https://github.com/varshneydevansh/perceptron
https://github.com/varshneydevansh/perceptron
Last synced: 9 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/varshneydevansh/perceptron
- Owner: varshneydevansh
- Created: 2017-12-06T06:18:26.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2017-12-06T06:44:58.000Z (over 8 years ago)
- Last Synced: 2025-05-16T19:47:46.710Z (about 1 year ago)
- Language: Processing
- Size: 4.88 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# perceptron
### Build using [Processing](https://processing.org/)
Processing is an open source computer programming language and integrated development environment (IDE) built for the electronic arts, new media art, and visual design communities with the purpose of
teaching the fundamentals of computer programming in a visual context, and to serve as the foundation for electronic sketchbooks.
The project was initiated in 2001 by Casey Reas and Benjamin Fry, both formerly of the Aesthetics and Computation Group at the MIT Media Lab. In 2012, they started the Processing Foundation along with
[Daniel Shiffman](https://github.com/shiffman), who joined as a third project lead. Johanna Hedva joined the Foundation in 2014 as Director of Advocacy.One of the aims of Processing is to allow non-programmers to start computer programming aided by visual feedback.
The Processing language builds on the Java language, but uses a simplified syntax and a graphics user interface.
In *machine learning*, the perceptron is an algorithm for supervised learning of binary classifiers (functions that can decide whether an input, represented by a vector of numbers, belongs to some specific class or not).
It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector. The algorithm allows for online learning,
in that it processes elements in the training set one at a time.
## Neural networks must learn
Unlike traditional algorithms, neural networks cannot be ‘programmed’ or ‘configured’ to work in the intended way.
Just like human brains, they have to learn how to accomplish a task. Roughly speaking, there are three learning strategies:
### Supervised learning
The easiest way. Can be used if a (large enough) set of test data with known results exists.
Then the learning goes like this:
* Process one dataset.
* Compare the output against the known result.
* Adjust the network and repeat.
This is the learning strategy we’ll use here.
### Unsupervised learning
Useful if no test data is readily available, and if it is possible to derive some kind of cost function from the desired behavior.
The cost function tells the neural network how much it is off the target.
The network then can adjust its parameters on the fly while working on the real data.
### Reinforced learning
The ‘carrot and stick’ method. Can be used if the neural network generates continuous action.
Follow the carrot in front of your nose! If you go the wrong way - ouch.
Over time, the network learns to prefer the right kind of action and to avoid the wrong one.
Ok, now we know a bit about the nature of artificial neural networks,
but what exactly are they made of? What do we see if we open the cover and peek inside?
## Neurons: The building blocks of neural networks
The very basic ingredient of any artificial neural network is the artificial neuron.
They are not only named after their biological counterparts but also are modeled after the behavior of the neurons in our brain.
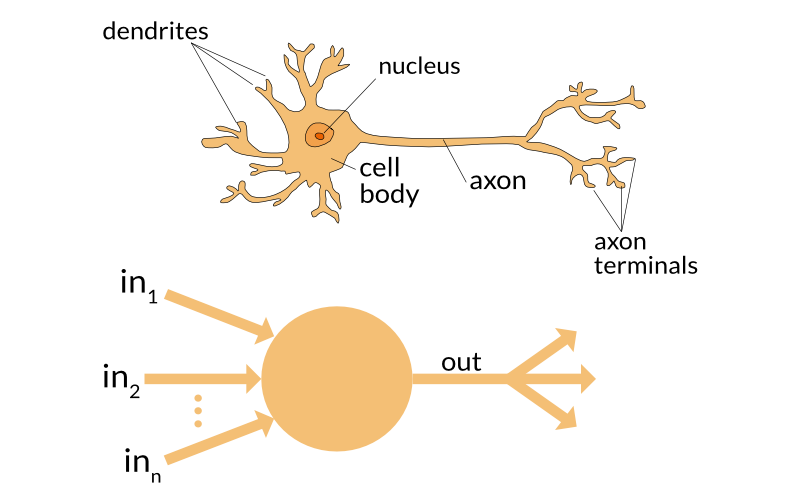
## Biology vs technology
Just like a biological neuron has dendrites to receive signals, a cell body to process them,
and an axon to send signals out to other neurons, the artificial neuron has a number of input channels,
a processing stage, and one output that can fan out to multiple other artificial neurons.
## The perceptron
The most basic form of an activation function is a simple binary function that has only two possible results.
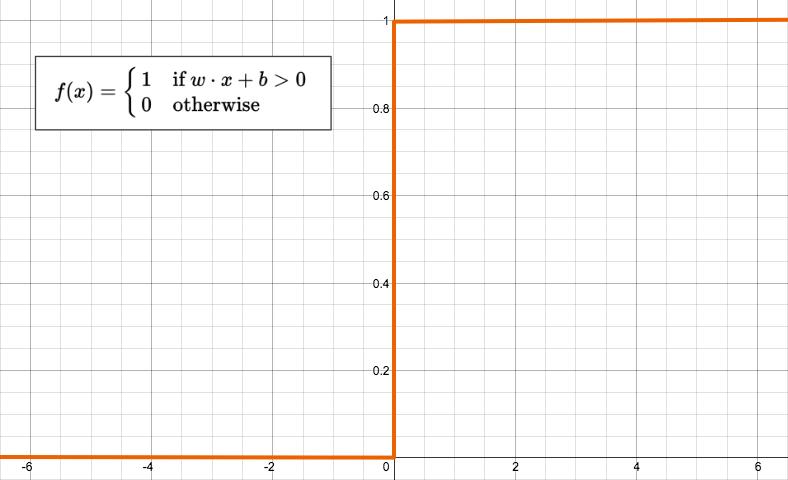
Despite looking so simple, the function has a quite elaborate name: [The Heaviside Step function](https://en.wikipedia.org/wiki/Heaviside_step_function).
This function returns 1 if the input is positive or zero, and 0 for any negative input.
A neuron whose activation function is a function like this is called a perceptron.
### Can we do something useful with a single perceptron?
If you think about it, it looks as if the perceptron consumes a lot of information for very little output - just 0 or 1.
How could this ever be useful on its own?
There is indeed a class of problems that a single perceptron can solve.
Consider the input vector as the coordinates of a point. For a vector with n elements, this point would live in an n-dimensional space.
To make life (and the code below) easier, let’s assume a two-dimensional plane. Like a sheet of paper.
Further consider that we draw a number of random points on this plane,
and we separate them into two sets by drawing a straight line across the paper:
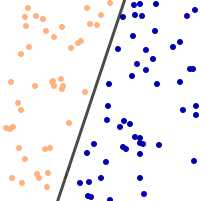
This line divides the points into two sets, one above and one below the line. (The two sets are then called [linearly separable](https://en.wikipedia.org/wiki/Linear_separability).)
A single perceptron, as bare and simple as it might appear, is able to learn where this line is, and when it finished learning, it can tell whether a given point is above or below that line.
Imagine that: A single perceptron already can learn how to classify points!