https://github.com/wowinter13/real_life_interview
Some questions from real life interviews. Ruby/Rails, Golang and other backend nuances.
https://github.com/wowinter13/real_life_interview
interview ruby sql-queries
Last synced: 9 months ago
JSON representation
Some questions from real life interviews. Ruby/Rails, Golang and other backend nuances.
- Host: GitHub
- URL: https://github.com/wowinter13/real_life_interview
- Owner: wowinter13
- Created: 2018-08-05T13:15:03.000Z (almost 8 years ago)
- Default Branch: master
- Last Pushed: 2023-10-04T15:32:50.000Z (almost 3 years ago)
- Last Synced: 2024-12-26T18:46:57.234Z (over 1 year ago)
- Topics: interview, ruby, sql-queries
- Homepage:
- Size: 641 KB
- Stars: 4
- Watchers: 4
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Technical Interview Cheat Sheet
A collection of questions from different technical interviews.
***
## Contributing
This is an open source, community project, and I am grateful for all the help I can get. If you find a mistake make a PR and please have a source so I can confirm the correction. If you have any suggestions feel free to open an issue.
***
# Table of Content
- [Computer Science](cs.md)
- [Databases](db.md)
- [DB Assessments](sql_assessments.md)
- [Architecture/Systems Design](arch.md)
- [Ruby & Rails](ruby.md)
- [Ruby Assessments](ruby_assessments.md)
- [Golang](golang.md)
- [Go Assessments](go_assessments.md)
***
### Concurrency and Parallelism
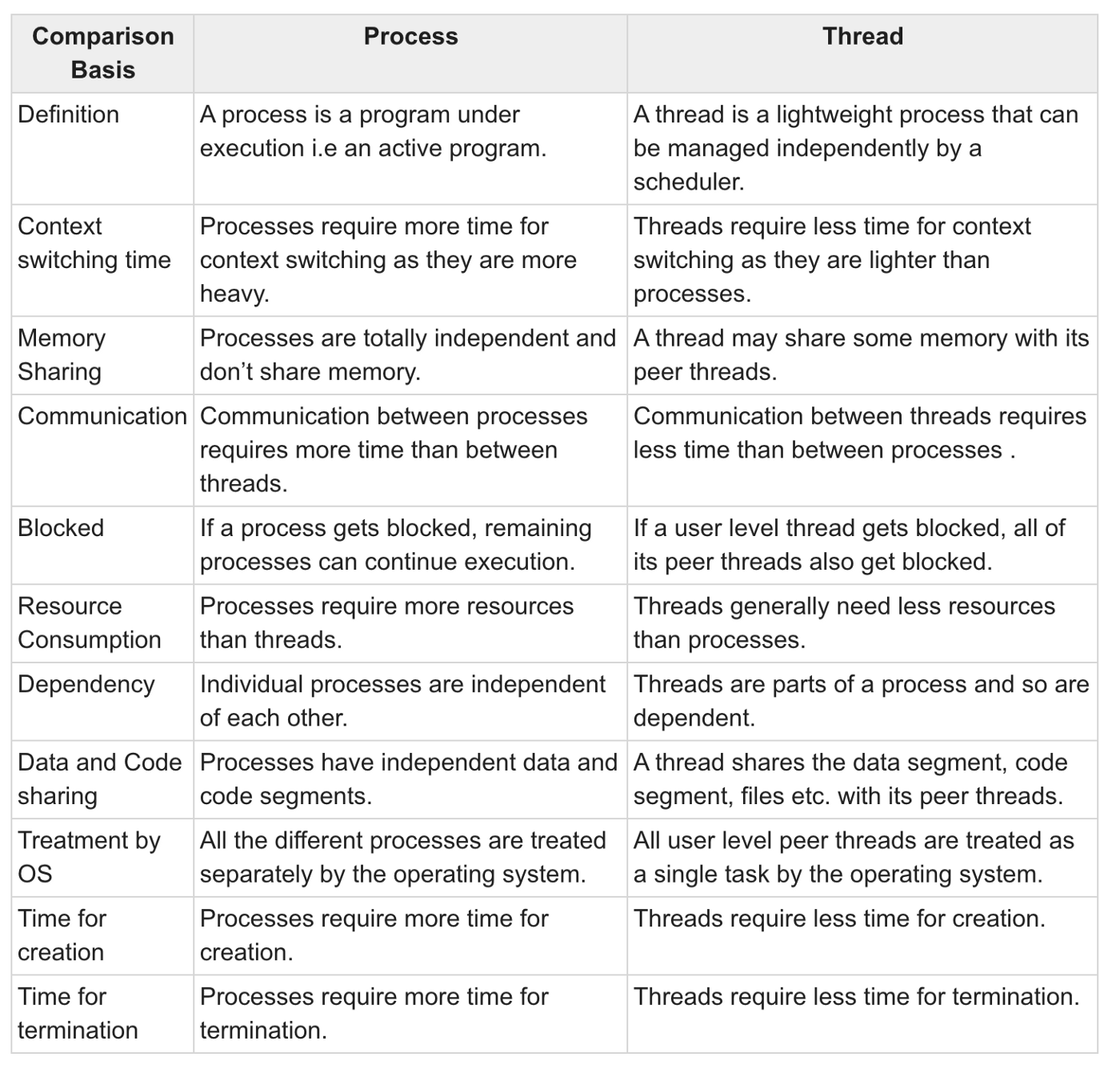
#### 1. Threads vs Processes
***
**Распределенные системы**
1. Replication
хранение копий одних и тех же данных на нескольких машинах, i.e. дубликация
Решает проблему географии (когда пользователи разбросаны по миру), проблему отказа одной из систем (высокая доступность) и простое горизонтальное масштабирование (обработка большего количества запросов).
Сложность репликации – изменение данных на всех узлах.
По типам разделяют репликацию с одним ведущим узлом (single leader), с несколькими ведущими узлами (multi-leader) и без ведущего узла (leaderless).
Те узлы, которые хранят копии называются реплики.
