https://github.com/therealaj/bulk-pdf
Downloads all PDFs on a webpage (for lazy people)
https://github.com/therealaj/bulk-pdf
scraper wget
Last synced: 6 months ago
JSON representation
Downloads all PDFs on a webpage (for lazy people)
- Host: GitHub
- URL: https://github.com/therealaj/bulk-pdf
- Owner: therealAJ
- License: mit
- Created: 2017-04-23T22:35:34.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2022-01-20T15:35:05.000Z (over 3 years ago)
- Last Synced: 2025-04-02T04:23:25.815Z (6 months ago)
- Topics: scraper, wget
- Language: Python
- Size: 2.2 MB
- Stars: 23
- Watchers: 3
- Forks: 5
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
Bulk PDF downloader

* will with work for local and non-hosted PDF's *


> a cli for downloading external pdf's (for lazy people like me)
## Demo
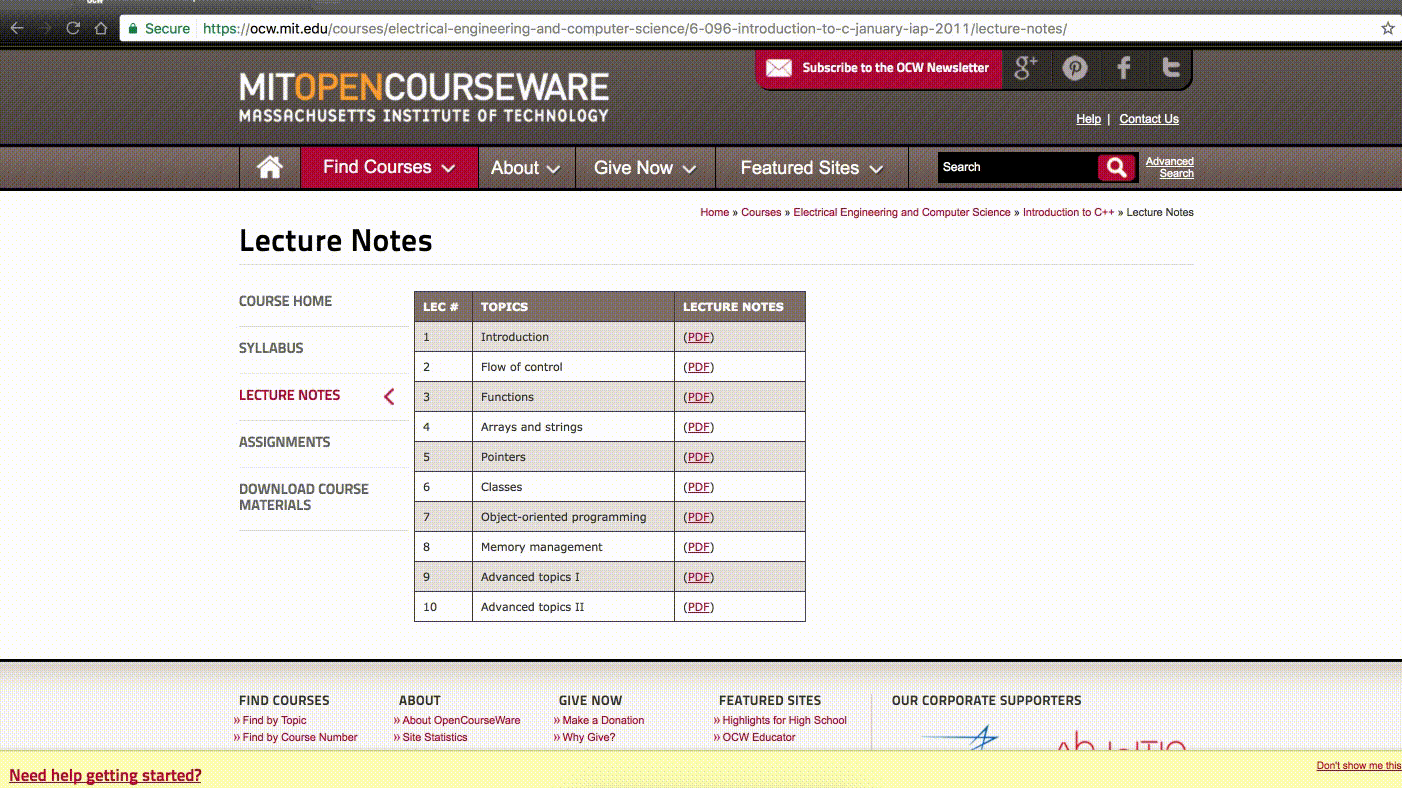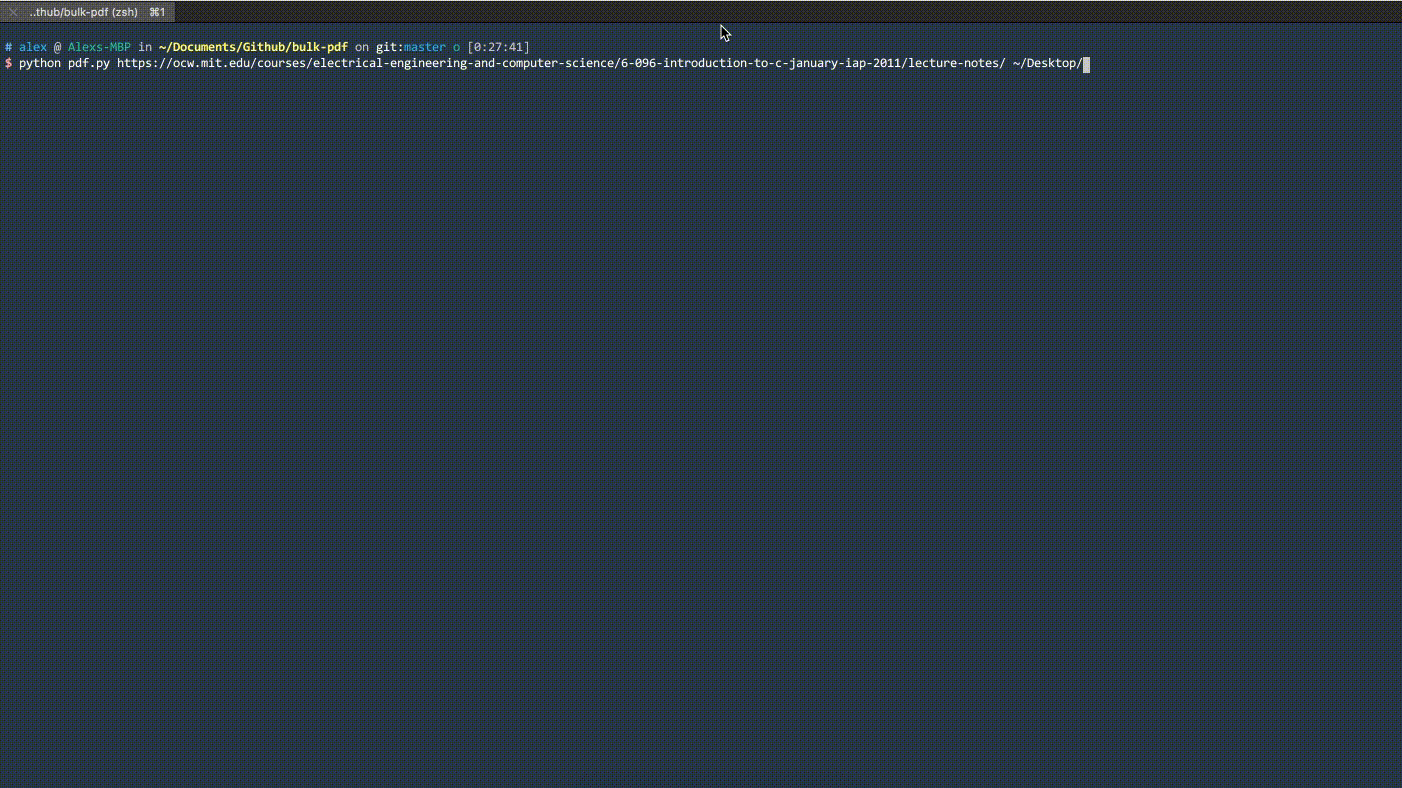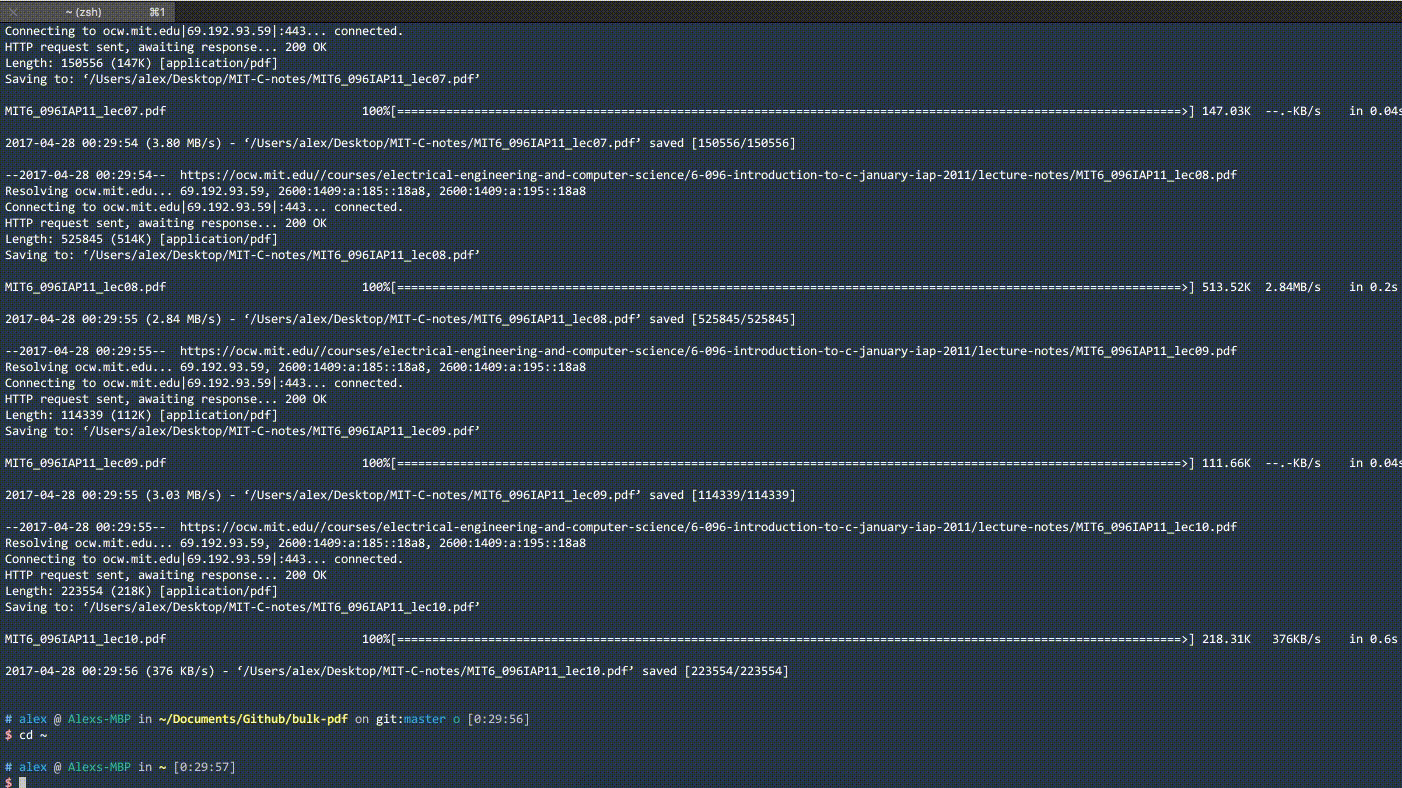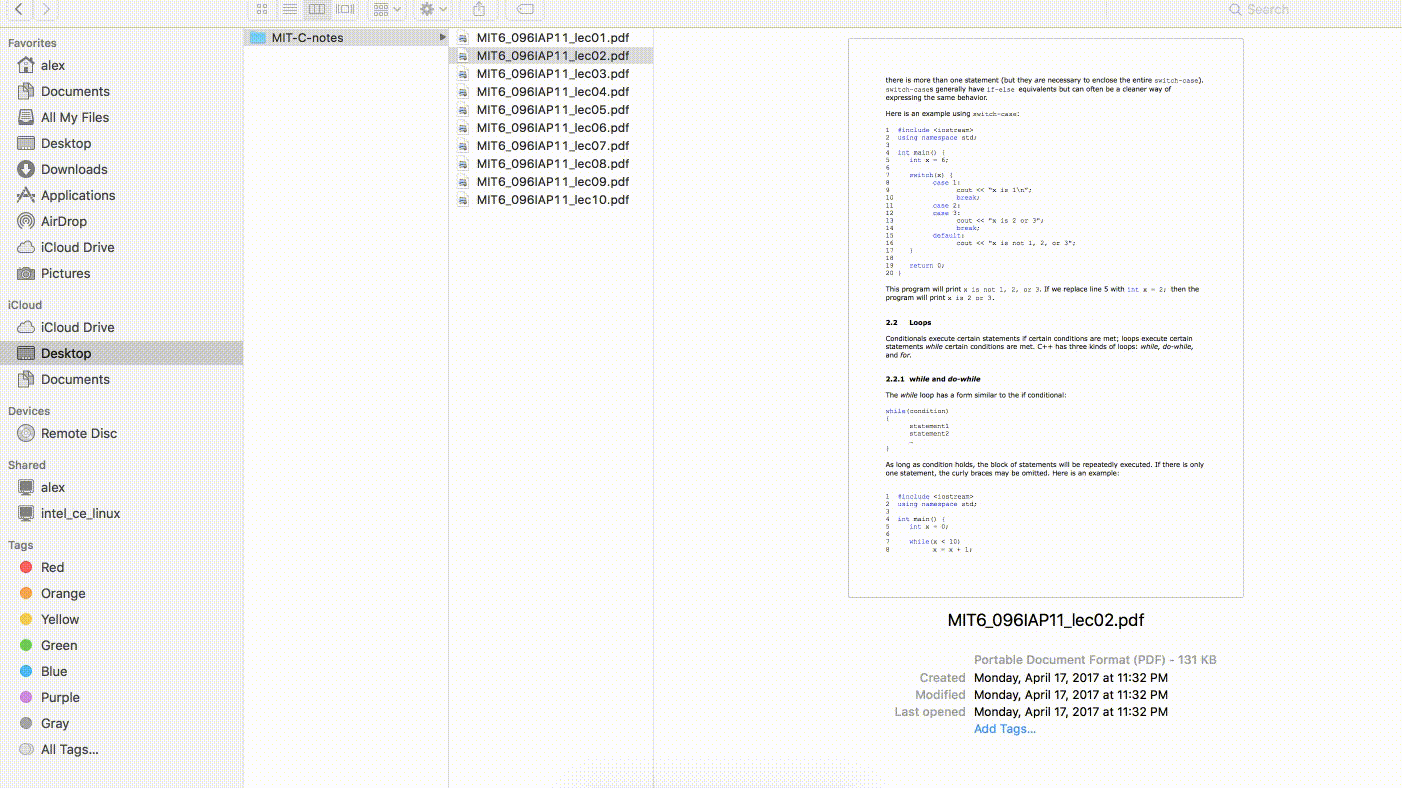
## Motivation
One day I was downloading what felt like millions of PDF packages of CS notes. A couple minutes in, I got really tired of right clicking `Save Link As`. So I decided to build this :)
## Requirements
`argparse`
`urllib`
`requests`
`wget`
`python >= 3.5`
## Install
```sh
$ git clone https://github.com/therealAJ/bulk-pdf
$ cd bulk-pdf
$ pip install -r reqs.txt
```
## Usage
```sh
$ python pdf.py [OPTIONAL-BASE-URL-FOR-HOSTED-PDFS]
```
Downloads discovered PDFs to specified `path`.
For example:
```sh
$ python pdf.py https://www.cs.ubc.ca/~schmidtm/Courses/340-F16/ ~/Desktop/Lectures
# downloads all PDFs to your `~/Desktop/Lectures` folder
```
### Notes
Webpages have different ways of hosting PDFs, some use an absolute url, like `https://hosting-site.com/hello.pdf`, others host locally and have `href` tags looking something like `\courses\cs101\hello.pdf`. The second case is the reason I added the ability to give the optional url for the parent hosting site.
You may run into a url that looks like `https://site.com/lectures.html`. More often than not, this is where you want to use the full url to parse the entire webpage and then use `https://site.com` as the optional parameter to do the `wget` requests with.
So, an example would look like:
```sh
$ python pdf.py https://site.com/lectures.html ~/Desktop/Test https://site.com
```
Hopefully I haven't confused you :) File an issue if you run into anything of interest. PRs welcome :)