https://github.com/yahoo/halodb
A fast, log structured key-value store.
https://github.com/yahoo/halodb
big-data embedded-database java key-value-store storage-engine
Last synced: over 1 year ago
JSON representation
A fast, log structured key-value store.
- Host: GitHub
- URL: https://github.com/yahoo/halodb
- Owner: yahoo
- License: apache-2.0
- Created: 2018-06-18T18:46:19.000Z (about 8 years ago)
- Default Branch: master
- Last Pushed: 2023-04-26T15:56:57.000Z (about 3 years ago)
- Last Synced: 2025-03-28T18:16:02.632Z (over 1 year ago)
- Topics: big-data, embedded-database, java, key-value-store, storage-engine
- Language: Java
- Homepage: https://yahoodevelopers.tumblr.com/post/178250134648/introducing-halodb-a-fast-embedded-key-value
- Size: 563 KB
- Stars: 514
- Watchers: 25
- Forks: 100
- Open Issues: 30
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: Code-of-Conduct.md
Awesome Lists containing this project
README
# HaloDB
[](https://travis-ci.org/yahoo/HaloDB)
[ ](https://bintray.com/yahoo/maven/halodb/_latestVersion)
HaloDB is a fast and simple embedded key-value store written in Java. HaloDB is suitable for IO bound workloads, and is capable of handling high throughput reads and writes at submillisecond latencies.
HaloDB was written for a high-throughput, low latency distributed key-value database that powers multiple ad platforms at Yahoo, therefore all its design choices and optimizations were
primarily for this use case.
Basic design principles employed in HaloDB are not new. Refer to this [document](docs/WhyHaloDB.md) for more details about the motivation for HaloDB and its inspirations.
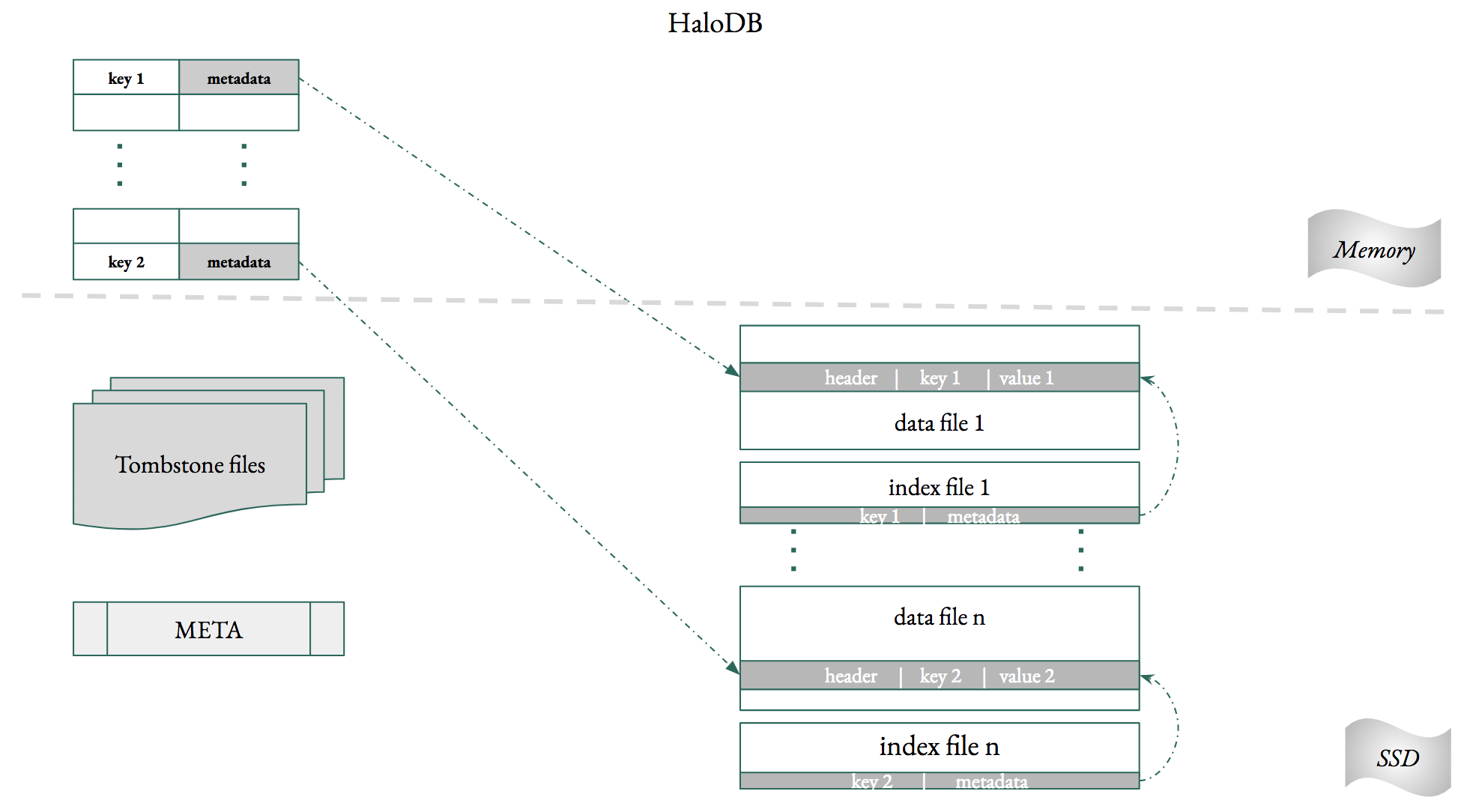
HaloDB comprises of two main components: an index in memory which stores all the keys, and append-only log files on
the persistent layer which stores all the data. To reduce Java garbage collection pressure the index
is allocated in native memory, outside the Java heap.
