https://github.com/vlomonaco/ar1-pytorch
AR1* with Latent Replay, implemented in PyTorch
https://github.com/vlomonaco/ar1-pytorch
computer-vision continual-learning continualai core50 deep-learning incremental-learning lifelong-learning pytorch
Last synced: about 1 year ago
JSON representation
AR1* with Latent Replay, implemented in PyTorch
- Host: GitHub
- URL: https://github.com/vlomonaco/ar1-pytorch
- Owner: vlomonaco
- License: other
- Created: 2020-02-11T13:07:46.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2020-05-08T07:26:28.000Z (about 6 years ago)
- Last Synced: 2025-04-14T14:22:26.201Z (about 1 year ago)
- Topics: computer-vision, continual-learning, continualai, core50, deep-learning, incremental-learning, lifelong-learning, pytorch
- Language: Python
- Homepage: https://arxiv.org/abs/1912.01100
- Size: 15.7 MB
- Stars: 30
- Watchers: 4
- Forks: 9
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# AR1* with Latent Replay
[](http://creativecommons.org/licenses/by/4.0/)
[](https://www.python.org/)
[](https://pytorch.org/)
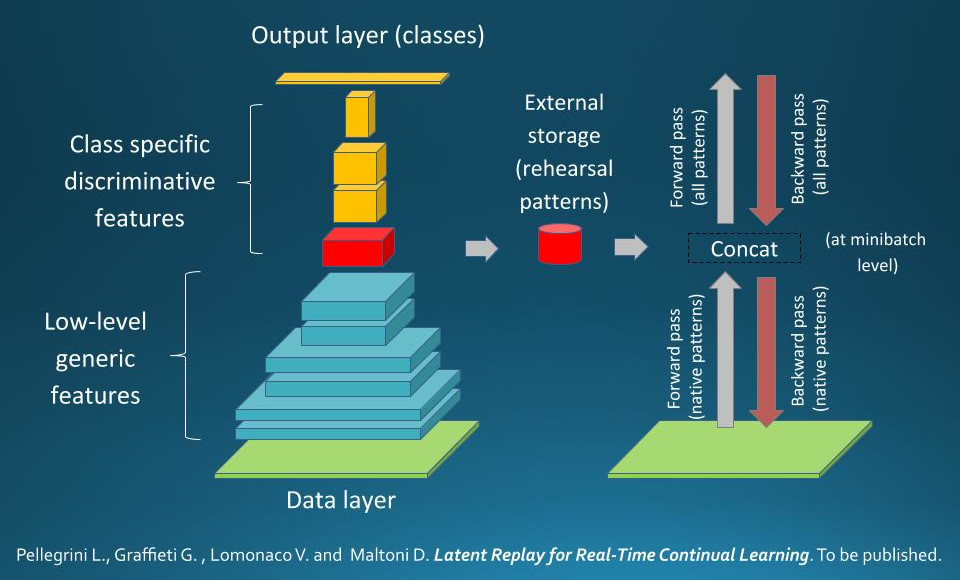
### Introduction
In this repository you will find a pytorch re-implementation of **AR1\* with
Latent Replay**. AR1* was shown to be very effective and efficient for
continual learning with real-world images.
Please consider citing the following paper if you want to use our algorithm in
your research project or application:
@article{pellegrini2019,
title = {Latent Replay for Real-Time Continual Learning},
author = {Lorenzo Pellegrini and Gabriele Graffieti and Vincenzo Lomonaco
and Davide Maltoni,
journal = {Arxiv preprint arXiv:1912.01100},
url = "https://arxiv.org/abs/1912.01100",
year = {2019}
}
The **original Caffe implementation** can be found [here](https://github.com/lrzpellegrini/Latent-Replay).
For more details about other variations or past versions of AR1 you can refer
to these papers:
@InProceedings{lomonaco2019nicv2,
title = {Rehearsal-Free Continual Learning over Small Non-I.I.D. Batches},
author = {Vincenzo Lomonaco and Davide Maltoni and Lorenzo Pellegrini},
journal = {1st Workshop on Continual Learning in Computer Vision
at CVPR2020},
url = "https://arxiv.org/abs/1907.03799",
year = {2019}
}
@article{MALTONI201956,
title = "Continuous learning in single-incremental-task scenarios",
journal = "Neural Networks",
volume = "116",
pages = "56 - 73",
year = "2019",
issn = "0893-6080",
doi = "https://doi.org/10.1016/j.neunet.2019.03.010",
url = "http://www.sciencedirect.com/science/article/pii/S0893608019300838",
author = "Davide Maltoni and Vincenzo Lomonaco"
}
### Project Structure
The project is structured as follows:
- [`models/`](models): In this folder the main MobileNetV1 model is defined
along with the custom Batch Renormalization Pytorch layer.
- [`ar1star_lat_replay.py`](ar1star_lat_replay.py): Main AR1* with Latent Replay
algorithm.
- [`data_loader.py`](data_loader.py): CORe50 data loader.
- [`LICENSE`](LICENSE): CC BY 4.0 Licence file.
- [`params.cfg`](params.cfg): Hyperparameters that will be used in the main
experiment on CORe50 NICv2-391.
- [`README.md`](README.md): This instructions file.
- [`utils.py`](utils.py): Utility functions used in the rest of the code.
### Getting Started
When using anaconda virtual environment all you need to do is run the following
command and conda will install everything for you.
See [environment.yml](./environment.yml):
conda env create --file environment.yml
conda activate ar1-env
Then to reproduce the results on the CORe50 NICv2-391 benchmark you just
need to run the following code:
```bash
python ar1star_lat_replay.py
```
The results will be logged on tensorboard, you can run it with:
```bash
tensorboard --logdir logs
```
Then open your browser at `http://localhost:6006`. If everything is setup you
should reach ~77% of accuracy at the end of the entire training procedure
(~24m on a single TitanX GPU).
This results is a few percentage point better than the one
suggested in the original paper. Keep in mind that this implementation
is *slightly different* from the original one in Caffe for a number of
reasons:
- the ImageNet pre-trained model is different.
- the pytorch SGD optimizer is different.
- the Batch Renormalization Layers are different.
- we did not find any advantage in keeping the BRN layers below the latent
reply layer free to learn, so we freeze them from the first batch.
### Use AR1* in Your Project
You are free to take this code and use it in your own project! However, take
in mind that the hyper-parameters used in the experiment have been chosen to
replicate the results shown in the paper for the CORe50 NICv2-391 scenario
and may result suboptimal in different settings.
We suggest to take a look at the papers linked above to have a better idea
on how to parametrize AR1* on different benchmarks. In particular we
underline the importance of BN / BRN parameters, which may be fundamental
to tune appropriately.
We are working to release AR1* hyper-parameter settings for other
common Continual Learning benchmarks. Send an email to vincenzo.lomonaco@unibo.it
in case you're interested!