https://github.com/wangwangwang23333/Business-Intelligence-Frontend
Front-end repository for BI course projects
https://github.com/wangwangwang23333/Business-Intelligence-Frontend
Last synced: 2 months ago
JSON representation
Front-end repository for BI course projects
- Host: GitHub
- URL: https://github.com/wangwangwang23333/Business-Intelligence-Frontend
- Owner: wangwangwang23333
- Created: 2022-05-08T16:02:57.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2022-06-14T07:45:07.000Z (about 3 years ago)
- Last Synced: 2024-11-10T06:34:33.975Z (8 months ago)
- Language: Vue
- Size: 13.3 MB
- Stars: 4
- Watchers: 0
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-tjsse-project - wangwangwang23333/Business-Intelligence-Frontend
README
# Business Intelligence
## 1 数据提取
### 1.1 数据分析
初始数据共有三种,分别为Aminer-Paper,AMiner-Author以及Aminer-Coauthor。
### 1.2 数据处理
#### 1.2.1 Aminer-Paper
对于Paper表,我们将其分为两个表,并对其中的机构进行了处理。
同时对于Paper表而言,其引用为一对多关系,所以将论文引用也拆出一张表。
将Paper表处理过后得到三个csv文件,分别为Aminer-Paper.csv,Aminer-Paper-Affiliation.csv,Aminer-Paper-Reference.csv。
#### 1.2.2 Aminer-Author
对于Author表而言,我们首先将其中的一对多关系拆分出来并形成表,然后再对其中的内容进行格式上的调整以及数据的处理。
将Author表处理后得到三个csv文件,分别为Aminer-Author.csv,Aminer-Author-Affiliation.csv,Aminer-Author-Interest.csv。
#### 1.2.3 Aminer-Coauthor
对于Coauthor而言,我们不需要做过多的处理,因为在本表中没有一对多的关系,所以直接处理即可。
#### 1.2.4 Affiliation
对于affiliation之间的关系,仅仅做以上的处理是不够的,还需要对Author的affiliation以及Paper的affiliation进行单独的处理,并且合起来做去重的工作。
## 2 数据存储
在将数据初步处理之后,我们将原数据集划分为10个`.csv` 文件。
经过调研,neo4j插入数据有以下几种方法:
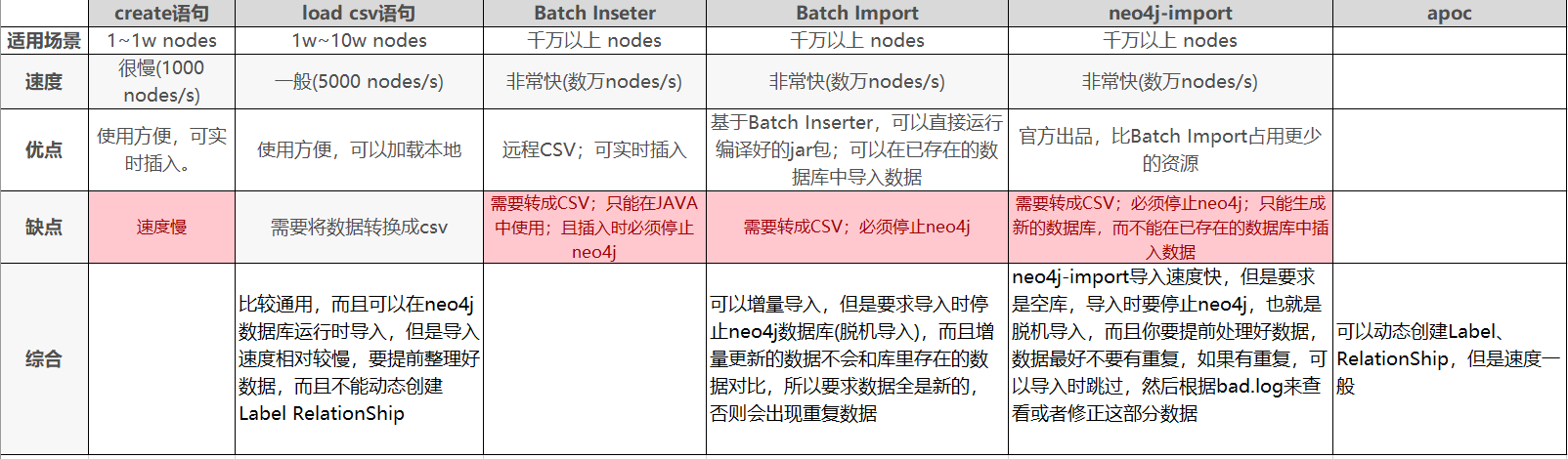
我们经过分析,认为本系统应该具有以下两个特征:
- 数据集是百万级,因此需要具有比较快的插入速度
- 数据能够支持动态更新,以便未来的修改
因此,经过综合考虑,我们最终采用`LOAD CSV` 语句进行数据的插入,步骤如下:
1. 将文件通过 ssh 连接和 wget 命令将文件(*.csv)复制到 neo4j/import 目录下;
2. 通过 neo4j 提供的 browser service 使用 LOAD CSV 命令将数据库导入到数据库中,随后在前端展示数据导入结果;
LOAD CSV 支持远程文件和本地文件的导入,这里我们选择了先存储为本地文
件再进行导入,这样相对而言比较安全。并且由于文件是存储于 neo4j 的宿主机器上,这样基本不会带来由于数据传输而带来的性能损失。
### 论文作者表
首先,需要插入实体关系。因此我们需要最先插入`Aminer-Author.csv`文件,使用下面的语句:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Author.csv" AS line CREATE(p:Author{index:line['index'],name:line['name'],pc:line['pc'],cn:line['cn'],hi:line['hi'],pi:line['pi'],upi:line['upi']})
```
插入完成后,共有1712433个结点,如下图所示:

