https://github.com/vaibhavs10/research-release-kit
https://github.com/vaibhavs10/research-release-kit
Last synced: 3 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/vaibhavs10/research-release-kit
- Owner: Vaibhavs10
- Created: 2024-12-09T16:45:46.000Z (7 months ago)
- Default Branch: main
- Last Pushed: 2024-12-09T16:52:23.000Z (7 months ago)
- Last Synced: 2025-02-04T13:45:48.743Z (5 months ago)
- Size: 20.5 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
ML Research Release Toolkit 🤗
**What is this doc?**
Congratulations on publishing your paper and sharing your research with the world! It's a huge accomplishment, but did you know you can increase the visibility and adoption of your work by releasing other parts of your research? That’s why we’ve put together this document, which provides a high-level overview of good practices and tips for helping to open-source your work.
**What does it mean to release Open Source research?**
Publishing your research - not just the paper, but some or all related artifacts, such as code, models, datasets, or online demos for people to try out.
**Why Open Source your ML research?**
By doing open-access research, you increase the adoption of your work and enable scientific reproducibility and collaborations with other researchers. By doing ML collaboratively, you share knowledge and resources in a community-centric way, advancing the ML field.
**What things can I do?**
ML releases come in all shapes and sizes. Depending on your timelines, priorities, internal policies, and other factors, you might just want to release the code, or you might want to release the models and other artifacts of your research.
Here is a high-level overview of things that can be done with a release:
- Release the paper
- Release the code repository
- Release the dataset
- Release the model
- Build an interactive demo
- Foster usage and adoption
**It’s up to you to define what, how, and when you want to release your artifacts**; this document provides guidance and tips. There is a section for each of the artifacts mentioned above.
**What tools will we use?**
We’ll use **arXiv** for sharing the paper. It’s a free open-access distribution service for papers widely used in the ML ecosystem.
We’ll use **GitHub** for sharing the code. GitHub is a platform for version control of code. On GitHub, you can share training code, examples on how to load the model or dataset, and more.
We’ll use **Hugging Face Hub** for distributing the model weights, datasets, and demos. HF is a platform of collaborative ML where people can easily explore, experiment, and build ML together. It also provides social features such as paper discussions.
**How to use this document?**
This document guides you through potential concrete items, but you don’t need to be all of them. Don’t be intimidated by all the subtasks; many take a minute, and they guide you as **you decide what to do**.
**We recommend duplicating this document.** Each section explains a different potential artifact. You'll find a checklist at the end of the doc to ensure you’re ready for the release.
**Examples of popular open-source releases**
- Llama 2 by Meta ([paper](https://arxiv.org/abs/2307.09288), [codebase](https://github.com/facebookresearch/llama), [models](https://huggingface.co/meta-llama), [demo](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat))
- Meditron by EPFL ([paper](https://arxiv.org/abs/2311.16079), [codebase](https://github.com/epfLLM/meditron), [model](https://huggingface.co/epfl-llm/meditron-7b), [data](https://huggingface.co/datasets/epfl-llm/guidelines))
- Fuyu by Adept ([blog](https://www.adept.ai/blog/fuyu-8b) , [model](https://huggingface.co/adept/fuyu-8b), [demo](https://huggingface.co/spaces/adept/fuyu-8b-demo))
- Seamless by Meta ([paper](https://arxiv.org/abs/2312.05187), [codebase](https://github.com/facebookresearch/seamless_communication), [collection](https://huggingface.co/collections/facebook/seamless-communication-6568d486ef451c6ba62c7724))
High-Quality GitHub Repos:
-
-
High-Quality Research Models
-
-
High-Quality Research Datasets
-
-
High-Quality Demos
-
-
## Release the paper
arXiv allows you to upload and share your paper with the community. It’s a free platform and does not require peer review.
1. Write your paper and prepare it for arXiv
The first step is writing your paper. A common tool for collaborative paper writing is [Overleaf](https://www.overleaf.com/) (for working in LaTeX). If submitting your paper to a conference, **follow their official template and style guides**.
Review arXiv’s official [guidelines](https://info.arxiv.org/help/submit/index.html), including the formatting expectations and licensing granting.

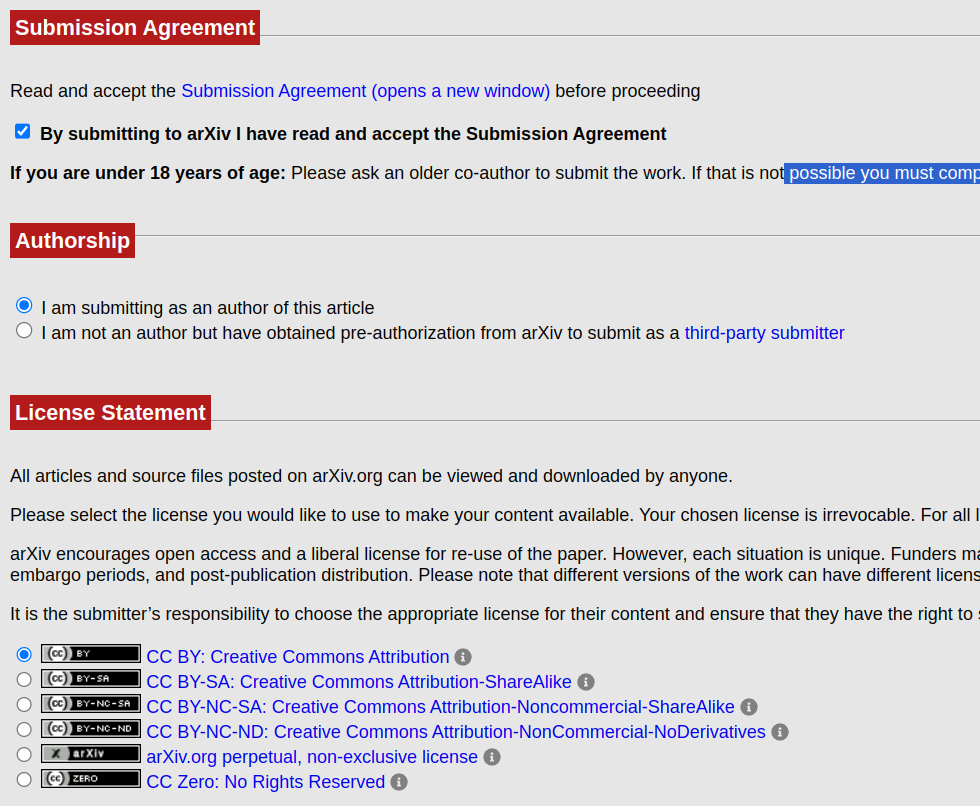
2. Submit your paper
Go to your [user page](https://arxiv.org/user/) and click “new submission”. Go through the process and submit! Submissions can take some time to be processed and are only made public [Sunday through Thursday](https://info.arxiv.org/help/availability.html).
**Note:** first-time submissions to a category require someone from the community to endorse[ it to be published](https://arxiv.org/auth/need-endorsement.php?tapir_dest=https%3A%2F%2Farxiv.org%2Fsubmit%2F5327946%2Fstart\&category_id=cs.AI). This is not a peer review!
## Release the code repository
We’ll use GitHub to share the code. GitHub is a platform for version control of code. On GitHub, you can share your codebase (either the inference/modeling code, the training code, or both!).
