_0_bert-base-uncased), [DistilBERT](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/Backend/Models/Model_2_distilbert), [ALBERT](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/Backend/Models/Model_1_albert), each link takes you to the source code as trained by the model.
Here is a visual representation of the main parameters of the models:
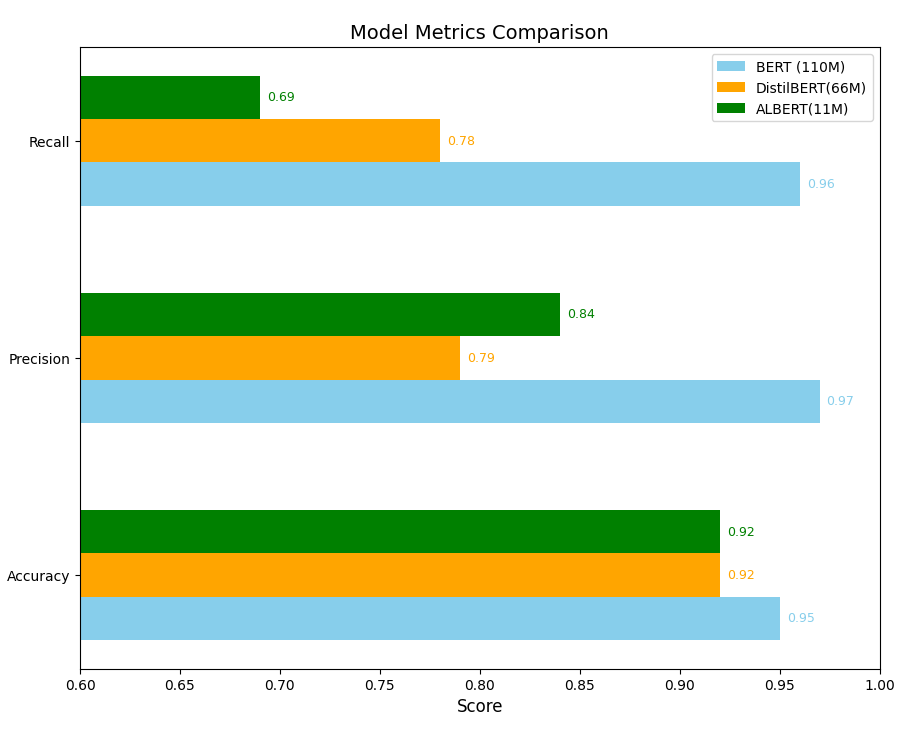
Here is a detailed description of each of the machine learning models we trained:
## BERT ֎
This project demonstrates toxic comment classification using the [bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) model from the BERT family. To automate the process of selecting hyperparameters, hepl us [Optuna](https://optuna.org/).
### 1. **Toxic Comment Classification with BERT**
- Utilized the `bert-base-uncased` model with PyTorch for flexibility and ease of use.
- Seamlessly integrated with Hugging Face Transformers.
- Training accelerated by ~30x using a GPU, efficiently handling BERT’s computational demands.
### 2. **Dataset Balancing**
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using oversampling with `sklearn`.
- Ensured rare toxic categories received equal attention by balancing class distributions.
- Improved model performance in recognizing rare toxic classes.
### 3. **Key Techniques**
- **Tokenization**: Preprocessed data tokenized using `BertTokenizer`.
- **Loss Function**: Used `BCEWithLogitsLoss` with weighted loss for rare class emphasis.
- **Gradient Clipping**: Optimized training stability with gradient clipping (`max_norm`).
- **Hyperparameter Tuning**: Tuned batch size, learning rate, and epochs using Optuna.
### 4. **Threshold Optimization**
- Used `itertools.product` to find optimal thresholds for each class.
- Improved recall and F1-score (by 1-1.5%) for better multi-label classification.
### 5. **Performance and Key Model Details**
- **Validation Metrics**:
- Accuracy: 0.95 ✅
- Precision: 0.97 ✅
- Recall: 0.96 ✅
- **Model Specifications**:
- Vocabulary Size: 30,522
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 12
- Total Parameters: 110M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP).
## DistilBERT ֎
This project demonstrates toxic comment classification using the [distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) model, a lightweight and efficient version of BERT.
### 1. Using PyTorch
- Selected for its flexibility, ease of use, and strong community support.
