Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/tomhosking/hrq-vae
Hierarchical Sketch Induction for Paraphrase Generation (Hosking et al., ACL 2022)
https://github.com/tomhosking/hrq-vae
Last synced: 24 days ago
JSON representation
Hierarchical Sketch Induction for Paraphrase Generation (Hosking et al., ACL 2022)
- Host: GitHub
- URL: https://github.com/tomhosking/hrq-vae
- Owner: tomhosking
- License: mit
- Created: 2021-10-11T14:52:49.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2023-11-08T15:55:51.000Z (about 1 year ago)
- Last Synced: 2024-10-08T13:26:43.618Z (about 1 month ago)
- Language: Python
- Homepage:
- Size: 80.4 MB
- Stars: 51
- Watchers: 3
- Forks: 7
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# [Hierarchical Sketch Induction for Paraphrase Generation](https://aclanthology.org/2022.acl-long.178/)
[](https://paperswithcode.com/sota/paraphrase-generation-on-mscoco?p=hierarchical-sketch-induction-for-paraphrase)
[](https://paperswithcode.com/sota/paraphrase-generation-on-paralex?p=hierarchical-sketch-induction-for-paraphrase)
[](https://paperswithcode.com/sota/paraphrase-generation-on-quora-question-pairs-1?p=hierarchical-sketch-induction-for-paraphrase)
This repo contains the code for the paper [Hierarchical Sketch Induction for Paraphrase Generation](https://aclanthology.org/2022.acl-long.178/), by Tom Hosking, Hao Tang & Mirella Lapata (ACL 2022).
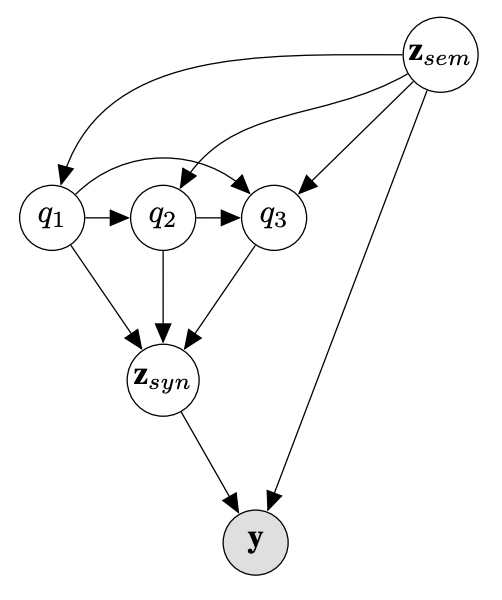
We propose a generative model of paraphrase generation, that encourages syntactic diversity by conditioning on an explicit syntactic sketch. We introduce Hierarchical Refinement Quantized Variational Autoencoders (HRQ-VAE), a method for learning decompositions of dense encodings as a sequence of discrete latent variables that make iterative refinements of increasing granularity. This hierarchy of codes is learned through end-to-end training, and represents fine-to-coarse grained information about the input. We use HRQ-VAE to encode the syntactic form of an input sentence as a path through the hierarchy, allowing us to more easily predict syntactic sketches at test time. Extensive experiments, including a human evaluation, confirm that HRQ-VAE learns a hierarchical representation of the input space, and generates paraphrases of higher quality than previous systems.
## Installation
First, create a fresh virtualenv and install the dependencies:
```
pip install -r requirements.txt
```
Then download (or create) the datasets/checkpoints you want to work with:
Download a pretrained checkpoint for Paralex
Download a pretrained checkpoint for QQP
Download a pretrained checkpoint for MSCOCO
Checkpoint zip files should be unzipped into `./models`, eg `./models/hrqvae_qqp`. Data zip files should be unzipped into `./data/`.
Note: Paralex was originally scraped from WikiAnswers, so many of the Paralex models and datasets are labelled as 'wa' or WikiAnswers.
Note 2: As per [this issue](https://github.com/tomhosking/hrq-vae/issues/2), the dataset splits used in the paper for MSCOCO and QQP (based on official splits) are actually somewhat leaky. We recommend using deduped versions of these splits (eg [here for QQP](https://tomho.sk/models/hrqvae/qqp_deduped.zip))for future work.
## Inference with pre-trained checkpoints
To replicate our results (eg for QQP), have a look at the example in `./examples/Replication-QQP.ipynb`.
