https://github.com/thunlp/Few-NERD
Code and data of ACL 2021 paper "Few-NERD: A Few-shot Named Entity Recognition Dataset"
https://github.com/thunlp/Few-NERD
deep-learning entity-typing few-shot-learning named-entity-recognition nlp
Last synced: about 1 year ago
JSON representation
Code and data of ACL 2021 paper "Few-NERD: A Few-shot Named Entity Recognition Dataset"
- Host: GitHub
- URL: https://github.com/thunlp/Few-NERD
- Owner: thunlp
- License: apache-2.0
- Created: 2021-05-07T10:34:41.000Z (about 5 years ago)
- Default Branch: main
- Last Pushed: 2023-09-07T09:34:19.000Z (almost 3 years ago)
- Last Synced: 2025-04-05T15:06:13.141Z (over 1 year ago)
- Topics: deep-learning, entity-typing, few-shot-learning, named-entity-recognition, nlp
- Language: Python
- Homepage: https://ningding97.github.io/fewnerd
- Size: 67.4 KB
- Stars: 396
- Watchers: 11
- Forks: 54
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Security: SECURITY.md
Awesome Lists containing this project
- StarryDivineSky - thunlp/Few-NERD
README
# Few-NERD: Not Only a Few-shot NER Dataset
  
This is the source code of the ACL-IJCNLP 2021 paper: [**Few-NERD: A Few-shot Named Entity Recognition Dataset**](https://arxiv.org/abs/2105.07464). Check out the [website](https://ningding97.github.io/fewnerd/) of Few-NERD.
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* **Updates** \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
- 09/03/2022: We have added the training script for supervised training using BERT tagger. Run `bash data/download.sh supervised` to download the data, and then run `bash run_supervised.sh`.
- 01/09/2021: We have modified the results of the supervised setting of Few-NERD in arxiv, thanks for the help of [PedroMLF](https://github.com/PedroMLF).
- 19/08/2021: **Important💥** In accompany with the released episode data, we have updated the training script. Simply add `--use_sampled_data` when running `train_demo.py` to train and test on the released episode data.
- 02/06/2021: To simplify training, we have released the data sampled by episode. click [here](https://cloud.tsinghua.edu.cn/f/0e38bd108d7b49808cc4/?dl=1) to download. The files are named such: `{train/dev/test}_{N}_{K}.jsonl`. We sampled 20000, 1000, 5000 episodes for train, dev, test, respectively.
- 26/05/2021: The current Few-NERD (SUP) is sentence-level. We will soon release Few-NERD (SUP) 1.1, which is paragraph-level and contains more contextual information.
- 11/06/2021: We have modified the word tokenization and we will soon update the latest results. We sincerely thank [tingtingma](https://github.com/mtt1998) and [Chandan Akiti](https://github.com/chandan047)
## Contents
- [Website](https://ningding97.github.io/fewnerd/)
- [Overview](#overview)
- [Getting Started](#requirements)
- [Requirements](#requirements)
- [Few-NERD Dataset](#few-nerd-dataset)
- [Get the Data](#get-the-data)
- [Data Format](Data-format)
- [Structure](#structure)
- [Key Implementations](#Key-Implementations)
- [N way K~2K shot Sampler](#Sampler)
- [How to Run](#How-to-Run)
- [Citation](#Citation)
- [Connection](#Connection)
## Overview
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains *8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens*. Three benchmark tasks are built, one is supervised: Few-NERD (SUP) and the other two are few-shot: Few-NERD (INTRA) and Few-NERD (INTER).