为了提高查询速度,我们建立了索引:
```cypher
create index on:Author(name)
create index on:Author(index)
```
### 论文表
接下来,我们开始插入论文关系表`Aminer-Paper.csv` 如下所示:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Paper.csv" AS line
CREATE(p:Paper{index: line['index'], paper_title:line['paper_title'], year: line['year'], publication_venue: line['publication_venue'], abstract: line['abstract']})
```
论文数据量总计为2092355,如下所示:

因此我们仍然通过建立索引来提高检索效率:
```cypher
create index on:Paper(index)
```
### 机构表
接下来,插入机构表,语句如下:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///Aminer-Company.csv" AS line
CREATE (c:Company{name: line['affiliation']})
```
机构数据量为909613,如下所示:

同时,需要给name字段添加索引:
```cypher
create index on:Company(name)
```
### 领域表
一个作者可能对多个领域感兴趣,一个领域也可能有多个作者。因此,我们需要将领域作为实体进行插入:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///Aminer-Area.csv" AS line
CREATE (c:Area{name: line['name']})
```
领域数据量为4055689,如下所示:
同样的,我们添加索引:
```cypher
create index on:Area(name)
```
### 作者——论文表
我们使用下面的代码插入`Aminer-Author-Paper.csv`文件:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Author-Paper.csv" AS line
MATCH (p: Paper{index: toString(line['paper_index'])}), (a: Author{index: toString(line['author_index'])})
CREATE (a)-[:Write{affiliation: line['affiliation']}]->(p)
```
该关系的数据量为5239261,如下所示:
### 论文——论文关系表
两个论文之间会存在引用和被引用关系,因此我们需要插入`Aminer-Paper-Reference.csv` 文件:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///Aminer-Paper-Reference.csv" AS line
MATCH (p1: Paper{index: line['paper_index']}), (p2: Paper{index: line['referenced_index']})
CREATE (p1)-[:Reference]->(p2)
```
Reference关系数据集总量为8024861,如下所示:
### 作者——作者合作表
两个作者之间会存在论文上的合作关系,因此需要插入作者之间的合作关系:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Coauthor.csv" AS line
MATCH (p1: Author{index: line['first_author']}), (p2: Author{index: line['second_author']})
CREATE (p1)-[:Cooperate{co_num: line['co_num']}]->(p2)
```
该关系的数据总量为5239261,如下所示:
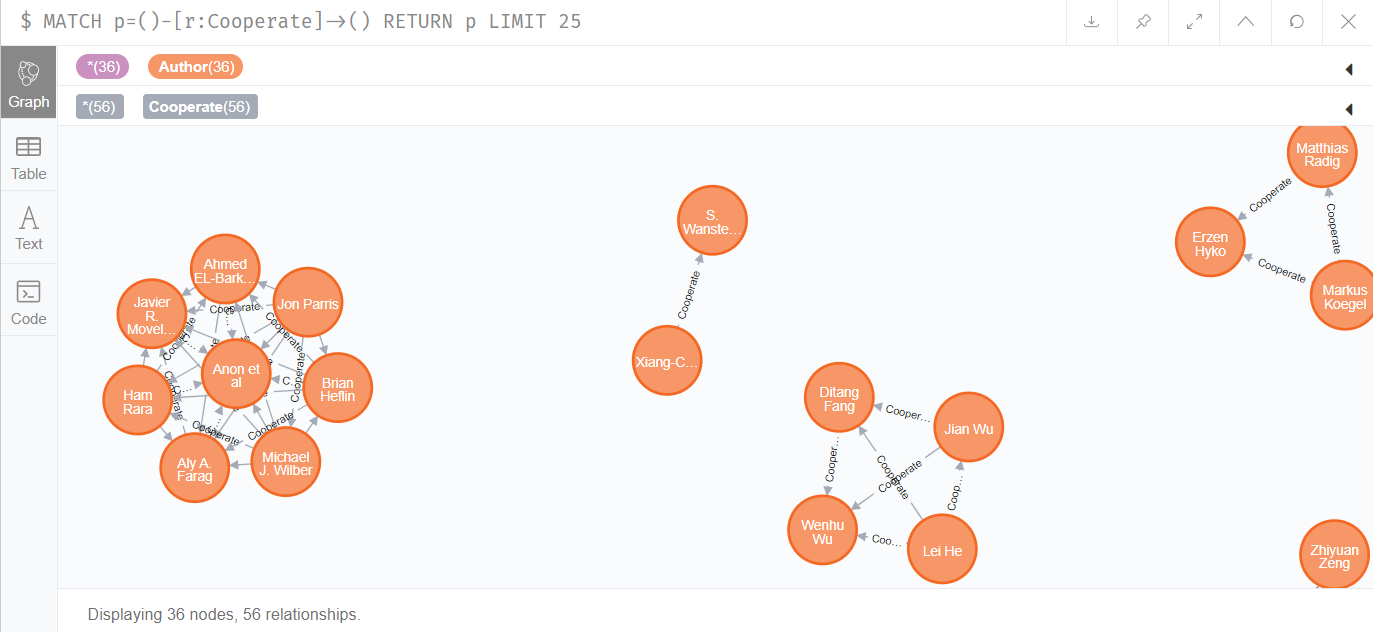
### 作者——机构关系
作者会属于某一个机构,因此,需要插入作者和机构之间的Work关系:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Author-Company.csv" AS line
MATCH (a:Author{index: line['author_index']}), (p: Company{name: line['affiliation']})
CREATE (a)-[:Work]->(p)
```
该关系的总量为1286650,如下所示:
