https://github.com/vivek3141/pacman-ai
A.I. plays the original 1980 Pacman using Neuroevolution of Augmenting Topologies and Deep Q Learning
https://github.com/vivek3141/pacman-ai
artificial-intelligence deep-q-learning dopamine dqn neat neat-python neural-network neuroevolution pacman python q-learning reinforcement-learning tensorflow tensorflow-rl
Last synced: over 1 year ago
JSON representation
A.I. plays the original 1980 Pacman using Neuroevolution of Augmenting Topologies and Deep Q Learning
- Host: GitHub
- URL: https://github.com/vivek3141/pacman-ai
- Owner: vivek3141
- License: gpl-3.0
- Created: 2019-02-20T19:29:21.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2019-04-01T18:06:11.000Z (over 7 years ago)
- Last Synced: 2023-03-02T04:25:50.185Z (over 3 years ago)
- Topics: artificial-intelligence, deep-q-learning, dopamine, dqn, neat, neat-python, neural-network, neuroevolution, pacman, python, q-learning, reinforcement-learning, tensorflow, tensorflow-rl
- Language: Python
- Homepage:
- Size: 1.57 MB
- Stars: 26
- Watchers: 3
- Forks: 4
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Pacman AI
This project builds a program that can play the original 1980 Atari Pacman.
The approaches used are Deep-Q-Learning and Neuroevolution of Augmenting Topologies
## Running The Program
Use the Makefile to run various parts of this project.
* NEAT
* Train - `make neat-train`
* Test - `make neat-test`
* DQN
* Train - `make rl-train`
* Test - `make rl-test`
* Q Learning Demo - `make q-learning`
#### Alternative
`main.py` usage
```bash
python3 main.py [algorithm] [train/test]
```
## Requirements
Install the requirements with
```bash
pip install -r requirements.txt
```
#### Alternative
```bash
sudo make install
```
## NEAT - Neuroevolution of Augmenting Topologies
All files using NEAT are stored under `NEAT/`
Train the NEAT model:
```bash
make neat-train
```
Test the NEAT model:
```bash
make neat-test
```
### Explanation
For an explanation on a project using the same algorithm watch [this video](https://www.youtube.com/watch?v=UdJ4titVY7I).
#### Short Explanation
This program uses a mathematical model, called a neural network, which simulates the brain of a human being.
A neural network works by taking inputs and outputting probabilities for each of the outputs. This can be accomplished
by using a sigmoid function.

`Neuroevolution of Augmenting Topologies`, or `NEAT` is what this project uses. The way standard
`neuroevolution` works is by randomly initializing a population of neural networks and
using survival of the fittest to get the best model. The best networks in each generations
are bred and some mutations are introduced. `NEAT` introduces features like speciation to
make a much more effective neuroevolution model. Neuroevolution is known to do better than standard
reinforcement learning models.
## DQN - Deep Q-Learning
All files using DQN are stored under `DQN/`
Train the DQN model:
```bash
make rl-train
```
Test the DQN model:
```bash
make rl-test
```
### Explanation
#### Q-Learning
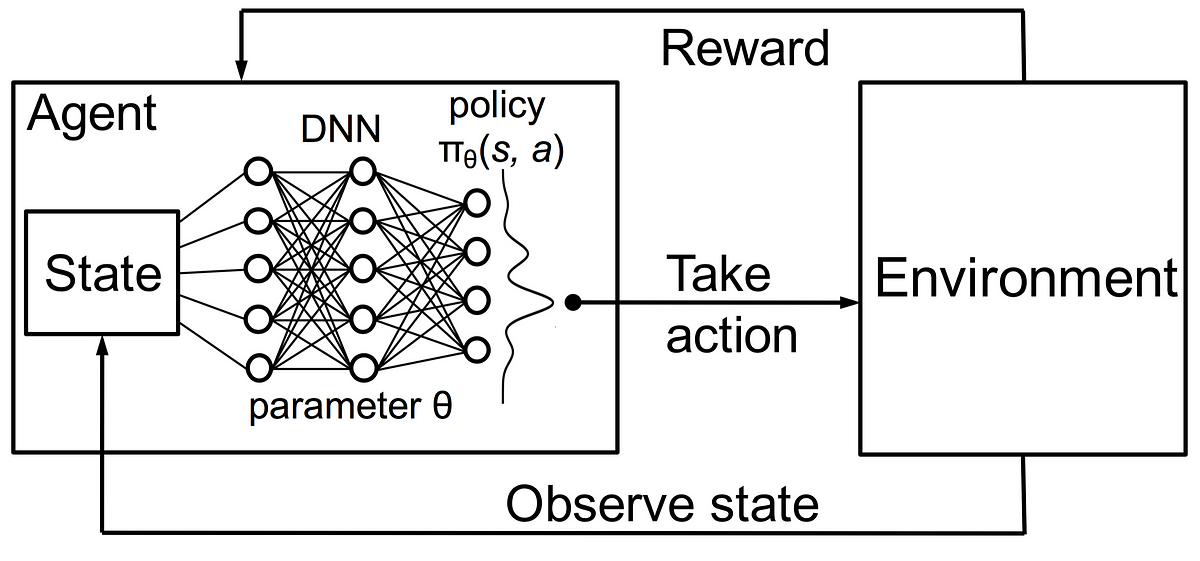
Q-learning learns the action-value function Q(s, a): how good to take an action at a particular state.
Here's what each term means:
* state - The observation you take from the environment. In this case, it would be an image
of the Pacman game or the RAM of the Atari console.

* action - The program's output for this particular state. For example, an action
would be to move left, up, right, or down in Pacman
* reward - A reward is a number that tells how good or bad an episode was. In this
case, the reward can be the score.
* Q(s, a) - Q is called the action-value function. In Q Learning, we build an table,
called the Q-Table for every state action pair. This Q Table helps determine
what action to choose.
This kind of state-action-reward system where the next state depends on the
previous state is called Markov Decision Process.

##### How Q-Learning Works

#### Deep-Q-Learning
Deep Q-learning is a special type of Q-Learning
where the Q-function is learnt by a deep neural network.
The input to the neural network is the state of the environment
and the outputs are the Q-Values.
The action with the maximum predicted Q-value is chosen as our action
to be taken in the environment.