https://github.com/woctezuma/regression
Gaussian Process Regression vs. Relevance Vector Machine.
https://github.com/woctezuma/regression
data-analysis data-science gaussian-process-regression machine-learning python regression relevance-vector-machine statistics
Last synced: about 1 year ago
JSON representation
Gaussian Process Regression vs. Relevance Vector Machine.
- Host: GitHub
- URL: https://github.com/woctezuma/regression
- Owner: woctezuma
- License: mit
- Created: 2019-03-23T18:40:23.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2024-06-18T06:56:42.000Z (about 2 years ago)
- Last Synced: 2025-04-08T10:50:22.590Z (over 1 year ago)
- Topics: data-analysis, data-science, gaussian-process-regression, machine-learning, python, regression, relevance-vector-machine, statistics
- Language: Python
- Homepage:
- Size: 42 KB
- Stars: 4
- Watchers: 2
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Regression
[![Code Quality][codacy-image]][codacy]
This repository contains Python code to perform 1-D regression with:
- [Gaussian Process Regression](https://en.wikipedia.org/wiki/Kriging),
- [Relevance Vector Machine](https://en.wikipedia.org/wiki/Relevance_vector_machine).
## Requirements
- Install the latest version of [Python 3.X](https://www.python.org/downloads/).
- Install the required packages:
```bash
pip install -r requirements.txt
pip install https://github.com/JamesRitchie/scikit-rvm/archive/master.zip
```
## Usage
```bash
python main.py
```
## Results
The ground truth is the sinc function.
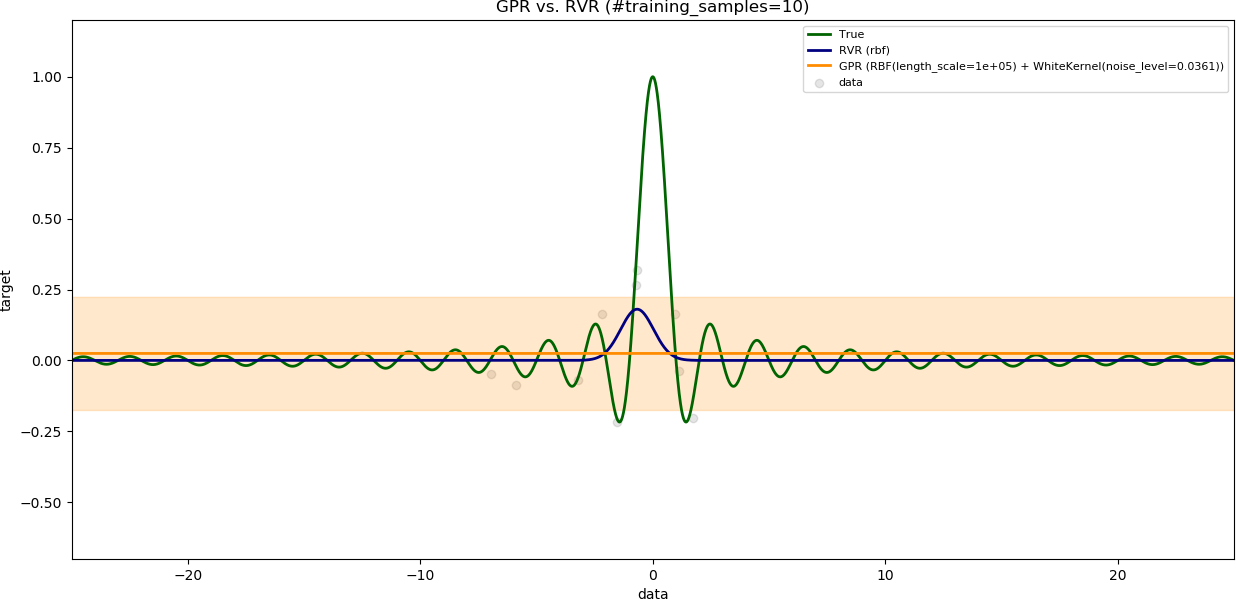
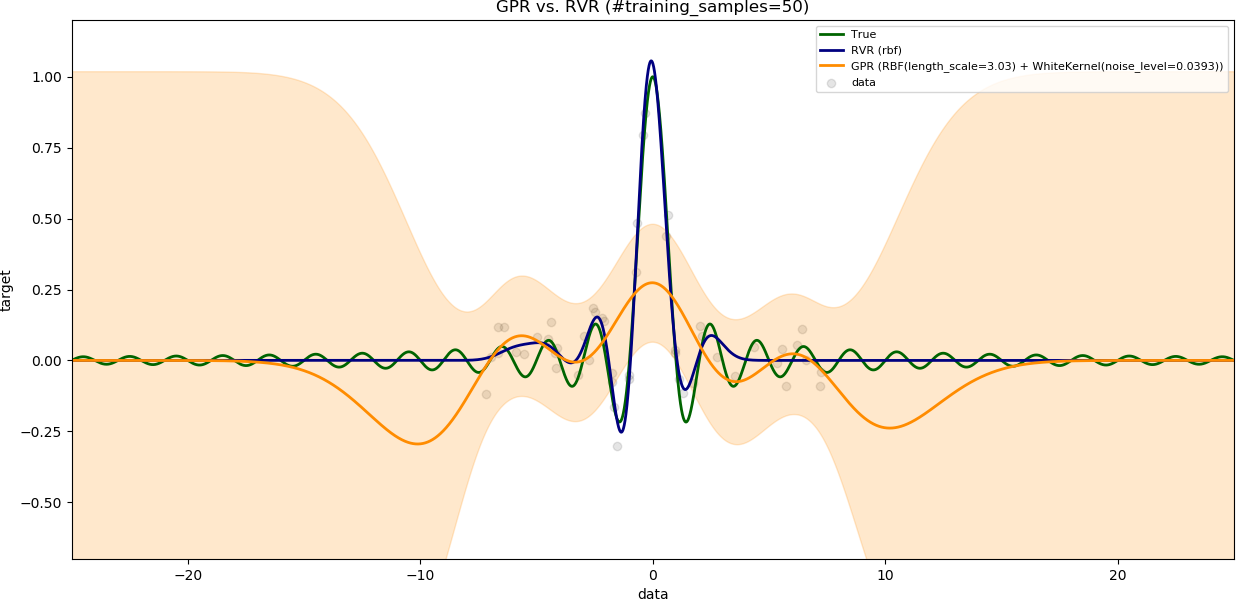
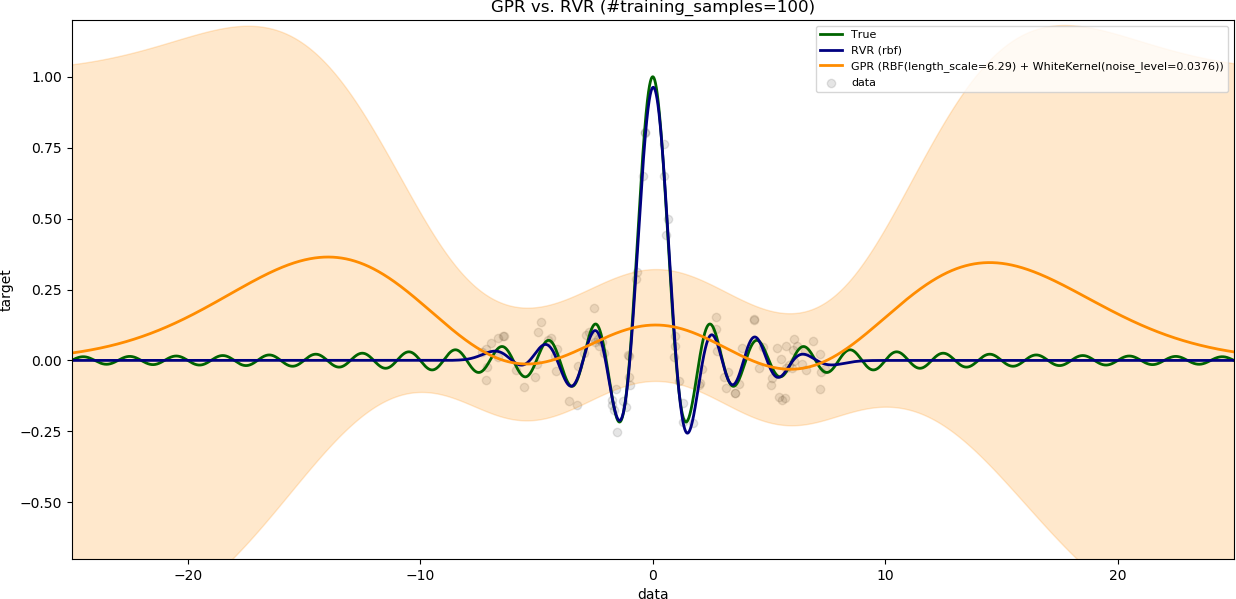
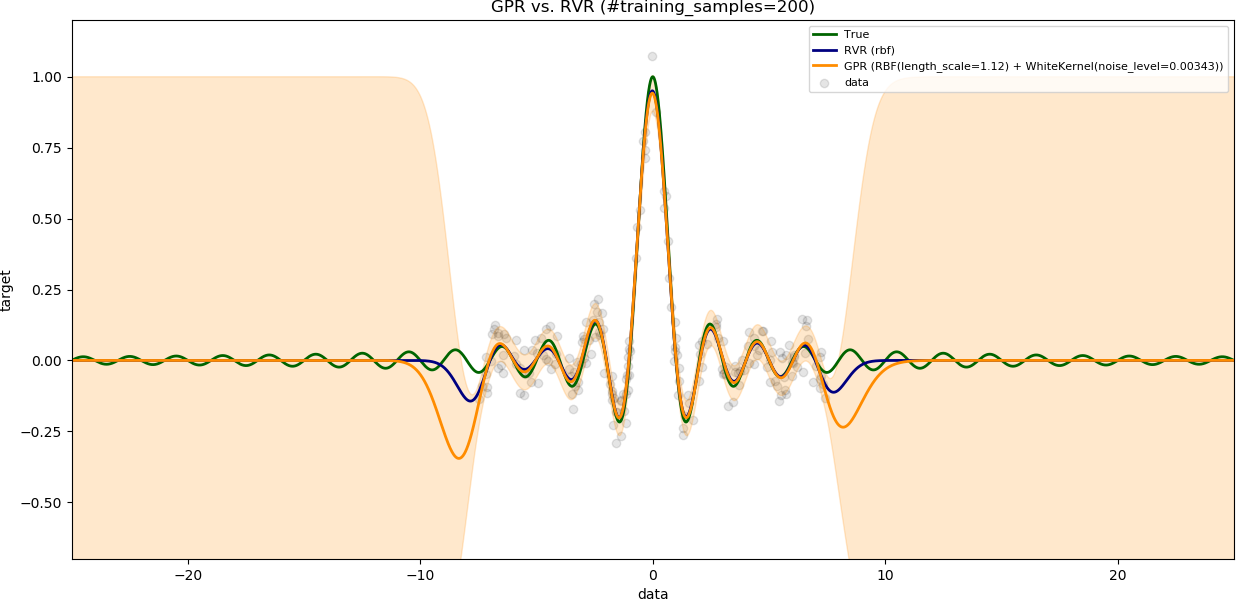
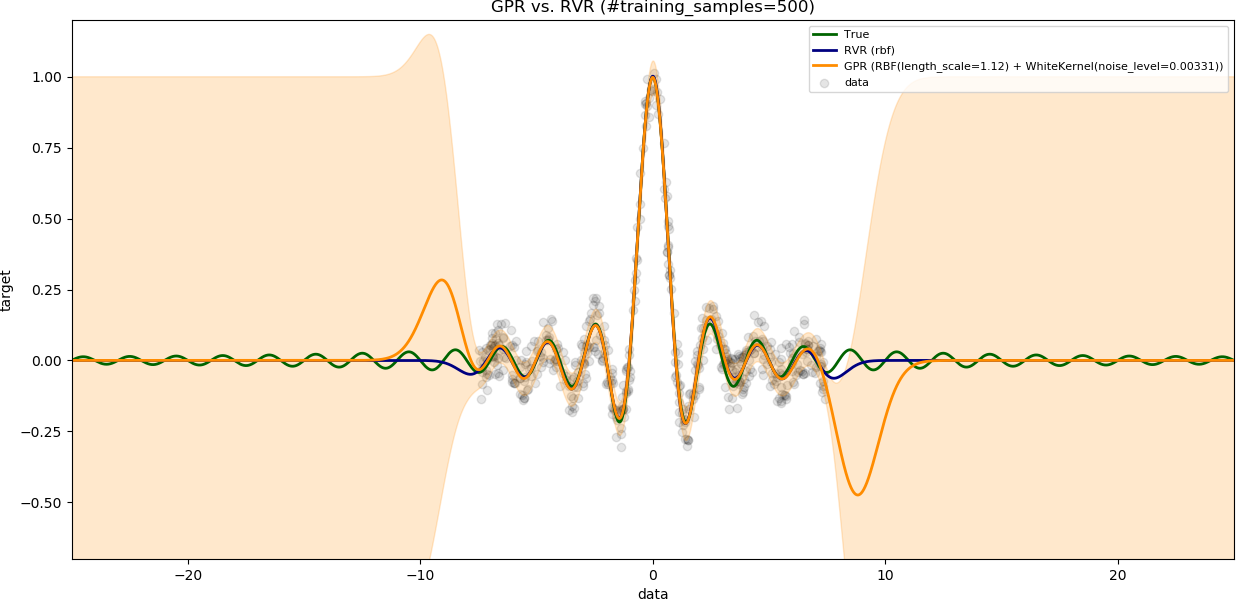
### Influence of the number of training samples
The variable `noise_level` is set to `0.1`.