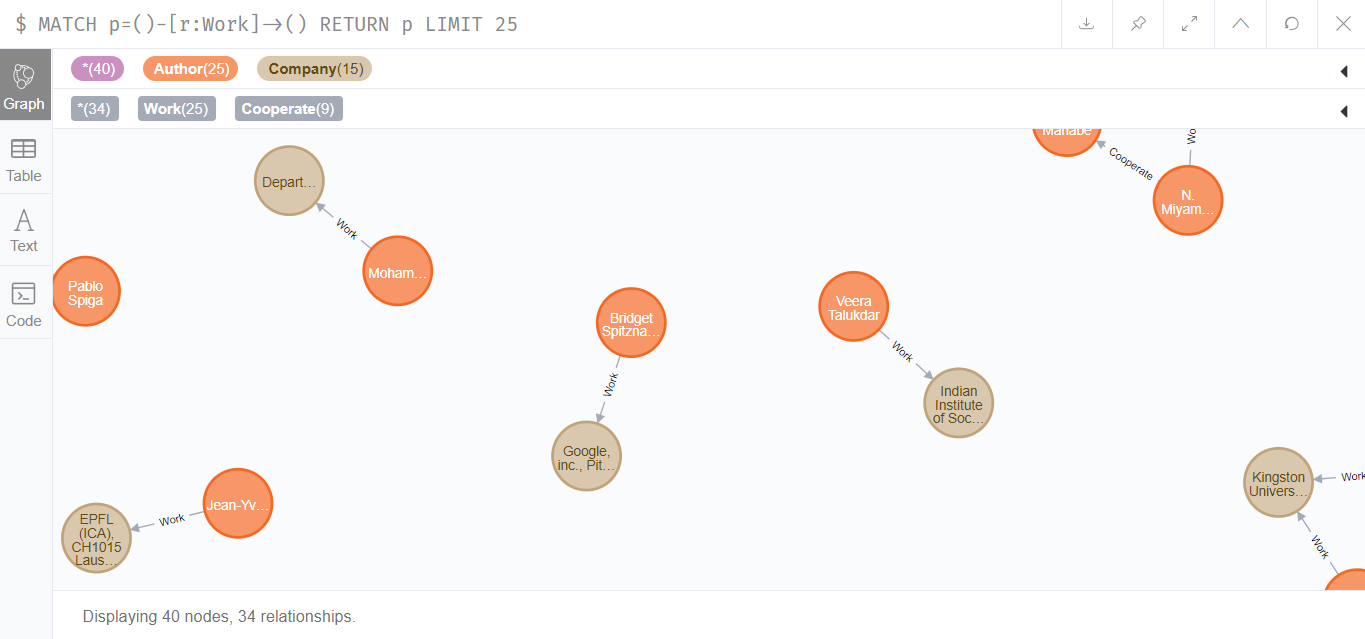
### 论文——机构关系
论文会在某一个机构下,因此论文和机构之间存在着Belongs关系:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Paper-Company.csv" AS line
MATCH (a:Paper{index: line['paper_index']}), (p: Company{name: line['affiliation']})
CREATE (a)-[:Belongs]->(p)
```
该关系的总数据量为1178333,如下图所示:
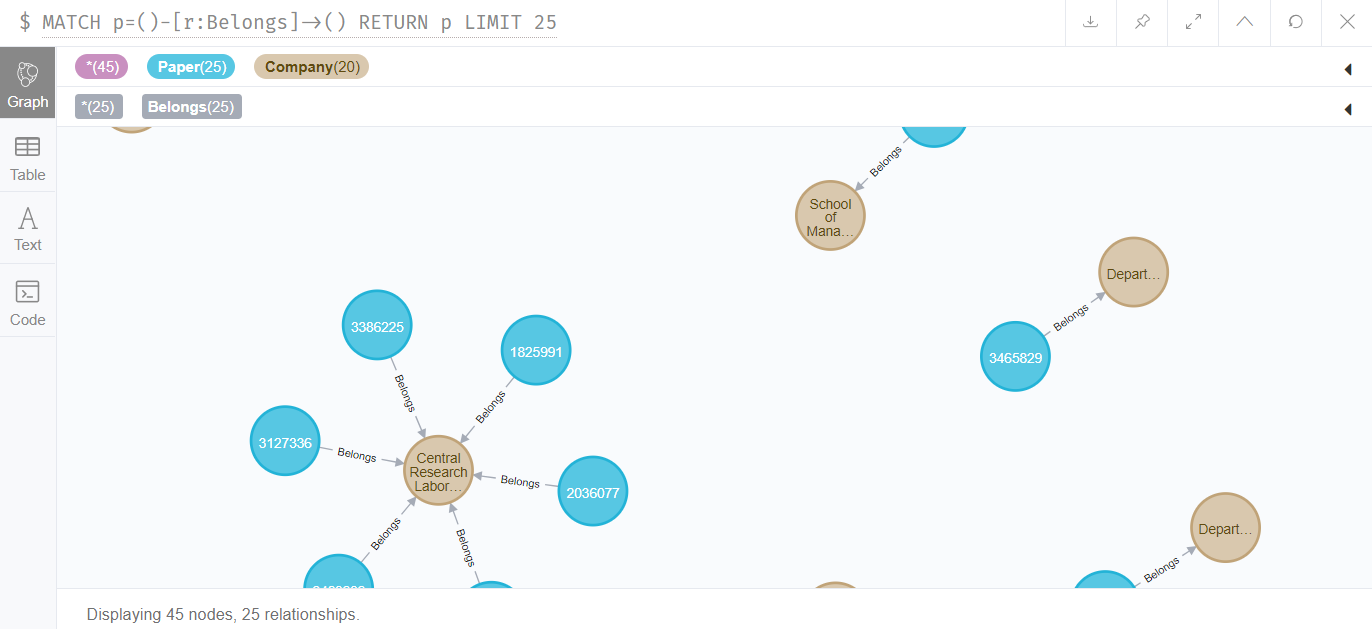
### 作者——领域关系表
一个作者可能对多个领域感兴趣,一个领域也可能有多个作者。因此,需要插入它们之间的关系:
``` cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM "file:///AMiner-Author-Interest.csv" AS line
MATCH (a:Author{index: line['author_index']}), (p: Area{name: line['interest']})
CREATE (a)-[:Search]->(p)
```
该关系的总数据量为14589918,如下所示:
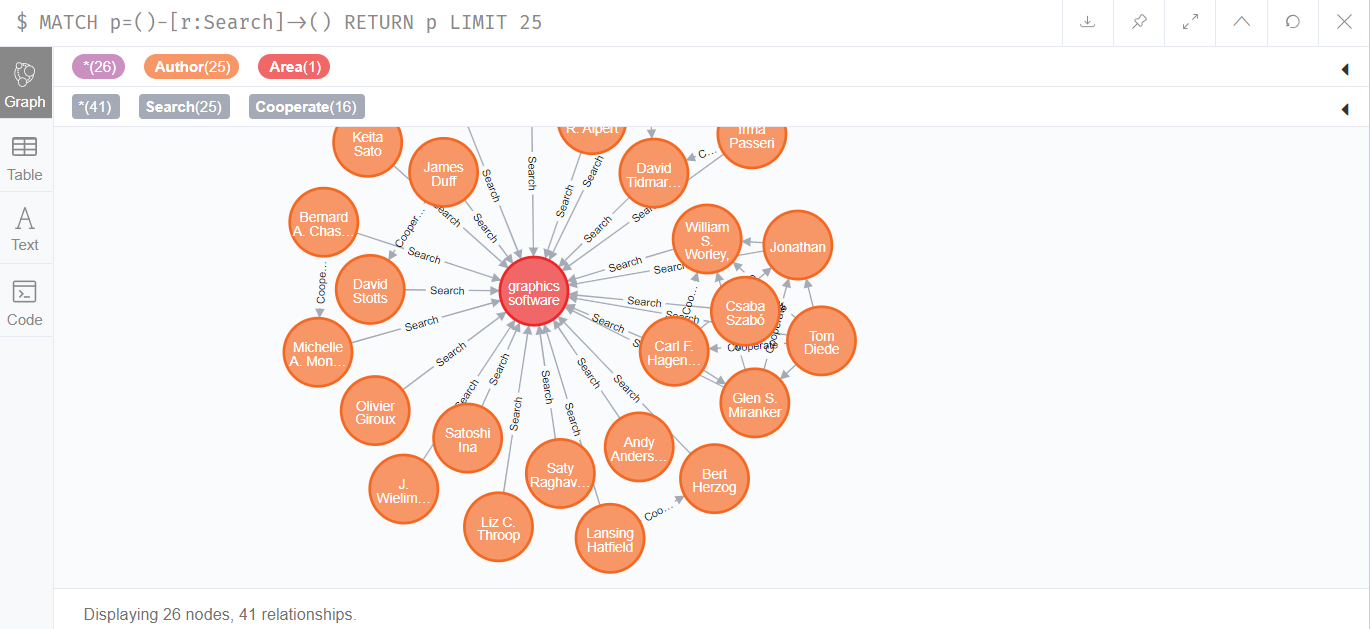
### 总结
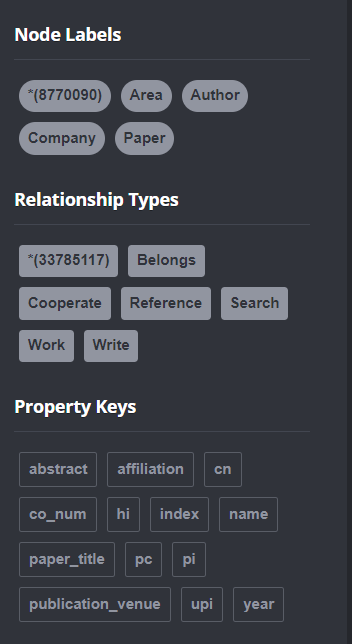
经过插入,neo4j中**共有8770090个结点和33785117个关系**,如下图所示:
## 3 功能实现
### 3.1 基本功能
#### 查询实体的关系和关联实体
输入:作者名/ 领域名
输出:与作者/ 领域相关的所有的关系以及实体
**实现方法**
前端输入作者名称,后端通过cypher语句执行查询。
语句如下所示:
```cypher
match (a:Author)
where a.name = \"{name}\"
return a.index as {returnProps}
```
```cypher
MATCH (a: Author)-[:Write]->(p: Paper)
where a.index = \"{authorIndex}\"
return p.paper_title as paper
```
```cypher
MATCH (a: Author)-[:Work]->(c: Company)
where a.index = \"{authorIndex}\"
return c.name as department
```
**示例**
用户输入`Hongming Zhu`,得到结果:

可以看到该作者有三个合作者,发表了一篇论文,同时属于一个部门。
#### 查询两个作者之间的合作关系
输入:两个作者名
输出:两个作者之间的合作论文
**实现方法**
前端输入两个作者名,后端先判断这两个作者之间是否为同一个人。
当判断完毕后,再通过cypher语句执行:
```cypher
MATCH (a:Author)-[r:Cooperate]->(b:Author)
where a.index = \"{authorIndex}\" return b as author
union
MATCH (a:Author)-[r:Cooperate]->(b:Author)
where b.index = \"{authorIndex}\" return a as author
```
**示例**
用户输入`Ar Hu` 和`Ralph C. Huntsinger`,得到结果:

### 3.2 基本业务
#### 查询某个领域中的关键作者和单位
如何理解关键是查询的关键,作者信息中存在h-index,p-index, up-index三种不同指标,这三种指标都相较于作者的论文数量与总引用量更能表达作者的综合水平。因此我们认为通过可供选择的指标进行筛选关键作者。
另一方面,筛选关键单位的方式也是存在两个的,一方面是通过包含该领域的作者数量,另一方面是包含该领域的整体作者指标均值。我们认为量并不能反映部门的权威性,因此我们选择采用该部门所包含该领域作者的p-index指标均值来反映关键性。
输入:领域名称,衡量指标,返回关键作者数量,返回关键部门数量
输出:关键作者信息列表,关键部门信息列表(包含部门名称,均值h-index, 均值p-index, 均值up-index, 作者数目, 包含作者信息)
**实现方法**
通过分别查询领域内关键作者与关键部门进行返回,cypher语句如下:
查询关键领域内的作者信息:
```cypher
MATCH (a:Author)-[:Search]->(ar:Area)
where ar.name=\"{area}\"