Базовый вариант реализации master/slave (leader-based replication). Лидер узла отвечает за запись данных в свое локальное хранилище, а затем используя журнал репликации (replication log) рассылает все обновления в ведомые узлы (followers). Данная реализация доступна во всех современных БД и некоторых брокерах сообщений.
По типам выполнения разделяют синхронную, асинхронную и полусинхронную репликацию.
Синхронная репликация обеспечивает гарантии актуальных данных между узлами, но в некоторых случаях операция записи может занимать долгое время. Проблема может возникнуть, если follower реплика не отвечает и произойдет rollback на ведущей реплике.
Чаще используют semi-синхронную репликацию, в данном случае синхронное обновление происходит только на одном ведущем и ведомом узле.
В случае отказа ведомого узла, проблема не возникает – ведущий узел хранит лог изменений и воспроизведет его при рестарте. В случае отказа ведущего узла, можно временно можно назначить ведомый узел в качестве ведущего.
Репликацию с несколькими ведущими узлами используют в развертывании систем, расположенных в нескольких ЦОДах.
В postgres это BDR (bi-directional replication). Чаще всего конфликты между асинхронными записями решаются алгоритмом LWW (last write wins).
Без ведущего узла – экспериментальный вариант, используется в Dynamo-подобных системах. Запросы падают сразу на все узлы.
2. Партицирование (шардирование, секционирование)
Секционирование это разбиение базы на отдельные кусочки. Снова же основная цель партицирования – масштабируемость системы, применяется когда набор данных настолько велик, что репликации становится недостаточно. Основная идея заключается в том, что при партицировании не используется разделение ресурсов.
Цель секционирования — равномерно распределить по узлам данные и загрузку по запросам. В случае если нагрузка распределена неравномерно, секционирование называют ассиметричным (skewed), а секцию с максимальной нагрузкой называют hot spot. Партицирование может быть как и автоматическим (по хеш-ключу), так и ручным. Ручное устанавливается по каким-либо диапазонным значениям. Для распределения запросов используется балансировщик нагрузок.
