https://github.com/tiyee/palmon
一个纯go实现的任务调度系统,没有任何第三方依赖, 支持docker和kubernetes,简单修改即可支持高可用架构。
https://github.com/tiyee/palmon
go-scheduler go-task-queue privor-queue
Last synced: 9 months ago
JSON representation
一个纯go实现的任务调度系统,没有任何第三方依赖, 支持docker和kubernetes,简单修改即可支持高可用架构。
- Host: GitHub
- URL: https://github.com/tiyee/palmon
- Owner: tiyee
- License: mit
- Created: 2023-05-10T10:16:34.000Z (about 3 years ago)
- Default Branch: master
- Last Pushed: 2023-11-09T09:41:03.000Z (over 2 years ago)
- Last Synced: 2024-06-21T16:44:05.982Z (about 2 years ago)
- Topics: go-scheduler, go-task-queue, privor-queue
- Language: Go
- Homepage:
- Size: 56.6 KB
- Stars: 4
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# palmon

**palmon**是一个纯go实现的任务调度系统,没有任何第三方依赖,但只是**demo**级别,勿用于生产环境!!!
## Demo
目前本人在二级目录下部署了该项目,仅做示例
### 创建任务
> curl -XPOST https://uploader.tiyee.com.cn/palmon/task -d '{"processor":2,"payload":"12344","Prior":1}'
结果
```json
{
"error": 0,
"message": "ok",
"data":
{
"task_id": 393778421588561921
}
}
```
### 获取任务状态和详情
> curl 'https://uploader.tiyee.com.cn/palmon/task?task_id=393778421588561921'
```json
{
"error": 0,
"message": "ok",
"data":{
"task_id": 393778421588561921,
"state": 2,
"result": "1234412344"
}
}
```
## API
统一返回格式
```json
{
"error":0,
"message":"ok",
"data": {
"task_id":393708785169862658,
"state":2,
"payload":"1234412344"
}
}
```
| 名称 | 类型 | 说明 |