### Basic Operations.
```java
// Open a db with default options.
HaloDBOptions options = new HaloDBOptions();
// Size of each data file will be 1GB.
options.setMaxFileSize(1024 * 1024 * 1024);
// Size of each tombstone file will be 64MB
// Large file size mean less file count but will slow down db open time. But if set
// file size too small, it will result large amount of tombstone files under db folder
options.setMaxTombstoneFileSize(64 * 1024 * 1024);
// Set the number of threads used to scan index and tombstone files in parallel
// to build in-memory index during db open. It must be a positive number which is
// not greater than Runtime.getRuntime().availableProcessors().
// It is used to speed up db open time.
options.setBuildIndexThreads(8);
// The threshold at which page cache is synced to disk.
// data will be durable only if it is flushed to disk, therefore
// more data will be lost if this value is set too high. Setting
// this value too low might interfere with read and write performance.
options.setFlushDataSizeBytes(10 * 1024 * 1024);
// The percentage of stale data in a data file at which the file will be compacted.
// This value helps control write and space amplification. Increasing this value will
// reduce write amplification but will increase space amplification.
// This along with the compactionJobRate below is the most important setting
// for tuning HaloDB performance. If this is set to x then write amplification
// will be approximately 1/x.
options.setCompactionThresholdPerFile(0.7);
// Controls how fast the compaction job should run.
// This is the amount of data which will be copied by the compaction thread per second.
// Optimal value depends on the compactionThresholdPerFile option.
options.setCompactionJobRate(50 * 1024 * 1024);
// Setting this value is important as it helps to preallocate enough
// memory for the off-heap cache. If the value is too low the db might
// need to rehash the cache. For a db of size n set this value to 2*n.
options.setNumberOfRecords(100_000_000);
// Delete operation for a key will write a tombstone record to a tombstone file.
// the tombstone record can be removed only when all previous version of that key
// has been deleted by the compaction job.
// enabling this option will delete during startup all tombstone records whose previous
// versions were removed from the data file.
options.setCleanUpTombstonesDuringOpen(true);
// HaloDB does native memory allocation for the in-memory index.
// Enabling this option will release all allocated memory back to the kernel when the db is closed.
// This option is not necessary if the JVM is shutdown when the db is closed, as in that case
// allocated memory is released automatically by the kernel.
// If using in-memory index without memory pool this option,
// depending on the number of records in the database,
// could be a slow as we need to call _free_ for each record.
options.setCleanUpInMemoryIndexOnClose(false);
// ** settings for memory pool **
options.setUseMemoryPool(true);
// Hash table implementation in HaloDB is similar to that of ConcurrentHashMap in Java 7.
// Hash table is divided into segments and each segment manages its own native memory.
// The number of segments is twice the number of cores in the machine.
// A segment's memory is further divided into chunks whose size can be configured here.
options.setMemoryPoolChunkSize(2 * 1024 * 1024);
// using a memory pool requires us to declare the size of keys in advance.
// Any write request with key length greater than the declared value will fail, but it
// is still possible to store keys smaller than this declared size.
options.setFixedKeySize(8);
// Represents a database instance and provides all methods for operating on the database.
HaloDB db = null;
// The directory will be created if it doesn't exist and all database files will be stored in this directory
String directory = "directory";
// Open the database. Directory will be created if it doesn't exist.
// If we are opening an existing database HaloDB needs to scan all the
// index files to create the in-memory index, which, depending on the db size, might take a few minutes.
db = HaloDB.open(directory, options);
// key and values are byte arrays. Key size is restricted to 128 bytes.
byte[] key1 = Ints.toByteArray(200);
byte[] value1 = "Value for key 1".getBytes();
byte[] key2 = Ints.toByteArray(300);
byte[] value2 = "Value for key 2".getBytes();
// add the key-value pair to the database.
db.put(key1, value1);
db.put(key2, value2);
// read the value from the database.
value1 = db.get(key1);
value2 = db.get(key2);
// delete a key from the database.
db.delete(key1);
// Open an iterator and iterate through all the key-value records.
