https://github.com/vupdivup/diffhouse
diffhouse is a repository mining tool for structuring Git metadata at scale
https://github.com/vupdivup/diffhouse
git open-source python repository-mining software-analysis
Last synced: 5 months ago
JSON representation
diffhouse is a repository mining tool for structuring Git metadata at scale
- Host: GitHub
- URL: https://github.com/vupdivup/diffhouse
- Owner: vupdivup
- License: mit
- Created: 2025-09-08T11:03:11.000Z (10 months ago)
- Default Branch: main
- Last Pushed: 2025-11-29T12:03:08.000Z (7 months ago)
- Last Synced: 2025-11-29T13:38:40.885Z (7 months ago)
- Topics: git, open-source, python, repository-mining, software-analysis
- Language: Python
- Homepage: https://vupdivup.github.io/diffhouse/
- Size: 1.54 MB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 12
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
- Citation: CITATION.cff
Awesome Lists containing this project
README
# diffhouse: Repository Mining at Scale
[](https://pypi.org/project/diffhouse/) [](https://doi.org/10.5281/zenodo.17368264) [](https://github.com/vupdivup/diffhouse/actions/workflows/os-test.yml)
[Documentation](https://vupdivup.github.io/diffhouse/)
diffhouse is a **Python solution for structuring Git metadata**, designed to enable
large-scale codebase analysis at practical speeds.
Key features are:
- 🚀 Fast access to commit data, file changes and more
- 📊 Easy integration with pandas and Polars
- 🐍 Simple-to-use Python interface
## Performance
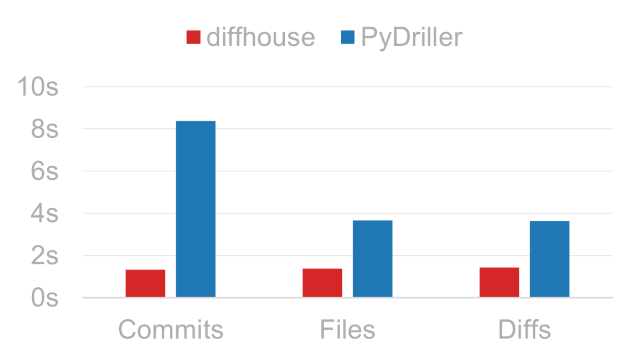
Processing times for tween.js. Lower is better.
For more details, see [benchmarks](https://vupdivup.github.io/diffhouse/benchmarks/).
## Requirements
Python
3.10 or higher
Git
2.22 or higher
Git also needs to be added to the system PATH.
## Limitations
At its core, diffhouse is a data *extraction* tool and therefore does not calculate software metrics like code churn or cyclomatic complexity; if this is needed, take a look at [PyDriller](https://github.com/ishepard/pydriller) instead.
## User Guide
This guide aims to cover the basic use cases of diffhouse. For a full list of objects, consider reading the
[API Reference](https://vupdivup.github.io/diffhouse/reference).
### Installation
Install diffhouse from PyPI:
```sh
pip install diffhouse
```
#### Optional Dependencies
If you plan to combine diffhouse with pandas or Polars, install the package with their respective extras:
pandas
pip install diffhouse[pandas]
Polars
pip install diffhouse[polars]
### Quickstart
```py
from diffhouse import Repo
with Repo('https://github.com/user/repo') as r:
for c in r.commits:
print(c.commit_hash[:10], c.date, c.author_email)
if len(r.branches.to_list()) > 100:
print('🎉')
df = r.diffs.to_pandas()
```
To start, create a [`Repo`](https://vupdivup.github.io/diffhouse/reference/repo/) instance by passing either a Git-hosting URL or a local path as its `source` argument. Next, use the `Repo` in a `with` statement to clone the source into a local, non-persistent
location.
Inside the `with` block, you can access data through the following properties:
| Property | Description | Record Type
| --- | --- | --- |
| [`Repo.commits`](https://vupdivup.github.io/diffhouse/reference/repo/#diffhouse.Repo.commits) | Commit history of the repository. | [`Commit`](https://vupdivup.github.io/diffhouse/reference/commit/) |
| [`Repo.filemods`](https://vupdivup.github.io/diffhouse/reference/repo/#diffhouse.Repo.filemods) | File modifications across the commit history. | [`FileMod`](https://vupdivup.github.io/diffhouse/reference/filemod/) |
| [`Repo.diffs`](https://vupdivup.github.io/diffhouse/reference/repo/#diffhouse.Repo.diffs) | Source code changes across the commit history. | [`Diff`](https://vupdivup.github.io/diffhouse/reference/diff/) |
| [`Repo.branches`](https://vupdivup.github.io/diffhouse/reference/repo/#diffhouse.Repo.branches) | Branches of the repository. | [`Branch`](https://vupdivup.github.io/diffhouse/reference/branch/) |
| [`Repo.tags`](https://vupdivup.github.io/diffhouse/reference/repo/#diffhouse.Repo.tags) | Tags of the repository. | [`Tag`](https://vupdivup.github.io/diffhouse/reference/tag/) |
### Querying Results
Data accessors like `Repo.commits` are [`Extractor`](https://vupdivup.github.io/diffhouse/reference/extractor/) objects and can output their results in various formats:
#### Looping Through Objects
You can use extractors in a `for` loop to process objects one by one. Data will be extracted on demand for memory efficiency:
```py
with Repo('https://github.com/user/repo') as r:
for c in r.commits:
print(c.commit_hash[:10])
print(c.author_name)
if c.in_main:
break
```
`iter_dicts()` is a `for` loop alternative that yields dictionaries instead of diffhouse objects. A good use case for this is writing results into a newline-delimited JSON file:
```py
import json
with (
Repo('https://github.com/user/repo') as r,
open('commits.jsonl', 'w') as f
):
for c in r.commits.iter_dicts():
f.write(json.dumps(c) + '\n')
```
#### Converting to Dataframes
pandas and Polars `DataFrame` APIs are supported out of the box. To convert result sets to dataframes, call the following methods:
- `to_pandas()` or `pd()` for pandas
- `to_polars()` or `pl()` for Polars
```py
with Repo('https://github.com/user/repo') as r:
df1 = r.filemods.to_pandas() # pandas
df2 = r.diffs.to_polars() # Polars
```
### Preliminary Filtering
You can filter data along certain dimensions *before* processing takes place to reduce extraction time and/or network load.
> [!NOTE]
> Filters are a WIP feature. Additional options like date and branch filtering are planned for future releases.
#### Skipping File Downloads
If no blob-level data is needed, pass `blobs=False` when creating the `Repo` to skip file downloads during cloning. Note that this will not populate:
- `files_changed`, `lines_added` and `lines_deleted` fields of `Repo.commits`
- `Repo.filemods`
- `Repo.diffs`
```py
with Repo('https://github.com/user/repo', blobs=False) as r:
for b in r.branches:
pass # business as usual
r.filemods # throws FilterError
```