https://github.com/vgherard/hepscrape
arXiv:hep-ph scraper
https://github.com/vgherard/hepscrape
natural-language-processing particle-physics physics text-mining
Last synced: about 1 year ago
JSON representation
arXiv:hep-ph scraper
- Host: GitHub
- URL: https://github.com/vgherard/hepscrape
- Owner: vgherard
- License: gpl-3.0
- Created: 2021-07-18T15:09:14.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2022-02-19T19:57:51.000Z (over 4 years ago)
- Last Synced: 2025-02-06T11:53:23.758Z (over 1 year ago)
- Topics: natural-language-processing, particle-physics, physics, text-mining
- Language: R
- Homepage:
- Size: 3.71 GB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 3
-
Metadata Files:
- Readme: README.Rmd
- License: LICENSE.md
Awesome Lists containing this project
README
---
output: github_document
---
```{r, include = FALSE}
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
```
# hepscrape

This repository automatically scrapes [arXiv](https://arxiv.org/) on a daily basis, for new articles in the hep-ph category (also crossposted).
The resulting dataset is stored in R serialized data format (.rds) in `data/hep_arxiv.rds`, and is a dataframe with the following fields:
```
- id: arXiv unique identifier
- submitted: date of submission
- authors
- title
- abstract
```
This dataset is kept up-to-date with the full [arXiv Metadata OAI Snapshot](https://www.kaggle.com/Cornell-University/arxiv), and it contains all arXiv:hep-ph records over the last 30 years.
More info coming soon.
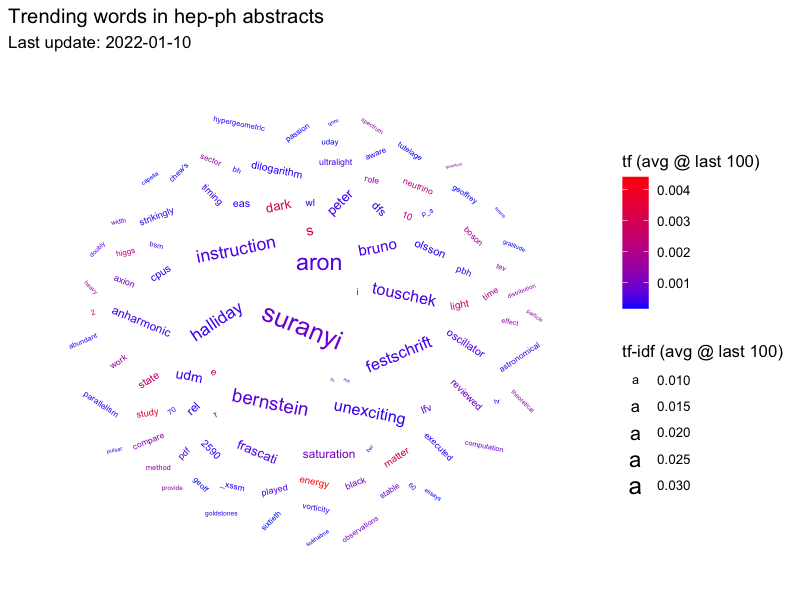
Figure: Word cloud from hep-ph abstracts. Words' character sizes are proportional to their Term-Frequency - Inverse-Document-Frequency, whereas color gradients are proportional to Term-Frequency. The `idf` weight is given by `w = ln (1 / df) ^ 1.5`. Term-frequencies are averaged over the last 100 arXiv submissions, while Inverse Document Frequencies are computed from the whole arXiv Metadata OAI Snapshot corpus.