return a as author order by toFloat(a.{indicator}) desc limit {limit.ToString()}
```
查询关键领域内的部门信息:
```cypher
MATCH(a: Area)<-[:Search]-(au: Author)-[:Work]->(c: Company)
where a.name = \"{area}\"
return c.name as deptName, AVG(toFloat(au.pi)) as avgPi,
AVG(toFloat(au.upi)) as avgUpi, AVG(toFloat(au.hi)) as avgHi, count(*) as authorNum
order by avgPi desc limit {limit}
```
**示例**
用户输入`Graphics Software ` 和 `hi` ,选择`author limit` 为3, `department limit` 也为3, 如下所示:

#### 查询某个领域中的关键期刊
查询某个领域的关键期刊是同样考量期刊内的论文衡量指标,在这里我们采用期刊内的论文引用数量来代替论文数量衡量期刊的重要性,论文的总引用数量可以一定程度反应期刊在该领域的权威性
输入:领域名称,返回关键期刊数量
输出:关键期刊信息(期刊名称,包含论文数量,引用数量,论文信息)
**实现方法**
通过查询领域内的关键期刊进行返回,cypher语句如下:
```cypher
MATCH (a:Area)<-[:Search]-(au:Author)-[:Write]->(p:Paper)<-[r:Reference]-(:Paper) " +
where a.name=\"{area}\"
return p.publication_venue as venueName, count(distinct(p)) as paperCount, count(distinct(r)) as referenceCount
order by referenceCount desc limit {limit}
```
**示例**
用户输入`Graphics Software ` 和 `hi` ,选择`venue limit` 为2,如下所示:

## 4 加分项
### 4.1 ETL及数据更新
本数据集有实时插入和动态更新数据的需求,我们需要提供和实现数据更新功能。并且由于数据集的体量过大,需要实现增量更新。对此我们使用导入csv的方式来实现新增数据和增量更新。
#### 4.1.1 数据合法性验证
首先是csv文件的上传。前端使用上传组件提示用户读取本地的文件,并对文件的种类和大小做出严格限制。文件必须是csv格式,且大小不超过100M(约50万条数据)。
对于数据的插入和更新而言,最需要关注的是数据的合法性。对此我们使用前端提前校验的方式,对csv的表头部分进行校验,以保证数据能成功更新到数据库中:
```javascript
checkValidateHead(tableHead){
let flag = true
tableHead.forEach((item,index)=>{
if(index >= this.tableRule[this.currentChosedTableName].length
|| item !== this.tableRule[this.currentChosedTableName][index]){
flag = false;
}
})
return flag;
},
```
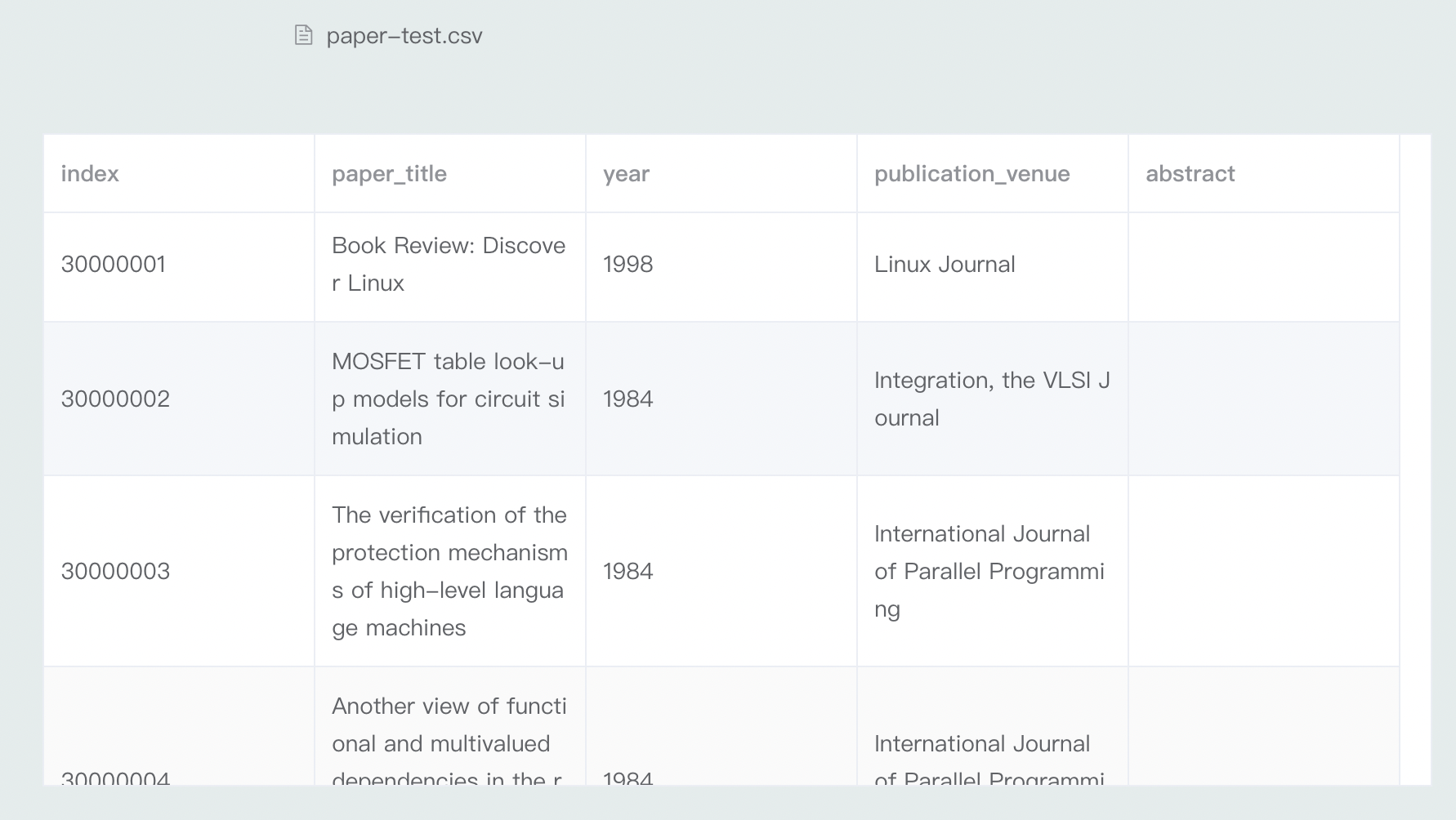
#### 4.2.2 数据读取
我们使用前端xlsx库在前端读取本地获取到的csv File文件,为了能让使用者直观查看csv内到数据,我们在前端实时显示了csv的表格内容:
同时在右侧展示合法的表头标签: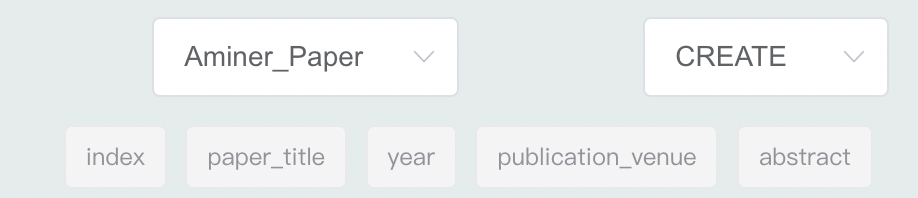
用户可以以此为依据在提交数据之前对自己的表格合法性进行自检。
同时,用户需要选择数据的模式是创建(CREATE)还是更新(MERGE),以及表的名称。我们支持全局9种数据库表的更新。
#### 4.1.3 图数据库实时更新
前端提交的数据会以FormData的形式传至后端,后端会将数据中的csv文件提取至对应的路径,执行图数据库的插入和更新语句(`LOAD CSV`),保证不同表间数据的一致性,因此数据的更新和插入是零时延的。
### 4.2 查询性能的提高
#### 4.2.1 数据插入过程中的优化
由于数据集相对比较大,因此用户导入需要较长的时间。
为了优化这一过程,同时保证导入过程中数据不会丢失,我们使用事务,也即每上传一定数据量就commit一次。
默认情况下,每一千行记录 neo4j 会进行一次 commit。通过`using periodic commit` 命令可以大大减少事务频繁 commit 带来的开销:
```cypher
using periodic commit 5000
LOAD CSV WITH HEADERS FROM
...