Индексы также требуется секционировать – локальные в рамках секции и глобальные между секциями.
**В случае postgresql часто используется связка partman/pg_cron для автоматического партицирования данных в какой-то период. (PARTITION BY)**
3. Как достигается консенсус в распределенных системах?
Используется алгоритм двухфазной фиксации (**2PC, two phase commit**). Этот алгоритм гарантирует, что все узлы либо зафиксировали транзакцию, либо прервали ее. Для этого используется диспетчер транзакций.
3. Stateful and stateless applications.
**Types of indexes**
1. Hash-indexes (key-value)
Used for columns containing unique data.
A hash index stores keys by dividing them into smaller buckets, where each bucket is given an integer ID-number to retrieve it quickly when searching for a key’s location in the hash table. The buckets are stored sequentially on a disk. Fast read, cheap storage. But it is impossible to store duplicate keys within a bucket.
2. LSM-tree (Log-Structured Merge-Tree)
3. B-trees (balanced tree)
The most popular index type.
Balanced tree is balanced because compared to hash or log-strucured indexes, B-trees always split keys by dividing them into chunks (page) with a fixed size (about 4Kb). Each page has a pointer (link) on the disk, and can be a reference to another one page. The links count for child elements called is called branching factor (for the sake of simplicity, depth).
**ACID**
ACID – atomacity, consistency, isolation, durability (атомарность, консистентность, изоляция, сохраняемость).
**А**томарность – прерываемость. Возможность прервать транзакцию при ошибке. Принцип "Все или ничего".
**C**onsistency – гарантия целостности данных. Можно сказать что если транзакция начинается при допустимом состоянии базы данных, то можно быть уверенным, что и после состояние БД будет соответствовать изначальным инвариантам (изначальным утверждениям).
**I**solation – гарантирует, что конкурентные операции изолированы друг от друга.
**D**urability – гарантирует, что данные не будут потеряны после успешно зафиксированных операций даже в случае сбоя самой БД.
**CAP теорема**
CAP – consistency, availability, partition tolerance (2/3).
**C**onsistency – согласованность.
**A**vailability – доступность.
**P**artition tolerance – устойчивость к нарушениям связности.
Теорема вызывает большего вопросов, чем ответов, тк даже самые современные и устойчивые системы не могут гарантировать соответствие условиям теоремы.
Говоря про согласованность, она нарушается уже при использовании многоядерных процессоров, если поток на одном ядре пишет в ячейку, а поток на другом читает – без использования барьеров памяти ошибка может возникнуть уже на таком уровне.
Доступность может быть "гарантирована" с помощью использования систем репликации и партиционирования, но при этом увеличивая вероятность нарушений связности.
#### 1. Do you know what is PGQ? Other queues in Postgres?
#### 2. Postgres. Indexes.
По типам индексов, их там в PG штук 5, но я лично сталкивался в миграциях только с btree и ginом.
btree это дефолтный индекс – balanced дерево. Получается работает как придавленное нормальное распределение, то есть, у нас очень ветвистое дерево, весь кайф в балансе, то есть глубина на всех участках одинаковая. Собственно по понятным причинам подходит для сортируемых данных.
gin - это базовый обратный индекc, там концепция обратная – мы храним не значения по индексам, а индексы по значениям.
Еще там есть Brin, как Сергей Брин, но индекс, Gist, хеш-индексы, но детали не изучал ибо не использовал осознанно.
#### 1. What are types of NoSQL databases?
graph stores, key-value stores, document stores, column stores.
***
### DB Questions
**What is N+1 query?**
The N+1 query is a query, when we do a one more query for a child-record each time iterating throught parent-records.
The main problem is a reduced performance.
**Basic SQL Clauses**
- HAVING
- GROUP
**Join types:**
- INNER
- OUTER
- LEFT RIGHT
- FULL
**Why do we need a transaction when getting data from the database?**
Транзакции обеспечивают гарантии функциональной безопасности. Упрощают обработку ошибок конкурентного доступа.
В случае состояния гонки это позволить сделать `LOCK` базы для получения ожидаемого результата.
Если более точно, то существует 4 уровня изоляции данных. По дефолту в PG используется `read commited`, который читает записи закомиченные до исполнения запроса. Транзакция позволяет исполнять запрос в рамках одного соединения и получать корректные данные на выходе.
**Что такое индекс, когда добавляют в базу и зачем они нужны**
Индекс — дополнительная структура, производная от основных данных.
Индекс это обмен памяти на скорость, и базе данных вместо того чтобы использовать полнотекстный поиск достаточно пройтись по индексу, это будет значительно быстрее.
Индексы влияют на скорость апдейта и инсерта, потому что при каждом изменение таблицы нужно перестраивать индекс.
**Как устроен btree и как функция защищает от коллизий**
**What is pgBouncer? When should we use it?**
Надстройка управляющая пулом соединений к Postgresql. Создает сеансы(сессии) для пользователей бд в рамках пула открытых соединений, что позволяет не открывать новое соединение для каждого из новых пользователей.
Использовать имеет смысл, когда база упирается в высокое количество клиентских соединений из-за чего транзакция занимает миллисекунды, но создание соединения секунды.
**Postgres replication (like: master-slave)**
**Базовые уровни изоляции транзакций**
- `Read Commited`
Default reading mode. Гарантирует, что любые закомиченные данные будут прочитаны. Вызывает lock на запись в таблице -> ставит в очередь другие транзакции. Запрещает Dirty Read. Обычно реализуется через блокировку транзакцией записи до модификации значения.
- `Read Uncommitted`
Разрешает Dirty Read. Самый низкий уровень изоляции. Позволяет читать еще не закомиченные данные. Транзакции не изолированы друг от друга.
- `Repeatable Read`
Транзакция вызывает lock на все записи на чтение и обновление в таблице, тк другие транзакции не имеют доступ к данным -> исключается аномалия `Non Repeatable read` (когда при двойном прочтении транзакция получает разный результат)
- `Serializable`
Доступ, используемый в программах для создания дампов БД. Максимальный уровень изоляции транзакций. Граф сериализации выполняется последовательно -> становятся недопустимы любые аномалии данных. Последовательное исполнение транзакций.
***
### Theoretical questions
**Кому принадлежат методы объекта класса**
Они принадлежат все равно классу, потому что хранятся в его структуре.
**3 принципа ООП:**
**How incapsulation works in Ruby?**
**5 principles SOLID:**
*SOLID is an acronym for 5 basic OOP principles based on making the code more understandable, flexible and maintainable.*
- **S(ingle resposibility)**
One class should have only one responsibility.
- **O(pen-closed)**
Class should be open for extension, but closed for modification.
- **L(iskov substitution)**
All subtype class instances should not break the behavior of the original ancestor class, so they can be substituted.
- **I(nterface segregation)**
Many interfaces of special usage (client-specific) are better than one universal and abstract interface.
- **D(ependency inversion)**
Abstractions should not depend on details. Details should depend on abstractions.
**Cвязность и что это означает**
*Классы должны как можно меньше знать друг о друге.*
***
### Practical questions
**What is the difference between Proc and Lambda?**
Proc - это объект. Прок не проверяет количество аргументов, а лямбда проверяет. Ну и return разный, лямбда возвращает результат как метод, а proc результат выполнения.
**What is Mixin?**
**Multiple inheritance in Ruby**
**The most known/used metaprogramming example in Ruby**
*attr_accessor, attr_reader, attr_writer*
**What are unit tests? And when do we use them?**
**Where should we store the business logic?(fat models/fat controllers)**
*Better to use some basic patterns like: interactors, services or operations, and to store it here.*
**Basic Ruby/Rails patterns:**
- Interactor
- FormObject
- ServiceObject
**What is MVC**
## Server-side questions
**Чем отличается puma от unicorn?**
**Fork/Thread. Что это и в чем разница?**
`Поток` создается в рамках одного процесса (параллелизм). `Форк` это создание новой отдельной копии процесса.
Потоки расходуют меньше памяти тк не создается новый инстанс задачи.
Но форки процесса наследуют ресурсы родителя, в том числе и коннекшены к базе данных.
Поэтому внутри каждого форка нужно заново переоткрывать соединение к БД.
Используя `MRI` лучше форкать, `jruby` - создавать треды, тк MRI запускает только 1 поток в моменте.
**Зачем нужен NGINX?**
Nginx - веб-сервер. Puma или Unicorn - application-сервер.
В NGINX'е есть базовая защита от DDOS'а.
Он лучше обрабатывает multipart-загрузку файлов.
Служит для обработки статики и ассетов.
Редирект.
**Static File Serving**: Nginx excels at serving static files directly. This allows you to offload serving static files (CSS, JavaScript, images, etc.) from your Ruby application server (like Puma) to Nginx, thus freeing up Puma to focus on serving dynamic content. This can lead to a more responsive application and better use of server resources.
**Load Balancing:** Nginx can be used as a reverse proxy and a load balancer.
**Caching**
**Rate Limiting and Security**: Nginx can perform rate limiting.
**Как работает loadbalancer**
### Concurrency and Parallelism
#### GIL. Threads.
GIL (global interpretation lock) is a thread synchronization mechanism used in Ruby that helps to avoid data conflicts when more than 1 thread is accessing the same area of memory.
And threads are used to parellelize computations. Threads are placed in a special context and can share the same memory.
### Ancient Magic (Ruby under a Microscope)
**Ruby Garbage Collector**
GC collects all unused objects and frees memory of them. Basically, GC will delete object, if there are no more calls to it in the program.
## Patterns
**Form object**
Не паттерн, а подход к обработке данных (по сути это замена permitted_params).
Получаем возможность препроцессить данные, валидировать их (dry-struct, dry-types, dry-validations).
**Decorator**
Декорирует только один объект (добавляет некоторую функциональность) (draper)
**Presenter**
Тоже декоратор, но уже максимально приближенный к вьюхам.
**Policies**
Не назвал бы паттерном, просто подход к делегированию информации и доступов (pundit).
**Serializers**
Способ нормализовать данные и стандартизировать API. (json serializer)
**Interactor, Service object**
Инкапсулирует часть бизнес логики (Command паттерн) (dry-transaction (чейнит шагами) -> Interactor::Organizer + Interactor).
**The difference between Presenter & Decorator**
На каждом проекте по разному делают в итоге. Но однозначно говоря - декоратор добавляет функциональность объекта. А презентер это сервис который подготавливает информацию к отображению (например обработка коллекции из сущностей с информацией из связей). Декоратор - это общее решение: вроде универсального форматирования. А презентер используется для какого-то узкого назначения.
### Concurrency and Parallelism
#### 1. Mutex & RWMutex. What is the difference between them?
#### What is the difference between `let`, `const` and `var` in JS.
#### How does OOP implemented in vanilla JS?
#### In cookie-based session management, who sets the session token?
// to sort
#### Why gRPC is better than our lovely REST? Why gRPC is a perfect choice for microservices? Do you know any useful features?
gRPC is a perfect choice for microservices simply because of being lightweight and fast. Talking about the advantages:
1. Metadata. Instead of using HTTP requests. Metadata is much simplier and perfectly fits for internal communication.
2. Streaming (thanks to HTTP 2.0). gRPC provides all streaming types (client, server, bidirectional).
3. Interceptors. The way gRPC allows you to modify and change requests/responses right out of the box. (read: middlewares)
4. Load Balancing.
5. Call Cancellation. You can simply kill a gRPC call if you don't need a response anymore.
#### RabbitMQ Clustering?
#### Quorum queues
#### PG: express index. Which index should be used for hashes and nested hashes.
#### 3. Garbage Collector в руби.
GC собирает неиспользуемые объекты и освобождает память от них. GC удаляет объект, если в программе больше нет его вызовов.
#### 4. include, extend, prepend
include - подгружает методы инстанса
extend - подгружает методы класса
prepend - подгружает методы инстанса ниже всего по ast дереву, то есть они самые первые
#### 5. Сложность поиска по ключу в хеше:
O(1), O константы
#### 6. коллизии в хешах
ситуация когда несколько ключей содержат одно значение, и получается что так как хеш это массив содержащий связанный списки, то получается что у нас образуется цепочка длинной больше чем 1. Я детали не изучал, знаю что руби справляется с этим через чейнинг, поэтому сложность если и увеличивается то в рамках адекватного.
#### 1. TCP vs UDP
TCP считает пакет потерянным после отсутствия ответа по истечении некоторого времени ожидания и автоматически повторяет пересылку потерянных пакетов. Надежный, нацелен на доставку.
UDP имеет смысл выбирать в случаях, когда запоздавшие данные теряют всякую ценность. Потери пакетов уместны. Стриминг, видео звонки и тд.
// TO sort
Q1. Массив и хеш - отличия и сложность.
A1. По массиву, у нас для любых поисков и удалений O(1) константы, для поиска по значению O(n). Все просто: O(1), тк в этом мире все использует ссылки, назовем их поинтеры, то массив устроен так: выделяется место в памяти под массив, но каждый элемент выделен участок памяти конкретного размера, условно когда мы делаем метод index, то мы просто берем точку в памяти и умножаем индекс на количество выделенной памяти.
При операциях со значениями O(n), потому что надо пройтись по всему размеру. Адресная арифметика.
С хешом, та же кошка вид сзади. Ну то есть на практике там все-равно кажется две операции идет, но условно сложность как и в массивах. При работе с ключами O(1), со значениями O(n).Тут все просто, хеш на самом деле массив, который хранит в себе ссылки. Цель хеширования перегонка данных к фиксированному размеру ячейки.
Q2. Сложность разворота массива?
A2.
Q3. Как работает выделение памяти?
A3. На примере массива. Руби аллоцирует память для массива, он не учитывает конечную длину. А когда мы добавляем данные, то происходит перенос всего объекта памяти. Руби выделяет ячейку большего размера и переносит туда весь массив целиком.
Как решить проблему выделения памяти? Ну на самом деле на примере из Си и Гоу скажу, достаточно задать изначальную длину массива я так думаю.
Q4: Руби не типизирован, почему все работает эффективно ведь в массив можно кинуть какие угодно данные какого уугодно размера?
A4: Ну механизм ссылок-поинтеров, как раньше уже упомянал, мы храним только ссылки на объект.
По типам индексов, их там в PG штук 5, но я лично сталкивался в миграциях только с btree и ginом.
btree это дефолтный индекс – balanced дерево. Получается работает как придавленное нормальное распределение, то есть, у нас очень ветвистое дерево, весь кайф в балансе, то есть глубина на всех участках одинаковая. Собственно по понятным причинам подходит для сортируемых данных.
gin - это базовый обратный индекc, там концепция обратная – мы храним не значения по индексам, а индексы по значениям. В детали не углублялся это уже для любителей NLP и всяких векторных корпусов из слов и тд. Просто этот тип лучше подходит для текста. Еще там есть Brin, как Сергей Брин, но индекс, Gist, хеш-индексы, но детали не изучал ибо не использовал осознанно.
Виды серверов:
1. Puma, Unicorn, Nginx, Apache
Puma, Unicorn – это application сервера.
Nginx, Apache – это веб-сервер.
У них разное назначение, веб-сервер это вроде гейткипера, он обрабатывает загрузку файлов, обрабатывает статику, картинки, стили, ассеты. Еще выступает прослойкой от DDOS'а, условно чтоб не происходили нагрузки напрямую на app server. Еще nginx умеет в редирект. В общем, web-сервер стоит между клиентом и app сервером.
Разница пумы и юникорна – пума многопоточный, а юникорн держит в процессе один поток. Гитлаб недавно на пуму переезжал.