https://github.com/voicepaw/so-vits-svc-fork
so-vits-svc fork with realtime support, improved interface and more features.
https://github.com/voicepaw/so-vits-svc-fork
contentvec deep-learning gan hacktoberfest hubert lightning pytorch pytorch-lightning realtime so-vits-svc softvc sovits speech-synthesis vits voice-changer voice-conversion
Last synced: about 1 year ago
JSON representation
so-vits-svc fork with realtime support, improved interface and more features.
- Host: GitHub
- URL: https://github.com/voicepaw/so-vits-svc-fork
- Owner: voicepaw
- License: other
- Created: 2023-03-15T14:15:50.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2025-05-05T17:02:39.000Z (about 1 year ago)
- Last Synced: 2025-05-11T14:01:45.931Z (about 1 year ago)
- Topics: contentvec, deep-learning, gan, hacktoberfest, hubert, lightning, pytorch, pytorch-lightning, realtime, so-vits-svc, softvc, sovits, speech-synthesis, vits, voice-changer, voice-conversion
- Language: Python
- Homepage:
- Size: 20.2 MB
- Stars: 8,992
- Watchers: 66
- Forks: 1,199
- Open Issues: 161
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- Funding: .github/FUNDING.yml
- License: LICENSE
- Code of conduct: .github/CODE_OF_CONDUCT.md
Awesome Lists containing this project
- StarryDivineSky - voicepaw/so-vits-svc-fork - vits-svc fork 歌唱语音转换 具有实时支持、改进的界面和更多功能。实时语音转换、更准确的音调估计、2x 更快的训练 (语音合成 / 网络服务_其他)
- AiTreasureBox - voicepaw/so-vits-svc-fork - 11-03_9168_-1](https://img.shields.io/github/stars/voicepaw/so-vits-svc-fork.svg) <a alt="Click Me" href="https://colab.research.google.com/github/34j/so-vits-svc-fork/blob/main/notebooks/so-vits-svc-fork-4.0.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open in Colab"/></a> |so-vits-svc fork with realtime support, improved interface and more features.| (Repos)
- awesome - voicepaw/so-vits-svc-fork - so-vits-svc fork with realtime support, improved interface and more features. (Python)
README
# SoftVC VITS Singing Voice Conversion Fork
[简体中文](README_zh_CN.md)









A fork of [`so-vits-svc`](https://github.com/svc-develop-team/so-vits-svc) with **realtime support** and **greatly improved interface**. Based on branch `4.0` (v1) (or `4.1`) and the models are compatible. `4.1` models are not supported. Other models are also not supported.
## No Longer Maintained
### Reasons
- Within a year, the technology has evolved enormously and there are many better alternatives
- Was hoping to create a more Modular, easy-to-install repository, but didn't have the skills, time, money to do so
- PySimpleGUI is no longer LGPL
- Using Typer is getting more popular than directly using Click
### Alternatives
Always beware of the very few influencers who are **quite overly surprised** about any new project/technology. You need to take every social networking post with semi-doubt.
The voice changer boom that occurred in 2023 has come to an end, and many developers, not just those in this repository, have been not very active for a while.
There are too many alternatives to list here but:
- RVC family: [IAHispano/Applio](https://github.com/IAHispano/Applio) (MIT), [fumiama's RVC](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI) (AGPL) and [original RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) (MIT)
- [VCClient](https://github.com/w-okada/voice-changer) (MIT etc.) is quite actively maintained and offers web-based GUI for real-time conversion.
- [fish-diffusion](https://github.com/fishaudio/fish-diffusion/commits/main/) tried to be quite modular but not quite actively maintained.
- [yxlllc/DDSP\-SVC](https://github.com/yxlllc/DDSP-SVC) - new releases are issued occasionally. [yxlllc/ReFlow\-VAE\-SVC](https://github.com/yxlllc/ReFlow-VAE-SVC)
- [coqui\-ai/TTS](https://github.com/coqui-ai/TTS) was for TTS but was partially modular. However, it is not maintained anymore, unfortunately.
Elsewhere, several start-ups have improved and marketed voice changers (probably for profit).
> Updates to this repository have been limited to maintenance since Spring 2023.
> ~~It is difficult to narrow the list of alternatives here, but please consider trying other projects if you are looking for a voice changer with even better performance (especially in terms of latency other than quality).~~ > ~~However, this project may be ideal for those who want to try out voice conversion for the moment (because it is easy to install).~~
## Features not available in the original repo
- **Realtime voice conversion** (enhanced in v1.1.0)
- Partially integrates [`QuickVC`](https://github.com/quickvc/QuickVC-VoiceConversion)
- Fixed misuse of [`ContentVec`](https://github.com/auspicious3000/contentvec) in the original repository.[^c]
- More accurate pitch estimation using [`CREPE`](https://github.com/marl/crepe/).
- GUI and unified CLI available
- ~2x faster training
- Ready to use just by installing with `pip`.
- Automatically download pretrained models. No need to install `fairseq`.
- Code completely formatted with black, isort, autoflake etc.
[^c]: [#206](https://github.com/voicepaw/so-vits-svc-fork/issues/206)
## Installation
### Option 1. One click easy installation