The variable `training_data_range` is set to a large value (`15`).
The results are shown with increasing number of training samples.
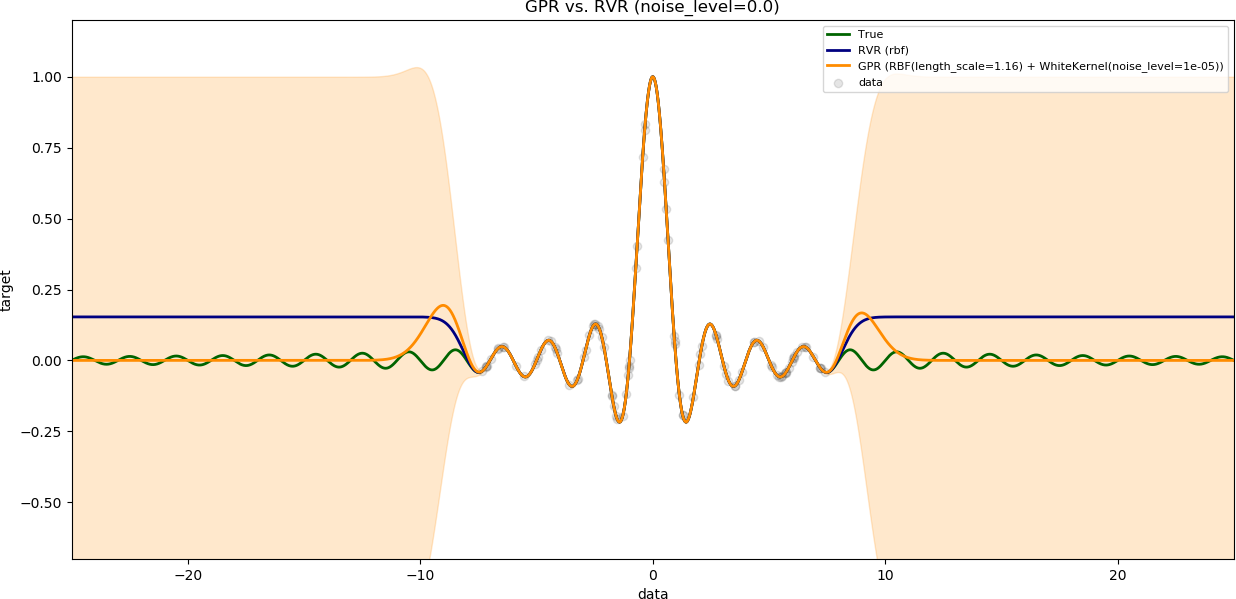
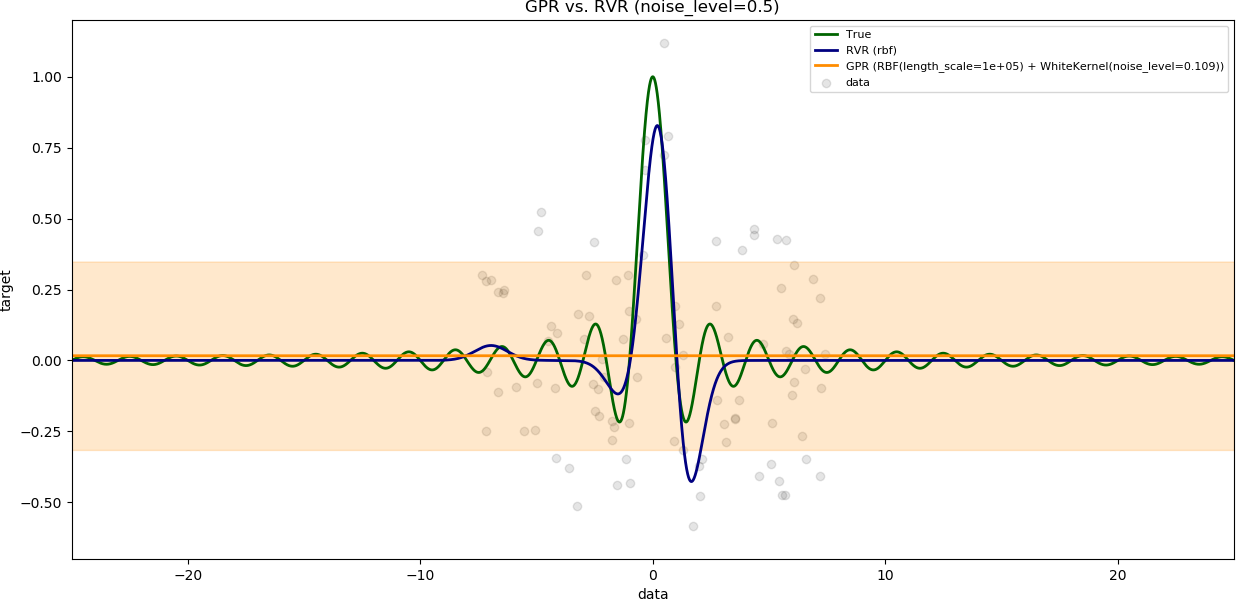