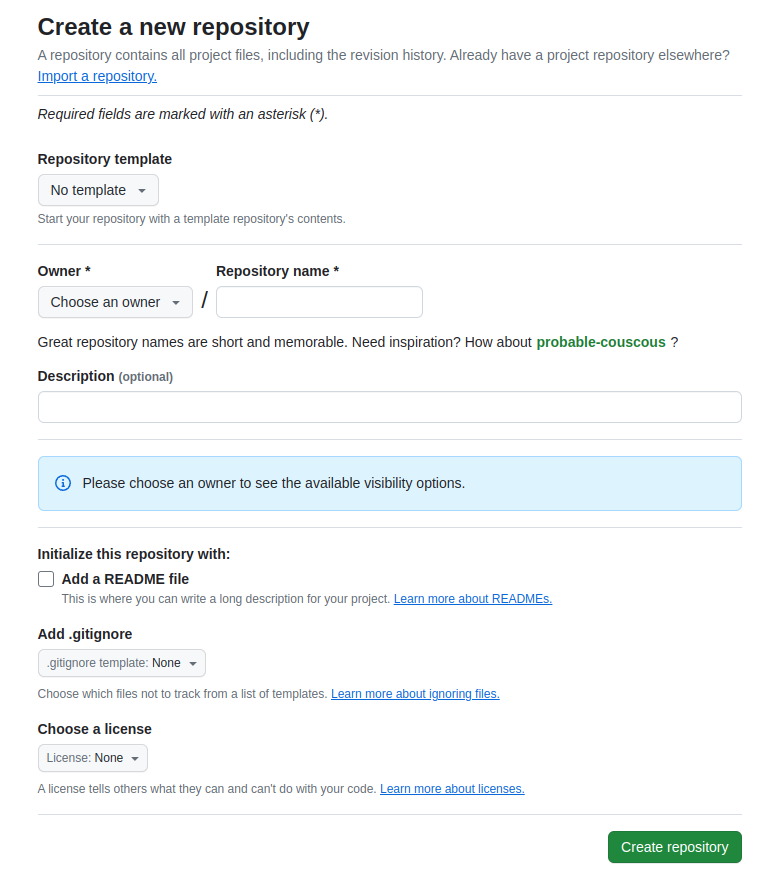
1. Create a repository at with a README and a license of your choice.
2. Write the README.
The README Is the file that describes the project. It’s written in markdown, a fairly simple language for text formatting. Having a description, links to artifacts (such as your paper), and some code examples is a great starting point.
Example
3. Upload your code
It’s now time to [upload your code](https://docs.github.com/en/repositories/working-with-files/managing-files/adding-a-file-to-a-repository)! What it is depends on your release! You can include code to run a model, training scripts, and more!
You might also want to integrate your model into a Hugging Face library to release with a day-0 integration. If that’s the case, feel free to contact so we can assess together and provide feedback.
## Release the dataset
The Hugging Face Hub provides hosting, discoverability, and social features for datasets. HF also provides an Open Source library, called [datasets](https://github.com/huggingface/datasets), that allows to load them programmatically, and even stream them efficiently in case they are huge. HF provides a viewer that allows users to explore the data directly in the browser.
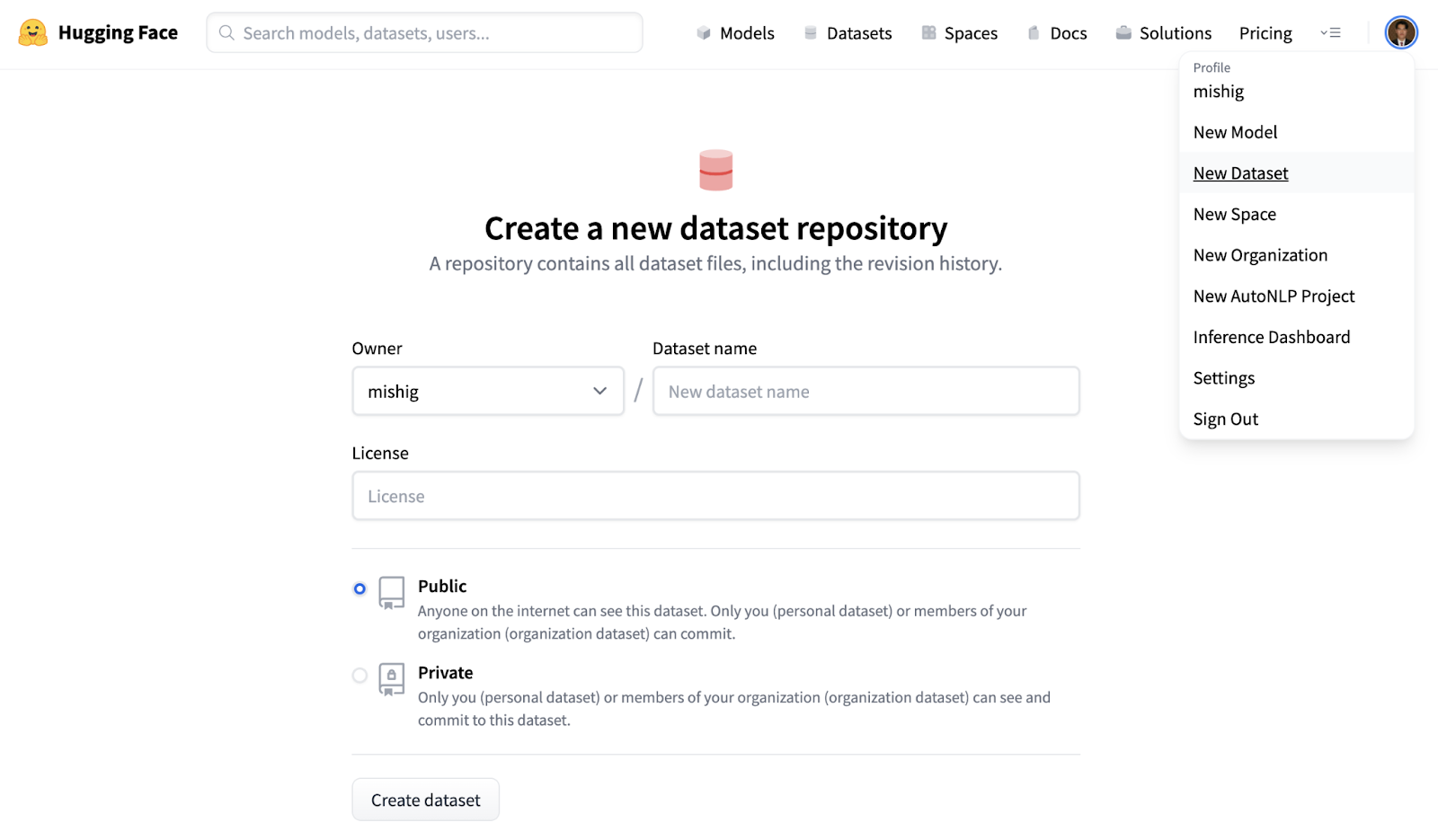
1. Create a repository at . You can create the repository in your account or under an organization.
2. Add files to the repository.
To do this, go to the **Files and versions** tab of the repository and click “Upload files”. You can drag and drop files/folders or upload them directly.