This BAT file will automatically perform the steps described below.
### Option 2. Manual installation (using pipx, experimental)
#### 1. Installing pipx
Windows (development version required due to [pypa/pipx#940](https://github.com/pypa/pipx/issues/940)):
```shell
py -3 -m pip install --user git+https://github.com/pypa/pipx.git
py -3 -m pipx ensurepath
```
Linux/MacOS:
```shell
python -m pip install --user pipx
python -m pipx ensurepath
```
#### 2. Installing so-vits-svc-fork
```shell
pipx install so-vits-svc-fork --python=3.11
pipx inject so-vits-svc-fork torch torchaudio --pip-args="--upgrade" --index-url=https://download.pytorch.org/whl/cu121 # https://download.pytorch.org/whl/nightly/cu121
```
### Option 3. Manual installation
Creating a virtual environment
Windows:
```shell
py -3.11 -m venv venv
venv\Scripts\activate
```
Linux/MacOS:
```shell
python3.11 -m venv venv
source venv/bin/activate
```
Anaconda:
```shell
conda create -n so-vits-svc-fork python=3.11 pip
conda activate so-vits-svc-fork
```
Installing without creating a virtual environment may cause a `PermissionError` if Python is installed in Program Files, etc.
Install this via pip (or your favourite package manager that uses pip):
```shell
python -m pip install -U pip setuptools wheel
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # https://download.pytorch.org/whl/nightly/cu121
pip install -U so-vits-svc-fork
```
Notes
- If no GPU is available or using MacOS, simply remove `pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu121`. MPS is probably supported.
- If you are using an AMD GPU on Linux, replace `--index-url https://download.pytorch.org/whl/cu121` with `--index-url https://download.pytorch.org/whl/nightly/rocm5.7`. AMD GPUs are not supported on Windows ([#120](https://github.com/voicepaw/so-vits-svc-fork/issues/120)).
### Update
Please update this package regularly to get the latest features and bug fixes.
```shell
pip install -U so-vits-svc-fork
# pipx upgrade so-vits-svc-fork
```
## Usage
### Inference
#### GUI
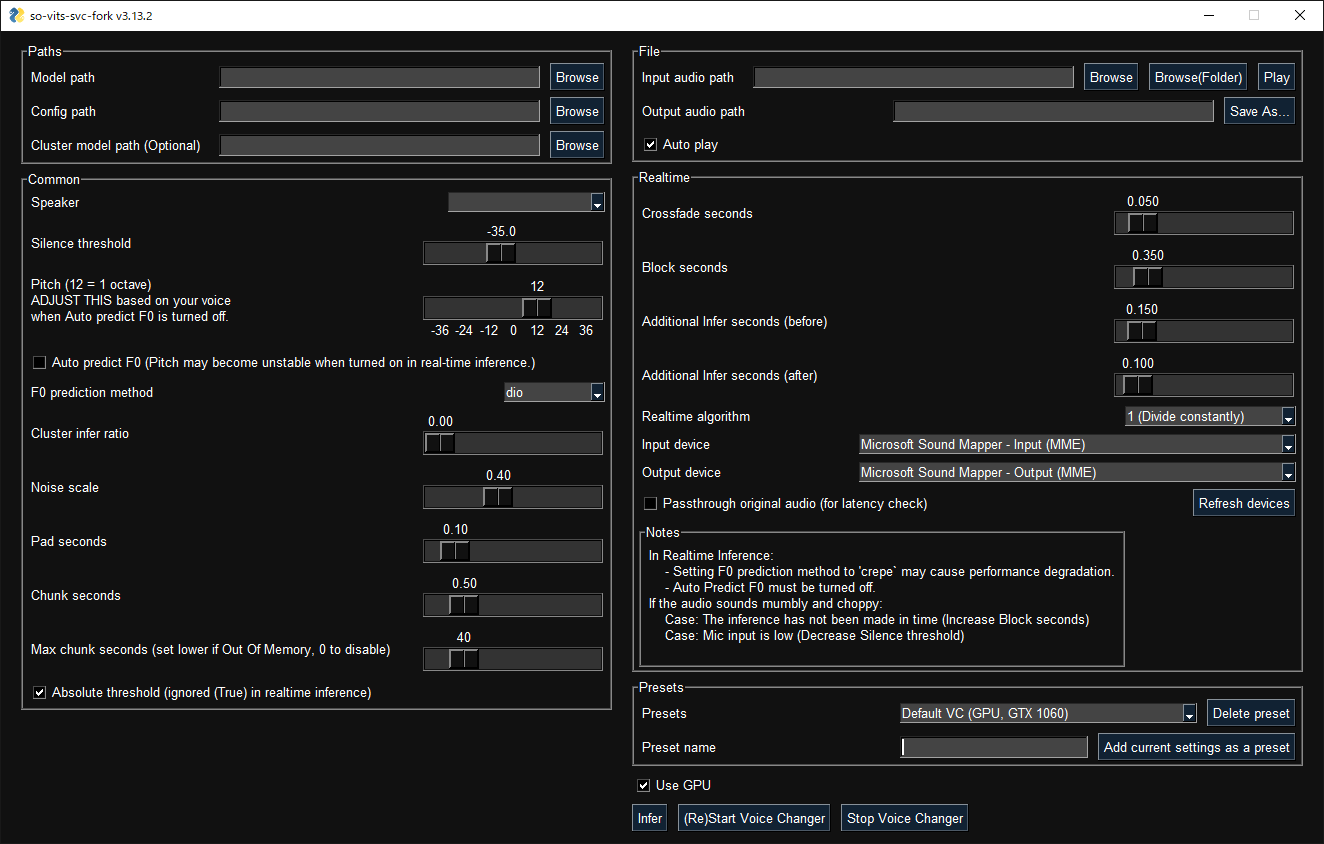
GUI launches with the following command:
```shell
svcg
```
#### CLI
- Realtime (from microphone)
```shell
svc vc
```
- File
```shell
svc infer source.wav
```
Pretrained models are available on [Hugging Face](https://huggingface.co/models?search=so-vits-svc) or [CIVITAI](https://civitai.com/tag/so-vits-svc-fork).
#### Notes
- If using WSL, please note that WSL requires additional setup to handle audio and the GUI will not work without finding an audio device.
- In real-time inference, if there is noise on the inputs, the HuBERT model will react to those as well. Consider using realtime noise reduction applications such as [RTX Voice](https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/) in this case.
- Models other than for 4.0v1 or this repository are not supported.
- GPU inference requires at least 4 GB of VRAM. If it does not work, try CPU inference as it is fast enough. [^r-inference]
[^r-inference]: [#469](https://github.com/voicepaw/so-vits-svc-fork/issues/469)
### Training
#### Before training
- If your dataset has BGM, please remove the BGM using software such as [Ultimate Vocal Remover](https://ultimatevocalremover.com/). `3_HP-Vocal-UVR.pth` or `UVR-MDX-NET Main` is recommended. [^1]
- If your dataset is a long audio file with a single speaker, use `svc pre-split` to split the dataset into multiple files (using `librosa`).
- If your dataset is a long audio file with multiple speakers, use `svc pre-sd` to split the dataset into multiple files (using `pyannote.audio`). Further manual classification may be necessary due to accuracy issues. If speakers speak with a variety of speech styles, set --min-speakers larger than the actual number of speakers. Due to unresolved dependencies, please install `pyannote.audio` manually: `pip install pyannote-audio`.
- To manually classify audio files, `svc pre-classify` is available. Up and down arrow keys can be used to change the playback speed.