```
#### 4.2.2 索引优化
查询的过程中,对经常使用的字段建立索引,将大大减少查询时间。
如Company实体,在建立索引之前,根据name字段查询指定Company的时间如下所示:
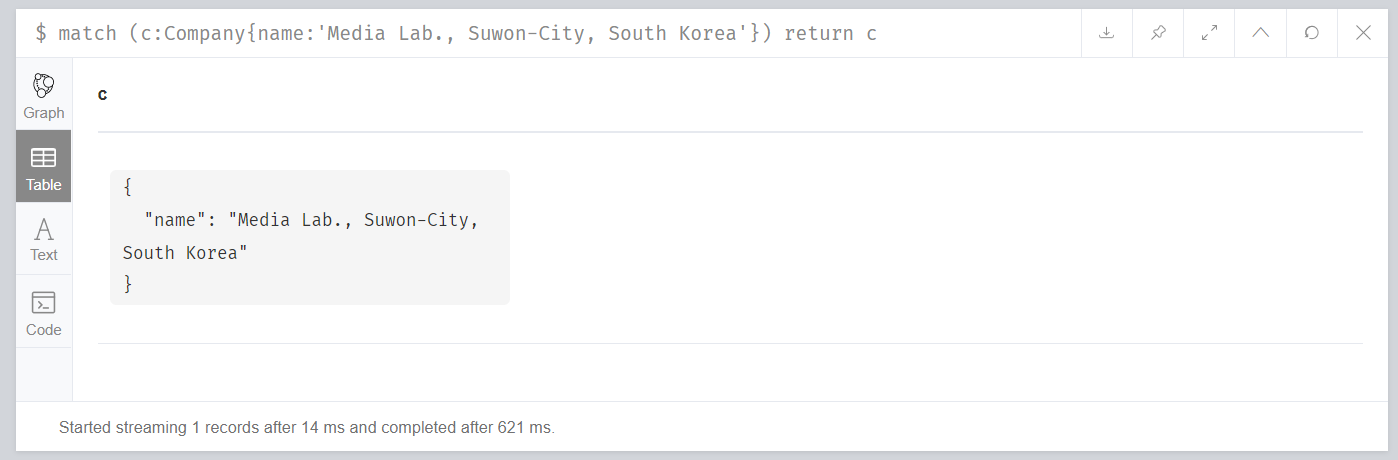
也即总计耗时14ms。
我们对Company的name字段建立索引:
```cypher
create index on:Company(name)
```
再次查询,时间如下所示:
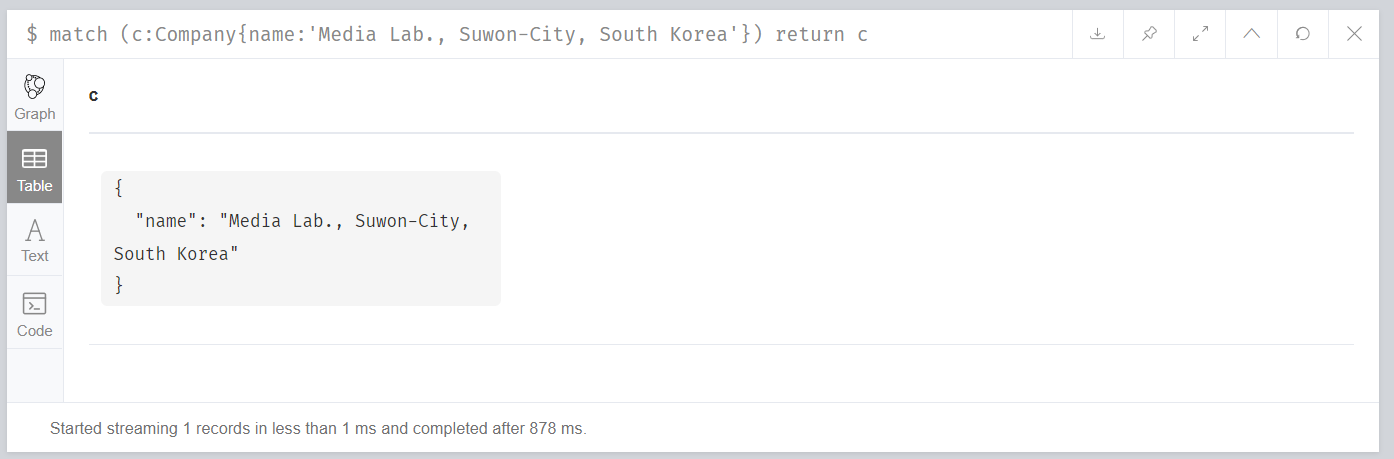
可以发现,查询用时降低到了1ms以内。
#### 4.2.3 缓存优化
缓存优化主要是对于复杂查询结果的保留。根据局部性原理,对于复杂查询的结果进行缓存保留可能会减少再次查询的时间(如果命中结果的话)。
