https://github.com/thomaskolasa/association_rules_example
investigation of retail transaction data from a country store in the Catskills
https://github.com/thomaskolasa/association_rules_example
Last synced: 1 day ago
JSON representation
investigation of retail transaction data from a country store in the Catskills
- Host: GitHub
- URL: https://github.com/thomaskolasa/association_rules_example
- Owner: thomaskolasa
- Created: 2019-04-15T13:28:31.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2019-04-15T20:35:09.000Z (about 6 years ago)
- Last Synced: 2024-11-22T15:41:22.469Z (8 months ago)
- Language: R
- Size: 753 KB
- Stars: 4
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# The Apriori Algorithm for Unsupervised Learning in R
#### A Simple Example using `arules`
During my time as an instructor at NYC Data Science Academy, I had the pleasure of mentoring hundreds of diverse student and client projects. Although we taught association rule mining in our machine learning curriculum, no students used it in a project.
When I saw one student had a dataset that was apt for the apriori algorithm, I leapt at the chance to put it into practice.
### What is the Apriori Algorithm?
The apriori algorithm looks for relationships among data in the form "if X, then Y". When finding item `X` in a dataset, it is associated with finding item `Y`. It is an unsupervised methodology that can be measured for qualitative impact.
Some common uses are in genetics (e.g. looking for frequently co-occuring gene sequences), finding associated assets in finance, finding patterns in cases of fraud, and market basket analysis. Popular since the mid-90s, some famous findings of association rules in retail were discovering which unintuitive purchases were associated with pregnancy and discovering that customers buy beer as part of hurricane preparedness.
Some examples of rules could be `if {guacamole} => then {chips}` or `{flashlight, batteries, water} => {beer}`.
To develop an association rule, we use the following terminology for items `X` and `Y`:
**Support:** the fraction of which each item appears within the dataset as a whole
`Support(X) = Count(X)/N`
**Confidence:** the likelihood that a constructed rule is correct
`Confidence(X → Y) = Support(X ∪ Y)/Support(X)`
**Lift:** the ratio by which the confidence of a rule exceeds the expected outcome
`Lift(X → Y) = Confidence(X → Y)/Support(Y) = Support(X ∪ Y)/(Support(X) * Support(Y))`
In practice, "lift" is the most useful for analytics because it explains the extent of a dependent relationship between variables.
Based on these terms, we can define if an association rule is important enough to examine. However, given *k* different items in a store, there are (2*k* - 1) different possible combinations of those items. To save on computation, we first search for small subsets of items in each transaction and iterate over larger subsets of items. If a small subset is lacking, then there is no need to compute any larger subsets that encase the smaller subset.
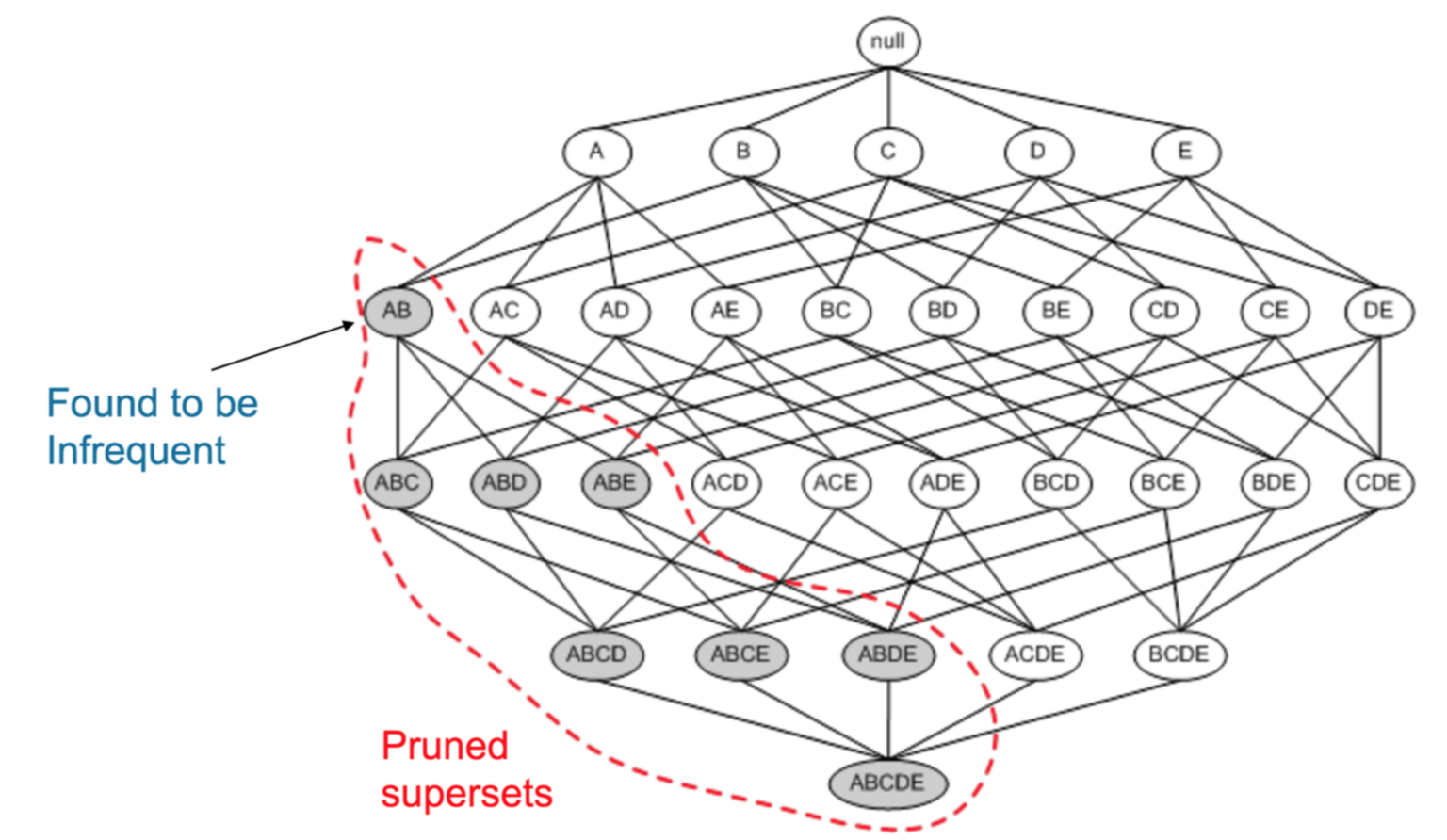
For implementation, I used the [arules](https://cran.r-project.org/web/packages/arules/arules.pdf) library in R.
