https://github.com/vas3k/infomate.club
RSS feed aggregator with collections and NLP article summarization
https://github.com/vas3k/infomate.club
feed nlp nltk python rss telegram
Last synced: 4 months ago
JSON representation
RSS feed aggregator with collections and NLP article summarization
- Host: GitHub
- URL: https://github.com/vas3k/infomate.club
- Owner: vas3k
- License: apache-2.0
- Created: 2020-01-05T11:17:13.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2025-01-10T12:37:22.000Z (6 months ago)
- Last Synced: 2025-03-24T00:02:01.760Z (4 months ago)
- Topics: feed, nlp, nltk, python, rss, telegram
- Language: Python
- Homepage: https://infomate.club
- Size: 1010 KB
- Stars: 459
- Watchers: 13
- Forks: 88
- Open Issues: 21
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Infomate.club
[](https://travis-ci.org/vas3k/infomate.club)
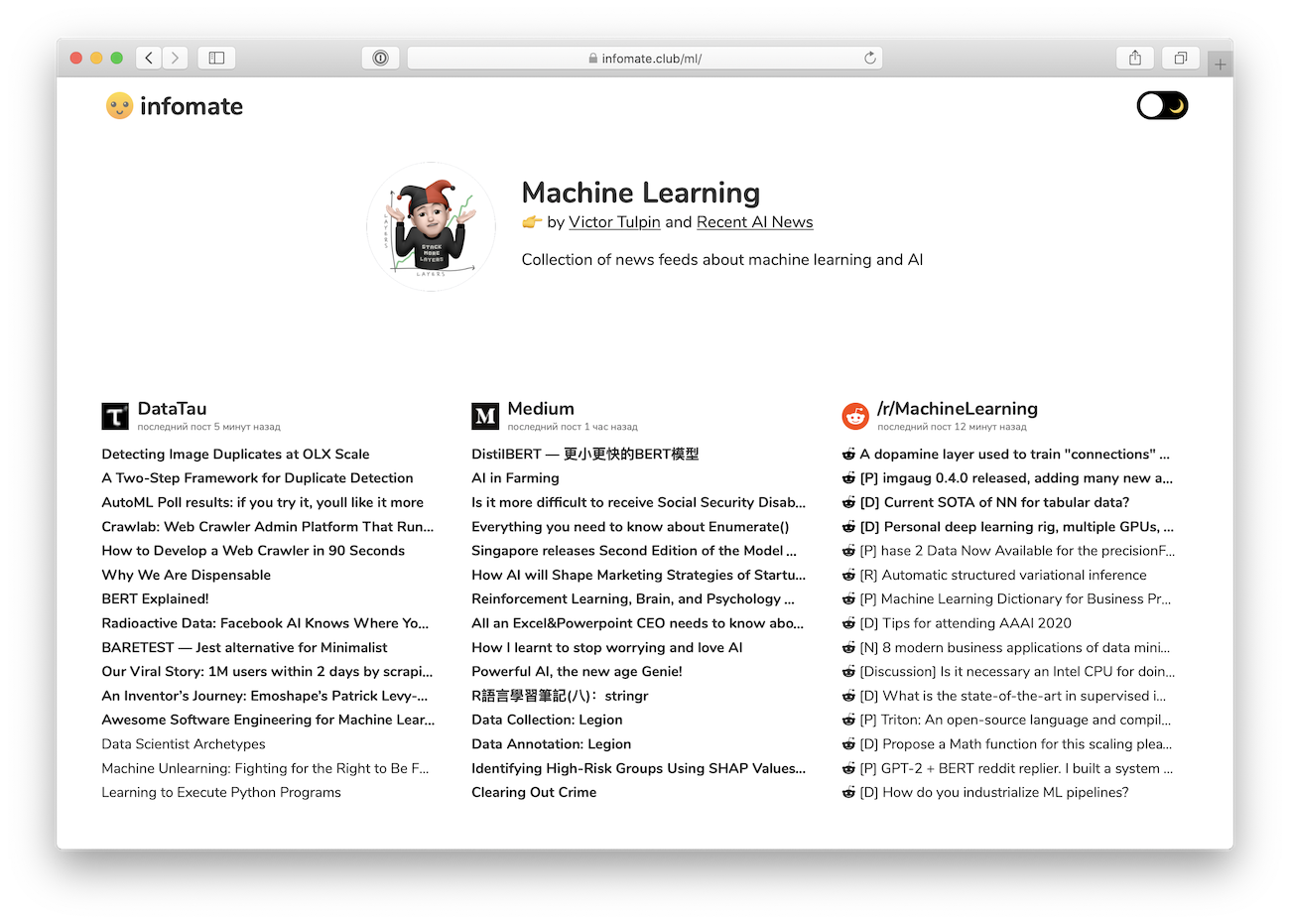
Infomate is a small web service that shows multiple RSS sources on one page and performs tricky parsing and summarizing articles using TextRank algorithm.