| ---------- | -------- | ------------- |
| error | `integer` | 错误编号,0表示无错误,大于0表示有误 |
| message | `string` | 返回的消息备注 |
| data | `any` | 返回的数据 |
### `POST` /task
添加任务,数据格式如下
```json
{
"processor":2,
"payload":"12344",
"prior":1
}
```
#### 参数说明
| 名称 | 类型 | 说明 |
| ---------- | -------- | ------------- |
| processor | `enum` | 任务类型编号(也可以称之为执行者编号),用来区分不同的任务,以便用不同的执行器去执行.目前只做了2这一个执行器。 |
| payload | `any` | 任务携带的信息 |
| prior | `enum` | 优先级,1-高,2-中,3-低 |
### `GET` /task
获取任务详情
#### 参数
| 名称 | 类型 | 说明 |
| ---------- | -------- | ------------- |
| task_id | `integer` | 任务id,创建时返回 |
#### 返回数据
```json
{
"error":0,
"message":"ok",
"data":{
"task_id":393708785169862658,
"state":2,
"result":"1234412344"
}
}
```
#### 参数说明
| 名称 | 类型 | 说明 |
| ---------- | -------- | ------------- |
| task_id | `integer` | 任务id |
| state | `enum` | 任务执行状态,0-待执行,1-执行中,2-已完成,3-已取消,4-发送错误 |
| result | `any` | 执行结果,json化数据 |
## 部署
> 注意,如果是mac系统,编译的时候需要修改`export GOOS=linux`为`export GOOS=darwin`
### docker部署
最简单的是`docker-compose`,直接执行下面命令
```shell
sudo mkdir -p /data/logs/palmon
git clone github.com/tiyee/palmon your_name
cd your_name
sudo docker-compose -f docker-compose.yml build
sudo docker-compose -f docker-compose.yml up -d
```
### kubernetes部署
本项目涉及的`coordinator`和`worker`是互相独立的,需要分别打包,可以直接利用github或其他自带的ci/cd工具打包后将镜像上传到镜像仓库,
但是目前不是高可用架构,`coordinator`只能部署一个pod,`worker`不限制pod数量。默认的`Puller`和`Pusher`里的`coordinator`的地址需要更改成k8s点的内部svc地址