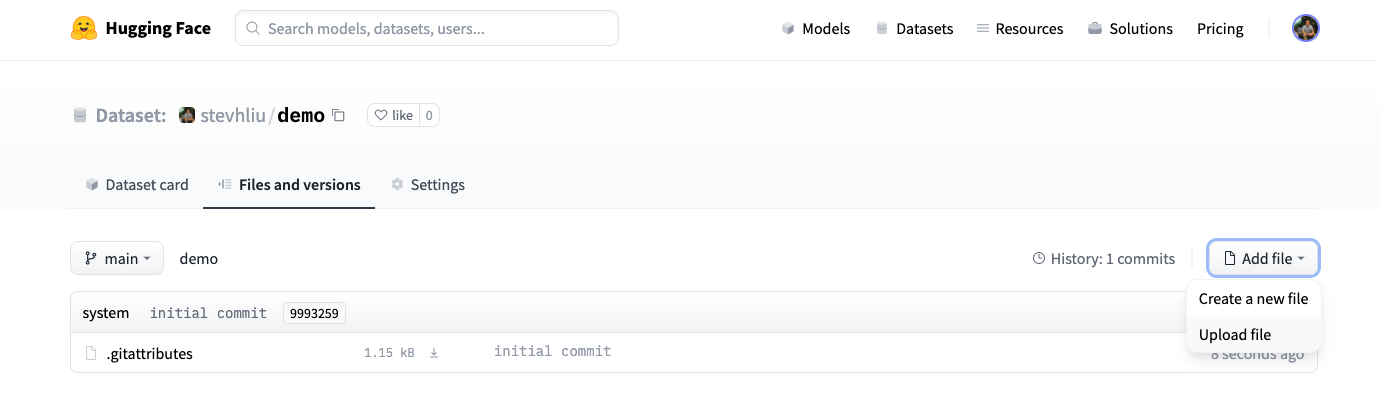
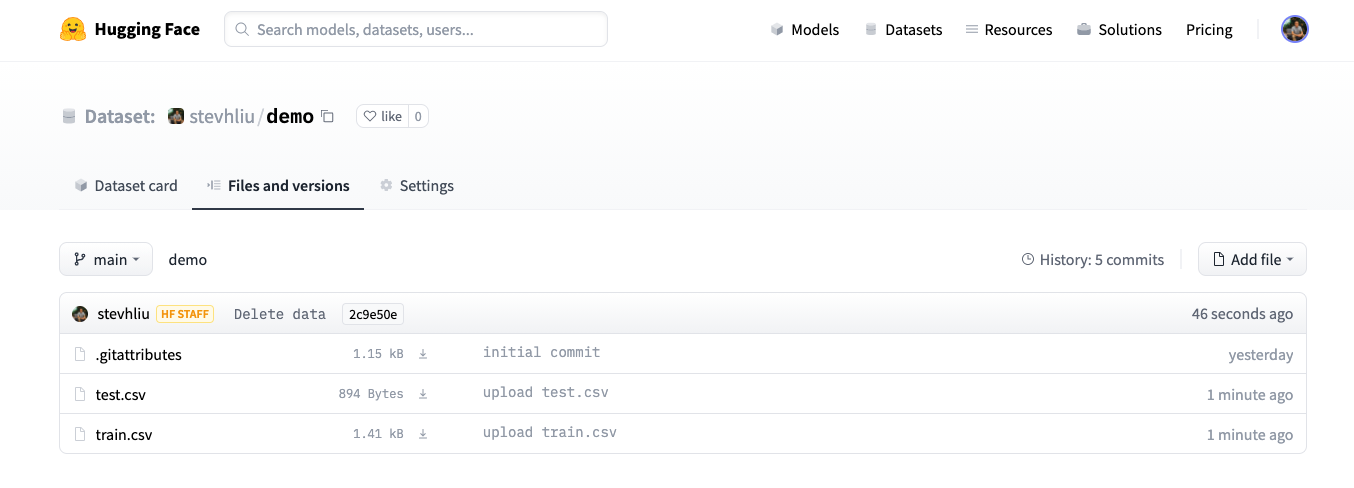
**Note:** The Hub supports different file [formats](https://huggingface.co/docs/hub/datasets-adding#file-formats). Those formats will get a viewer in the browser and automatically be supported in the datasets library. For other formats, you can still write your own loading script. Check out the [official documentation](https://huggingface.co/docs/datasets/create_dataset).
from datasets import load_dataset
dataset = load_dataset("stevhliu/demo")
**Note:** HF uses git-based repositories under the hood. If you’re familiar with Git (e.g., if you use GitHub or GitLab), you can use similar workflows rather than the UI. Find more information in the [guide](https://huggingface.co/docs/hub/repositories-getting-started#terminal). You can also use the [datasets library](https://huggingface.co/docs/datasets/upload_dataset) to push repositories.
3. Create a dataset card
Dataset cards are files that accompany the dataset and provide handy information. They are essential for discoverability, reproducibility, and sharing! You can find a dataset card as the README.md file in any repo.
Apart from the main content, dataset cards contain useful metadata at the top. The UI has utilities to get you started with it. We strongly encourage defining **license** and **task\_categories** (which specify the task of the data, such as text-to-image). Both are key for discoverability and usage.
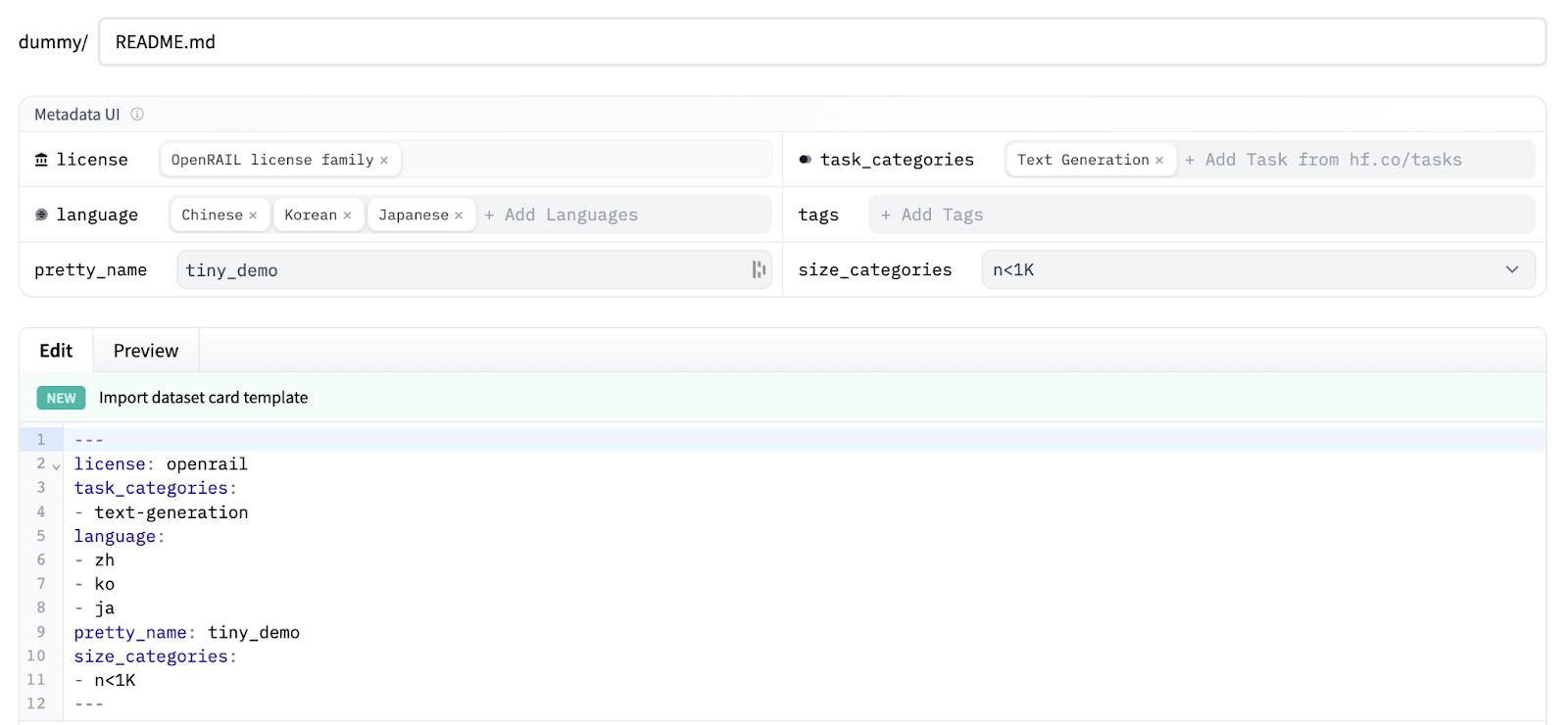
We suggest adding a link to your arXiv paper in the dataset card content. HF automatically links both together.
You can read more about dataset cards in its [official documentation](https://huggingface.co/docs/hub/datasets-adding).
## Release the model weights.
The Hugging Face Hub provides hosting, discoverability, and social features for models. It’s not constrained to HF official libraries, you can **share model weights of your favorite ML libraries** (or from your research codebase).