## Inference on a custom dataset
You can also run the model on your own data:
```
import json
from torchseq.agents.para_agent import ParaphraseAgent
from torchseq.datasets.json_loader import JsonDataLoader
from torchseq.utils.config import Config
import torch
# Which checkpoint should we load?
path_to_model = './models/hrqvae_paralex/'
path_to_data = './data/'
# Define the data
examples = [
{'input': 'What is the income for a soccer player?'},
{'input': 'What do soccer players earn?'}
]
# Change the config to use the custom dataset
with open(path_to_model + "/config.json") as f:
cfg_dict = json.load(f)
cfg_dict["dataset"] = "json"
cfg_dict["json_dataset"] = {
"path": None,
"field_map": [
{"type": "copy", "from": "input", "to": "s2"},
{"type": "copy", "from": "input", "to": "s1"},
],
}
# Enable the code predictor
cfg_dict["bottleneck"]["code_predictor"]["infer_codes"] = True
# Create the dataset and model
config = Config(cfg_dict)
data_loader = JsonDataLoader(config, test_samples=examples, data_path=path_to_data)
checkpoint_path = path_to_model + "/model/checkpoint.pt"
instance = ParaphraseAgent(config=config, run_id=None, output_path=None, data_path=path_to_data, silent=True, verbose=False, training_mode=False)
# Load the checkpoint
instance.load_checkpoint(checkpoint_path)
instance.model.eval()
# Finally, run inference
_, _, (pred_output, _, _), _ = instance.inference(data_loader.test_loader)
print(pred_output)
```
> ['what is the salary for a soccer player?', 'what do soccer players earn?']
## Inference with multiple outputs
If you want to generate multiple diverse paraphrases for each input (aka 'top-k' inference), have a look at `./examples/topk.ipynb`.
## Training from scratch
Train a fresh checkpoint using:
```
torchseq --train --config ./configs/hrqvae_paralex.json
```
## Training on a new dataset
To use a different dataset, you will need to generate a total of 4 datasets. These should be folders in `./data`, containing `{train,dev,test}.jsonl` files.
An example of this process is given in `./scripts/MSCOCO.ipynb`.
#### A cluster dataset, that is a list of the paraphrase clusters
```
{"qs": ["What are some good science documentaries?", "What is a good documentary on science?", "What is the best science documentary you have ever watched?", "Can you recommend some good documentaries in science?", "What the best science documentaries?"]}
{"qs": ["What do we use water for?", "Why do we, as human beings, use water for?"]}
...
```
#### A flattened dataset, that is just a list of all the paraphrases
The sentences must be in the same order as in the cluster dataset!
```
{"q": "Can you recommend some good documentaries in science?"}
{"q": "What the best science documentaries?"}
{"q": "What do we use water for?"}
...
```
#### The training triples
Generate this using the following command for question datasets:
```
python3 ./scripts/generate_training_triples.py --use_diff_templ_for_sem --rate 1.0 --sample_size 26 --extended_stopwords --real_exemplars --exhaustive --template_dropout 0.3 --dataset qqp-clusters --min_samples 0
```
Or this command for other datasets:
```
python3 ./scripts/generate_training_triples.py --use_diff_templ_for_sem --rate 1.0 --sample_size 26 --pos_templates --extended_stopwords --no_stopwords --real_exemplars --exhaustive --template_dropout 0.3 --dataset mscoco-clusters --min_samples 0
```
Replace `qqp-clusters` with the path to your dataset in "cluster" format.
#### A dataset to use for evaluation
For each cluster, select a single sentence to use as the input (assigned to `sem_input`) and add all the other references to `paras`. `tgt` and `syn_input` should be set to one of references.
```
{"tgt": "What are some good science documentaries?", "syn_input": "What are some good science documentaries?", "sem_input": "Can you recommend some good documentaries in science?", "paras": ["What are some good science documentaries?", "What the best science documentaries?", "What is the best science documentary you have ever watched?", "What is a good documentary on science?"]}
{"tgt": "What do we use water for?", "syn_input": "What do we use water for?", "sem_input": "Why do we, as human beings, use water for?", "paras": ["What do we use water for?"]}
...
```
#### Train the model
Have a look at the config files, eg `configs/hrqvae_qqp.json`, and update all the references to the different datasets, then run:
`torchseq --train --config ./configs/hrqvae_mydataset.json`
## Use HRQ-VAE in your project
Have a look at `./src/hrq_vae.py` for our implementation.
## Citation
```
@inproceedings{hosking-etal-2022-hierarchical,
title = "Hierarchical Sketch Induction for Paraphrase Generation",
author = "Hosking, Tom and
Tang, Hao and
Lapata, Mirella",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.178",
pages = "2489--2501",
}
```