## 高可用配置
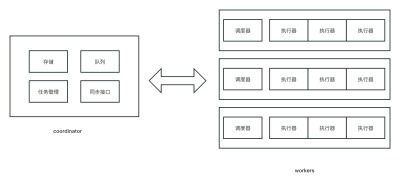
如图所示,存储和队列系统目前是一个纯go的简单实现,跟`coordinator`耦合在一起,`worker`会不断从`coordinator`拉取任务并执行,然后将任务的执行结果推送到`coordinator`,
如果`coordinator`部署多份,就会任务分布在不同的pod,数据不一致。
如果要高可用,存储和队列需要独立部署,它们本身需要是高可用的。然后`coordinator`就可以多点部署,通过vip系统或k8s的svc来统一访问`coordinator`。
## 优先队列
每个任务都有优先级`prior`属性,它是是一个数字,越小表示优先级越高。如果只是单纯按优先级来执行,有可能会导致低优先级的任务一直得不到执行,俗称`饿死`。所以还得考虑时间因素。
于是,根据一定算法,计算了一个`score`值,公式如下
`score= ( 1 << 62 ) - ( prior << 41 ) - factor * epochTimestamp`
我们可以通过设置`factor`大小来控制时间因素的影响,这样可以保证低优先级的任务也能被执行。
目前队列是一个纯go实现的`最大堆`,任务是按score来决定执行顺序的。但是如果是正式环境,显然不行。得用成熟的支持优先队列的队列来处理,比如`ActiveMQ`,
`RabbitMQ`等。
但新的问题来了,目前市面成熟的优先队列支持的优先级区间都很小,最多0-255,显然不支持我们score这么大的数字。因此需要设计一个新的方案。
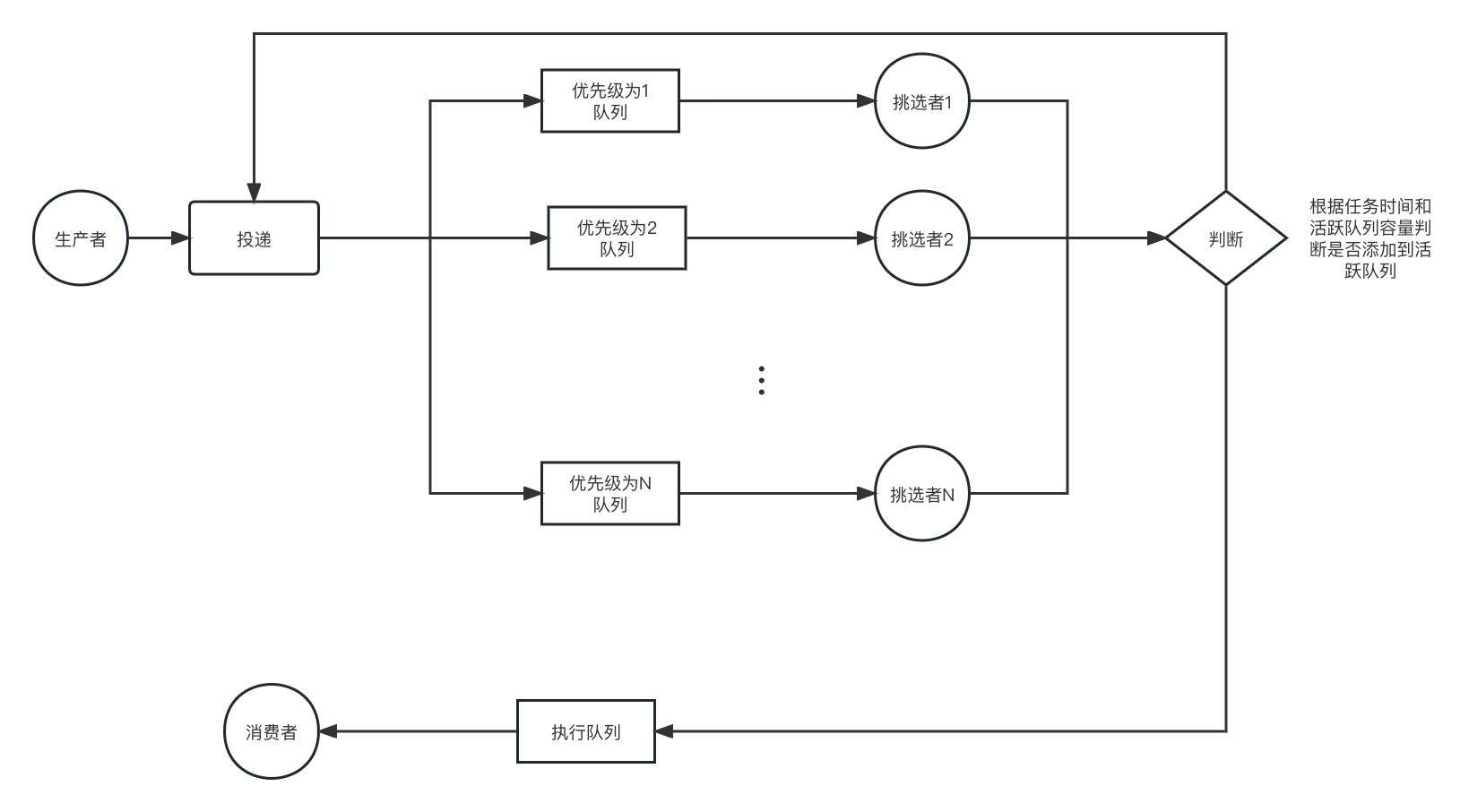
所以,可以根据任务优先级投递到不同优先级的队列,然后由一个统一的,或各种独立的监控者循环读取这些队列,如果符合条件,就投入到活动队列,不符合条件的重新添加到原来队列。这种方案用任何队列都可实现,该过程如下图所示。这种方案适合除开prior外,有多种打分条件的队列。
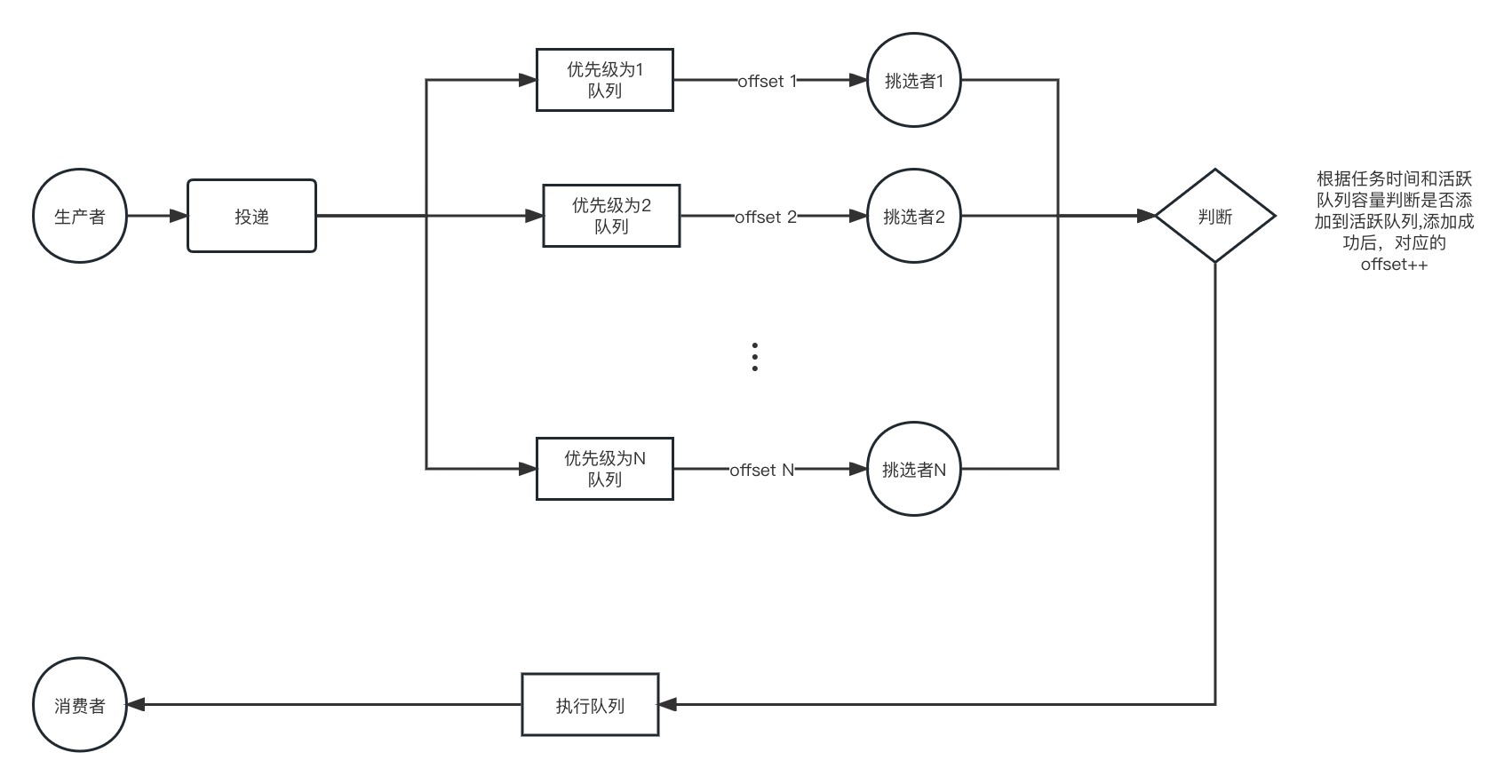
当然还可以利用kafka的存储来实现,把各种不同权重的任务投入不同的kafka,然后由监控者自己维护kafka的offset,如果符合活跃条件,则将其投入活跃队列,然后offset++。如下图所示,这种方案适合于除开prior外只有时间这一种判断条件。
## 定时任务
定时任务分为三种**单次任务**,**多次任务**,**循环任务**,顾名思义,就是只执行一次,执行有限次数和一直循环执行。所以定时任务可以看作是一组任务。
关于定时任务的描述,一般是类似crontab 这种
```shell
* * * * *
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 6) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
```