[^1]: https://ytpmv.info/how-to-use-uvr/
#### Cloud
[](https://colab.research.google.com/github/voicepaw/so-vits-svc-fork/blob/main/notebooks/so-vits-svc-fork-4.0.ipynb)
[](https://console.paperspace.com/github/voicepaw/so-vits-svc-fork-paperspace/blob/main/so-vits-svc-fork-4.0-paperspace.ipynb)
[![Paperspace Referral]()](https://www.paperspace.com/?r=9VJN74I)[^p]
If you do not have access to a GPU with more than 10 GB of VRAM, the free plan of Google Colab is recommended for light users and the Pro/Growth plan of Paperspace is recommended for heavy users. Conversely, if you have access to a high-end GPU, the use of cloud services is not recommended.
[^p]: If you register a referral code and then add a payment method, you may save about $5 on your first month's monthly billing. Note that both referral rewards are Paperspace credits and not cash. It was a tough decision but inserted because debugging and training the initial model requires a large amount of computing power and the developer is a student.
#### Local
Place your dataset like `dataset_raw/{speaker_id}/**/{wav_file}.{any_format}` (subfolders and non-ASCII filenames are acceptable) and run:
```shell
svc pre-resample
svc pre-config
svc pre-hubert
svc train -t
```
#### Notes
- Dataset audio duration per file should be <~ 10s.
- Need at least 4GB of VRAM. [^r-training]
- It is recommended to increase the `batch_size` as much as possible in `config.json` before the `train` command to match the VRAM capacity. Setting `batch_size` to `auto-{init_batch_size}-{max_n_trials}` (or simply `auto`) will automatically increase `batch_size` until OOM error occurs, but may not be useful in some cases.
- To use `CREPE`, replace `svc pre-hubert` with `svc pre-hubert -fm crepe`.
- To use `ContentVec` correctly, replace `svc pre-config` with `-t so-vits-svc-4.0v1`. Training may take slightly longer because some weights are reset due to reusing legacy initial generator weights.
- To use `MS-iSTFT Decoder`, replace `svc pre-config` with `svc pre-config -t quickvc`.
- Silence removal and volume normalization are automatically performed (as in the upstream repo) and are not required.
- If you have trained on a large, copyright-free dataset, consider releasing it as an initial model.
- For further details (e.g. parameters, etc.), you can see the [Wiki](https://github.com/voicepaw/so-vits-svc-fork/wiki) or [Discussions](https://github.com/voicepaw/so-vits-svc-fork/discussions).
[^r-training]: [#456](https://github.com/voicepaw/so-vits-svc-fork/issues/456)
### Further help
For more details, run `svc -h` or `svc -h`.
```shell
> svc -h
Usage: svc [OPTIONS] COMMAND [ARGS]...
so-vits-svc allows any folder structure for training data.
However, the following folder structure is recommended.
When training: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}
When inference: configs/44k/config.json, logs/44k/G_XXXX.pth
If the folder structure is followed, you DO NOT NEED TO SPECIFY model path, config path, etc.
(The latest model will be automatically loaded.)
To train a model, run pre-resample, pre-config, pre-hubert, train.
To infer a model, run infer.
Options:
-h, --help Show this message and exit.
Commands:
clean Clean up files, only useful if you are using the default file structure
infer Inference
onnx Export model to onnx (currently not working)
pre-classify Classify multiple audio files into multiple files
pre-config Preprocessing part 2: config
pre-hubert Preprocessing part 3: hubert If the HuBERT model is not found, it will be...
pre-resample Preprocessing part 1: resample
pre-sd Speech diarization using pyannote.audio
pre-split Split audio files into multiple files
train Train model If D_0.pth or G_0.pth not found, automatically download from hub.
train-cluster Train k-means clustering
vc Realtime inference from microphone
```
#### External Links
[Video Tutorial](https://www.youtube.com/watch?v=tZn0lcGO5OQ)
## Contributors ✨
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):

34j
💻 🤔 📖 💡 🚇 🚧 👀 ⚠️ ✅ 📣 🐛

GarrettConway
💻 🐛 📖 👀

BlueAmulet
🤔 💬 💻 🚧

ThrowawayAccount01
🐛

緋
📖 🐛

Lordmau5
🐛 💻 🤔 🚧 💬 📓

DL909
🐛

Satisfy256
🐛

Pierluigi Zagaria
📓

ruckusmattster
🐛

Desuka-art
🐛

heyfixit
📖

Nerdy Rodent
📹

谢宇
📖

ColdCawfee
🐛

sbersier
🤔 📓 🐛

Meldoner
🐛 🤔 💻

mmodeusher
🐛

AlonDan
🐛

Likkkez
🐛

Duct Tape Games
🐛

Xianglong He
🐛

75aosu
🐛

tonyco82
🐛

yxlllc
🤔 💻

outhipped
🐛

escoolioinglesias
🐛 📓 📹

Blacksingh
🐛

Mgs. M. Thoyib Antarnusa
🐛

Exosfeer
🐛 💻

guranon
🐛 🤔 💻

Alexander Koumis
💻

acekagami
🌍

Highupech
🐛

Scorpi
💻

Maximxls
💻

Star3Lord
🐛 💻

Forkoz
🐛 💻

Zerui Chen
💻 🤔

Roee Shenberg
📓 🤔 💻

Justas
🐛 💻

Onako2
📖

4ll0w3v1l
💻

j5y0V6b
🛡️

marcellocirelli
🐛

Priyanshu Patel
💻

Anna Gorshunova
🐛 💻
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!