对于本项目而言,消耗时间的查询无非是对领域内,关键作者、部门、期刊的查询。因此我们在后端查询中采用Redis来进行结果的暂存。
如果再次查询相关的内容,则会通过优先访问缓存内容。如果缓存命中,则将减少查询时间。
如图为Redis中存储的查询结果信息:

查询代码在此略过,见后端代码。
### 4.3 可视化
针对于搜索条件的输入,我们都提供了模糊匹配功能,以方便用户的使用:
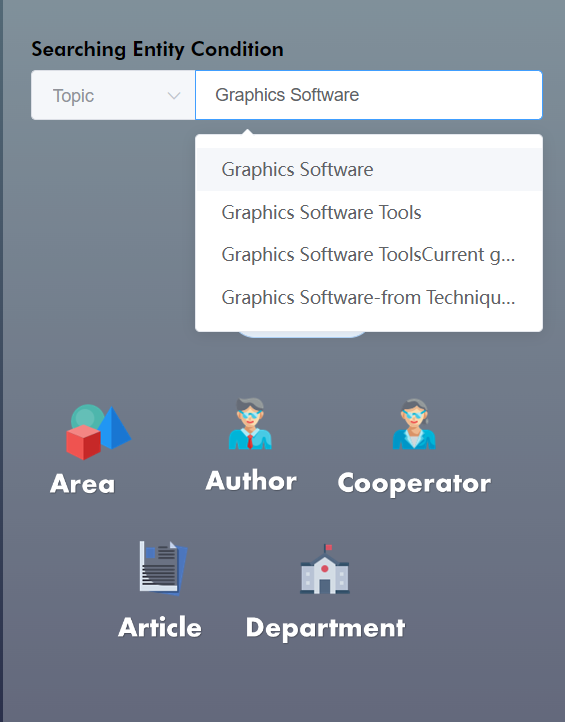
我们提供了多种结果展示方式。
#### 4.3.1 基本功能展示
针对于读者等实体检索,我们提供网络图的展示方式:
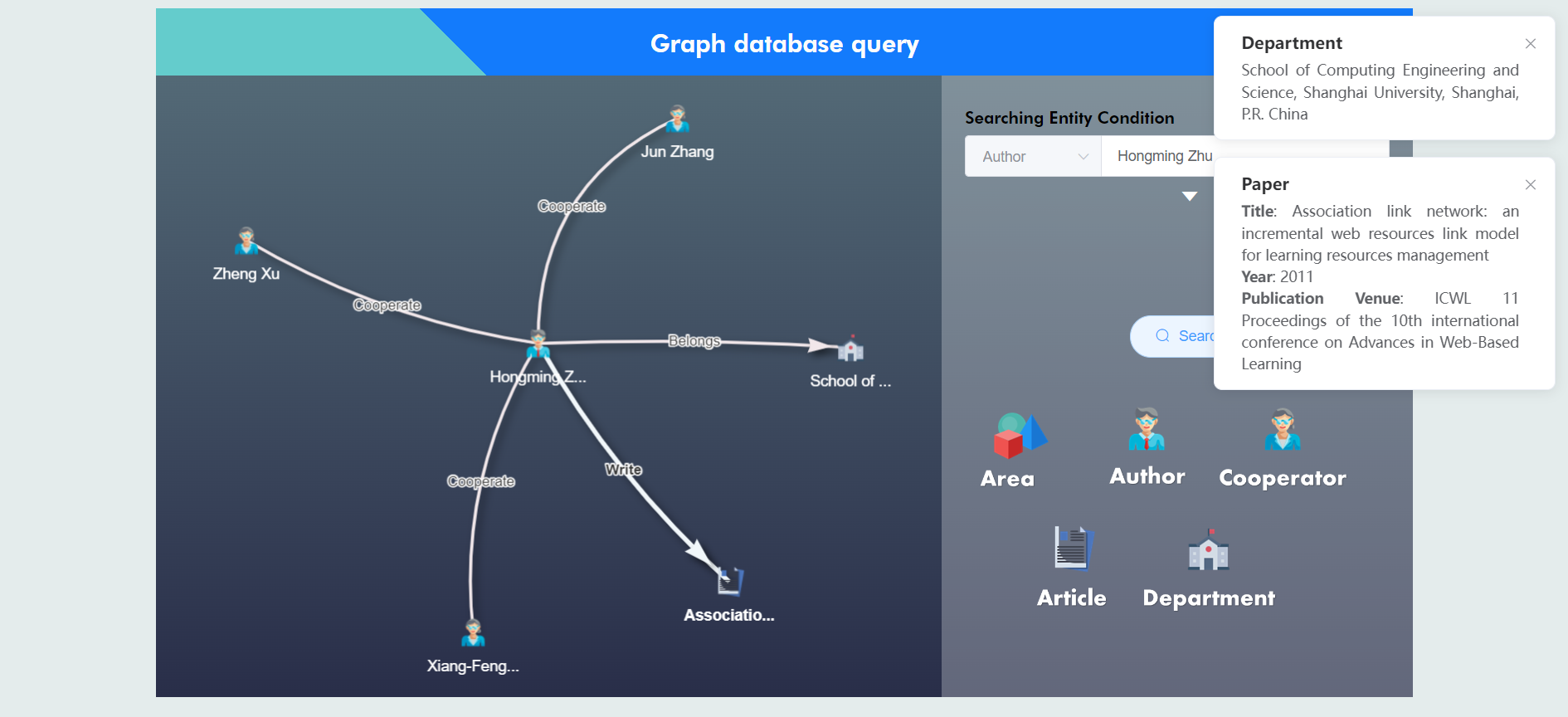