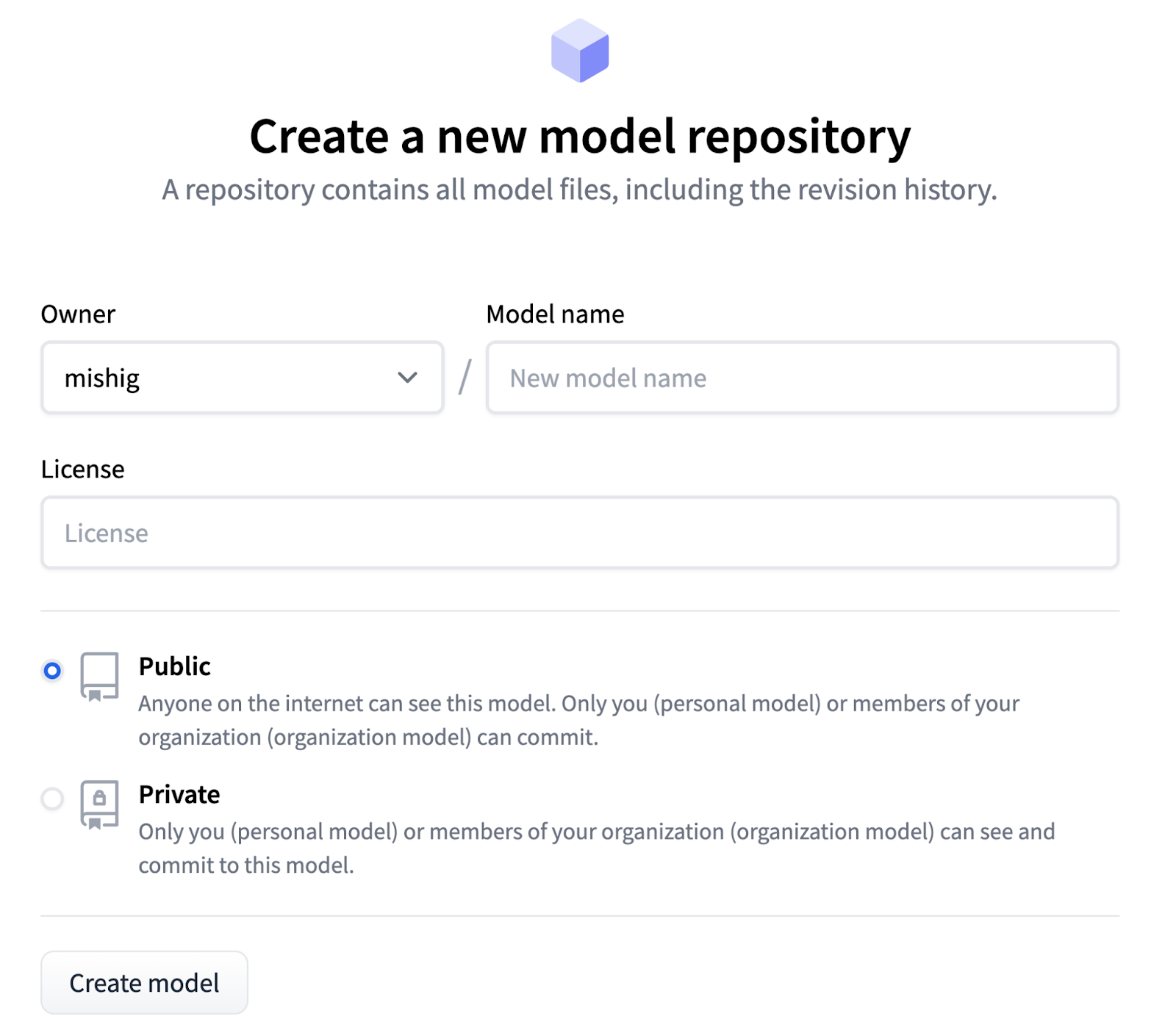
1. Create a repository at .
You can create the repository in your account or under an organization.
2. Add files to the repository.
To do this, you can go to the Files tab of the repository and click “Upload files”. You can drag and drop files/folders or upload them directly.
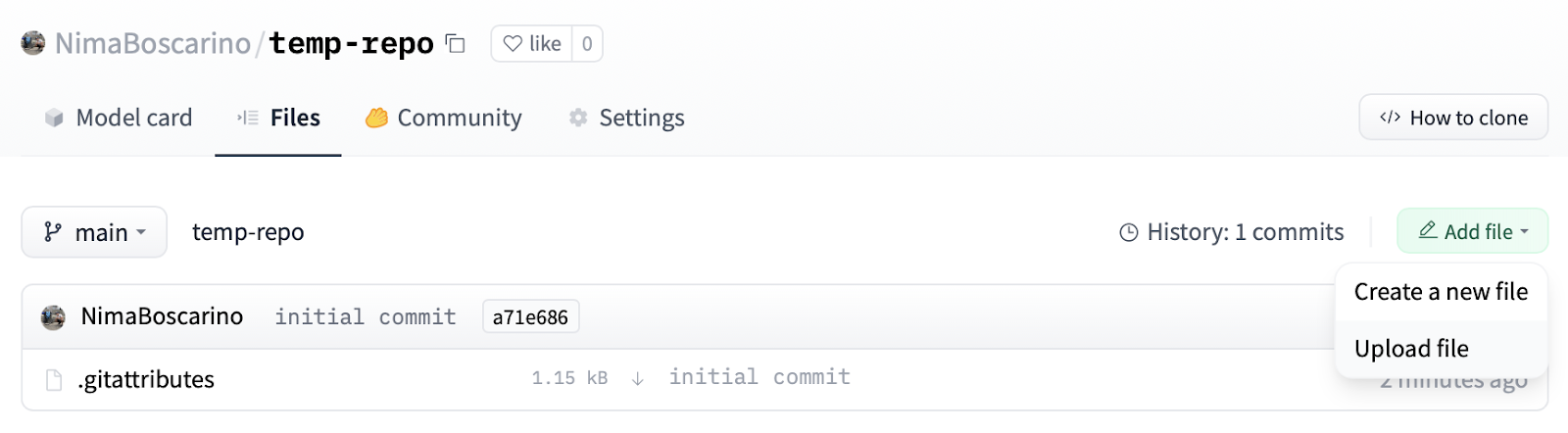
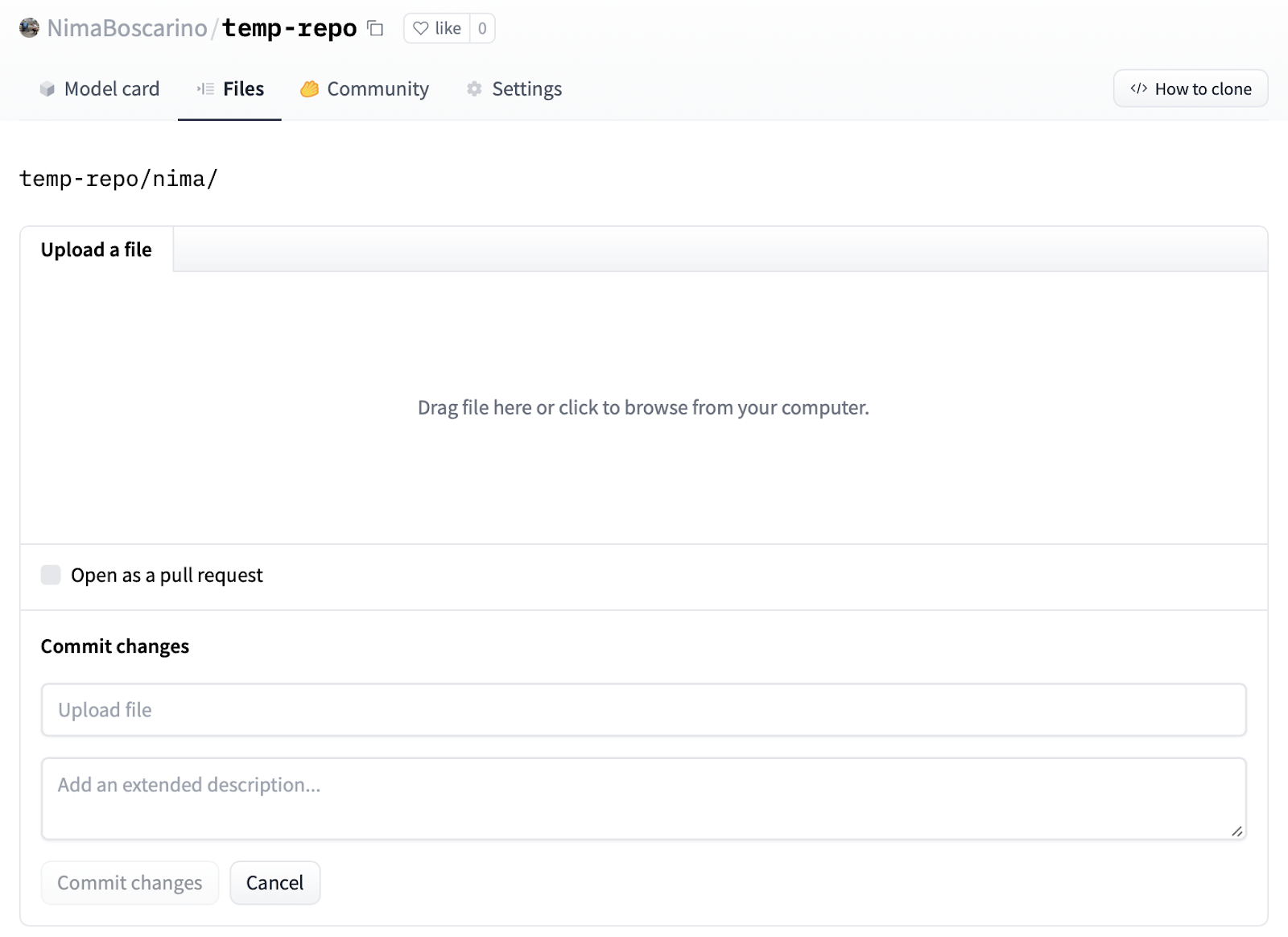
**Note:** Under the hood, HF uses git-based repositories. If you’re familiar with Git (e.g., if you use GitHub or GitLab), you can use similar workflows rather than the UI. Find more information in the [guide](https://huggingface.co/docs/hub/repositories-getting-started#terminal).
3. Create a model card.
Model cards are files that accompany the models and provide handy information. Model cards are essential for discoverability, reproducibility, and sharing! You can find a model card as the README.md file in any model repo. We strongly recommend adding a code snippet showing how to load and use the model.
Apart from the main content, model cards contain useful metadata at the top. The UI has utilities to get you started with it. We strongly encourage you to specify **license** and **pipeline\_tag** (which specify the task of the model, such as text-to-image). Both are key for discoverability and usage.
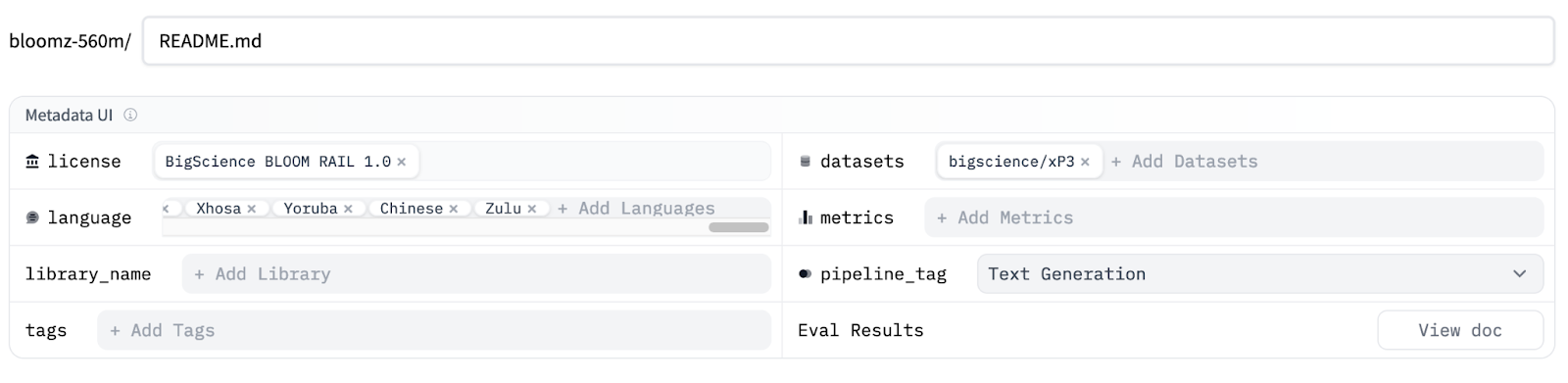
There are other fields worth adding. You can find out about them [here](https://huggingface.co/docs/hub/model-cards). Some suggestions are
- **language:** list of languages of the model
- **tags:** free tags that help with discoverability
- **datasets**: which datasets were used to train the model
- **base\_model**: if we’re talking about a fine-tuned model, which was the base model?
- **library\_name**: which libraries can be used to load the model
We suggest adding a link to your arXiv paper in the model card content. HF automatically links both together.
You can read more about model cards in its [official documentation](https://huggingface.co/docs/hub/model-cards).
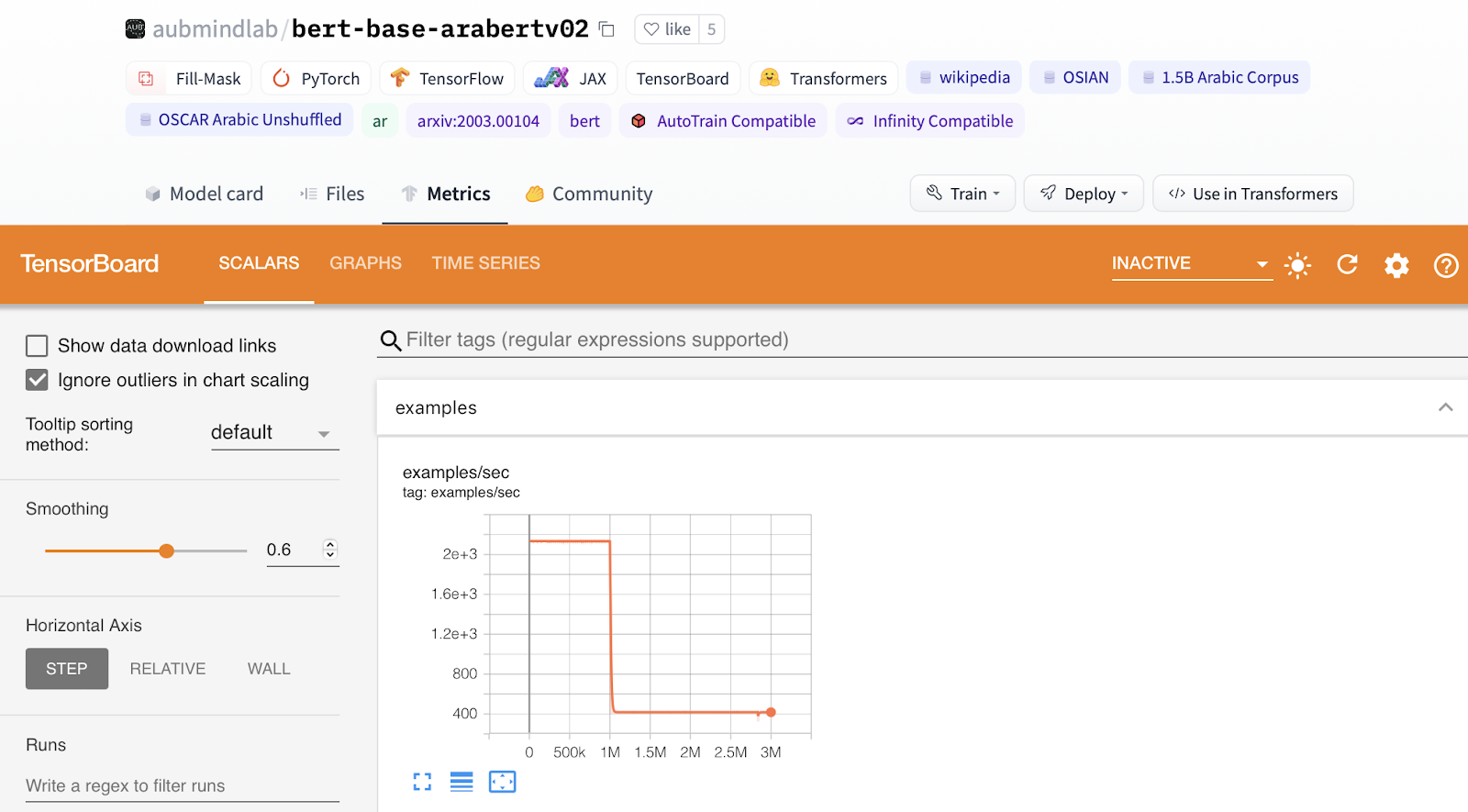
4. [Extra] Add TensorBoard traces
TensorBoard is a tool that provides tooling for visualizing metrics.If you push TensorBoard traces to the Hub, an automatic **Metrics** tab will show a TensorBoard instance. Read more about them [here](https://huggingface.co/docs/hub/tensorboard).
5. [Extra] Programmatic Access
If you want to download the model from Hugging Face in your codebase or online demos, you can use the [huggingface\_hub](https://huggingface.co/docs/huggingface_hub/guides/download) Python library for programmatic access. E.g., this will download a specific file.
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")
And this downloads all files in the repository.
from huggingface_hub import snapshot_download
snapshot_download(repo_id="lysandre/arxiv-nlp", revision="refs/pr/1")
## Build an Interactive Demo
The Hugging Face Hub provides hosting, discoverability, and social features for online demos - called Spaces. Spaces make it easy to create and deploy ML-powered demos in minutes.