The schema of Few-NERD is:
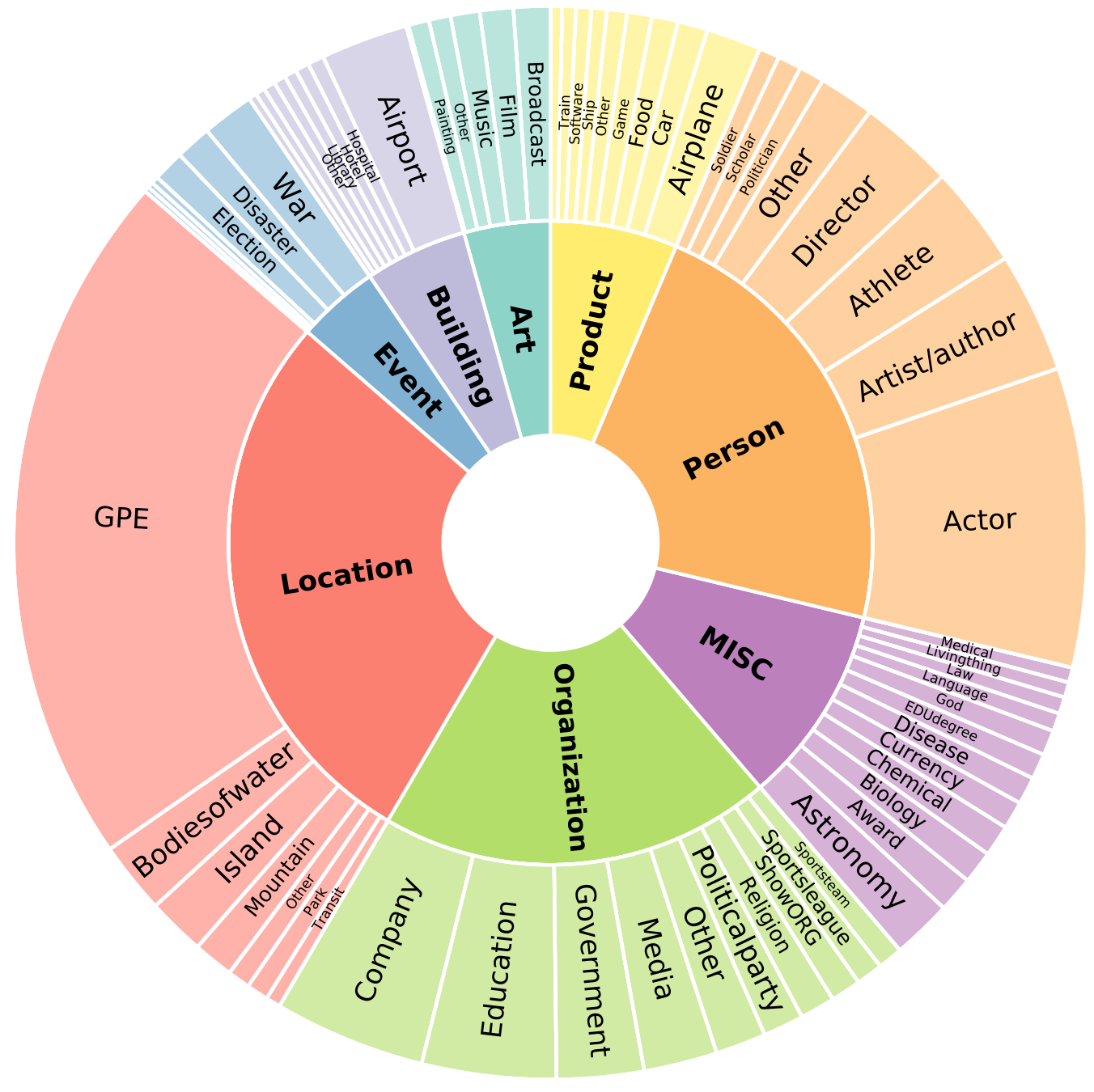
Few-NERD is manually annotated based on the context, for example, in the sentence "*London is the fifth album by the British rock band…*", the named entity `London` is labeled as `Art-Music`.
## Requirements
Run the following script to install the remaining dependencies,
```shell
pip install -r requirements.txt
```
## Few-NERD Dataset
### Get the Data
- Few-NERD contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens.
- We have splitted the data into 3 training mode. One for supervised setting-`supervised`, the other two for few-shot setting `inter` and `intra`. Each contains three files `train.txt`, `dev.txt`, `test.txt`. `supervised`datasets are randomly split. `inter` datasets are randomly split within coarse type, i.e. each file contains all 8 coarse types but different fine-grained types. `intra` datasets are randomly split by coarse type.
- The splitted dataset can be downloaded automatically once you run the model. **If you want to download the data manually, run data/download.sh, remember to add parameter supervised/inter/intra to indicate the type of the dataset**
To obtain the three benchmark datasets of Few-NERD, simply run the bash file `data/download.sh` with parameter `supervised/inter/intra` as below
```shell
bash data/download.sh supervised
```
To get the data sampled by episode, run
```shell
bash data/download.sh episode-data
unzip -d data/ data/episode-data.zip
```
### Data Format
The data are pre-processed into the typical NER data forms as below (`token\tlabel`).
