https://github.com/williamyang98/viterbidecodercpp
Viterbi decoder with vectorisation written in C++
https://github.com/williamyang98/viterbidecodercpp
convolutional-encoder decoding-algorithm dsp viterbi-decoder
Last synced: 9 months ago
JSON representation
Viterbi decoder with vectorisation written in C++
- Host: GitHub
- URL: https://github.com/williamyang98/viterbidecodercpp
- Owner: williamyang98
- License: lgpl-2.1
- Created: 2023-02-18T12:22:33.000Z (over 3 years ago)
- Default Branch: master
- Last Pushed: 2025-02-24T15:57:12.000Z (over 1 year ago)
- Last Synced: 2025-04-22T05:22:09.180Z (about 1 year ago)
- Topics: convolutional-encoder, decoding-algorithm, dsp, viterbi-decoder
- Language: C++
- Homepage:
- Size: 222 KB
- Stars: 12
- Watchers: 3
- Forks: 4
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Introduction
[](https://github.com/williamyang98/ViterbiDecoderCpp/actions/workflows/x86-windows.yml)
[](https://github.com/williamyang98/ViterbiDecoderCpp/actions/workflows/x86-linux.yml)
[](https://github.com/williamyang98/ViterbiDecoderCpp/actions/workflows/arm-linux.yml)
This is a C++ port of Phil Karn's Viterbi decoder which can be found [here](https://github.com/ka9q/libfec).
**This is a header only library. Just copy and paste the header files to your desired location.**
See examples/run_simple.cpp for a common usage scenario.
Modifications include:
- Templated code for creating decoders of any code rate and constraint length
- Branch table can be specified at runtime and shared between multiple decoders
- Initial error values and renormalisation threshold can be specified
- Vectorisation using intrinsics for arbitary constraint lengths (where possible) for significant speedups
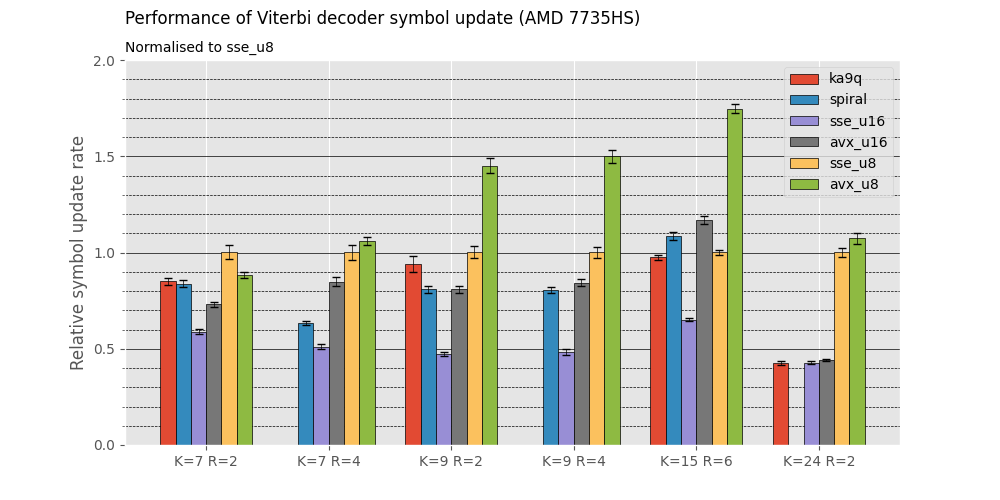
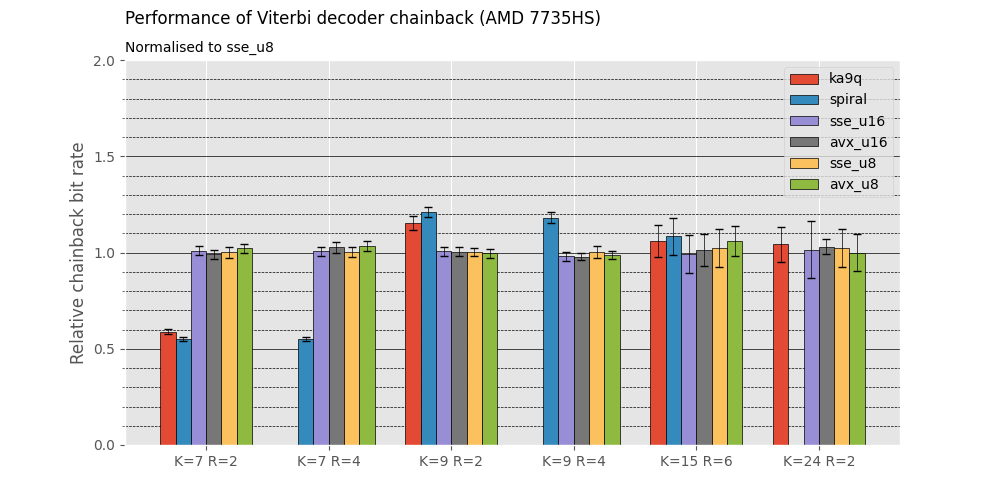
Performance is similar to Phil Karn's original C implementation for provided decoders.
Heavy templating is used for better performance. Compared to code that uses constraint length (K) and code rate (R) as runtime parameters [here](https://github.com/williamyang98/ViterbiDecoderCpp/tree/44cdd3c0a38a748a7084edeff859cf4d54ac911a), the templated version is up to 50% faster. This is because the compiler can perform more optimisations if the constraint length and code rate are known ahead of time.
# Intrinsics support
For x86 processors AVX2 or SSE4.1 is required for vectorisation.
For arm processors aarch64 is required for vectorisation.
The following intrinsic implementations exist:
- 16bit error metrics and soft decision values
- 8bit error metrics and soft decision values
Each vectorisaton type requires the convolution code to have a minimum constraint length (K)
| Type | Width | Kmin | Speedup |
| --- | --- | --- | --- |
| Scalar | | 2 | 1x |
| x86 SSE4.1 | 16bit | 5 | 8x |
| x86 SSE4.1 | 8bit | 6 | 16x |
| x86 AVX2 | 16bit | 6 | 16x |
| x86 AVX2 | 8bit | 7 | 32x |
| ARM Neon | 16bit | 5 | 8x |
| ARM Neon | 8bit | 6 | 16x |
Benchmarks show that the vectorised decoders have significiant speedups that can approach or supercede the theoretical values.
Using the 16bit and 8bit based intrinsics implementations as a guide you can make your own intrinsics implementation.
# Additional notes
- **Significant performance improvements can be achieved with using [offset binary](https://en.wikipedia.org/wiki/Offset_binary)**
- Soft decision values take the form of offset binary given by: 0 to N
- The branch table needs values: 0 and N
- Instead of performing a subtract then absolute, you can use an XOR operation which behaves like conditional negation
- Refer to the [original Phil Karn code](https://github.com/ka9q/libfec/blob/7c6706fb969c3f8fe6ec7778b2472762e0d88acc/viterbi615_sse2.c#L128) for this improvement
- Explanation with example
- Branch table has values: 0 or 255
- Soft decision values in offset binary: 0 to 255
- Consider a soft decision value of x
- If branch value is 0, XOR will return x
- If branch value is 255, XOR will return 255-x
- Performance improvements can be achieved with using signed integer types
- Using signed integer types allows for the use of modular arithmetic instead of saturated arithmetic. This can provide a up to a 33% speed boost due to CPI decreasing from 0.5 to 0.33.
- Unsigned integer types are used since they increase the range of error values after renormalisation, and saturated arithmetic will prevent overflows/underflows.
- The implementations uses template parameters and static asserts to:
- Check if the provided constraint length and code rate meet the vectorisation requirements
- Generate aligned data structures and provide the compiler more information about the decoder for better optimisation
- Unsigned 8bit error metrics have severe limitations. These include:
- Limited range of soft decision values to avoid overflowing past the renormalisation threshold.
- Higher code rates (such as Cassini) will quickly reach the renormalisation threshold and deteriorate in accuracy. This is because the maximum error for each branch is a multiple of the code rate.
- If you are only interested in hard decision decoding then using 8bit error metrics is the better choice
- Use hard decision values [-1,+1] of type int8_t
- Due to the small maximum branch error of 2*R we can set the renormalisation threshold to be quite high.
- renormalisation_threshold = UINT8_MAX - (2\*R\*10)
- This is less accurate compared to 16bit soft decision decoding but with up to 2x performance due to the usage of 8bit values.
- 
- Depending on your usage requirements changes to the library are absolutely encouraged
- Additionally check out Phil Karn's fine tuned assembly code [here](https://github.com/ka9q/libfec) for the best possible performance
- This code is not considered heavily tested and your mileage may vary. Refer to ```/examples``` for applications to benchmark performance and verify accuracy.
# Useful alternatives
- [Spiral project](https://www.spiral.net/software/viterbi.html) aims to auto-generate high performance code for any input parameters
- [ka9q/libfec](https://github.com/ka9q/libfec) is Phil Karn's original C implementation
# Benchmarks
Benchmarks are available in a separate repository located [here](https://github.com/williamyang98/ka9q_viterbi_comparison)