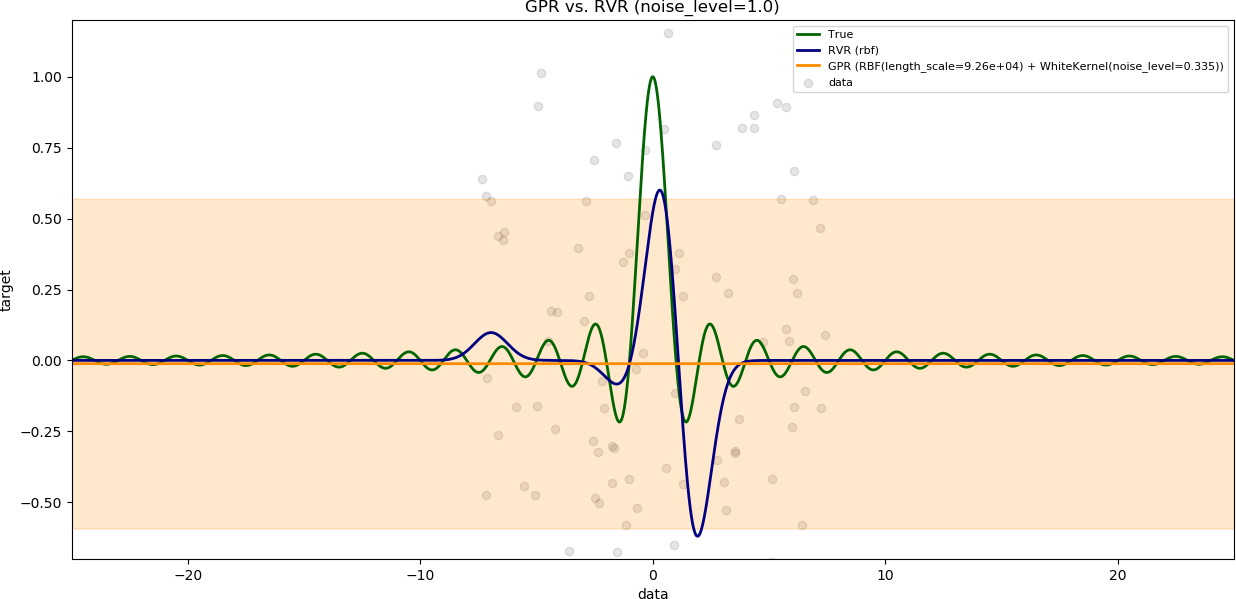
### Influence of the noise level
The variable `num_samples` is set to `100`.
The variable `training_data_range` is set to a large value (`15`).
The results are shown with increasing noise level.