```latex
Between O
1789 O
and O
1793 O
he O
sat O
on O
a O
committee O
reviewing O
the O
administrative MISC-law
constitution MISC-law
of MISC-law
Galicia MISC-law
to O
little O
effect O
. O
```
## Structure
The structure of our project is:
```shell
--util
| -- framework.py
| -- data_loader.py
| -- viterbi.py # viterbi decoder for structshot only
| -- word_encoder
| -- fewshotsampler.py
-- proto.py # prototypical model
-- nnshot.py # nnshot model
-- train_demo.py # main training script
```
## Key Implementations
#### Sampler
As established in our paper, we design an *N way K~2K shot* sampling strategy in our work , the implementation is sat `util/fewshotsampler.py`.
#### ProtoBERT
Prototypical nets with BERT is implemented in `model/proto.py`.
#### NNShot & StructShot
NNShot with BERT is implemented in `model/nnshot.py`.
StructShot is realized by adding an extra viterbi decoder in `util/framework.py`.
**Note that the backbone BERT encoder we used for structshot model is not pre-trained with NER task**
## How to Run
Run `train_demo.py`. The arguments are presented below. The default parameters are for `proto` model on `inter`mode dataset.
```shell
-- mode training mode, must be inter, intra, or supervised
-- trainN N in train
-- N N in val and test
-- K K shot
-- Q Num of query per class
-- batch_size batch size
-- train_iter num of iters in training
-- val_iter num of iters in validation
-- test_iter num of iters in testing
-- val_step val after training how many iters
-- model model name, must be proto, nnshot or structshot
-- max_length max length of tokenized sentence
-- lr learning rate
-- weight_decay weight decay
-- grad_iter accumulate gradient every x iterations
-- load_ckpt path to load model
-- save_ckpt path to save model
-- fp16 use nvidia apex fp16
-- only_test no training process, only test
-- ckpt_name checkpoint name
-- seed random seed
-- pretrain_ckpt bert pre-trained checkpoint
-- dot use dot instead of L2 distance in distance calculation
-- use_sgd_for_bert use SGD instead of AdamW for BERT.
# only for structshot
-- tau StructShot parameter to re-normalizes the transition probabilities
```
- For hyperparameter `--tau` in structshot, we use `0.32` in 1-shot setting, `0.318` for 5-way-5-shot setting, and `0.434` for 10-way-5-shot setting.
- Take `structshot` model on `inter` dataset for example, the expriments can be run as follows.
**5-way-1~5-shot**
```bash
python3 train_demo.py --mode inter \
--lr 1e-4 --batch_size 8 --trainN 5 --N 5 --K 1 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 64 --model structshot --tau 0.32
```
**5-way-5~10-shot**
```bash
python3 train_demo.py --mode inter \
--lr 1e-4 --batch_size 1 --trainN 5 --N 5 --K 5 --Q 5 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 32 --model structshot --tau 0.318
```
**10-way-1~5-shot**
```bash
python3 train_demo.py --mode inter \
--lr 1e-4 --batch_size 4 --trainN 10 --N 10 --K 1 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 64 --model structshot --tau 0.32
```
**10-way-5~10-shot**
```bash
python3 train_demo.py --mode inter \
--lr 1e-4 --batch_size 1 --trainN 10 --N 10 --K 5 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 32 --model structshot --tau 0.434
```
## Citation
If you use Few-NERD in your work, please cite our paper:
```bibtex
@inproceedings{ding-etal-2021-nerd,
title = "Few-{NERD}: A Few-shot Named Entity Recognition Dataset",
author = "Ding, Ning and
Xu, Guangwei and
Chen, Yulin and
Wang, Xiaobin and
Han, Xu and
Xie, Pengjun and
Zheng, Haitao and
Liu, Zhiyuan",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.248",
doi = "10.18653/v1/2021.acl-long.248",
pages = "3198--3213",
}
```
## License
Few-NERD dataset is distributed under the CC BY-SA 4.0 license. The code is distributed under the Apache 2.0 license.
## Connection
If you have any questions, feel free to contact
- [dingn18@mails.tsinghua.edu.cn;](mailto:dingn18@mails.tsinghua.edu.cn)
- [yl-chen21@mails.tsinghua.edu.cn;](mailto:yl-chen21@mails.tsinghua.edu.cn)