https://github.com/travisvn/openai-edge-tts
Text-to-speech API endpoint compatible with OpenAI's TTS API endpoint, using Microsoft Edge TTS to generate speech for free locally
https://github.com/travisvn/openai-edge-tts
ai chatgpt edge-tts llm llm-webui llms ollama ollama-webui open-webui openai self-hosted speech text-to-speech tts
Last synced: over 1 year ago
JSON representation
Text-to-speech API endpoint compatible with OpenAI's TTS API endpoint, using Microsoft Edge TTS to generate speech for free locally
- Host: GitHub
- URL: https://github.com/travisvn/openai-edge-tts
- Owner: travisvn
- License: gpl-3.0
- Created: 2024-10-09T23:31:11.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-10-23T21:33:46.000Z (over 1 year ago)
- Last Synced: 2024-10-24T09:58:42.566Z (over 1 year ago)
- Topics: ai, chatgpt, edge-tts, llm, llm-webui, llms, ollama, ollama-webui, open-webui, openai, self-hosted, speech, text-to-speech, tts
- Language: Python
- Homepage:
- Size: 73.2 KB
- Stars: 80
- Watchers: 3
- Forks: 14
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-ChatGPT-repositories - openai-edge-tts - Free, high-quality text-to-speech API endpoint to replace OpenAI, Azure, or ElevenLabs (NLP)
README
# OpenAI-Compatible Edge-TTS API 🗣️





[](https://discord.gg/GkFbBCBqJ6)
[](https://linkedin.com/in/travisvannimwegen)
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API.
`edge-tts` uses Microsoft Edge's online text-to-speech service, so it is completely free.
[View this project on Docker Hub](https://hub.docker.com/r/travisvn/openai-edge-tts)
# Please ⭐️ star this repo if you find it helpful
## Features
- **OpenAI-Compatible Endpoint**: `/v1/audio/speech` with similar request structure and behavior.
- **Supported Voices**: Maps OpenAI voices (alloy, echo, fable, onyx, nova, shimmer) to `edge-tts` equivalents.
- **Flexible Formats**: Supports multiple audio formats (mp3, opus, aac, flac, wav, pcm).
- **Adjustable Speed**: Option to modify playback speed (0.25x to 4.0x).
- **Optional Direct Edge-TTS Voice Selection**: Use either OpenAI voice mappings or specify any edge-tts voice directly.
## Getting Started
### Prerequisites
- **Docker** (recommended): Docker and Docker Compose for containerized setup.
- **Python** (optional): For local development, install dependencies in `requirements.txt`.
- **ffmpeg** (optional): Required for audio format conversion. Optional if sticking to mp3.
### Installation
1. **Clone the Repository**:
```bash
git clone https://github.com/travisvn/openai-edge-tts.git
cd openai-edge-tts
```
2. **Environment Variables**: Create a `.env` file in the root directory with the following variables:
```
API_KEY=your_api_key_here
PORT=5050
DEFAULT_VOICE=en-US-AvaNeural
DEFAULT_RESPONSE_FORMAT=mp3
DEFAULT_SPEED=1.0
DEFAULT_LANGUAGE=en-US
REQUIRE_API_KEY=True
REMOVE_FILTER=False
EXPAND_API=True
```
Or, copy the default `.env.example` with the following:
```bash
cp .env.example .env
```
3. **Run with Docker Compose** (recommended):
```bash
docker compose up --build
```
_(Note: docker-compose is not the same as docker compose)_
Run with `-d` to run docker compose in "detached mode", meaning it will run in the background and free up your terminal.
```bash
docker compose up -d
```
Alternatively, **run directly with Docker**:
```bash
docker build -t openai-edge-tts .
docker run -p 5050:5050 --env-file .env openai-edge-tts
```
To run the container in the background, add `-d` after the `docker run` command:
```bash
docker run -d -p 5050:5050 --env-file .env openai-edge-tts
```
4. **Access the API**: Your server will be accessible at `http://localhost:5050`.
## Running with Python
If you prefer to run this project directly with Python, follow these steps to set up a virtual environment, install dependencies, and start the server.
