https://github.com/threezh1/sitecopy
sitecopy is a tool that facilitates personal website backup and network data collection
https://github.com/threezh1/sitecopy
Last synced: about 1 year ago
JSON representation
sitecopy is a tool that facilitates personal website backup and network data collection
- Host: GitHub
- URL: https://github.com/threezh1/sitecopy
- Owner: Threezh1
- Created: 2019-12-12T14:23:33.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2024-01-21T11:48:45.000Z (over 2 years ago)
- Last Synced: 2025-03-31T17:16:20.335Z (about 1 year ago)
- Language: Python
- Size: 13.7 KB
- Stars: 599
- Watchers: 6
- Forks: 178
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# SiteCopy
sitecopy is a tool that facilitates personal website backup and network data collection
## 介绍
网站复制,也可称为网站备份。是通过工具将网页上的内容全部保存下来。当然不仅仅只是保存了一个html页面,而是将网页源码内所包含的css、js和静态文件等全部保存,以在本地也可以完整的浏览整个网站。网络上也有一些类似的工具,但使用起来并不理想。于是自己写一个Python脚本,方便个人对网站的备份,也方便一些网络资料的收集。
- 工具名称: SiteCopy
- 作者: Threezh1
- 博客: http://www.threezh1.com/
关于SiteCopy的开发记录:[论如何优雅的复制一个网站的所有页面](https://xz.aliyun.com/t/6941)
对互联网任何网站的复制需在取得授权后方可进行,若使用者因此做出危害网络安全的行为后果自负,与作者无关,特此声明。
## 使用
Python版本: 3.7
安装依赖库: `pip3 install -r requirements.txt`
- 复制单个页面
`python sitecopy.py -u "http://www.threezh1.com"`
- 复制整个网站
`python sitecopy.py -u "http://www.threezh1.com" -e`
- 复制多个页面
`python sitecopy.py -s "site.txt"`
- 复制多个网站
`python sitecopy.py -s "site.txt" -e`
指定链接爬取的循环次数: -d (默认为200)
指定线程数:-e (默认为30)
例子: 爬取 www.threezh1.com 网站所有页面,指定链接爬取的循环次数为200,指定线程数为30
`python sitecopy.py -u "http://www.threezh1.com" -e -d 200 -t 30`
## 复制网站测试
- 复制自己的博客:https://threezh1.com 花费时间:2分钟48秒
运行截图:

目录截图:
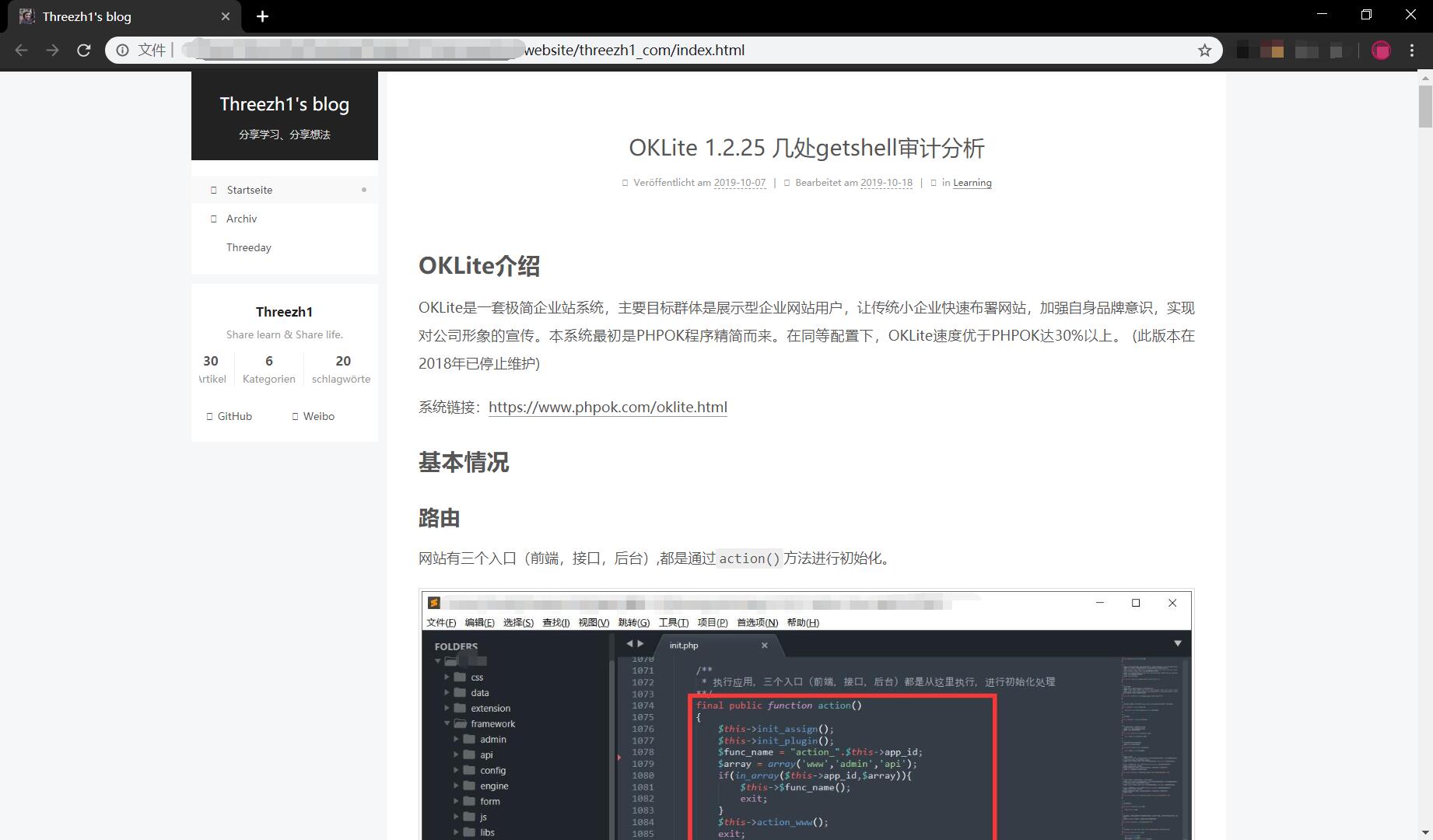
页面截图:
## 已知存在的问题
1. 目录替换时在有些情况下会进行多次替换导致页面无法正常显示
2. 网站或图床有防爬措施时无法正常保存
3. 网络问题导致脚本无法正常执行
非常希望能够和师傅们共同交流对这些问题的解决方式,我的邮箱:makefoxm@qq.com