https://github.com/williamyang1991/fresco
[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation
https://github.com/williamyang1991/fresco
controlnet diffusion video-processing
Last synced: about 1 year ago
JSON representation
[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation
- Host: GitHub
- URL: https://github.com/williamyang1991/fresco
- Owner: williamyang1991
- License: other
- Created: 2024-03-12T12:41:24.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-03-31T12:32:43.000Z (about 2 years ago)
- Last Synced: 2024-03-31T13:34:56.568Z (about 2 years ago)
- Topics: controlnet, diffusion, video-processing
- Language: Jupyter Notebook
- Homepage:
- Size: 9.94 MB
- Stars: 541
- Watchers: 11
- Forks: 51
- Open Issues: 18
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
# FRESCO - Official PyTorch Implementation
**FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation**
[Shuai Yang](https://williamyang1991.github.io/), [Yifan Zhou](https://zhouyifan.net/), [Ziwei Liu](https://liuziwei7.github.io/) and [Chen Change Loy](https://www.mmlab-ntu.com/person/ccloy/)
in CVPR 2024
[**Project Page**](https://www.mmlab-ntu.com/project/fresco/) | [**Paper**](https://arxiv.org/abs/2403.12962) | [**Supplementary Video**](https://youtu.be/jLnGx5H-wLw) | [**Input Data and Video Results**](https://drive.google.com/file/d/12BFx3hp8_jp9m0EmKpw-cus2SABPQx2Q/view?usp=sharing)

**Abstract:** *The remarkable efficacy of text-to-image diffusion models has motivated extensive exploration of their potential application in video domains.
Zero-shot methods seek to extend image diffusion models to videos without necessitating model training.
Recent methods mainly focus on incorporating inter-frame correspondence into attention mechanisms. However, the soft constraint imposed on determining where to attend to valid features can sometimes be insufficient, resulting in temporal inconsistency.
In this paper, we introduce FRESCO, intra-frame correspondence alongside inter-frame correspondence to establish a more robust spatial-temporal constraint. This enhancement ensures a more consistent transformation of semantically similar content across frames. Beyond mere attention guidance, our approach involves an explicit update of features to achieve high spatial-temporal consistency with the input video, significantly improving the visual coherence of the resulting translated videos.
Extensive experiments demonstrate the effectiveness of our proposed framework in producing high-quality, coherent videos, marking a notable improvement over existing zero-shot methods.*
**Features**:
- **Temporal consistency**: use intra-and inter-frame constraint with better consistency and coverage than optical flow alone.
- Compared with our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), FRESCO is more robust to large and quick motion.
- **Zero-shot**: no training or fine-tuning required.
- **Flexibility**: compatible with off-the-shelf models (e.g., [ControlNet](https://github.com/lllyasviel/ControlNet), [LoRA](https://civitai.com/)) for customized translation.
https://github.com/williamyang1991/FRESCO/assets/18130694/aad358af-4d27-4f18-b069-89a1abd94d38
## Updates
- [05/2024] The Diffusers pipeline is available: [FRESCO Community Pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#fresco).
- [04/2024] Integrated to 🤗 [Hugging Face](https://huggingface.co/spaces/PKUWilliamYang/FRESCO). Enjoy the web demo!
- [03/2024] Paper is released.
- [03/2024] Code is released.
- [03/2024] This website is created.
### TODO
- [x] ~~Integrate into Diffusers~~
- [x] ~~Add Huggingface web demo~~
- [x] ~~Add webUI.~~
- [x] ~~Update readme~~
- [x] ~~Upload paper to arXiv, release related material~~
## Installation
1. Clone the repository.
```shell
git clone https://github.com/williamyang1991/FRESCO.git
cd FRESCO
```
2. You can simply set up the environment with pip based on [requirements.txt](https://github.com/williamyang1991/FRESCO/blob/main/requirements.txt)
- Create a conda environment and install torch >= 2.0.0. Here is an example script to install torch 2.0.0 + CUDA 11.8 :
```
conda create --name diffusers python==3.8.5
conda activate diffusers
pip install torch==2.0.0 torchvision==0.15.1 --index-url https://download.pytorch.org/whl/cu118
```
- Run `pip install -r requirements.txt` in an environment where torch is installed.
- We have tested on torch 2.0.0/2.1.0 and diffusers 0.19.3
- If you use new versions of diffusers, you need to modify [my_forward()](https://github.com/williamyang1991/FRESCO/blob/fb991262615665de88f7a8f2cc903d9539e1b234/src/diffusion_hacked.py#L496)
3. Run the installation script. The required models will be downloaded in `./model`, `./src/ControlNet/annotator` and `./src/ebsynth/deps/ebsynth/bin`.
- Requires access to huggingface.co
```shell
python install.py
```
4. You can run the demo with `run_fresco.py`
```shell
python run_fresco.py ./config/config_music.yaml
```
5. For issues with Ebsynth, please refer to [issues](https://github.com/williamyang1991/Rerender_A_Video#issues)
## (1) Inference
### WebUI (recommended)
```
python webUI.py
```
The Gradio app also allows you to flexibly change the inference options. Just try it for more details.
Upload your video, input the prompt, select the model and seed, and hit:
- **Run Key Frames**: detect keyframes, translate all keyframes.
- **Run Propagation**: propagate the keyframes to other frames for full video translation
- **Run All**: **Run Key Frames** and **Run Propagation**
Select the model:
- **Base model**: base Stable Diffusion model (SD 1.5)
- Stable Diffusion 1.5: official model
- [rev-Animated](https://huggingface.co/stablediffusionapi/rev-animated): a semi-realistic (2.5D) model
- [realistic-Vision](https://huggingface.co/SG161222/Realistic_Vision_V2.0): a photo-realistic model
- [flat2d-animerge](https://huggingface.co/stablediffusionapi/flat-2d-animerge): a cartoon model
- You can add other models on huggingface.co by modifying this [line](https://github.com/williamyang1991/FRESCO/blob/1afcca9c7b1bc1ac68254f900be9bd768fbb6988/webUI.py#L362)
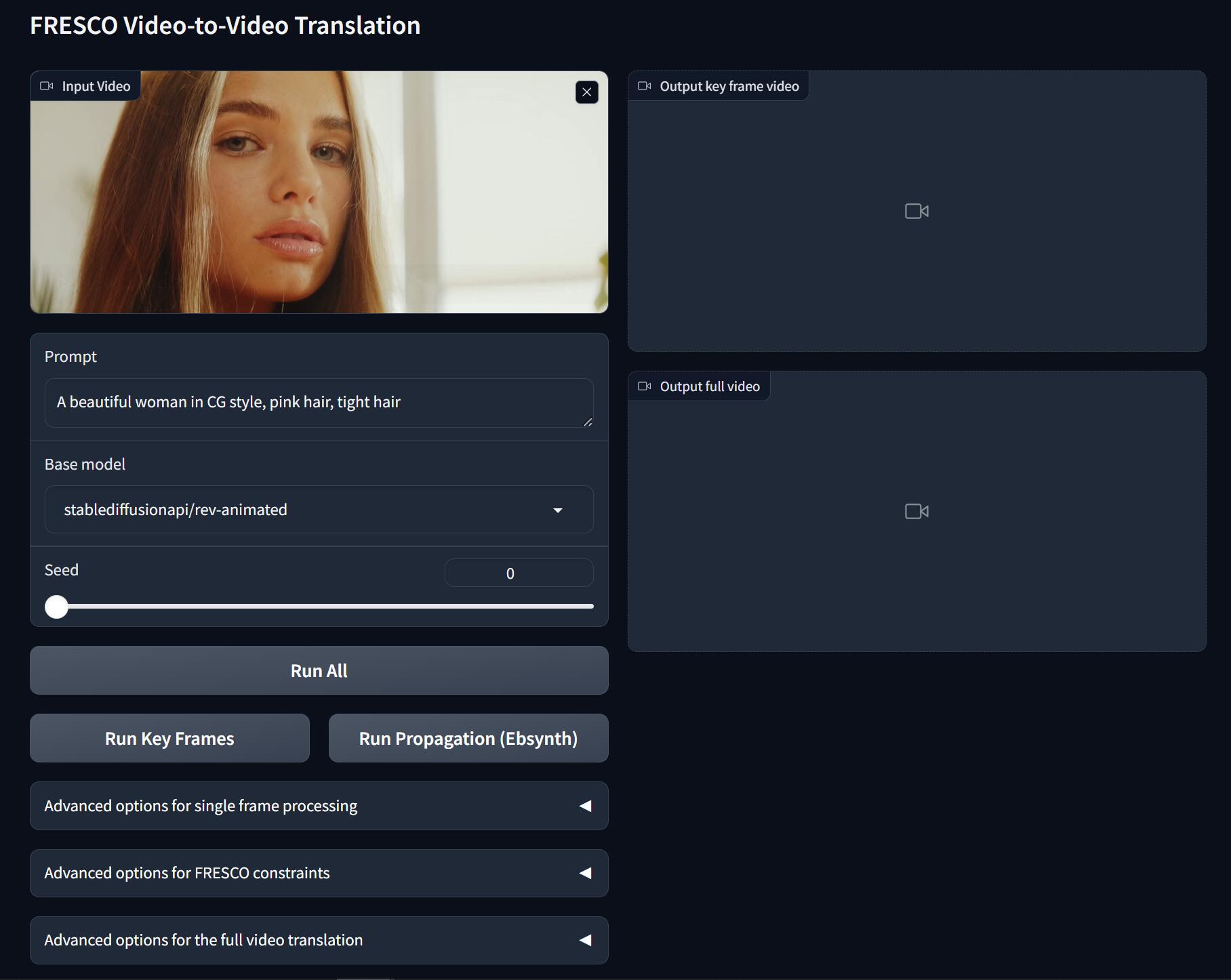
We provide abundant advanced options to play with
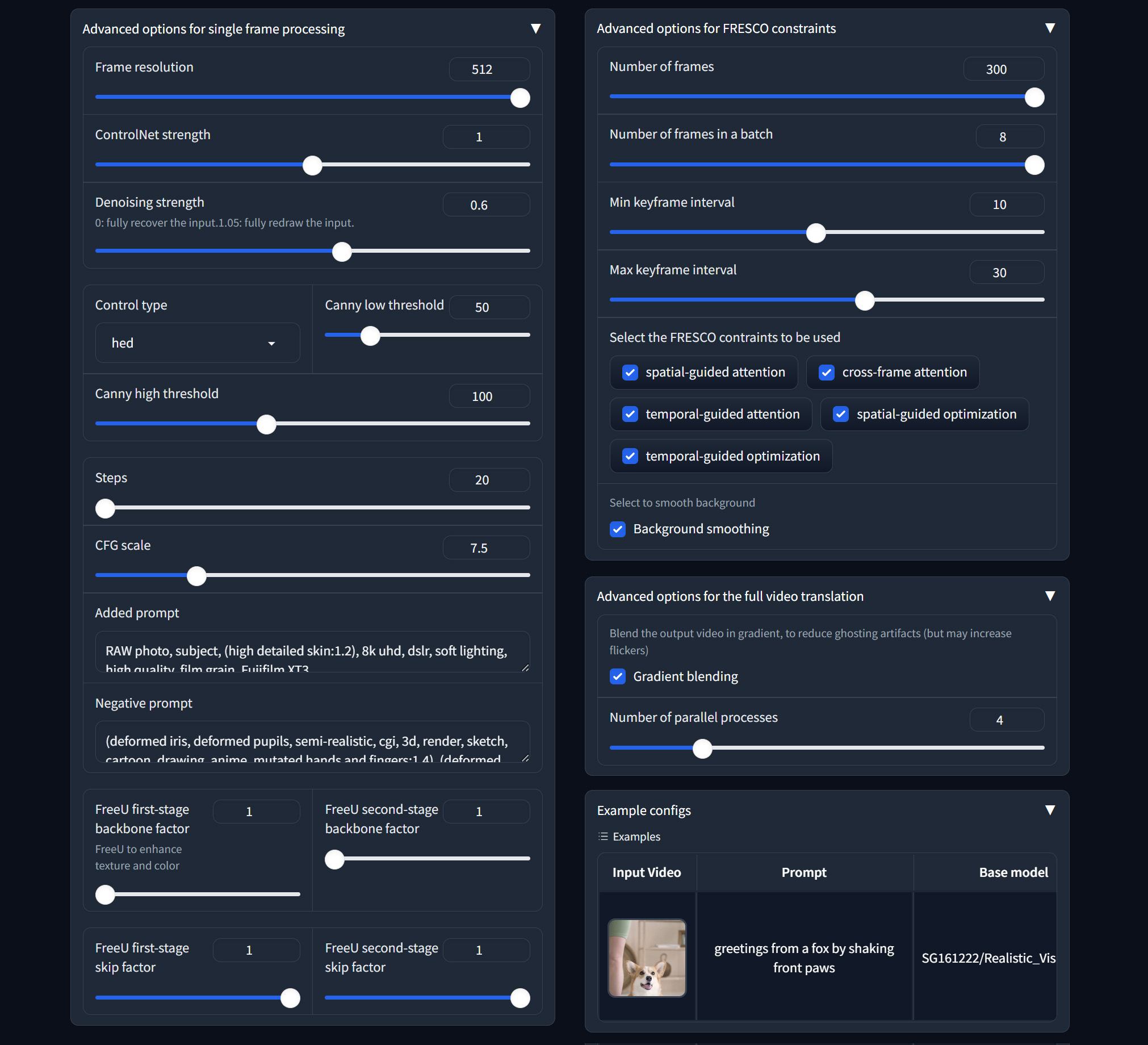
Advanced options for single frame processing
1. **Frame resolution**: resize the short side of the video to 512.
2. ControlNet related:
- **ControlNet strength**: how well the output matches the input control edges
- **Control type**: HED edge, Canny edge, Depth map
- **Canny low/high threshold**: low values for more edge details
3. SDEdit related:
- **Denoising strength**: repaint degree (low value to make the output look more like the original video)
- **Preserve color**: preserve the color of the original video
4. SD related:
- **Steps**: denoising step
- **CFG scale**: how well the output matches the prompt
- **Added prompt/Negative prompt**: supplementary prompts
5. FreeU related:
- **FreeU first/second-stage backbone factor**: =1 do nothing; >1 enhance output color and details
- **FreeU first/second-stage skip factor**: =1 do nothing; <1 enhance output color and details
Advanced options for FRESCO constraints
1. Keyframe related
- **Number of frames**: Total frames to be translated
- **Number of frames in a batch**: To avoid out-of-memory, use small batch size
- **Min keyframe interval (s_min)**: The keyframes will be detected at least every s_min frames
- **Max keyframe interval (s_max)**: The keyframes will be detected at most every s_max frames
2. FRESCO constraints
- FRESCO-guided Attention:
- **spatial-guided attention**: Check to enable spatial-guided attention
- **cross-frame attention**: Check to enable efficient cross-frame attention
- **temporal-guided attention**: Check to enable temporal-guided attention
- FRESCO-guided optimization:
- **spatial-guided optimization**: Check to enable spatial-guided optimization
- **temporal-guided optimization**: Check to enable temporal-guided optimization
3. **Background smoothing**: Check to enable background smoothing (best for static background)
Advanced options for the full video translation
1. **Gradient blending**: apply Poisson Blending to reduce ghosting artifacts. May slow the process and increase flickers.
2. **Number of parallel processes**: multiprocessing to speed up the process. Large value (4) is recommended.
### Command Line
We provide a flexible script `run_fresco.py` to run our method.
Set the options via a config file. For example,
```shell
python run_fresco.py ./config/config_music.yaml
```
We provide some examples of the config in `config` directory.
Most options in the config is the same as those in WebUI.
Please check the explanations in the WebUI section.
We provide a separate Ebsynth python script `video_blend.py` with the temporal blending algorithm introduced in
[Stylizing Video by Example](https://dcgi.fel.cvut.cz/home/sykorad/ebsynth.html) for interpolating style between key frames.
It can work on your own stylized key frames independently of our FRESCO algorithm.
```python
video_blend.py [-h] [--output OUTPUT] [--fps FPS] [--key_ind KEY_IND [KEY_IND ...]] [--key KEY] [--n_proc N_PROC] [-ps] [-ne] [-tmp] name
positional arguments:
name Path to input video
optional arguments:
-h, --help show this help message and exit
--output OUTPUT Path to output video
--fps FPS The FPS of output video
--key_ind KEY_IND [KEY_IND ...]
key frame index
--key KEY The subfolder name of stylized key frames
--n_proc N_PROC The max process count
-ps Use poisson gradient blending
-ne Do not run ebsynth (use previous ebsynth output)
-tmp Keep temporary output
```
An example
```
python video_blend.py ./output/dog/ --key keys --key_ind 0 11 23 33 49 60 72 82 93 106 120 137 151 170 182 193 213 228 238 252 262 288 299 --output ./output/dog/blend.mp4 --fps 24 --n_proc 4 -ps
```
For the details, please refer to our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video/tree/main?tab=readme-ov-file#our-ebsynth-implementation) (The mainly difference is the way of specifying key frame index)
## (2) Results
### Key frame translation




a red car turns in the winter
an African American boxer wearing black boxing gloves punches towards the camera, cartoon style
a cartoon spiderman in black suit, black shoes and white gloves is dancing
a beautiful woman holding her glasses in CG style
### Full video translation
https://github.com/williamyang1991/FRESCO/assets/18130694/bf8bfb82-5cb7-4b2f-8169-cf8dbf408b54
## Citation
If you find this work useful for your research, please consider citing our paper:
```bibtex
@inproceedings{yang2024fresco,
title = {FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation},
author = {Yang, Shuai and Zhou, Yifan and Liu, Ziwei and and Loy, Chen Change},
booktitle = {CVPR},
year = {2024},
}
```
## Acknowledgments
The code is mainly developed based on [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), [ControlNet](https://github.com/lllyasviel/ControlNet), [Stable Diffusion](https://github.com/Stability-AI/stablediffusion), [GMFlow](https://github.com/haofeixu/gmflow) and [Ebsynth](https://github.com/jamriska/ebsynth).