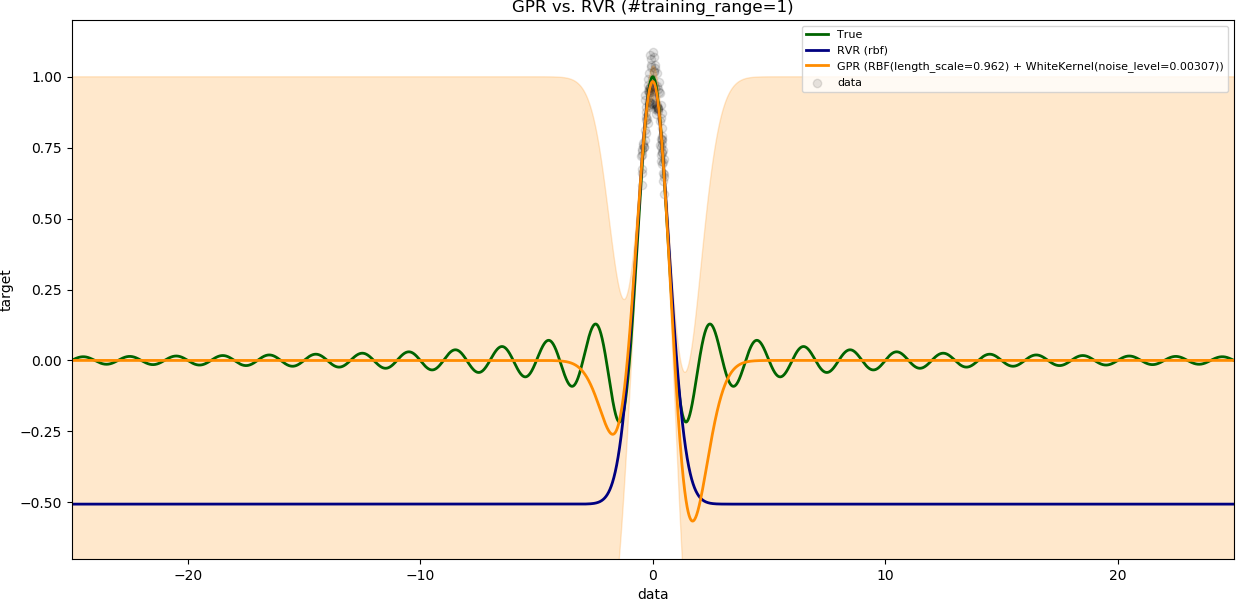
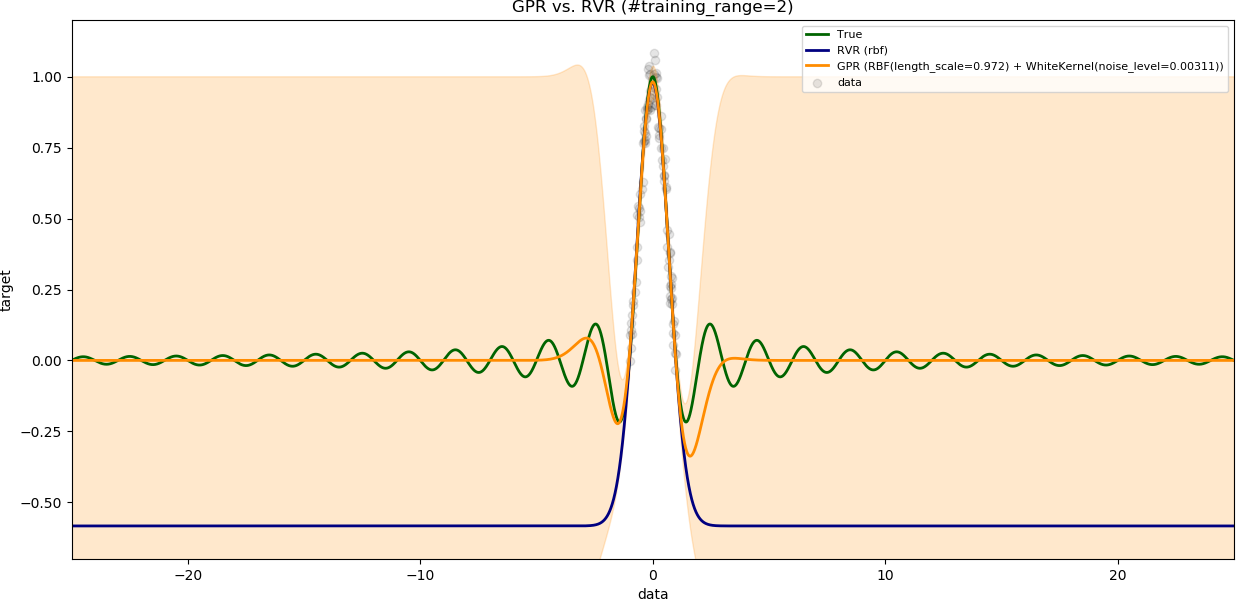
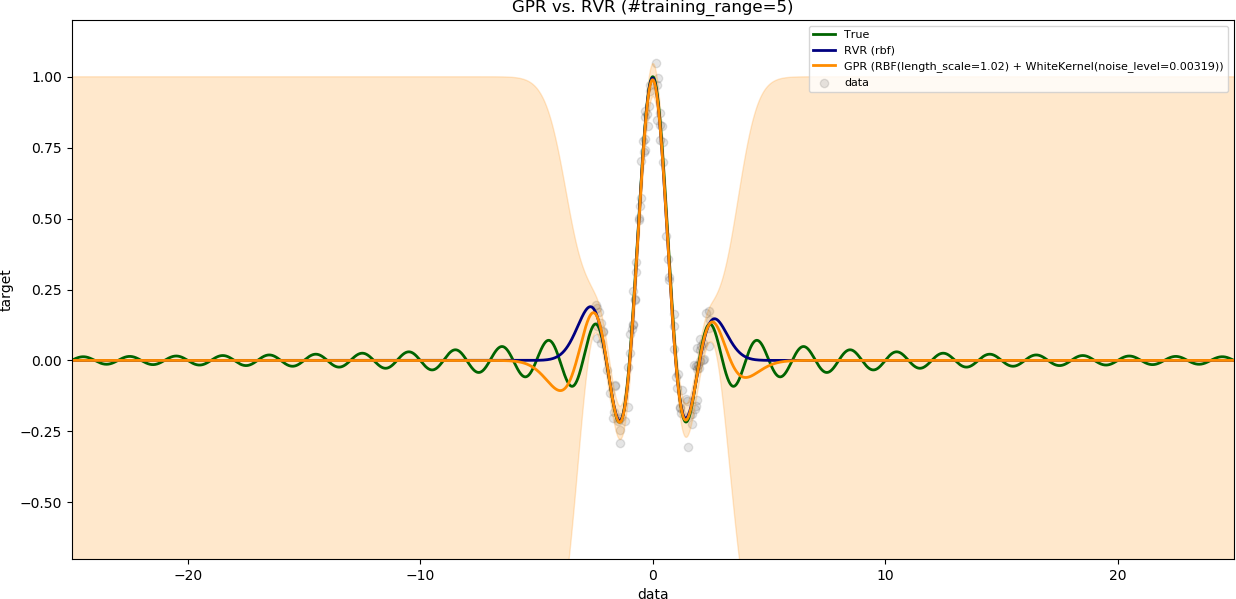
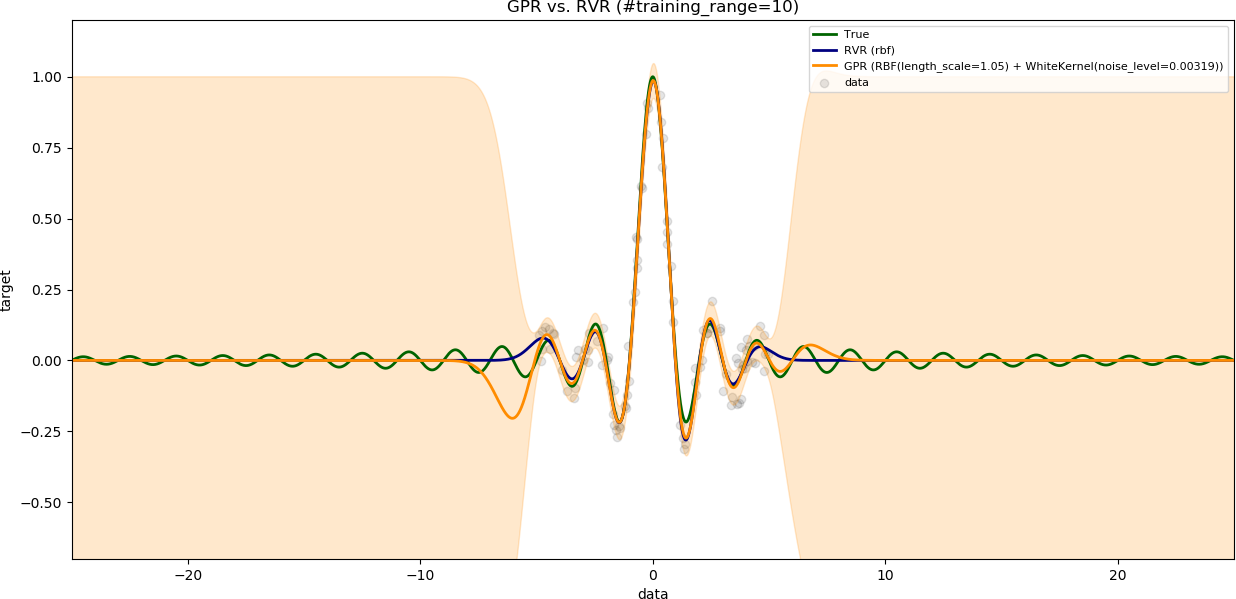
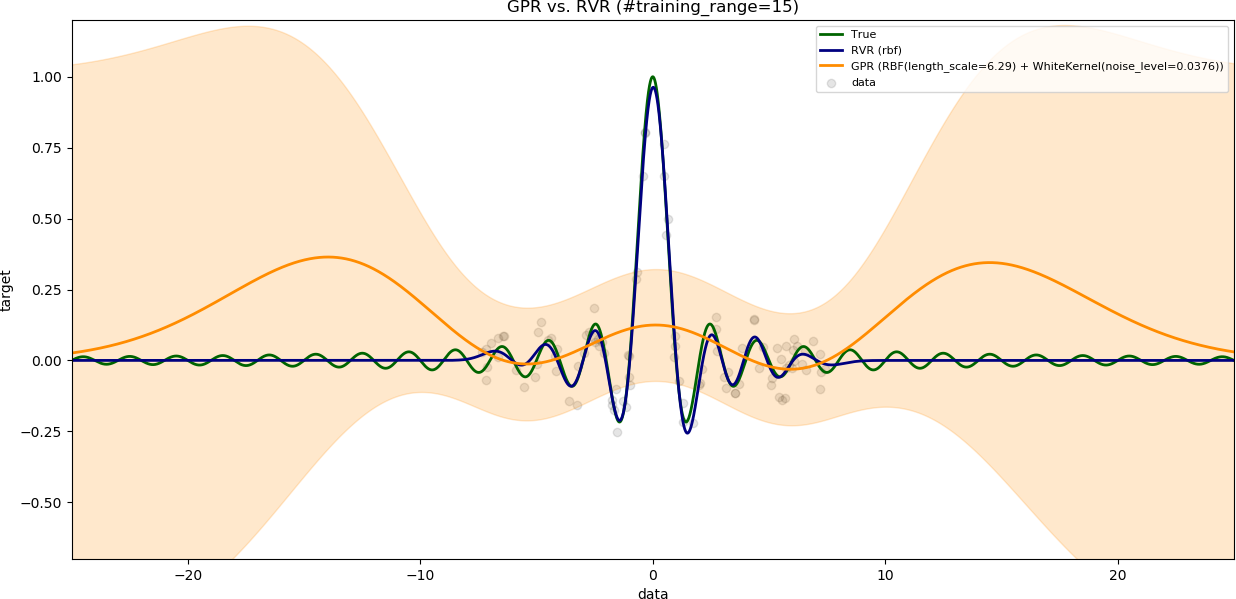
### Influence of range of training data
The variable `num_samples` is set to `100`.
The variable `noise_level` is set to `0.1`.
The results are shown with increasing range of training data
## References
- Python module [scikit-learn](https://github.com/scikit-learn/scikit-learn)
- Documentation: [Gaussian Process](https://scikit-learn.org/stable/modules/gaussian_process.html) with scikit-learn
- Python module [scikit-rvm](https://github.com/JamesRitchie/scikit-rvm)
- Python module [sklearn-rvm](https://github.com/Mind-the-Pineapple/sklearn-rvm)
- Slides about [Relevance Vector Regression](http://lasa.epfl.ch/teaching/lectures/ML_MSc_Advanced/Slides/Lec_IX_NonlinearRegression_Part_I.pdf)
- Slides about [Gaussian Process Regression](http://lasa.epfl.ch/teaching/lectures/ML_MSc_Advanced/Slides/Lec_IX_NonlinearRegression_Part_II.pdf)
[pyup]:
[dependency-image]:
[python3-image]:
[codacy]:
[codacy-image]: