https://github.com/uptrain-ai/uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured checks (covering language, code, embedding use-cases), perform root cause analysis on failure cases and give insights on how to resolve them.
https://github.com/uptrain-ai/uptrain
autoevaluation evaluation experimentation hallucination-detection jailbreak-detection llm-eval llm-prompting llm-test llmops machine-learning monitoring openai-evals prompt-engineering root-cause-analysis
Last synced: about 1 year ago
JSON representation
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured checks (covering language, code, embedding use-cases), perform root cause analysis on failure cases and give insights on how to resolve them.
- Host: GitHub
- URL: https://github.com/uptrain-ai/uptrain
- Owner: uptrain-ai
- License: apache-2.0
- Created: 2022-11-07T07:29:06.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2024-08-18T13:30:44.000Z (almost 2 years ago)
- Last Synced: 2025-05-09T14:16:24.198Z (about 1 year ago)
- Topics: autoevaluation, evaluation, experimentation, hallucination-detection, jailbreak-detection, llm-eval, llm-prompting, llm-test, llmops, machine-learning, monitoring, openai-evals, prompt-engineering, root-cause-analysis
- Language: Python
- Homepage: https://uptrain.ai/
- Size: 36.9 MB
- Stars: 2,261
- Watchers: 19
- Forks: 198
- Open Issues: 52
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Security: SECURITY.md
Awesome Lists containing this project
- StarryDivineSky - uptrain-ai/uptrain
- awesome-production-machine-learning - UpTrain - ai/uptrain.svg?style=social) - UpTrain is an open-source tool for evaluating LLM applications. (Evaluation and Monitoring)
- Awesome-LLM-RAG-Application - uptrain - ai/uptrain) (开源工具 / 评测框架)
- awesome-evals - UpTrain - ai/uptrain> — 20+ preconfigured checks + root-cause analysis on failures. (5 · Evaluation infrastructure (the eval stack: datasets, scorers, online/offline, tracing, CI) / 5a · Eval frameworks & harnesses (code-first test-runners))
- awesome-ai-eval - **UpTrain** - ai/uptrain?style=social&label=github.com) - OSS/hosted evaluation suite with 20+ checks, RCA tooling, and LlamaIndex integrations. (Platforms / Open Source Platforms)
- awesome-infra-for-ai - uptrain-ai/uptrain - UpTrain is an open-source platform providing evaluation and monitoring for Generative AI applications, offering preconfigured checks, root cause analysis, and production monitoring for LLMs. (LLMOps / LLM Evaluation & Testing)
README










**[UpTrain](https://uptrain.ai)** is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for [20+ preconfigured evaluations](https://github.com/uptrain-ai/uptrain?tab=readme-ov-file#pre-built-evaluations-we-offer-) (covering language, code, embedding use cases), perform [root cause analysis](https://github.com/uptrain-ai/uptrain/blob/main/examples/root_cause_analysis/rag_with_citation.ipynb) on failure cases and give insights on how to resolve them.
# Key Features 🔑

UpTrain Dashboard is a web-based interface that runs on your **local machine**. You can use the dashboard to evaluate your LLM applications, view the results, and perform a root cause analysis.

Support for **20+ pre-configured evaluations** such as Response Completeness, Factual Accuracy, Context Conciseness etc.

All the evaluations and analysis run locally on your system, ensuring that the data never leaves your secure environment (except for LLM calls while using model grading checks)

**Experiment with different embedding models** like text-embedding-3-large/small, text-embedding-3-ada, baai/bge-large, etc. UpTrain supports HuggingFace models, Replicate endpoints, or custom models hosted on your endpoint.

You can **perform root cause analysis** on cases with either negative user feedback or low evaluation scores to understand which part of your LLM pipeline is giving suboptimal results. Check out the supported RCA templates.

We allow you to use any of OpenAI, Anthropic, Mistral, Azure's Openai endpoints or open-source LLMs hosted on Anyscale to be used as evaluators.