**Why are demos interesting?**
Demos make research accessible to a much broader audience and increase scientific reproducibility. Building simple-to-use demos enables anyone with a browser to try out your research! Some of them even go viral!
**How do these demos look?**
It’s up to you! We’ll share how to build on in the next section, but here are some popular ones:
[Stable Diffusion by Stability](https://huggingface.co/spaces/stabilityai/stable-diffusion) (text to image)
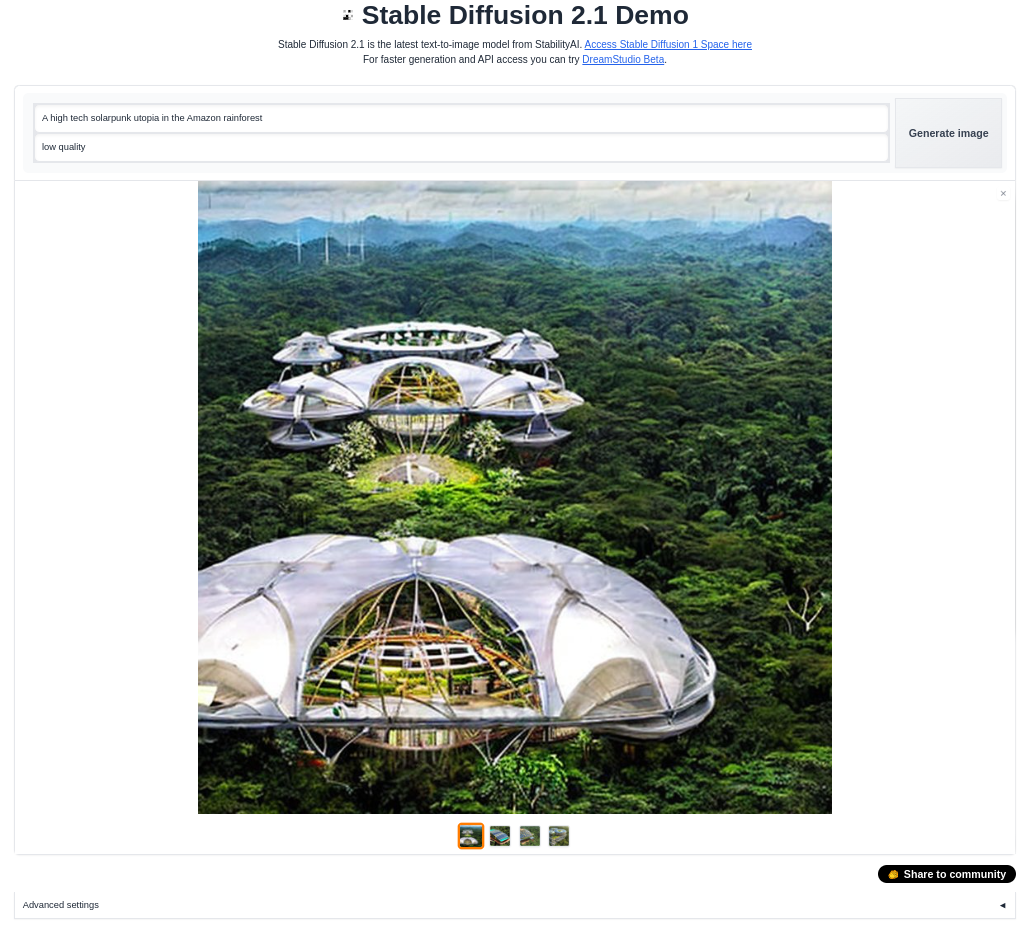
[MusicGen](https://huggingface.co/spaces/facebook/MusicGen) by Meta (text to music generation)

[AI Comic Factory](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory) by jbilcke (comic generation)

**Note**: Spaces are free when running on CPUs. If running with GPUs, you can request a community grant (in the **Settings** tab) or pay for a T4, A10G, or A100.
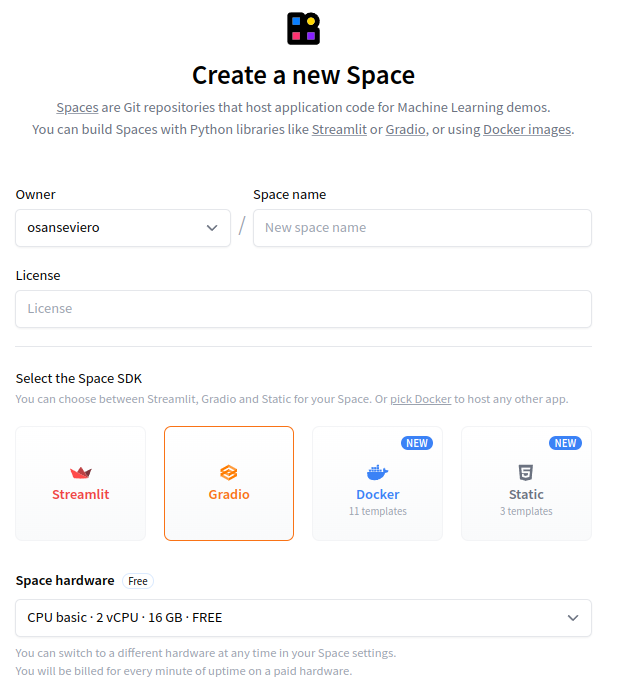
1. Create a repository at . You can create the repository in your account or under an organization.
Spaces can be built with OS Python libraries such as Gradio or Streamlit, but you can also use Docker or static HTML pages. We recommend using Gradio for quick prototyping, but you can use your favorite tool!
2. Create your application file
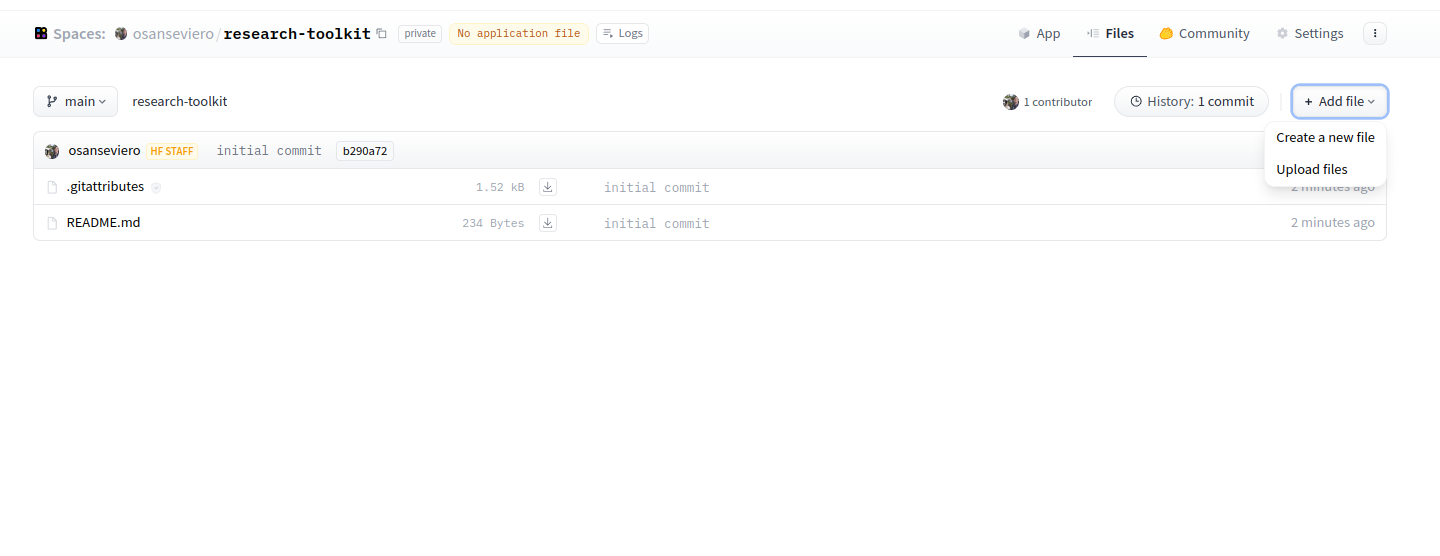
This doc assumes you’re building a Gradio demo. Feel free to check the Gradio Spaces [docs](https://huggingface.co/docs/hub/spaces-sdks-gradio). You can go to the Files tab of the repository and click “Upload files'' or “Create a new file”. The main Python script should be called **app.py**.