It helps to keep track of news from different areas without subscribing to hundreds of media accounts and getting annoying notifications.
Thematic and people-based collections does a really good job for discovery of new sources of information. Since we all are biased, such compilations can really help us to get out of information bubbles.
### Live URL: [infomate.club](https://infomate.club)
## 🐶 This is a pet-project
Which means you really shouldn't expect much from it. I wrote the MVP over the weekend to solve my own pain. No state-of-art kubernetes bullshit, no architecture patterns, even no tests at all. It's here just to show people what a pet-project might look like.
This code has been written for fun, not for business. There is usually a big difference.
## 🤔 How it works
It's basically a Django web app with a bunch of [scripts](scripts) for RSS parsing. It stores the parsed data in a PostgreSQL database.
The web app is only used to show the data (with heavy caching).
Parsing and feed updates are performed by the three scripts running in cron. Like poor people do.
[Feedparser](https://pythonhosted.org/feedparser/) and [BeautifulSoup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/) are used to find, download and parse RSS.
Text summarization is done via [newspaper3k](https://newspaper.readthedocs.io/en/latest/) with some additional protection against bad types of content like podcasts and too big pages in general, which can eat all your memory. Anything can happen in the RSS world :)
## ▶️ Running it locally
The easy way. Install [docker](https://docs.docker.com/install/) on your machine. Then:
```
git clone [email protected]:vas3k/infomate.club.git
cd infomate.club
docker-compose up --build
```
On the first run you might need to wait until the "migrate_and_init" container will finish its job populating your database.
After that you can open [localhost:8000](http://localhost:8000) in your favorite browser and enjoy.
If something stucked or you want to terminate it completely, use this command in another terminal:
```shell script
docker-compose down --remove-orphans
```
## ⚙️ boards.yml format
All collections and feeds are stored in one file — [boards.yml](boards.yml).
This is your main and only entry point to add new stuff.
```
boards:
- name: Tech # board title
slug: tech # board url
is_visible: true # visibility on the main page
is_private: false # private boards require logging in
curator: # board author profile
name: John Wick
title: Main news
avatar: https://i.vas3k.ru/fhr.png
bio: Major technology media in English and Russian
footer: >
this is a general selection of popular technology media.
The page is updated once per hour.
blocks: # list of logical feed blocks
- name: English # block title
slug: en # unique board id
feeds:
- name: Hacker News
url: https://news.ycombinator.com
rss: https://news.ycombinator.com/rss
- name: dev.to
url: https://dev.to
rss: https://dev.to/feed
- name: TechCrunch
rss: http://feeds.feedburner.com/TechCrunch/
url: https://techcrunch.com
is_parsable: false # do not try to parse pages, show RSS content only
conditions:
- type: not_in
field: title
word: Trump # exclude articles with a word "Trump" in title
```
## 💎 Running in production
Deployment is done using a simple Github Action which builds a docker container, puts it into Github Registry, logs into your server via SSH and pulls it.
The pipeline is triggered on every push to master branch. If you want to set up your own fork, please add these constants to your repo SECRETS:
```
APP_HOST — e.g. "https://your.host.com"
GHCR_TOKEN — your personal guthib access token with permissions to read/write into Github Registry
SECRET_KEY — random string for django stuff (not really used)
SENTRY_DSN — if you want to use Sentry
PRODUCTION_SSH_HOST — hostname or IP of your server
PRODUCTION_SSH_USERNAME — user which can deploy to your server
PRODUCTION_SSH_KEY — private key for this user
```
After you install them all and commit something to the master, the action should run and deploy it to your server on port **8816**.
Don't forget to set up nginx as a proxy for that app (add SSL and everything else in there). Here's example config for that: [etc/nginx/infomate.club.conf](etc/nginx/infomate.club.conf)
If something doesn't work, check the action itself: [.github/workflows/deploy.yml](.github/workflows/deploy.yml)
## 🎉 Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
You can help us with opened issues too. There's always something to work on.
We don't have any strict rules on formatting, just explain your motivation and the changes you've made to the PR description so that others understand what's going on.
## 👩💼 License
[Apache 2.0](LICENSE) © Vasily Zubarev
> TL;DR: you can modify, distribute and use it commercially,
but you MUST reference the original author or give a link to service