通过点击图中的结点,还可以查看部门、文章等具体信息。
此外,点击合作作者,支持对该作者进行进一步的检索:
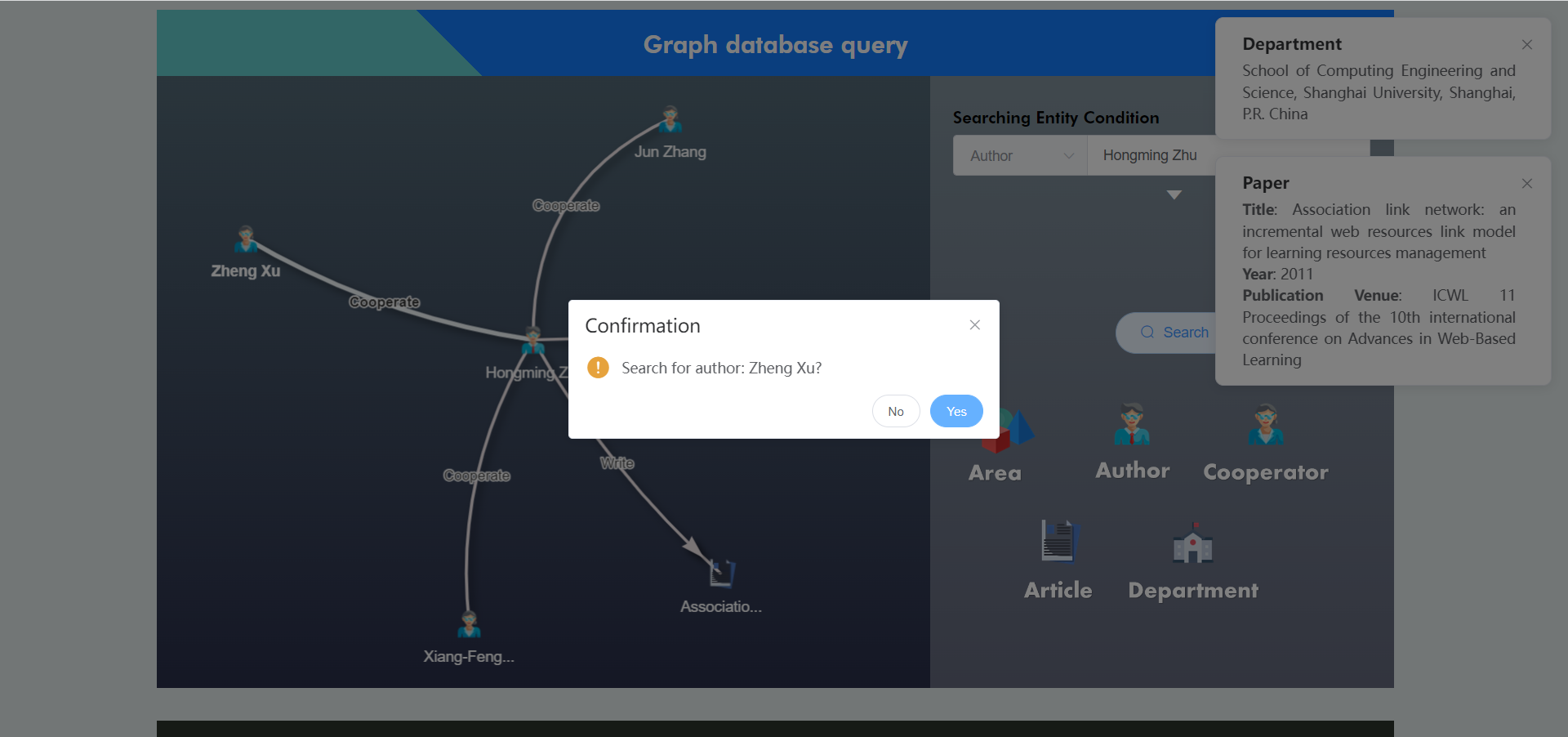
当出现重名作者的情况时,系统支持进一步选择具体是哪一个作者:
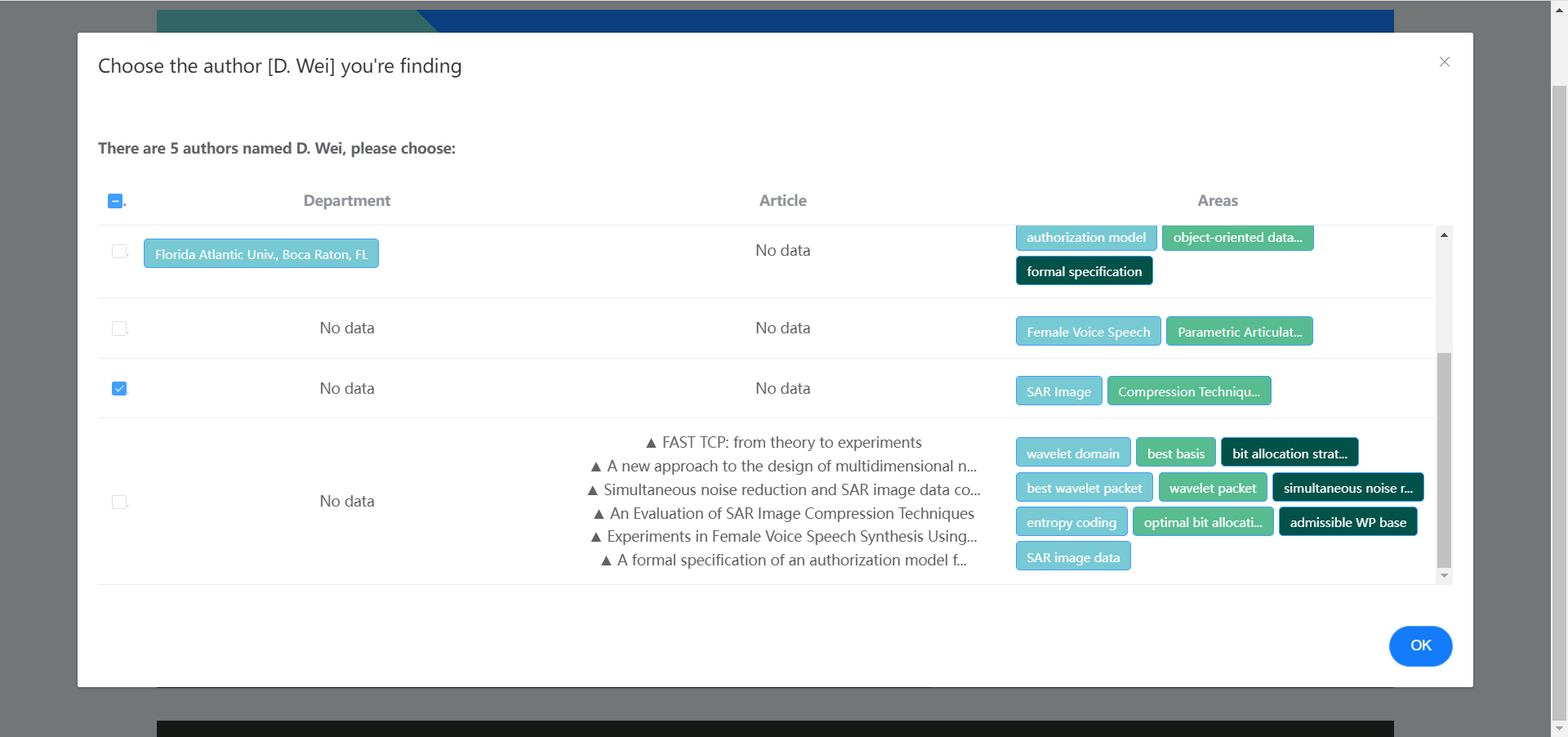
此外,网络图支持拖拽与放大 / 缩小等。
#### 4.3.2 基本业务展示
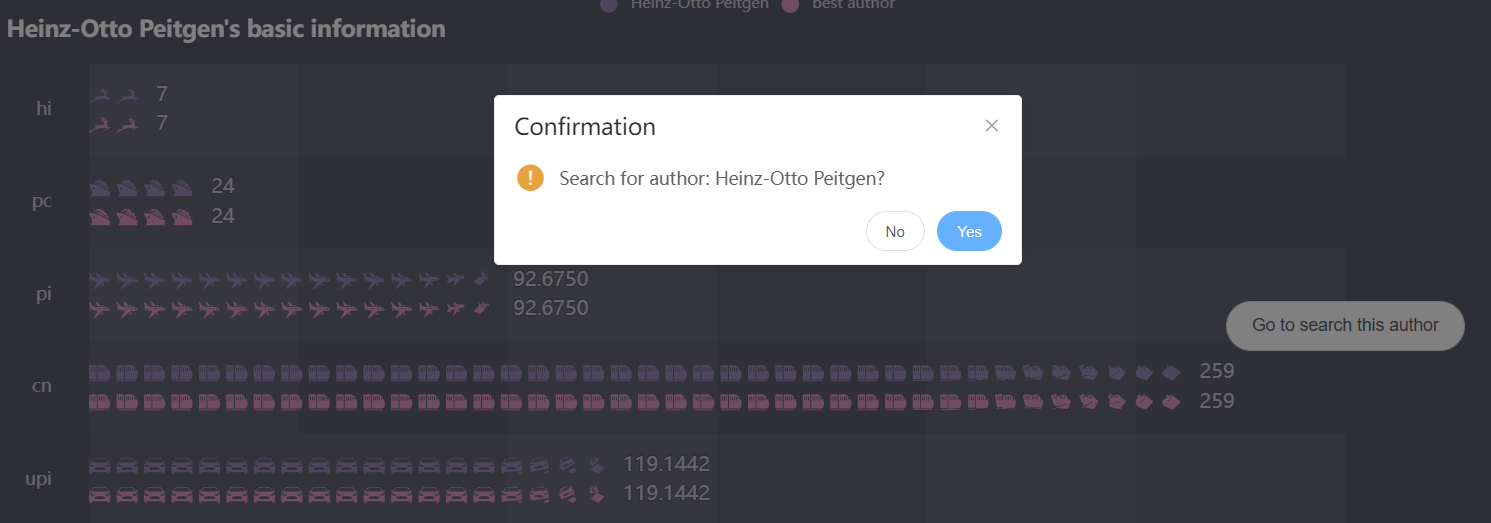
用户可以选择要查询的领域,以及使用的指标(pi、hi或upi)。
其中,关键作者和关键部门将以雷达图的方式显示在界面中;在下方,还可以查询某一个作者的具体指标。点击进一步搜索,可以进入该作者的搜索界面:
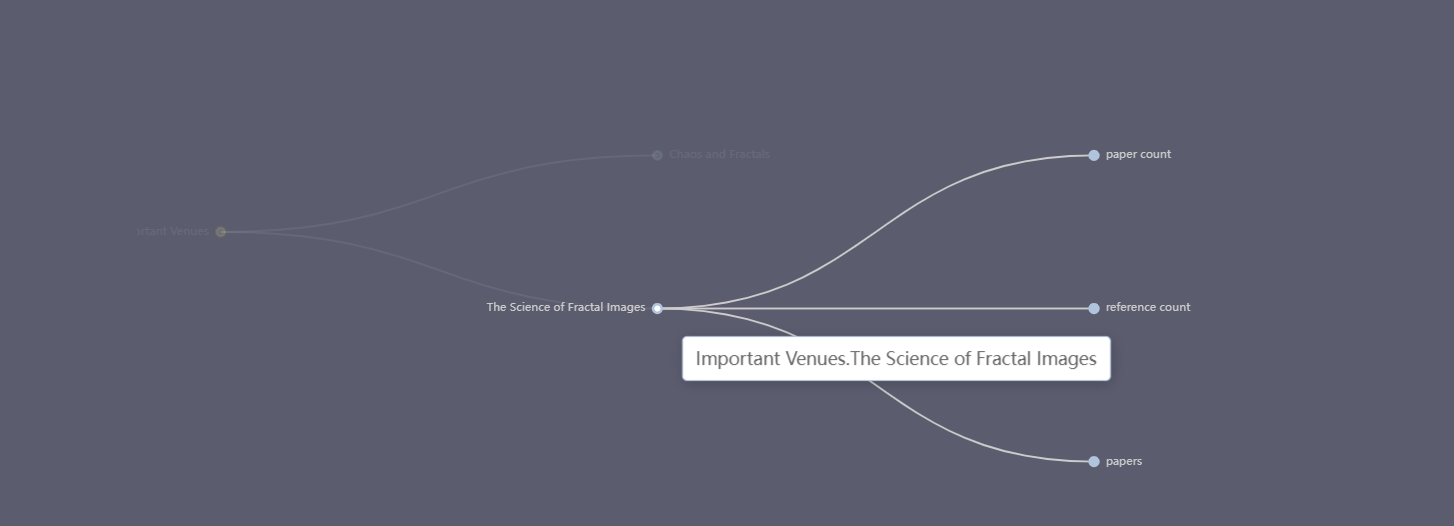
在最下方,关键期刊将以树形图的方式展示:
#### 4.3.3 辅助功能
为了方便用户更好的使用查询系统,我们提供了Navigation Video。
用户可以在界面中查看到数据集,并直接进行下载:
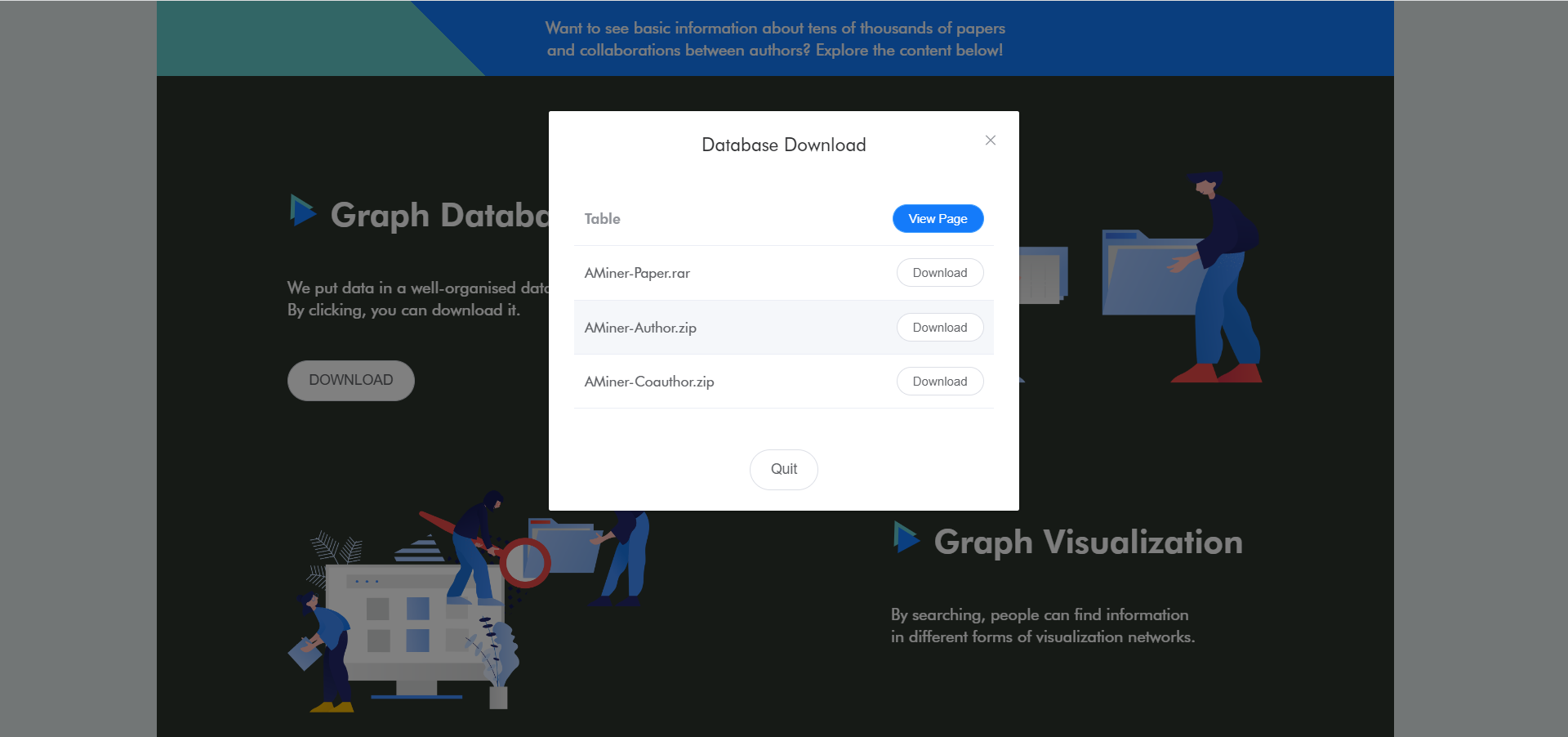
同时,网页提供了评论区以供交流:
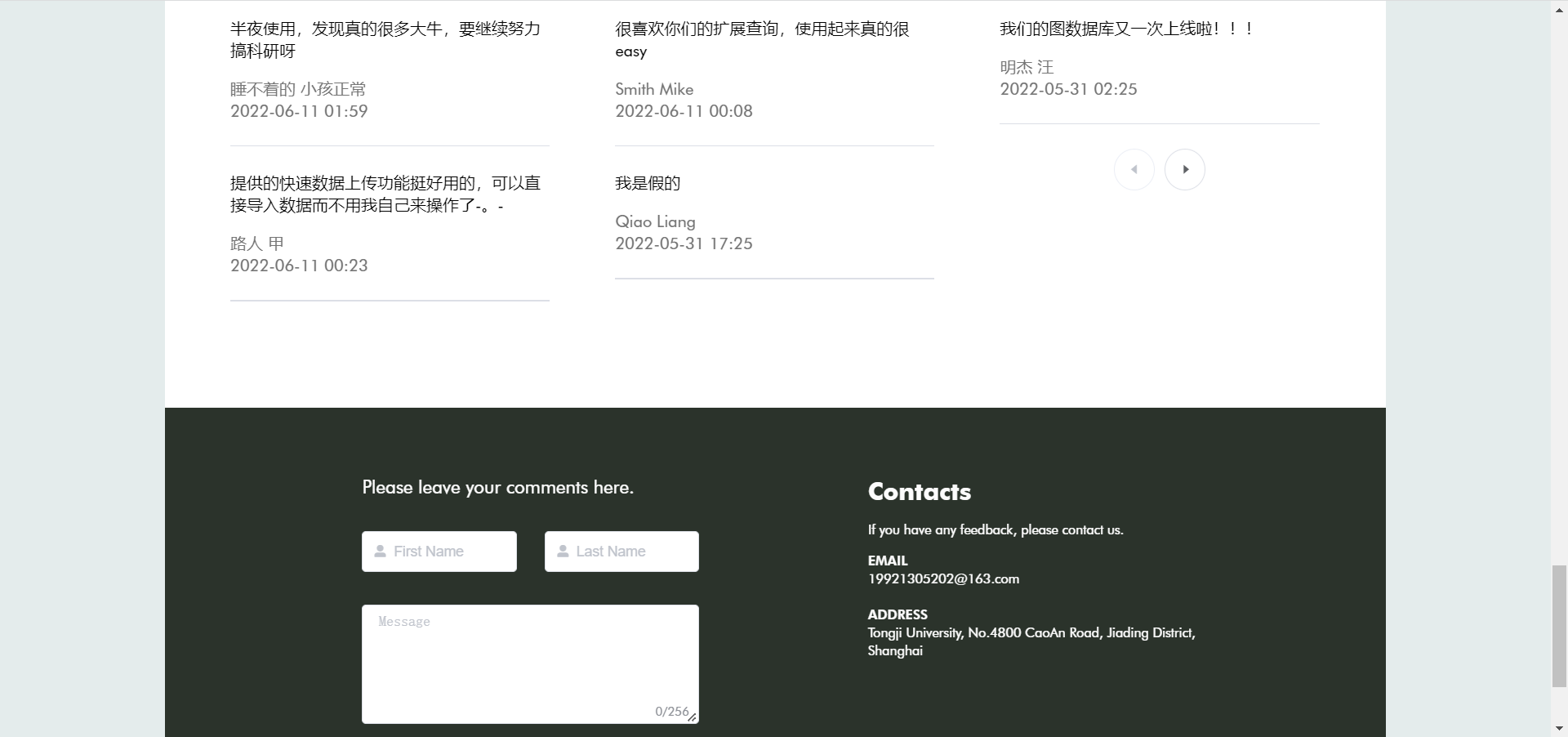
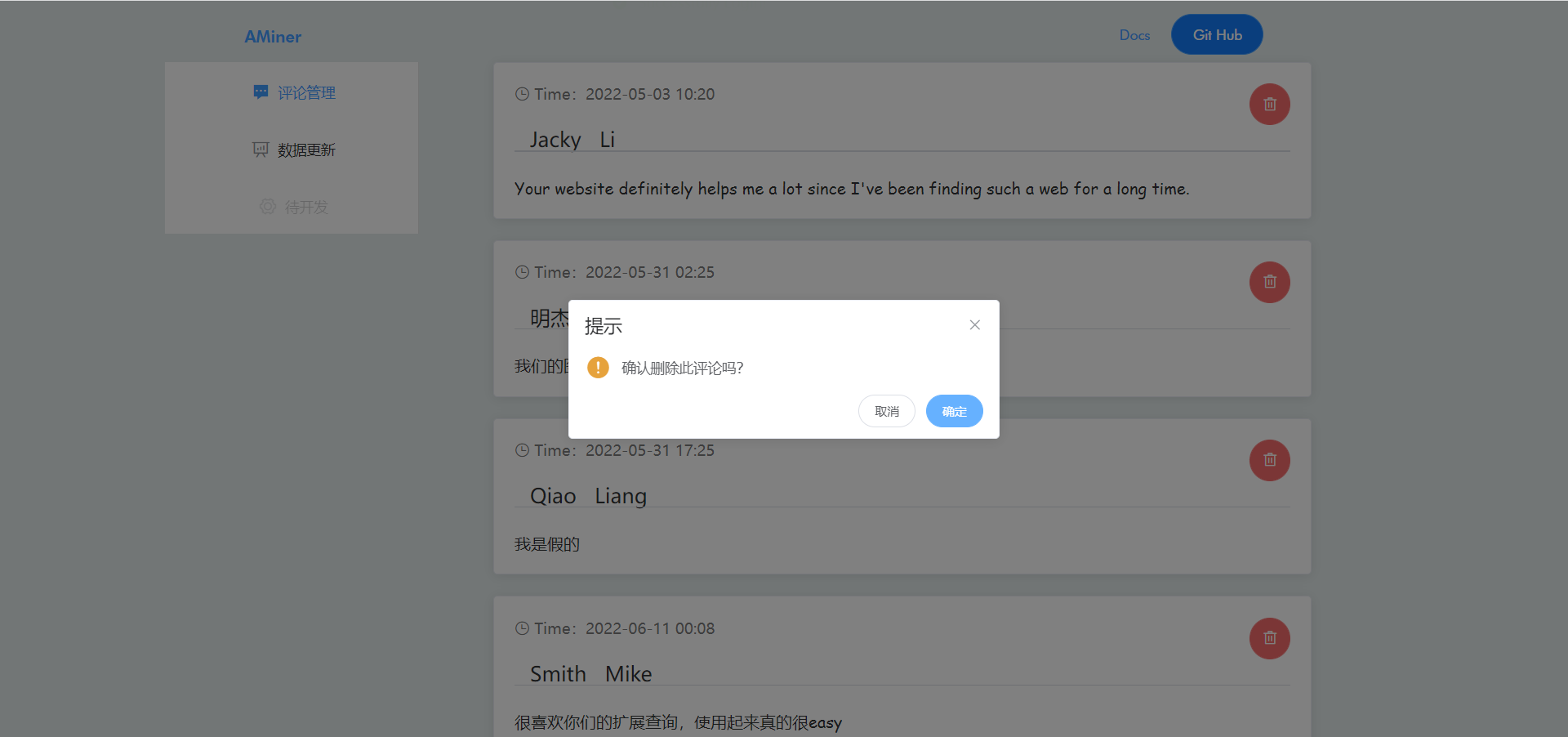
相对应的,我们也提供了评论管理界面:
数据上传部分在4.1部分已经介绍过,在此不再赘述。