https://github.com/ufoym/imbalanced-dataset-sampler
A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones.
https://github.com/ufoym/imbalanced-dataset-sampler
data-sampling image-classification imbalanced-data pytorch
Last synced: about 1 year ago
JSON representation
A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones.
- Host: GitHub
- URL: https://github.com/ufoym/imbalanced-dataset-sampler
- Owner: ufoym
- License: mit
- Created: 2018-05-29T02:15:17.000Z (about 8 years ago)
- Default Branch: master
- Last Pushed: 2025-04-07T19:45:17.000Z (over 1 year ago)
- Last Synced: 2025-05-08T12:01:59.067Z (about 1 year ago)
- Topics: data-sampling, image-classification, imbalanced-data, pytorch
- Language: Python
- Homepage:
- Size: 181 KB
- Stars: 2,301
- Watchers: 32
- Forks: 265
- Open Issues: 32
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-imbalanced-learning - imbalanced-dataset-sampler - A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones. (3.2 Github Repositories / 3.2.1 *Algorithms & Utilities & Jupyter Notebooks*)
README
# Imbalanced Dataset Sampler

## Introduction
In many machine learning applications, we often come across datasets where some types of data may be seen more than other types. Take identification of rare diseases for example, there are probably more normal samples than disease ones. In these cases, we need to make sure that the trained model is not biased towards the class that has more data. As an example, consider a dataset where there are 5 disease images and 20 normal images. If the model predicts all images to be normal, its accuracy is 80%, and F1-score of such a model is 0.88. Therefore, the model has high tendency to be biased toward the ‘normal’ class.
To solve this problem, a widely adopted technique is called resampling. It consists of removing samples from the majority class (under-sampling) and / or adding more examples from the minority class (over-sampling). Despite the advantage of balancing classes, these techniques also have their weaknesses (there is no free lunch). The simplest implementation of over-sampling is to duplicate random records from the minority class, which can cause overfitting. In under-sampling, the simplest technique involves removing random records from the majority class, which can cause loss of information.

In this repo, we implement an easy-to-use PyTorch sampler `ImbalancedDatasetSampler` that is able to
- rebalance the class distributions when sampling from the imbalanced dataset
- estimate the sampling weights automatically
- avoid creating a new balanced dataset
- mitigate overfitting when it is used in conjunction with data augmentation techniques
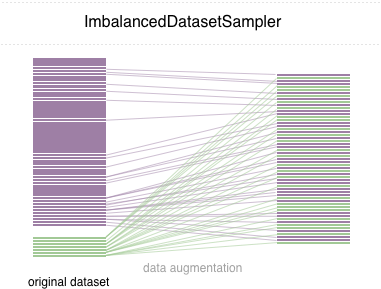
## Usage
For a simple start install the package via one of following ways:
```bash
pip install torchsampler
```
Simply pass an `ImbalancedDatasetSampler` for the parameter `sampler` when creating a `DataLoader`.
For example:
```python
from torchsampler import ImbalancedDatasetSampler
train_loader = torch.utils.data.DataLoader(
train_dataset,
sampler=ImbalancedDatasetSampler(train_dataset),
batch_size=args.batch_size,
**kwargs
)
```
Then in each epoch, the loader will sample the entire dataset and weigh your samples inversely to your class appearing probability.
## Example: Imbalanced MNIST Dataset
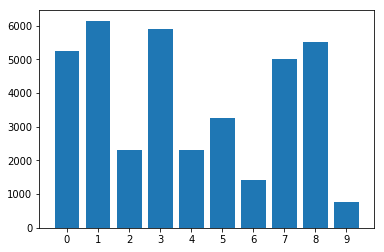
Distribution of classes in the imbalanced dataset:
With Imbalanced Dataset Sampler:
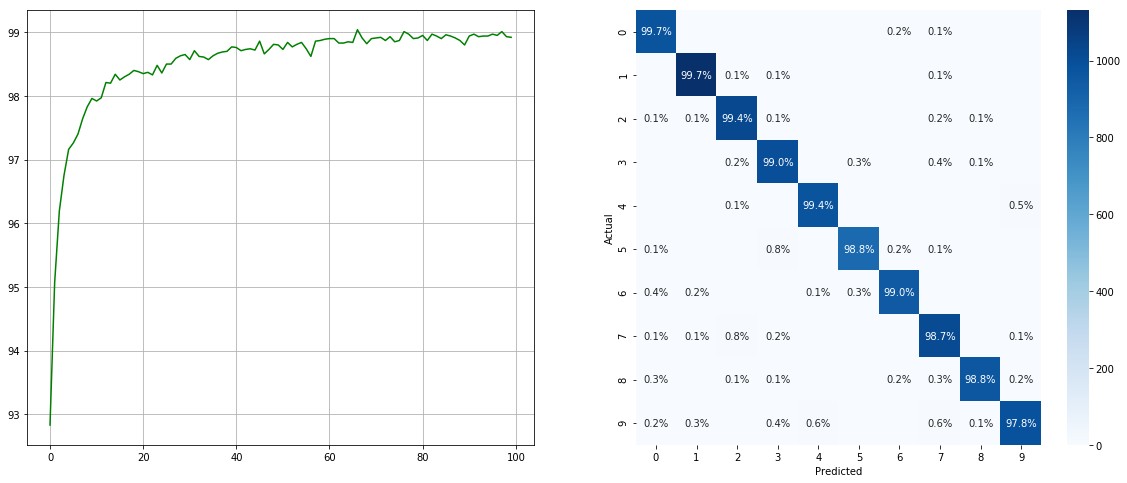
(left: test acc in each epoch; right: confusion matrix)
Without Imbalanced Dataset Sampler:
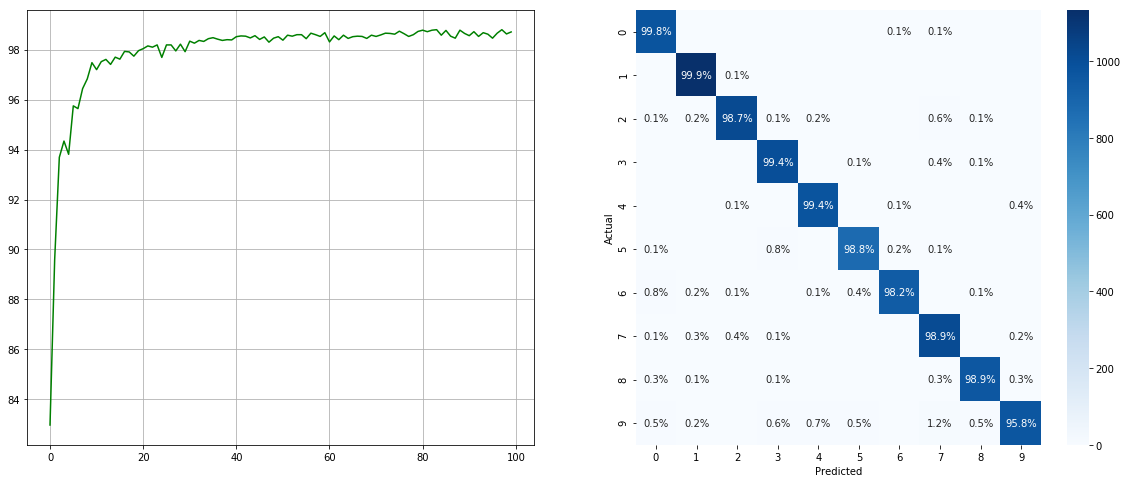
(left: test acc in each epoch; right: confusion matrix)
Note that there are significant improvements for minor classes such as `2` `6` `9`, while the accuracy of the other classes is preserved.
## Contributing
We appreciate all contributions. If you are planning to contribute back bug-fixes, please do so without any further discussion. If you plan to contribute new features, utility functions or extensions, please first open an issue and discuss the feature with us.
## Licensing
[MIT licensed](https://github.com/ufoym/imbalanced-dataset-sampler/blob/master/LICENSE).