- Seamlessly integrated with Hugging Face Transformers.
### 2. Dataset Balancing
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using `sklearn.utils.resample`.
- Applied stratified splitting for training and test datasets.
- Oversampled rare toxic classes, improving model recognition of all categories.
### 3. Key Techniques
- **Tokenization**: Preprocessed data with `DistilBertTokenizer`.
- **Loss Function**: Binary Cross-Entropy with Logits (`BCEWithLogitsLoss`).
- **Hyperparameter Tuning**: Optimized batch size (`16`), learning rate (`2e-5`), and epochs (`3`) with Optuna.
### 4. Accelerated Training
- Utilized GPU for training, achieving a ~30x speedup over CPU.
### 5. Threshold Optimization
- Used `itertools.product` to determine optimal thresholds for each class.
- Improved recall and F1-score for multi-label classification.
### 6. **Performance and Key Model Details**
- **Validation Metrics**:
- Accuracy: 0.92 ✅
- Precision: 0.79 ✅
- Recall: 0.78 ✅
- **Model Specifications**:
- Vocabulary Size: 30522
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 6
- Total Parameters: 66M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM).
## ALBERT ֎
This project demonstrates toxic comment classification using the [albert-base-v2](https://huggingface.co/albert/albert-base-v2) model, a lightweight and efficient version of BERT designed to reduce parameters while maintaining high performance.
### 1. Using PyTorch
- Selected for its flexibility, ease of use, and strong community support.
- Seamlessly integrated with Hugging Face Transformers.
### 2. Dataset Balancing
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using `sklearn.utils.resample`.
- Applied stratified splitting for training and test datasets.
- Oversampled rare toxic classes to improve model recognition of all categories.
### 3. Key Techniques
- **Tokenization**: Preprocessed data with `AlbertTokenizer`.
- **Loss Function**: Binary Cross-Entropy with Logits (`BCEWithLogitsLoss`).
- **Hyperparameter Tuning**: Optimized batch size (`8`), learning rate (`2e-5`), and epochs (`3`) using Optuna.
### 4. Accelerated Training
- Utilized GPU for training, achieving a ~30x speedup over CPU.
### 5. Threshold Optimization
- Used `itertools.product` to determine optimal thresholds for each class.
- Enhanced recall and F1-score for multi-label classification.
### 6. **Performance and Key Model Details**
- **Validation Metrics**:
- Accuracy: 0.92 ✅
- Precision: 0.84 ✅
- Recall: 0.69 ✅
- **Model Specifications**:
- Vocabulary Size: 30000
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 12
- Intermediate Size: 4096
- Total Parameters: 11M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM).
We used to Cloud computing on [Kaggle](https://www.kaggle.com/code/techn0man1ac/toxiccommentclassificationsystem/) for are speed up model training.
# 💻 How to install
There are two ways to install the application on your computer:
## Simple 😎
Download [Docker](https://www.docker.com/) -> Log in to your profile in the application -> Open the Docker terminal(bottom of the program) -> Enter command:
```
docker pull techn0man1ac/toxiccommentclassificationsystem:latest
```
After that, all the necessary files will be downloaded from [DockerHub](https://hub.docker.com/repository/docker/techn0man1ac/toxiccommentclassificationsystem) -> Go to the `Images` tab -> Launch the image by clicking `Run` -> Click `Optional settings` -> Set the host port `8501`
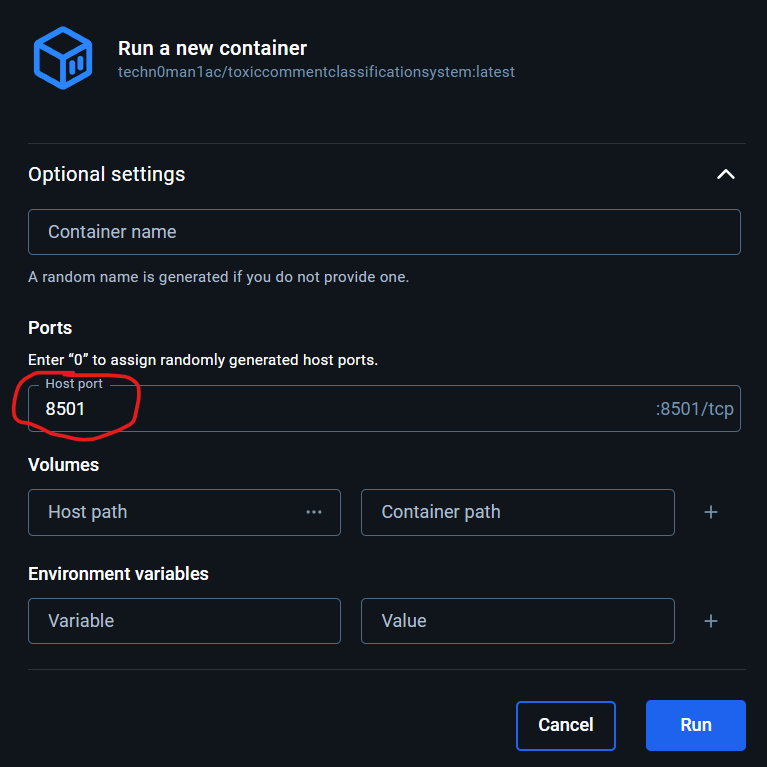
Open http://localhost:8501 in your browser.
## Like a pro 💪
This way need from you, to have some skills with command line, GitHub and Docker.
1. Cloning a repository:
```
git clone https://github.com/techn0man1ac/ToxicCommentClassification.git
```
2. Download the [model files from this link](https://drive.google.com/drive/folders/17kR8llTZ1yNig5xFjrnpLCKyRfQkIwz2?usp=sharing), after downloading the `albert`, `bert` and `distilbert` directories, put them in the `frontend\saved_models` directory, like that:
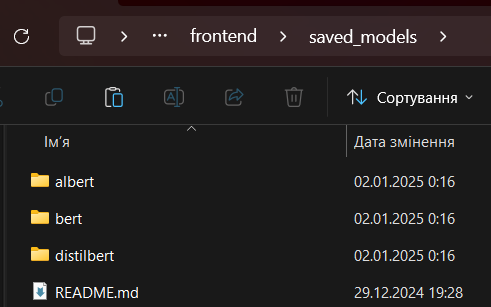
3. Open a command line/terminal and navigate to the `ToxicCommentClassification` directory, and pack the container with the command:
```
docker-compose up
```
4. After which the application will immediately start and a browser window will open with the address http://localhost:8501
To turn off the application, run the command:
```
docker-compose down
```
# 🚀 How to use(Front End)
After launching the application, you will see the project's home tab with a description of the application and the technologies used in it. The program looks like this when running:
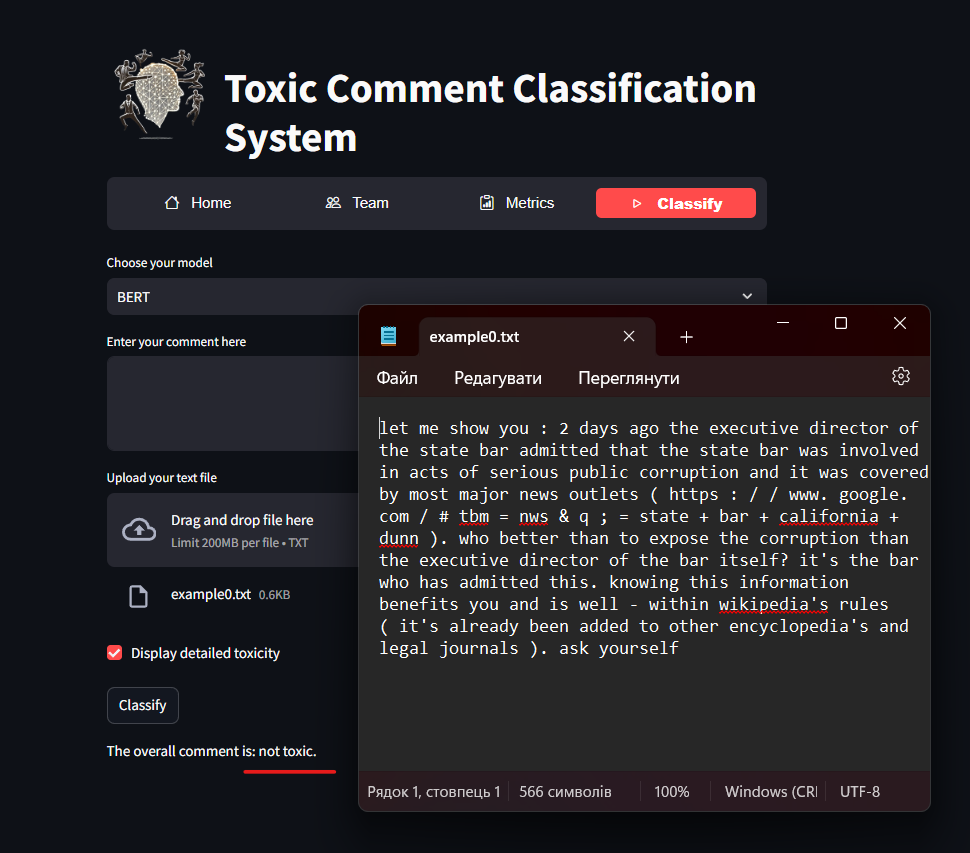
The application interface is intuitive and user-friendly.
The structure of the tabs is as follows:
- `Home` - Here you can find a description of the app, the technologies used for its operation, the mission and vision of the project, and acknowledgments
- `Team` - This tab contains those without whom the app would not exist, its creators
- `Metrics` - In this tab, you can choose one of 3 models, after selecting it, the technical characteristics of each of the machine learning models are loaded
- `Classification` - A tab where you can test the work of models.
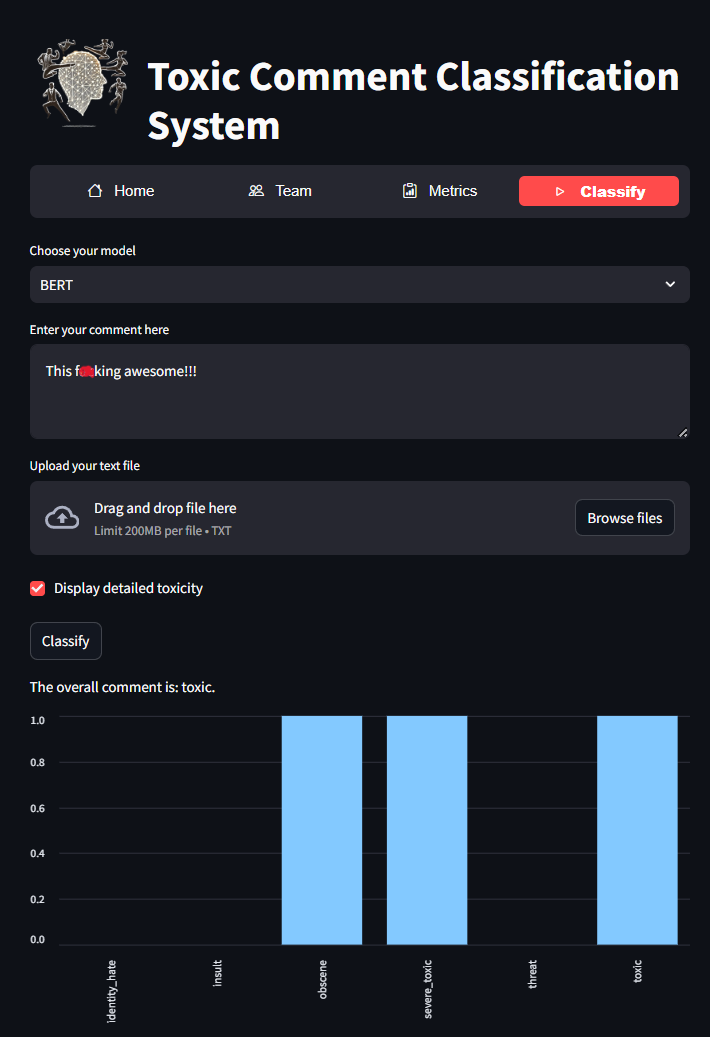
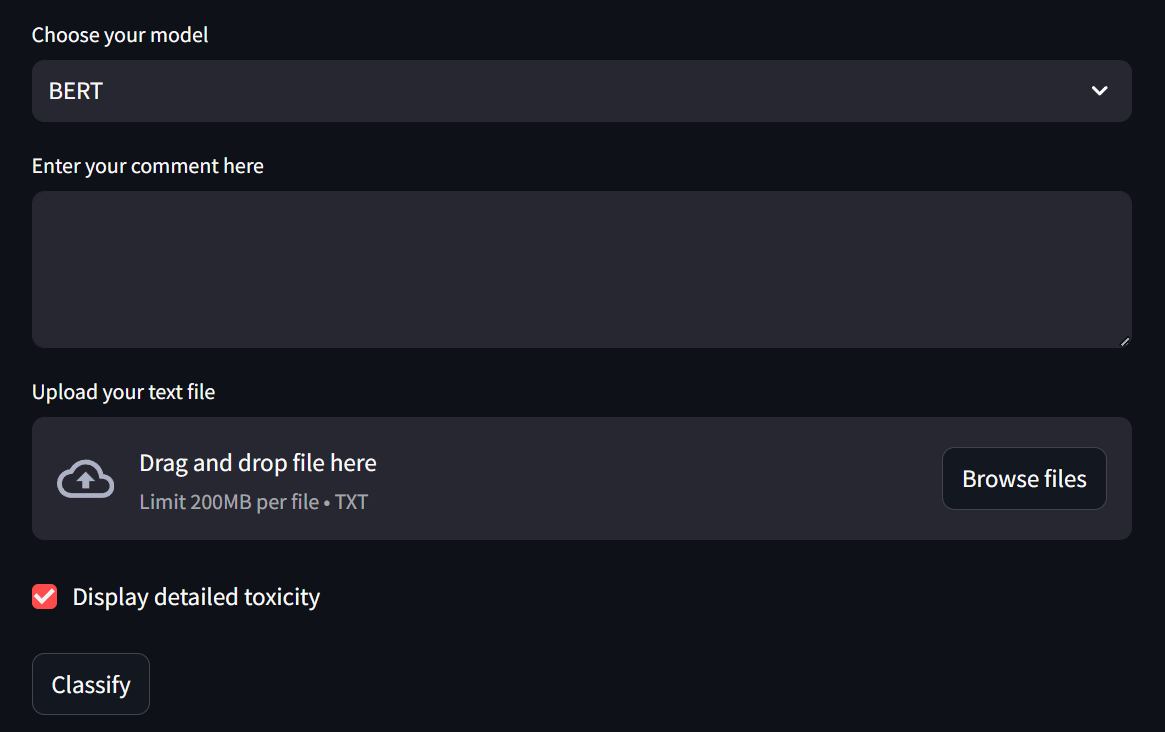
The main elements of the interface:
- `Choose your model` - A drop-down list where you can select one of 3 pre-trained machine learning models
- `Enter your comment here` - In this field you can manually write a text to test it for toxicity and further classify it in a positive case
- `Upload your text file` - By clicking here, a dialog box will appear with the choice of a file in `txt format` (after uploading the file, the text in the text field is ignored)
- `Display detailed toxicity` - A checkbox that displays a detailed classification by class if the model considers the text to be toxic
The application interface is intuitive and user-friendly. The application is also able to classify text files in the txt format.
The [app written](https://github.com/techn0man1ac/ToxicCommentClassification/tree/main/frontend) with the help of streamlit provides a user-friendly interface to observe and try out functionality of the included BERT-based models for comment toxicity classification.
# 🎯 Mission
The mission of our project is to create a reliable and accurate machine learning model that can effectively classify different levels of toxicity in online comments. We plan to use advanced technologies to analyze text and create a system that will help moderators and users create healthier and safer social media environments.
# 🌟 Vision
Our vision is to make online communication safe and comfortable for everyone. We want to build a system that not only can detect toxic comments, but also helps to understand the context and tries to reduce the number of such messages. We want to create a tool that will be used not only by moderators, but also by every user to provide a safe environment for the exchange of thoughts and ideas.
# 📜 Licence
This project is a group work published under the [MIT license](https://github.com/techn0man1ac/ToxicCommentClassification/blob/main/LICENSE) , and all project contributors are listed in the license text.
# 👏 Acknowledgments
This project was developed by a team of professionals as a graduation thesis of the [GoIT](https://goit.global/) **Python Data Science and Machine Learning** course.
Thank you for exploring our project! Together, we can make online spaces healthier and more respectful.