HaloDBIterator iterator = db.newIterator();
while (iterator.hasNext()) {
Record record = iterator.next();
System.out.println(Ints.fromByteArray(record.getKey()));
System.out.println(new String(record.getValue()));
}
// get stats and print it.
HaloDBStats stats = db.stats();
System.out.println(stats.toString());
// reset stats
db.resetStats();
// pause background compaction thread.
// if a file is being compacted the thread
// will block until the compaction is complete.
db.pauseCompaction();
// resume background compaction thread.
db.resumeCompaction();
// repeatedly calling pause/resume compaction methods will have no effect.
// Close the database.
db.close();
```
Binaries for HaloDB are hosted on [Bintray](https://bintray.com/yahoo).
``` xml
com.oath.halodb
halodb
x.y.x
yahoo-bintray
yahoo-bintray
https://yahoo.bintray.com/maven
```
### Read, Write and Space amplification.
Read amplification in HaloDB is always 1—for a read request it needs to do at most one disk lookup—hence it is well suited for
read latency critical workloads. HaloDB provides a configuration which can be tuned to control write amplification
and space amplification, both of which trade-off with each other; HaloDB has a background compaction thread which removes stale data
from the DB. The percentage of stale data at which a file is compacted can be controlled. Increasing this value will increase space amplification
but will reduce write amplification. For example if the value is set to 50% then write amplification will be approximately 2
### Durability and Crash recovery.
Write Ahead Logs (WAL) are usually used by databases for crash recovery. Since for HaloDB WAL _is the_ database crash recovery
is easier and faster.
HaloDB does not flush writes to disk immediately, but, for performance reasons, writes only to the OS page cache. The cache is synced to
disk once a configurable size is reached. In the event of a power loss, the data not flushed to disk will be lost. This compromise
between performance and durability is a necessary one.
In the event of a power loss and data corruption, HaloDB will scan and discard corrupted records. Since the write thread and compaction
thread could be writing to at most two files at a time only those files need to be repaired and hence recovery times are very short.
In the event of a power loss HaloDB offers the following consistency guarantees:
* Writes are atomic.
* Inserts and updates are committed to disk in the same order they are received.
* When inserts/updates and deletes are interleaved total ordering is not guaranteed, but partial ordering is guaranteed for inserts/updates and deletes.
### In-memory index.
HaloDB stores all keys and their associated metadata in an index in memory. The size of this index, depending on the
number and length of keys, can be quite big. Therefore, storing this in the Java Heap is a non-starter for a
performance critical storage engine. HaloDB solves this problem by storing the index in native memory,
outside the heap. There are two variants of the index; one with a memory pool and the other
without it. Using the memory pool helps to reduce the memory footprint of the index and reduce
fragmentation, but requires fixed size keys. A billion 8 byte keys
currently takes around 44GB of memory with memory pool and around 64GB without memory pool.
The size of the keys when using a memory pool should be declared in advance, and although this imposes an
upper limit on the size of the keys it is still possible to store keys smaller than this declared size.
Without the memory pool, HaloDB needs to allocate native memory for every write request. Therefore,
memory fragmentation could be an issue. Using [jemalloc](http://jemalloc.net/) is highly recommended as it
provides a significant reduction in the cache's memory footprint and fragmentation.
### Delete operations.
Delete operation for a key will add a tombstone record to a tombstone file, which is distinct from the data files.
This design has the advantage that the tombstone record once written need not be copied again during compaction, but
the drawback is that in case of a power loss HaloDB cannot guarantee total ordering when put and delete operations are
interleaved (although partial ordering for both is guaranteed).
### DB open time
Open db could take a few minutes, depends on number of records and tombstones. If the db open time is critical to your
use case, please keep tombstone file size relatively small and increase the number of threads used in building index.
See the option setting section in example code above. As best practice, set tombstone file size at 64MB and set build
index threads to number of available processors divided by number of dbs being opened simultaneously.
### System requirements.
* HaloDB requires Java 8 to run, but has not yet been tested with newer Java versions.
* HaloDB has been tested on Linux running on x86 and on MacOS. It may run on other platforms, but this hasn't been verified yet.
* For performance disable Transparent Huge Pages and swapping (vm.swappiness=0).
* If a thread is interrupted JVM will close those file channels the thread was operating on.
Therefore, don't interrupt threads while they are doing IO operations.
### Restrictions.
* Size of keys is restricted to 128 bytes.
* HaloDB don't support range scans or ordered access.
# Benchmarks.
[Benchmarks](docs/benchmarks.md).
# Contributing
Contributions are most welcome. Please refer to the [CONTRIBUTING](https://github.com/yahoo/HaloDB/blob/master/CONTRIBUTING.md) guide
# Credits
HaloDB was written by [Arjun Mannaly](https://github.com/amannaly).
# License
HaloDB is released under the Apache License, Version 2.0