3. Write your application code
If you’re loading a model or dataset, you can load it with the huggingface\_hub Python library.
import gradio as gr
def greet(name):
return f”Hello {name}”}
demo = gr.Interface(
fn=greet,
inputs=[“text”],
outputs=[“text”],
)
demo.launch()
4. Try out your app!
Your app is built! Make sure to try it out.

**Note:** Under the hood, HF uses git-based repositories. If you’re familiar with Git (e.g., if you use GitHub or GitLab), you can use similar workflows rather than the UI (e.g., git add, git clone, git push). Find more information in the [guide](https://huggingface.co/docs/hub/repositories-getting-started#terminal).
**Spaces FAQ**
1. Which model libraries can I use?
You can use any library you like. You can define your [dependencies](https://huggingface.co/docs/hub/spaces-dependencies) in a requirements.txt file.
2. How do I load a model?
If you want to download the model from the Hub in your Space, you can use the [huggingface\_hub](https://huggingface.co/docs/huggingface_hub/guides/download) Python library for programmatic access. E.g., this will download a specific file.
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")
And this downloads all files in the repository.
from huggingface_hub import snapshot_download
snapshot_download(repo_id="lysandre/arxiv-nlp", revision="refs/pr/1")
3. What can I do with Gradio?
Feel free to check [Gradio docs and guides](https://www.gradio.app/guides/quickstart). Gradio provides a simple API for demo building and flexibility for you to customize your demo layout as you prefer.
It has components such as Audio, Text, Annotated Images, Chatbots, Code, Files, Gallery of Images, 3D objects, Videos, and even build your own.
4. Any tips for making a good demo?
- Simple demos are more popular.
- Have titles, descriptions, and sections briefly explaining what the demo showcases.
- Make sure to link to your model or paper.
- Add bias and content acknowledgment (see [SD demo](https://huggingface.co/spaces/stabilityai/stable-diffusion?logs=build) as an example).
## Foster usage and adoption:
You have a paper, a model/dataset, a GitHub repo, and a demo! What’s next? Your last step is ensuring your project is set up for success, so here are some additional things you can do to increase the visibility of your work.
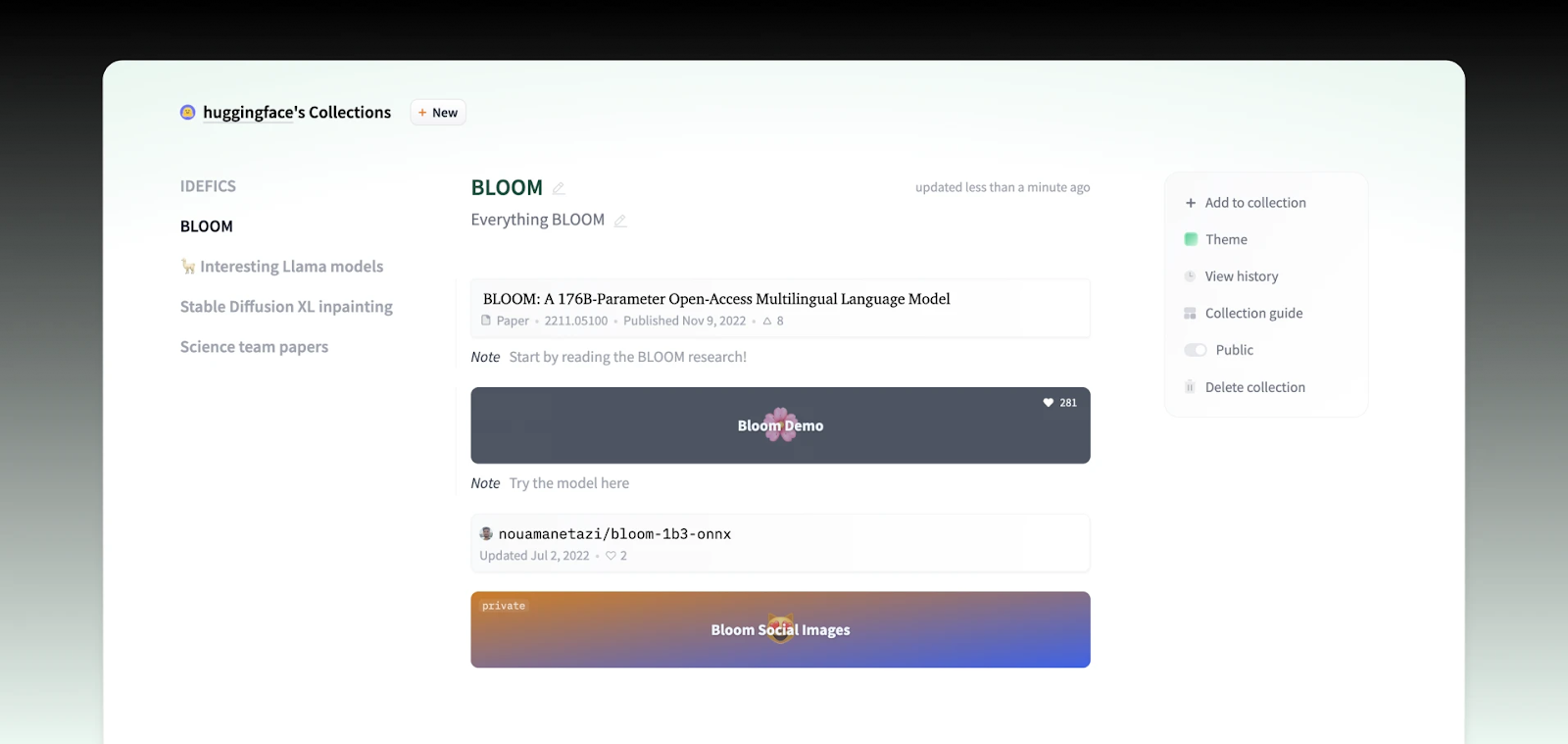
### \[Bonus] Collections
You can collect all project artifacts (model, dataset, demo, paper) as a collection on the Hub, which will be linked directly from your profile. Check out the [documentation](https://huggingface.co/docs/hub/collections).
