https://github.com/worldbank/llm4data
LLM4Data is a Python library designed to facilitate the application of large language models (LLMs) and artificial intelligence for development data and knowledge discovery.
https://github.com/worldbank/llm4data
ai data development-data gpt gpt-4 indicators llm llm4data metadata sql wdi world-development-indicators
Last synced: over 1 year ago
JSON representation
LLM4Data is a Python library designed to facilitate the application of large language models (LLMs) and artificial intelligence for development data and knowledge discovery.
- Host: GitHub
- URL: https://github.com/worldbank/llm4data
- Owner: worldbank
- License: other
- Created: 2023-05-23T19:28:48.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2024-12-02T23:32:04.000Z (over 1 year ago)
- Last Synced: 2025-03-31T07:08:16.760Z (over 1 year ago)
- Topics: ai, data, development-data, gpt, gpt-4, indicators, llm, llm4data, metadata, sql, wdi, world-development-indicators
- Language: Python
- Homepage: https://worldbank.github.io/llm4data/
- Size: 3.41 MB
- Stars: 57
- Watchers: 5
- Forks: 4
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Contributing: .github/CONTRIBUTING.md
- License: LICENSE
- Code of conduct: .github/CODE_OF_CONDUCT.md
Awesome Lists containing this project
README
# LLM4Data
LLM4Data is a Python library designed to facilitate the application of large language models (LLMs) and artificial intelligence for development data and knowledge discovery. It is intended to empower users and organizations to discover and interact with development data in innovative ways through natural language.
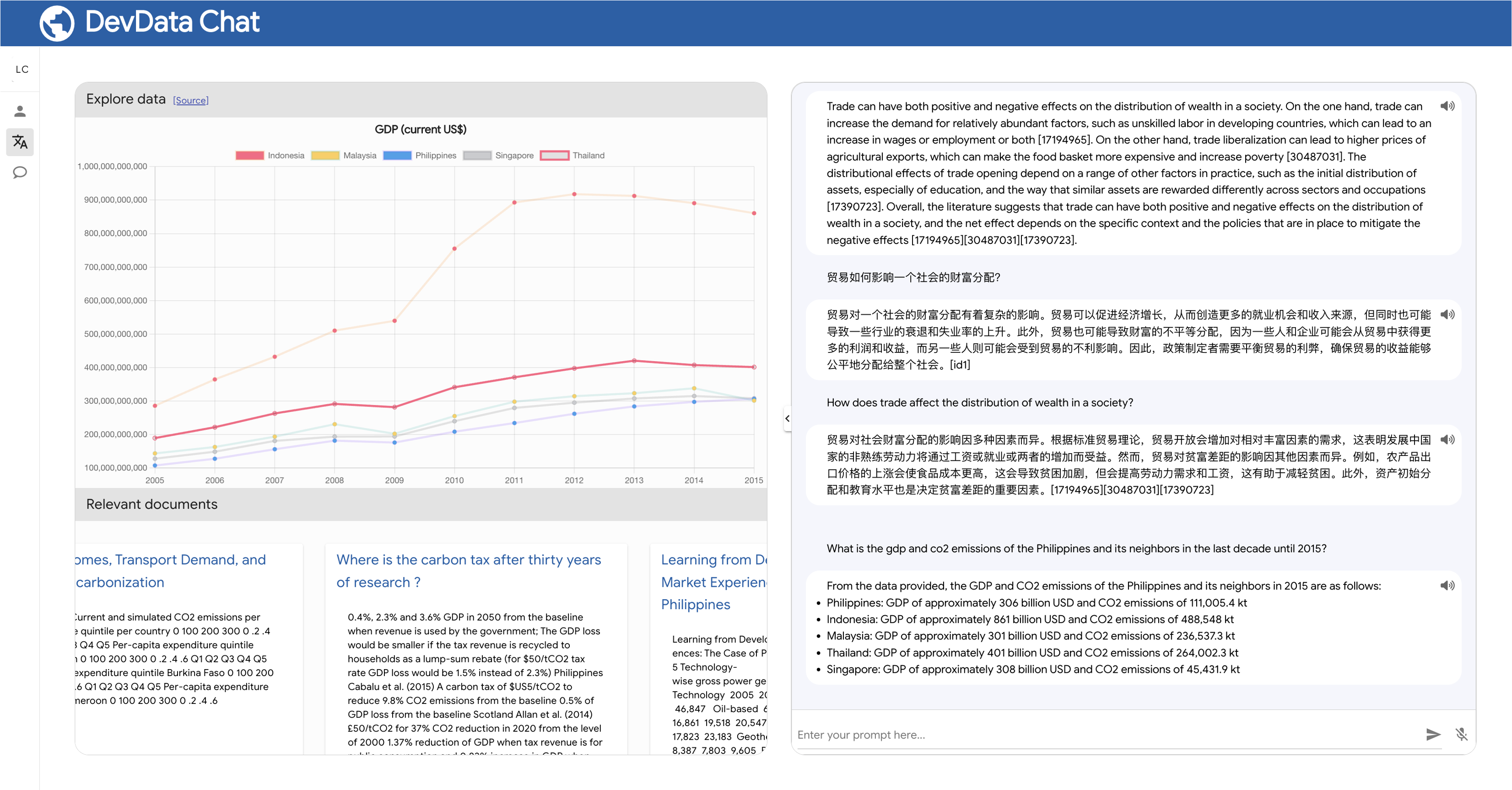
The LLM4Data powers the DevData Chat application, which will soon be available as an open-source project. This application demonstrates the various ways in which LLM (Language Model) and AI enhance discovery and interaction with data and knowledge, bringing innovative solutions to help address discoverability and accessibility gaps.
The LLM4Data library contains a collection of discovery and data augmentation solutions for various data types including documents, indicators, microdata, geospatial data, and more. The current version of the library includes solutions for the WDI indicators. Additional solutions will be added in [future releases](https://worldbank.github.io/llm4data/README.html#upcoming-features).
Built around existing [metadata standards and schemas](https://mah0001.github.io/schema-guide/), users and organizations can benefit from LLMs to enhance data-driven applications, enabling natural language processing, text generation, and more with LLM4Data. The library serves as a bridge between LLMs and development data using open-sourced libraries, offering a seamless interface to leverage the capabilities of these powerful language models.
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install LLM4Data.
```bash
pip install llm4data
```
## Usage
The following examples demonstrate how to use LLM4Data to generate WDI API URLs and SQL queries from prompts.
Additional examples can be found [here](notebooks/examples/).
### Generate WDI API URL from a prompt
```{warning}
This example uses the OpenAI API. Before you proceed, make sure to set your API keys in the `.env` file. See the [setup instructions](https://worldbank.github.io/llm4data/notebooks/examples/getting-started/openai-api.html) for more details.
```
```python
from llm4data.prompts.indicators import wdi
# Create a WDI API prompt object
wdi_api = wdi.WDIAPIPrompt()
# Send a prompt to the LLM to get a WDI API URL relevant to the prompt
response = wdi_api.send_prompt(
"What is the gdp and the co2 emissions of the philippines and its neighbors in the last decade?"
)
# Parse the response to get the WDI API URL
wdi_api_url = wdi_api.parse_response(response)
print(wdi_api_url)
```
The output will look like the following:
```
https://api.worldbank.org/v2/country/PHL;IDN;MYS;SGP;THA;VNM/indicator/NY.GDP.MKTP.CD;EN.ATM.CO2E.KT?date=2013:2022&format=json&source=2
```
Notice that the URL generated already includes the country codes and indicators relevant to the prompt. It understands which countries are the neighbors of the Philippines. It also understands which indicator codes are likely to provide the relevant data for GDP and CO2 emissions.
The URL also includes the date range, format, and source of the data. The user can then tweak the URL as needed, and use it to query the WDI API.
### Generate SQL queries on WDI data from a prompt
```{warning}
Make sure you have set up your environment first. The example below requires a working database engine, e.g., postgresql. If you want to use SQLite, make sure to update the `.env` file and set the environment variables.
```
While the WDI data can be loaded into a Pandas dataframe, it is not always practical to do so; for example, developing applications that can answer arbitrary data questions.
The LLM4Data library includes an SQL interface to WDI data, allowing users to query the data using SQL.
This interface will allow users to query the data using SQL, and return the results as a Pandas dataframe. The interface also allows users to query the data using SQL, and return the results as a JSON object.
```python
import json
from llm4data.prompts.indicators import templates, wdi
from llm4data.llm.indicators import wdi_sql
prompt = "What is the GDP and army spending of the Philippines in 2020?"
sql_data = wdi_sql.WDISQL().llm2sql_answer(prompt, as_dict=True)
print(sql_data)
# # {'sql': "SELECT country, value AS gdp, (SELECT value FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'MS.MIL.XPND.GD.ZS' AND year = 2020) AS army_spending FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'NY.GDP.MKTP.CD' AND year = 2020 AND value IS NOT NULL",
# # 'params': {},
# # 'data': {'data': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}],
# # 'sample': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}]},
# # 'num_samples': 20}
```
### Generate a narrative explanation of the SQL query response
The LLM4Data library also includes support for generating narrative explanations of SQL query responses. This is useful for generating natural language descriptions of data, which can be used to provide context to users and to explain the results of data queries.
```python
from llm4data.prompts.indicators import templates
# Send the prompt to the LLM for a narrative explanation of the response.
# This is optional and can be skipped.
# Note that we pass only a sample in the `context_data`.
# This could limit the quality of the response.
# This is a limitation of the current version of the LLM which is constrained by the context length and cost.
explainer = templates.IndicatorPrompt()
description = explainer.send_prompt(prompt=prompt, context_data=json.dumps(sql_data["data"]["sample"]))
print(description["content"])
# # Based on the data provided, the GDP of the Philippines in 2020 was approximately 362 billion USD. Meanwhile, the country's army spending in the same year was around 1.01 billion USD. It is worth noting that while army spending is an important aspect of a country's budget, it is not the only factor that contributes to its economic growth and development. Other factors such as infrastructure, education, and healthcare also play a crucial role in shaping a country's economy.
```
### Why not use Langchain for SQL queries?
Langchain is a great library and it has a wrapper for SQL databases that allows you to query them using natural language. The wrapper is called `SQLDatabaseChain` and can be used as follows:
```python
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
db = SQLDatabase.from_uri("sqlite:///../llm4dev/data/sqldb/wdi.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True, return_intermediate_steps=True)
out = db_chain("What is the GDP and army spending of the Philippines in 2020?")
```
```bash
> Entering new SQLDatabaseChain chain...
What is the GDP and army spending of the Philippines in 2020?
SQLQuery:SELECT "value" FROM wdi WHERE "name" = 'GDP (current US$)' AND "country_iso3" = 'PHL' AND "year" = 2020
UNION
SELECT "value" FROM wdi WHERE "name" = 'Military expenditure (% of GDP)' AND "country_iso3" = 'PHL' AND "year" = 2020
SQLResult: [(1.01242392260698,), (361751116292.541,)]
Answer:The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541.
> Finished chain.
```
Unfortunately, the answer `The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541.` is incorrect because the values have been swapped.
One of the goals of LLM4Data is to develop solutions around the limitations of existing open-source solutions as applied to development data and knowledge discovery.
## Key Features and Roadmap
- Text generation: Utilize LLMs to generate coherent and contextually relevant text around development data, enabling the creation of chatbots and content generation systems.
- Interactive experiences: Create engaging user experiences by integrating LLMs into applications, allowing users to interact with development data in a more intuitive and conversational manner.
- Metadata augmentation: Enhance existing metadata with LLMs, enabling the creation of new metadata and the improvement of existing metadata.
- AI-powered insights: Extract valuable insights from datasets using LLMs, empowering data exploration, trend analysis, and knowledge discovery.
- Dynamic integration: Through the use of metadata standards and schemas, load and utilize your own Python scripts containing LLM functionality on-the-fly, seamlessly incorporating them into your project through plug-ins.
- Natural language processing: Leverage LLMs to analyze and process textual data, enabling tasks like sentiment analysis, text classification, and language translation.
## Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please see [CONTRIBUTING.md](.github/CONTRIBUTING.md) for more information.
## License
LLM4Data is licensed under the [ World Bank Master Community License Agreement](LICENSE).
## Upcoming Features
- [ ] Metadata augmentation with LLM
- [ ] Document and metadata indexing
- [ ] Semantic search:
- [ ] For indicators
- [ ] For documents
- [ ] For microdata
- [ ] For geospatial data
- [ ] For voice and videos
- [ ] Open-source chat UI
- [ ] Data use framework
## TODO
- [ ] Add contributing guidelines
- [ ] Add more documentations
- [ ] Add unit tests
- [ ] Add CI/CD