UpTrain provides tons of ways to **customize evaluations**. You can customize the evaluation method (chain of thought vs classify), few-shot examples, and scenario description. You can also create custom evaluators.
### Coming Soon:
1. Collaborate with your team
2. Embedding visualization via UMAP and Clustering
3. Pattern recognition among failure cases
4. Prompt improvement suggestions
# Getting Started 🙌
## Method 1: Using the Locally Hosted Dashboard
The UpTrain dashboard is a web-based interface that allows you to evaluate your LLM applications. It is a self-hosted dashboard that runs on your local machine.
You don't need to write any code to use the dashboard. You can use the dashboard to evaluate your LLM applications, view the results, and perform a root cause analysis.
Before you start, ensure you have docker installed on your machine. If not, you can install it from [here](https://docs.docker.com/get-docker/).
The following commands will download the UpTrain dashboard and start it on your local machine.
```bash
# Clone the repository
git clone https://github.com/uptrain-ai/uptrain
cd uptrain
# Run UpTrain
bash run_uptrain.sh
```
> **NOTE:** UpTrain Dashboard is currently in **Beta version**. We would love your feedback to improve it.
## Method 2: Using the UpTrain package
If you are a developer and want to integrate UpTrain evaluations into your application, you can use the UpTrain package. This allows for a more programmatic way to evaluate your LLM applications.
### Install the package through pip:
```bash
pip install uptrain
```
### How to use UpTrain:
You can evaluate your responses via the open-source version by providing your OpenAI API key to run evaluations.
```python
from uptrain import EvalLLM, Evals
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question': 'Which is the most popular global sport?',
'context': "The popularity of sports can be measured in various ways, including TV viewership, social media presence, number of participants, and economic impact. Football is undoubtedly the world's most popular sport with major events like the FIFA World Cup and sports personalities like Ronaldo and Messi, drawing a followership of more than 4 billion people. Cricket is particularly popular in countries like India, Pakistan, Australia, and England. The ICC Cricket World Cup and Indian Premier League (IPL) have substantial viewership. The NBA has made basketball popular worldwide, especially in countries like the USA, Canada, China, and the Philippines. Major tennis tournaments like Wimbledon, the US Open, French Open, and Australian Open have large global audiences. Players like Roger Federer, Serena Williams, and Rafael Nadal have boosted the sport's popularity. Field Hockey is very popular in countries like India, Netherlands, and Australia. It has a considerable following in many parts of the world.",
'response': 'Football is the most popular sport with around 4 billion followers worldwide'
}]
eval_llm = EvalLLM(openai_api_key=OPENAI_API_KEY)
results = eval_llm.evaluate(
data=data,
checks=[Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_COMPLETENESS]
)
print(json.dumps(results, indent=3))
```
If you have any questions, please join our [Slack community](https://join.slack.com/t/uptraincommunity/shared_invite/zt-1yih3aojn-CEoR_gAh6PDSknhFmuaJeg)
Speak directly with the maintainers of UpTrain by [booking a call here](https://calendly.com/uptrain-sourabh/30min).
# Pre-built Evaluations We Offer 📝

| Eval | Description |
| ---- | ----------- |
|[Response Completeness](https://docs.uptrain.ai/predefined-evaluations/response-quality/response-completeness) | Grades whether the response has answered all the aspects of the question specified. |
|[Response Conciseness](https://docs.uptrain.ai/predefined-evaluations/response-quality/response-conciseness) | Grades how concise the generated response is or if it has any additional irrelevant information for the question asked. |
|[Response Relevance](https://docs.uptrain.ai/predefined-evaluations/response-quality/response-relevance)| Grades how relevant the generated context was to the question specified.|
|[Response Validity](https://docs.uptrain.ai/predefined-evaluations/response-quality/response-validity)| Grades if the response generated is valid or not. A response is considered to be valid if it contains any information.|
|[Response Consistency](https://docs.uptrain.ai/predefined-evaluations/response-quality/response-consistency)| Grades how consistent the response is with the question asked as well as with the context provided.|

| Eval | Description |
| ---- | ----------- |
|[Context Relevance](https://docs.uptrain.ai/predefined-evaluations/context-awareness/context-relevance) | Grades how relevant the context was to the question specified. |
|[Context Utilization](https://docs.uptrain.ai/predefined-evaluations/context-awareness/context-utilization) | Grades how complete the generated response was for the question specified, given the information provided in the context. |
|[Factual Accuracy](https://docs.uptrain.ai/predefined-evaluations/context-awareness/factual-accuracy)| Grades whether the response generated is factually correct and grounded by the provided context.|
|[Context Conciseness](https://docs.uptrain.ai/predefined-evaluations/context-awareness/context-conciseness)| Evaluates the concise context cited from an original context for irrelevant information.
|[Context Reranking](https://docs.uptrain.ai/predefined-evaluations/context-awareness/context-reranking)| Evaluates how efficient the reranked context is compared to the original context.|

| Eval | Description |
| ---- | ----------- |
|[Language Features](https://docs.uptrain.ai/predefined-evaluations/language-quality/fluency-and-coherence) | Grades the quality and effectiveness of language in a response, focusing on factors such as clarity, coherence, conciseness, and overall communication. |
|[Tonality](https://docs.uptrain.ai/predefined-evaluations/code-evals/code-hallucination) | Grades whether the generated response matches the required persona's tone |

| Eval | Description |
| ---- | ----------- |
|[Code Hallucination](https://docs.uptrain.ai/predefined-evaluations/code-evals/code-hallucination) | Grades whether the code present in the generated response is grounded by the context. |

| Eval | Description |
| ---- | ----------- |
|[User Satisfaction](https://docs.uptrain.ai/predefined-evaluations/conversation-evals/user-satisfaction) | Grades how well the user's concerns are addressed and assesses their satisfaction based on provided conversation. |

Eval | Description |
| ---- | ----------- |
|[Custom Guideline](https://docs.uptrain.ai/predefined-evaluations/custom-evals/custom-guideline) | Allows you to specify a guideline and grades how well the LLM adheres to the provided guideline when giving a response. |
|[Custom Prompts](https://docs.uptrain.ai/predefined-evaluations/custom-evals/custom-prompt-eval) | Allows you to create your own set of evaluations. |

| Eval | Description |
| ---- | ----------- |
|[Response Matching](https://docs.uptrain.ai/predefined-evaluations/ground-truth-comparison/response-matching) | Compares and grades how well the response generated by the LLM aligns with the provided ground truth. |

| Eval | Description |
| ---- | ----------- |
|[Prompt Injection](https://docs.uptrain.ai/predefined-evaluations/safeguarding/prompt-injection) | Grades whether the user's prompt is an attempt to make the LLM reveal its system prompts. |
|[Jailbreak Detection](https://docs.uptrain.ai/predefined-evaluations/safeguarding/jailbreak) | Grades whether the user's prompt is an attempt to jailbreak (i.e. generate illegal or harmful responses). |

| Eval | Description |
| ---- | ----------- |
|[Sub-Query Completeness](https://docs.uptrain.ai/predefined-evaluations/query-quality/sub-query-completeness) | Evaluate whether all of the sub-questions generated from a user's query, taken together, cover all aspects of the user's query or not |
| [Multi-Query Accuracy](https://docs.uptrain.ai/predefined-evaluations/query-quality/multi-query-accuracy) | Evaluate whether the variants generated accurately represent the original query |
# Integrations 🤝
| Eval Frameworks | LLM Providers | LLM Packages | Serving frameworks | LLM Observability | Vector DBs |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| [OpenAI Evals](https://docs.uptrain.ai/tutorials/openai-evals) | [OpenAI](https://docs.uptrain.ai/llms/openai) | [LlamaIndex](https://docs.uptrain.ai/integrations/framework/llamaindex-methods/overview) | [Ollama](https://docs.uptrain.ai/llms/ollama) | [Langfuse](https://docs.uptrain.ai/integrations/observation-tools/langfuse) | [Qdrant](https://docs.uptrain.ai/integrations/vector_db/qdrant) |
| | [Azure](https://docs.uptrain.ai/llms/azure) | | [Together AI](https://docs.uptrain.ai/llms/together_ai) | [Helicone](https://docs.uptrain.ai/integrations/observation-tools/helicone) | [FAISS](https://docs.uptrain.ai/integrations/vector_db/faiss) |
| | [Claude](https://docs.uptrain.ai/llms/claude) | | [Anyscale](https://docs.uptrain.ai/llms/anyscale) | [Zeno](https://docs.uptrain.ai/integrations/observation-tools/zeno) | [Chroma](https://docs.uptrain.ai/integrations/vector_db/chroma) |
| | [Mistral](https://docs.uptrain.ai/llms/mistral) | | Replicate |
| | | | HuggingFace |
More integrations are coming soon. If you have a specific integration in mind, please let us know by [creating an issue](https://github.com/uptrain-ai/uptrain/issues).
# Monitoring Prompt Drift in LLMs: Benchmark by UpTrain
Most popular LLMs like GPT-4, GPT-3.5-turbo, Claude-2.1 etc., are closed-source, i.e. exposed via an API with very little visibility on what happens under the hood. There are many reported instances of prompt drift (or GPT-4 becoming lazy) and research work exploring the degradation in model quality. This benchmark is an attempt to track the change in model behaviour by evaluating its response on a fixed dataset.
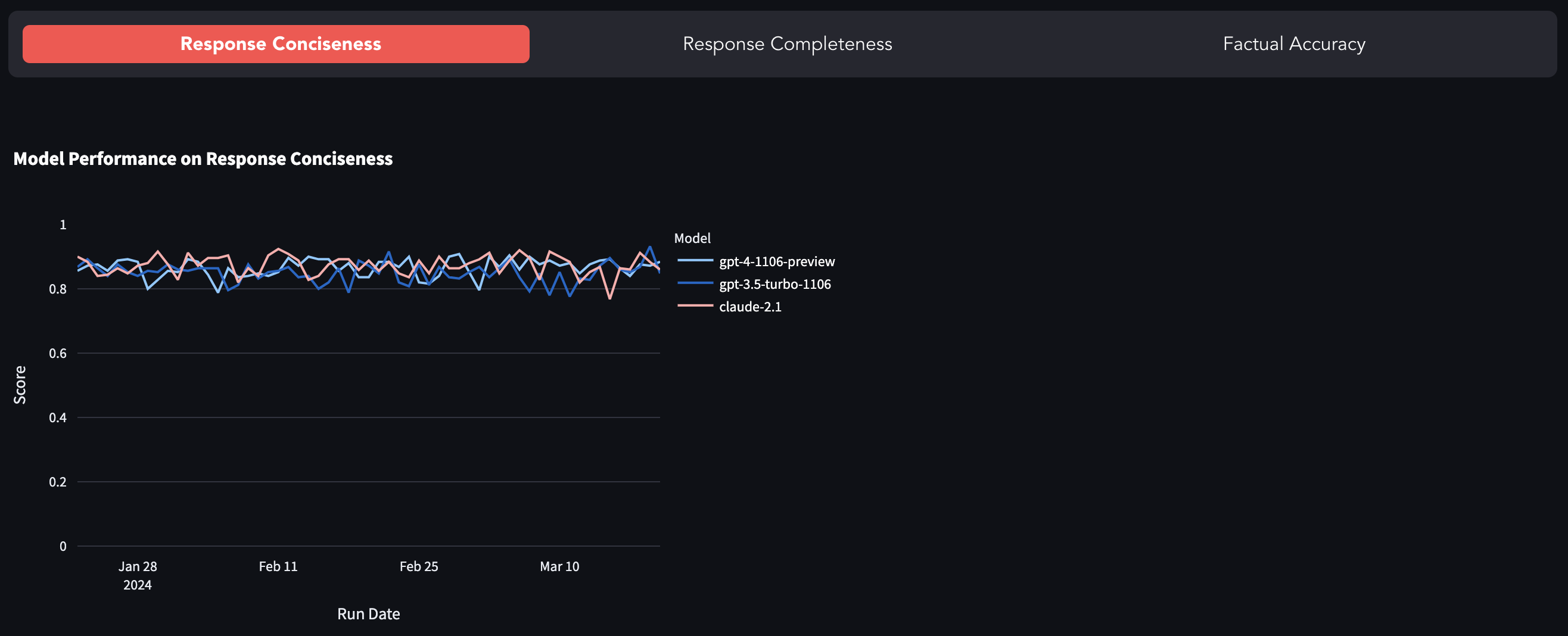
You can find the benchmark [here](https://demo.uptrain.ai/benchmark).
# Resources 💡
1. [How to evaluate your LLM application](https://blog.uptrain.ai/how-to-evaluate-your-llm-applications)
1. [How to detect jailbreaks](https://blog.uptrain.ai/llm-jailbreak/)
1. [Dealing with hallucinations](https://blog.uptrain.ai/dealing-with-hallucinations-in-llms-a-deep-dive/)
# Why we are building UpTrain 🤔
Having worked with ML and NLP models for the last 8 years, we were continuosly frustated with numerous hidden failures in our models which led to us building UpTrain. UpTrain was initially started as an ML observability tool with checks to identify regression in accuracy.
However we soon released that LLM developers face an even bigger problem -- there is no good way to measure accuracy of their LLM applications, let alone identify regression.
We also saw release of [OpenAI evals](https://github.com/openai/evals), where they proposed the use of LLMs to grade the model responses. Furthermore, we gained confidence to approach this after reading [how Anthropic leverages RLAIF](https://arxiv.org/pdf/2212.08073.pdf) and dived right into the LLM evaluations research (We are soon releasing a repository of awesome evaluations research).
So, come today, UpTrain is our attempt to bring order to LLM chaos and contribute back to the community. While a majority of developers still rely on intuition and productionise prompt changes by reviewing a couple of cases, we have heard enough regression stories to believe "evaluations and improvement" will be a key part of LLM ecosystem as the space matures.
1. Robust evaluations allows you to systematically experiment with different configurations and prevent any regressions by helping objectively select the best choice.
1. It helps you understand where your systems are going wrong, find the root cause(s) and fix them - long before your end users complain and potentially churn out.
1. Evaluations like prompt injection and jailbreak detection are essential to maintain safety and security of your LLM applications.
1. Evaluations help you provide transparency and build trust with your end-users - especially relevant if you are selling to enterprises.
# Why open-source?
1. We understand that there is **no one-size-fits-all solution** when it come to evaluations. We are increasingly seeing the desire from developers to modify the evaluation prompt or set of choices or the few shot examples, etc. We believe the best developer experience lies in open-source, instead of exposing 20 different parameters.
1. **Foster innovation**: The field of LLM evaluations and using LLM-as-a-judge is still pretty nascent. We see a lot of exciting research happening, almost on a daily basis and being open-source provides the right platform to us and our community to implement those techniques and innovate faster.
## How You Can Help 🙏
We are continuously striving to enhance UpTrain, and there are several ways you can contribute:
1. **Notice any issues or areas for improvement:** If you spot anything wrong or have ideas for enhancements, please [create an issue](https://github.com/uptrain-ai/uptrain/issues) on our GitHub repository.
1. **Contribute directly:** If you see an issue you can fix or have code improvements to suggest, feel free to contribute directly to the [repository](https://github.com/uptrain-ai/uptrain/blob/main/CONTRIBUTING.md).
1. **Request custom evaluations:** If your application requires a tailored evaluation, [let us know]((https://join.slack.com/t/uptraincommunity/shared_invite/zt-1yih3aojn-CEoR_gAh6PDSknhFmuaJeg)), and we'll add it to the repository.
1. **Integrate with your tools:** Need integration with your existing tools? [Reach out]((https://join.slack.com/t/uptraincommunity/shared_invite/zt-1yih3aojn-CEoR_gAh6PDSknhFmuaJeg)), and we'll work on it.
1. **Assistance with evaluations:** If you need assistance with evaluations, post your query on our [Slack channel](https://join.slack.com/t/uptraincommunity/shared_invite/zt-1yih3aojn-CEoR_gAh6PDSknhFmuaJeg), and we'll resolve it promptly.
1. **Show your support:** Show your support by starring us ⭐ on GitHub to track our progress.
1. **Spread the word:** If you like what we've built, give us a shoutout on Twitter!
Your contributions and support are greatly appreciated! Thank you for being a part of UpTrain's journey.
# License 💻
This repo is published under Apache 2.0 license and we are committed to adding more functionalities to the UpTrain open-source repo. We also have a managed version if you just want a more hands-off experience. Please book a [demo call here](https://calendly.com/uptrain-sourabh/30min).
# Provide feedback (Harsher the better 😉)
We are building UpTrain in public. Help us improve by giving your feedback **[here](https://docs.google.com/forms/d/e/1FAIpQLSezGUkkC0JoEvx-0gCrRSmGutA-jqyb7kl2lomXv302_C3MnQ/viewform?usp=sf_link)**.
# Contributors 🖥️
We welcome contributions to UpTrain. Please see our [contribution guide](https://github.com/uptrain-ai/uptrain/blob/main/CONTRIBUTING.md) for details.