### \[Bonus] Paper Space
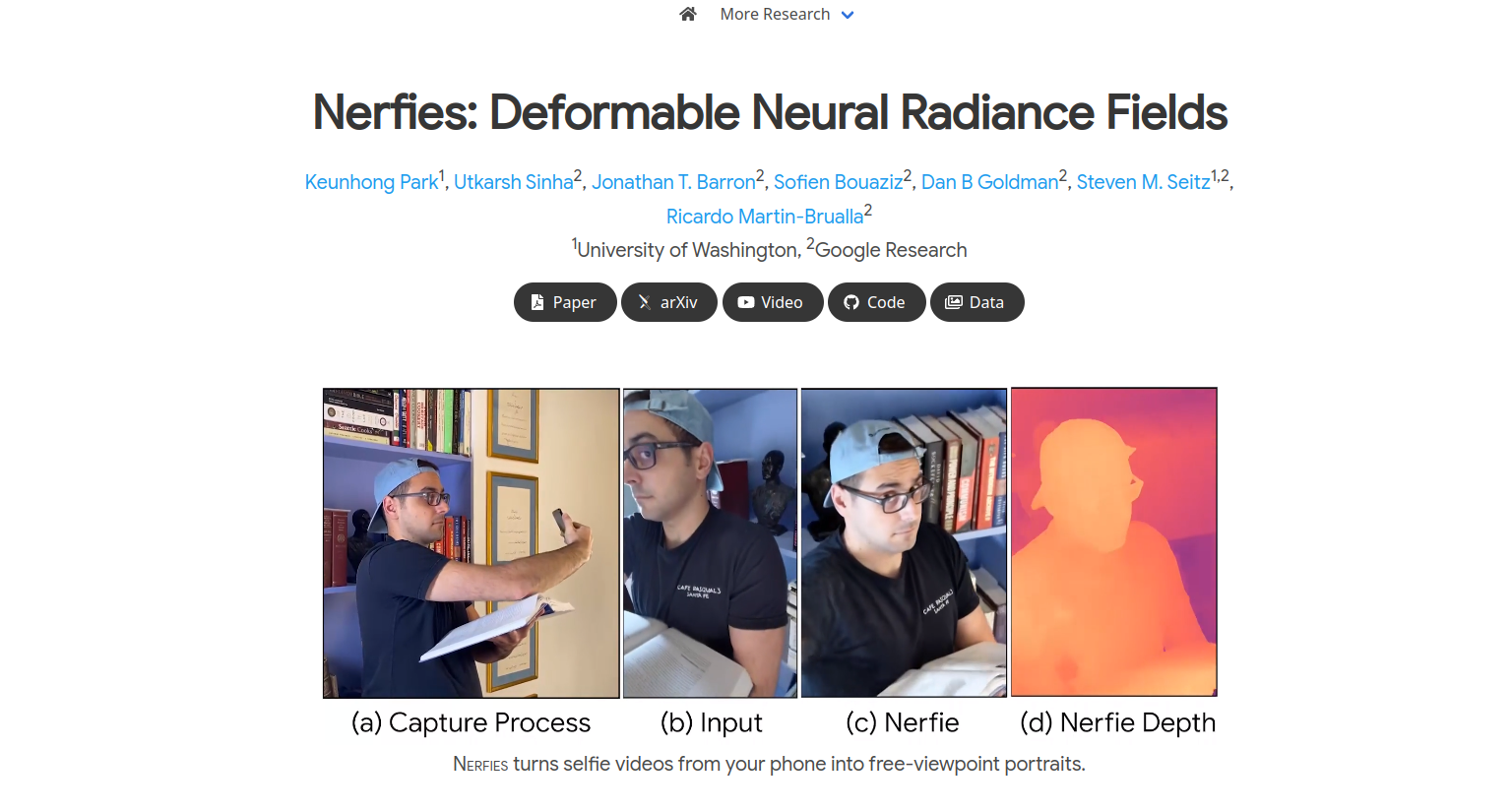
Have you seen very nice [research websites](https://nerfies.github.io/) with all the artifacts and some nice examples of their work? You can host one like this using GitHub Pages or Hugging Face Spaces. For Spaces, just select the [Nerfies/Paper Project template](https://huggingface.co/new-space?template=nerfies%2Fpaper-template) and customize the content for your liking!
### \[Bonus] Hugging Face Paper Page
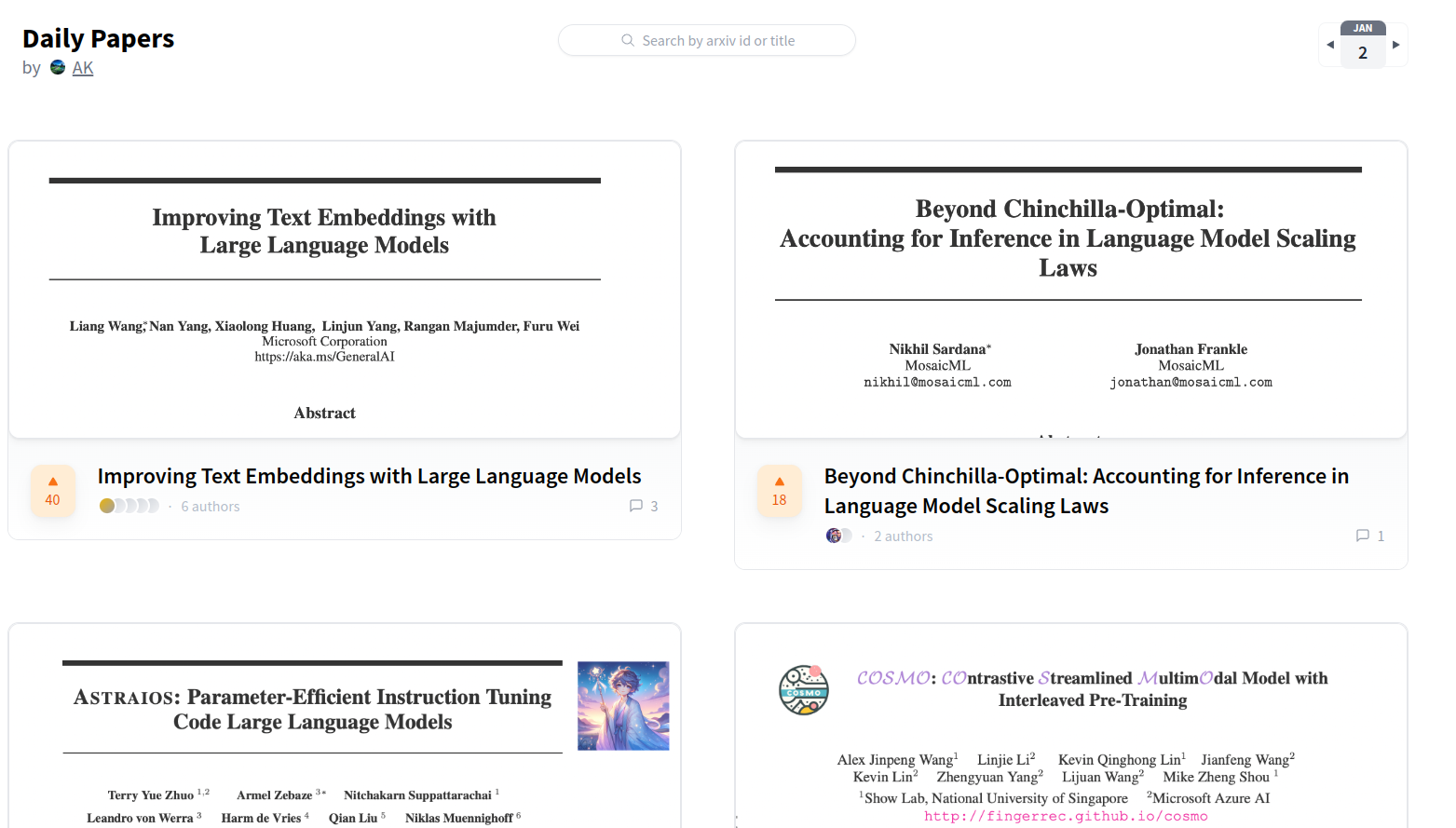
[HF paper pages](https://huggingface.co/papers) allow people to find artifacts related to a paper such as models, datasets, and apps/demos (Spaces). Paper pages also enable the community to discuss the paper! As soon as your paper is in arXiv, you can index a paper in HF and claim authorship; this will link your paper directly to your account. Check out the [documentation](https://huggingface.co/docs/hub/paper-pages#claiming-authorship-to-a-paper).
### Communicate
Congrats on the release! Although you might think you’re done, communicating about it is one of the most important pieces of a research release! Using social platforms such as X or Reddit, writing a blog post, or preparing some announcements to build some momentum for your work is important.
Try to partner with collaborators such as researchers or open-source contributors for the release; this can amplify your message and open new doors. Once you communicate, engage with the community! Effective communication is not just about broadcasting your research but also about building relationships and engaging with your audience.
## How to use this document?
We recommend duplicating this document and using the checkboxes below to track the progress. Don’t be intimidated by all the subtasks, many of these take a minute, and they guide you as **you decide what to do** and can be completed quickly! There are docs below explaining how to do the different items.
- [ ] Release the paper
- [ ] Get the paper ready and in the final format
- [ ] ArXiv release
- [ ] HF Papers indexing
- [ ] Release the code repository
- [ ] Release the dataset
- [ ] Decide on a license
- [ ] Upload dataset to a Hub (e.g., HF, Kaggle, Zenodo)
- [ ] Create a dataset card
- [ ] Add metadata (task, license, language, …)
- [ ] Add links to other artifacts (arxiv url)
- [ ] Write main content
- [ ] Release the model
- [ ] Decide on a license
- [ ] Upload the model to the Hub
- [ ] Create a model card
- [ ] Add metadata (task, license, datasets, …)
- [ ] Add links to other artifacts (arxiv url)
- [ ] Write main content
- [ ] Add a code snippet showing how to use the model
- [ ] Build a demo
- [ ] Write a Colab or a script
- [ ] Build an interactive Space
- [ ] Prepare for release
- [ ] Make sure your artifacts are interlinked
- [ ] Build a Paper Project Page
- [ ] Build a Collection of artifacts
- [ ] Communicate about it
- [ ] Celebrate