### 1. Clone the Repository
```bash
git clone https://github.com/travisvn/openai-edge-tts.git
cd openai-edge-tts
```
### 2. Set Up a Virtual Environment
Create and activate a virtual environment to isolate dependencies:
```bash
# For macOS/Linux
python3 -m venv venv
source venv/bin/activate
# For Windows
python -m venv venv
venv\Scripts\activate
```
### 3. Install Dependencies
Use `pip` to install the required packages listed in `requirements.txt`:
```bash
pip install -r requirements.txt
```
### 4. Configure Environment Variables
Create a `.env` file in the root directory and set the following variables:
```plaintext
API_KEY=your_api_key_here
PORT=5050
DEFAULT_VOICE=en-US-AvaNeural
DEFAULT_RESPONSE_FORMAT=mp3
DEFAULT_SPEED=1.0
DEFAULT_LANGUAGE=en-US
REQUIRE_API_KEY=True
REMOVE_FILTER=False
EXPAND_API=True
```
### 5. Run the Server
Once configured, start the server with:
```bash
python app/server.py
```
The server will start running at `http://localhost:5050`.
### 6. Test the API
You can now interact with the API at `http://localhost:5050/v1/audio/speech` and other available endpoints. See the [Usage](#usage) section for request examples.
### Usage
#### Endpoint: `/v1/audio/speech`
Generates audio from the input text. Available parameters:
**Required Parameter:**
- **input** (string): The text to be converted to audio (up to 4096 characters).
**Optional Parameters:**
- **model** (string): Set to "tts-1" or "tts-1-hd" (default: `"tts-1"`).
- **voice** (string): One of the OpenAI-compatible voices (alloy, echo, fable, onyx, nova, shimmer) or any valid `edge-tts` voice (default: `"en-US-AvaNeural"`).
- **response_format** (string): Audio format. Options: `mp3`, `opus`, `aac`, `flac`, `wav`, `pcm` (default: `mp3`).
- **speed** (number): Playback speed (0.25 to 4.0). Default is `1.0`.
Example request with `curl` and saving the output to an mp3 file:
```bash
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
"voice": "echo",
"response_format": "mp3",
"speed": 1.1
}' \
--output speech.mp3
```
Or, to be in line with the OpenAI API endpoint parameters:
```bash
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"model": "tts-1",
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
"voice": "alloy"
}' \
--output speech.mp3
```
And an example of a language other than English:
```bash
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"model": "tts-1",
"input": "じゃあ、行く。電車の時間、調べておくよ。",
"voice": "ja-JP-KeitaNeural"
}' \
--output speech.mp3
```
### Additional Endpoints
- **POST/GET /v1/models**: Lists available TTS models.
- **POST/GET /v1/voices**: Lists `edge-tts` voices for a given language / locale.
- **POST/GET /v1/voices/all**: Lists all `edge-tts` voices, with language support information.
### Contributing
Contributions are welcome! Please fork the repository and create a pull request for any improvements.
### License
This project is licensed under GNU General Public License v3.0 (GPL-3.0), and the acceptable use-case is intended to be personal use. For enterprise or non-personal use of `openai-edge-tts`, contact me at tts@travisvn.com
___
## Example Use Case
> [!TIP]
> Swap `localhost` to your local IP (ex. `192.168.0.1`) if you have issues
>