### The Data
The dataset is from a small country store in the Catskill Mountains of upstate New York. After removing all of the personal data, the relevant formatted transaction data can be found in [transactions.csv](https://github.com/thomaskolasa/association_rules_example/blob/master/transactions.csv). Each row is a separate transaction. Here are a few examples:
| | | | | |
|---|---|---|---|---|
|Chocolate Truffles | | | | |
|Honey | | | | |
|Pancake & Waffle Mix |Gift Set | | | |
|Honey | | | | |
|Honey & Syrup | | | | |
|Ketchup | | | | |
|Ketchup | | | | |
|Honey | | | | |
|Chocolate Truffles | | | | |
|Gift Set | | | | |
|Ketchup | | | | |
|Pancake & Waffle Mix | | | | |
|Maple Sugar | Honey & Syrup | Pancake & Waffle Mix | | |
|Honey & Syrup | | | | |
|Chocolate Truffles |Honey | | | |
|... |... |... |... |...|
This works nicely for a simple toy example because most transaction data involves millions of sales and thousands of products. This dataset has 505 transactions and 14 different items, including:
- Case of Honey
- Chocolate Truffles
- Cocktail Rimmers
- Gift Set
- Honey
- Honey & Syrup
- Honey Wand
- Ketchup
- Maple Sugar
- Maple Syrup
- Marinating Solutions
- Pancake & Waffle Mix
- Raw Honey Comb
- Syrup
For simplicity, I treated each item type as a unique item ("honey & syrup" is distinct from "honey" or "syrup").
Since there are usually many more transactions and items, the function `read.transactions()` creates a memory-efficient sparse matrix of the data (essentially only storing 1's for the relevant items).
Investigating the 505 transactions, 383 contain a single item. These can't help us much to find association with other purchases. However, 88 transactions were comprised of 2 items, 24 had 3 items, 4 had 4 items, and 3 had 5 items. While customers often buy many products simultaneously at supermarkets, customers usually bought a single item from this novelty store.

The `arules` package also contains the function `itemFrequencyPlot()` to easily inspect the frequency of each item in the dataset. Honey, truffles, and the gift set are the most popular items.

Finally, I ran the apriori algorithm to find associations between items in the transactions. The function's default level of support is `0.8` and default level of confidence is `0.1`. In practice for market basket analysis, this support level is unrealistically high. Most retailors who would do this type of investigation have many products, so even the most popular products can appear in only a small subset of transactions. A higher confidence level makes more sense since we are trying to find rules of inference that are stronger, meaning they are correct a larger proportion of the time.
While these default values might be good starting points for large datasets in different fields, only a small subset of this data contains any relevant rules. I had to lower the support threshold to `0.02` for any rules to appear, meaning the function only listed rules for a group of items that happen in at least 2% of the transactions. I also adjusted the confidence level to `0.5`, meaning I will look at rules where the union of the left and right hand sides of the rule appears at least half of the time that the left hand side of the rule appears in the data.
Since this is unsupervised learning, it is permissable to try many different levels of support and confidence as this is an investigation of any possible useful rules in the data. Lower support would expose less common rules and lower confidence would expose weaker rules. While there are (214-1) = 16,383 rules from theoretical combinations of products, 166 rules can be constructed from the actual data.
In examining the rules that fit the support and confidence criteria, the two relevant ones that appear are:
| |lhs | |rhs |support |confidence |lift |
|-|-------------|----|--------|-----------|-----------|--------|
|1|{Honey Wand} | => |{Honey} |0.02178218 |0.8461538 |2.400605|
|2|{Maple Syrup}| => |{Honey} |0.02178218 |0.7333333 |2.080524|
Rule 1 means purchasing a honey wand (left hand side) is associated with purchasing honey (right hand side).
Rule 2 means purchasing maple syrup is associated with purchasing honey.
Both these rules have similar support, meaning they both appear in about 2.2% of the transactions (11 transactions). The confidence of the first rule is 0.85, meaning that of the 13 transactions with a honey wand, 11 transactions also contained honey. The confidence of the second rule is 0.73, meaning that of the 15 transactions that included maple syrup, 11 also included honey.
Looking at the lift of the rules, purchasing a honey wand is associated with a 2.4 times increase in the purchase of honey and purchasing maple syrup is associated with a 2.1 time increase in the purchase of honey. One relevant takeaway from this analysis would be to place honey wands near the honey in the store since they are often bought together.
In case you weren't sure if customers who buy honey wands are more likely to buy honey, now we know!