但显然,它无法表达重复次数或截止时间,也无法表示开始时间,为此可以借鉴日历系统的两个协议[RFC 5545](https://www.ietf.org/rfc/rfc5545.txt) 和 [RFC 2445](https://www.ietf.org/rfc/rfc2445.txt) 里关于时间rules的表示法,简单说就是`起始时间` ; `频率`;`命中规则`; `终止条件`。比如
2023年5月1日起,每周重复, 每周一或周二的上午10点1分0秒执行,执行10次 , 可表示为
> `2023-05-01 00:00:00; daily; (week=1 or week = 2) and hour=10 and minut = 1 and second = 0; count=10 `
2023年5月1日起,每年春节除夕夜上午10点1分0秒执行,知道2029年1月1日 , 可表示为
> `2023-05-01 00:00:00; daily; is_sf_holiday(${current_date}); ${current_date} >= 2029-01-01 00:00:00 `
日期规则可以通过for循环展开,注意的是,每年重复并不表示频率是年,因为每年的绝对时间区间不同,同理按月重复的频率也不是月。但是按周重复,按天重复,按时分秒重复是可以按实际表述处理的。组合型命中规则,也不能完全按照表述的频率来处理。
上述的规则可以看作是一个特定的`DSL`,是可以解析成对应的for循环的,然后可以把每次执行的绝对时间算出来。在到达这个绝对时间点的时候,将其包装成一个特定的任务,添加到我们这个任务执行系统即可。大概步骤如下:
1. 新建定时任务,算出下一次(即第一次)的执行时间,将其添加到延时队列
2. 消费延时队列,获取马上要执行的任务,将其添加到我们这个执行系统里,然后计算出下一次的执行时间并添加到延时队列,如果没有一下次了,则定时任务终止
3. 重复步骤(2)
为了保证到点儿的任务优先被执行,可以在上图的挑选者里特殊处理,保证优先被执行。
## 执行器
| 名称 | ID | 说明 |
| ---------- | -------- | ------------- |
| puller | - | 自带,执行从`coordinator`拉取任务的工作 |
| pusher| - | 自带,任务执行完后,由pusher将结果推送给`coordinator` |
| proc1 | 2| 自定义执行器,当做一个简单demo,只是将payload repeat 一次然后返回 |
执行器是用来执行任务点,`worker`从`coordinator`拉取任务后,根据任务的类型,由不同的执行器去执行。
但有两个个例外,分别是puller和pusher,他们的任务不是从coordinator获取的,而是节点内部生成的。
`dispatcher`会按照指定的策略定期往节点`jobChannel`写入拉取任务,然后puller获取这个任务后就去coorddinator拉取任务,随后将任务投入`jobChannel`。
同理,pusher的任务也不是`coordinator`获取的, 其他执行器执行完任务后,会将执行结果写入pusher任务的payload里,然后由pusher将payload的内容包装成json数据推送给`coordinator`,