> _It may be the case that, when accessing this endpoint on a different server / computer or when the call is made from another source (like Open WebUI), you need to change the URL from `localhost` to your local IP (something like `192.168.0.1` or similar)_
# Open WebUI
Open up the Admin Panel and go to Settings -> Audio
Below, you can see a screenshot of the correct configuration for using this project to substitute the OpenAI endpoint
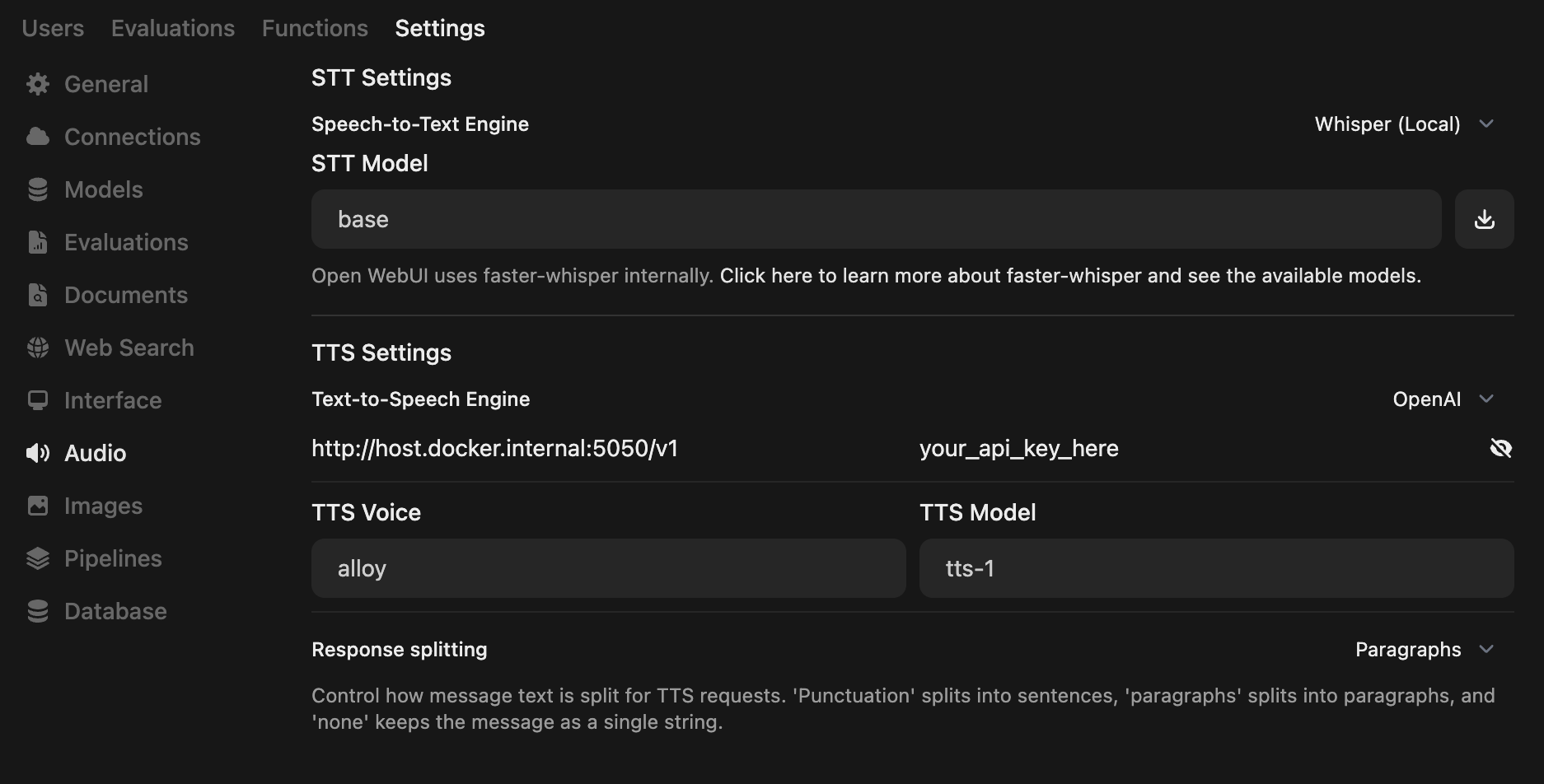
If you're running both Open WebUI and this project in Docker, the API endpoint URL is probably `http://host.docker.internal:5050/v1`
> [!NOTE]
> View the official docs for [Open WebUI integration with OpenAI Edge TTS](https://docs.openwebui.com/tutorials/text-to-speech/openai-edge-tts-integration)
# AnythingLLM
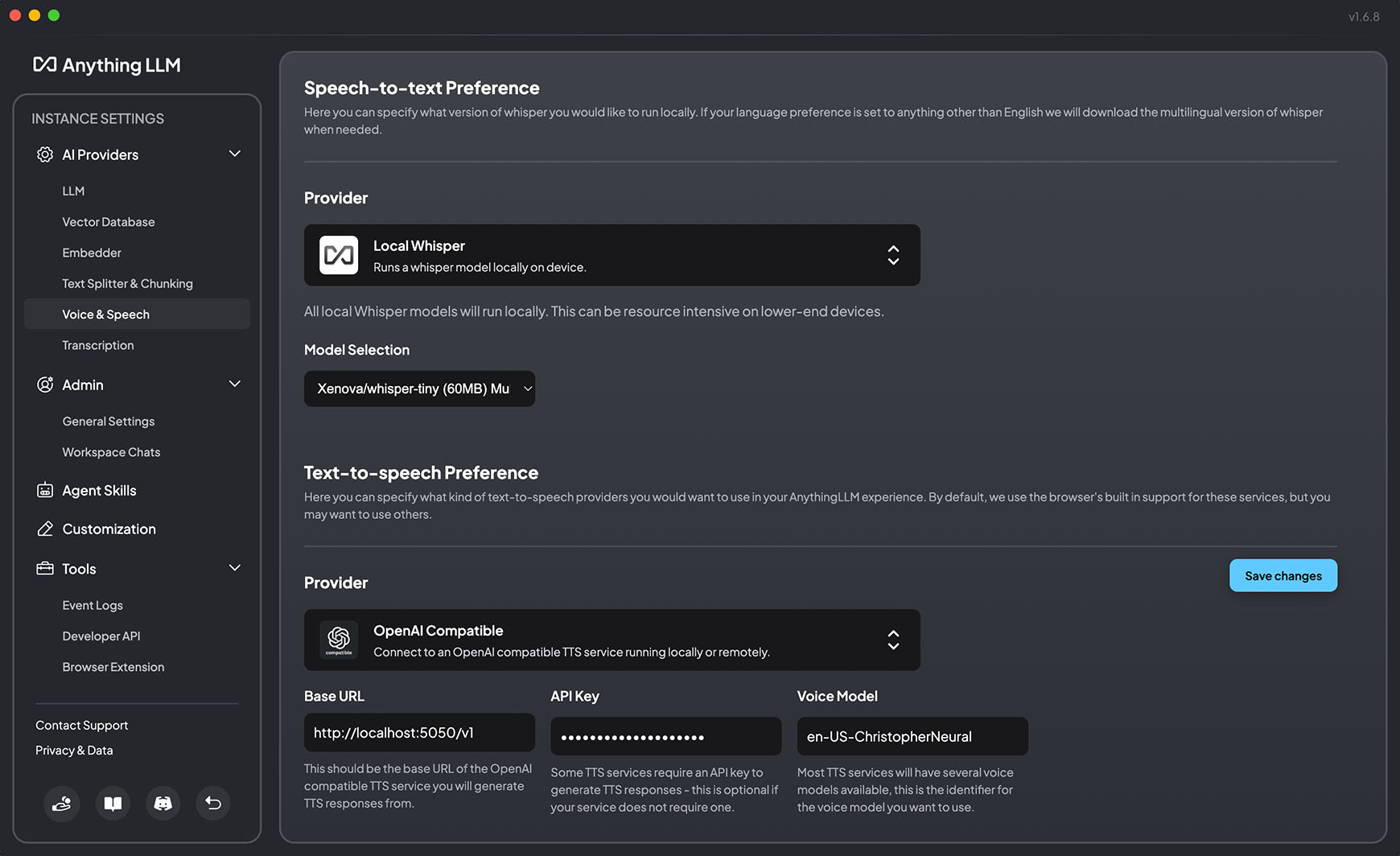
In version 1.6.8, AnythingLLM added support for "generic OpenAI TTS providers" — meaning we can use this project as the TTS provider in AnythingLLM
Open up settings and go to Voice & Speech (Under AI Providers)
Below, you can see a screenshot of the correct configuration for using this project to substitute the OpenAI endpoint
___
## Quick Info
- `your_api_key_here` never needs to be replaced — No "real" API key is required. Use whichever string you'd like.
- The quickest way to get this up and running is to install docker and run the command below:
```bash
docker run -d -p 5050:5050 -e API_KEY=your_api_key_here -e PORT=5050 travisvn/openai-edge-tts:latest
```
___
# Voice Samples 🎙️
[Play voice samples and see all available Edge TTS voices](https://tts.travisvn.com/)