https://github.com/ydf0509/nb_log
pip install nb_log 各种日志handler和自动转化项目的任意print的效果。日志自动彩色炫酷,可点击控制台的日志自动精确跳转到pycharm的文件和行号。文件日志多进程切割安全。在10个最重要方面全方位超过loguru
https://github.com/ydf0509/nb_log
Last synced: 4 months ago
JSON representation
pip install nb_log 各种日志handler和自动转化项目的任意print的效果。日志自动彩色炫酷,可点击控制台的日志自动精确跳转到pycharm的文件和行号。文件日志多进程切割安全。在10个最重要方面全方位超过loguru
- Host: GitHub
- URL: https://github.com/ydf0509/nb_log
- Owner: ydf0509
- Created: 2020-05-12T01:14:56.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2024-10-29T06:45:00.000Z (4 months ago)
- Last Synced: 2024-10-29T07:22:31.264Z (4 months ago)
- Language: Python
- Homepage:
- Size: 2.91 MB
- Stars: 390
- Watchers: 6
- Forks: 74
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# 1.nb_log 简介
[nb_log readthedocs文档链接](https://nb-log-doc.readthedocs.io/zh_CN/latest)
[nb_log 源码链接](https://github.com/ydf0509/nb_log)
[//]: # ([](https://postimg.cc/HJ2shsBC))
[](https://imgse.com/i/pkFSfc8)
文中文档较长,但其中大部分不是 讲解nb_log 的用法,是复习内置logging的概念。
是由于python人员不懂logging包的日志命名空间和python日志树形命名空间结构,不懂handlers和logger的关系是什么。
所以需要很长的篇幅。
很多pythoner到现在都不知道python的 logging.getLogger() 第一个入参的意义和作用,造成nb_log也不知道怎么使用多命名空间。
## tips: 要想更简单简化使用日志,请安装kuai_log
pip install kuai_log
```
kuai_log 是没有基于logging封装,但kuai_log是100%兼容logging包的方法名和入参.
kuai_log的KuaiLogger方法和入参在logging的Logger一定存在且相同, 但是logging包有的小众方法,kuai_log不存在
kuai_log比logging和loguru快30倍,比nb_log快4倍.
kuai_log 不需要配置文件,全部用入参
kuai_log 没有依赖任何三方包,nb_log依赖某些三方包
```
## 1.0 nb_log 安装
pip install nb_log
## 1.0.1 nb_log不仅是日志,还对print以及sys.stdout(sys.stderr) 打了强力的猴子补丁
对代码里面的print打了猴子补丁,自动显示print所在地方的文件名和精确行号,不怕有人胡乱print,找不到在哪里print的了。
对代码里面的 print 以及 streamHanlder日志调用的sys.stdout/stderr 打了猴子补丁,能支持所有标准输出自动写入到文件中,每天生成一个文件。
(见1.1.d配置文件说明的 SYS_STD_FILE_NAME 和 PRINT_WRTIE_FILE_NAME)。
## 1.0.2 nb_log 新增支持loguru包模式来记录日志,原汁原味的loguru来打印控制台和写入日志文件,见文档1.10.b
有了这,还有什么理由还说nb_log不如loguru,loguru只是nb_log的一个子集。
loguru控制台打印模式截图:
[](https://imgse.com/i/pkFShjS)
## 1.1 nb_log 简单使用例子
控制台打印日志:
```python
print('导入nb_log之前的print是普通的')
from nb_log import get_logger
logger = get_logger('lalala',) # get_logger 只有一个name是必传递的,其他的参数不是必传。
# logger = get_logger('lalala',log_filename='lalala.log',formatter_template=5,log_file_handler_type=2) # get_logger有很多其他入参可以自由定制logger。
logger.debug(f'debug是绿色,说明是调试的,代码ok ')
logger.info('info是天蓝色,日志正常 ')
logger.warning('黄色yello,有警告了 ')
logger.error('粉红色说明代码有错误 ')
logger.critical('血红色,说明发生了严重错误 ')
print('导入nb_log之后的print是强化版的可点击跳转的')
```
### 1.1.a nb_log 写入日志文件
nb_log默认是只打印到控制台,不会把日志写入到文件、kafka、mongo、es、发邮件和钉钉的,nb_log 记录到每一种地方都有单独的控制参数。
只有get_logger 设置了log_filename,那么该logger才会写到这个文件,日志文件夹的路径是 nb_log_config.py 的 LOG_PATH 配置的。
```python
from nb_log import get_logger
logger = get_logger('logger_namespace',
log_filename='namespace_file.log',
error_log_filename='f4b_error.log')
logger.debug('这条日志会写到文件中')
```
### 1.1.a2 nb_log 写入日志文件,并将错误日志同时写到另外的错误日志文件中
get_logger 传参了 error_log_filename 后,error级别以上的日志会单独写入到错误文件中。
或者 在nb_log_config.py 配置文件中 配置 AUTO_WRITE_ERROR_LEVEL_TO_SEPARATE_FILE = True # 自动把错误error级别以上日志写到单独的文件,根据log_filename名字自动生成错误文件日志名字。
```python
from nb_log import get_logger
logger = get_logger('logger_namespace',
log_filename='namespace_file.log',
error_log_filename='namespace_file_error.log')
logger.debug('这条日志会写到普通文件中')
logger.error('这条日志会写到普通文件中,同时会单独写入到错误文件中')
```
### 1.1.b nb_log 的最核心函数 get_logger入参说明
```doctest
:param name 日志命名空间,这个是最重要最难理解的一个入参,很多pythoner到现在还不知道name是什么作用。日志命名空间,意义非常非常非常重要,有些人到现在还不知道 logging.getLogger() 第一个入参的作用,太low了。不同的name的logger可以表现出不同的行为。
例如让 aa命名空间的日志打印控制台并且写入到文件,并且只记录info级别以上,让 bb 命名空间的日志仅仅打印控制台,并且打印debug以上级别,
这种就可以通过不同的日志命名空间做到。
:param log_level_int: 日志输出级别,设置为 1 2 3 4 5,分别对应原生logging.DEBUG(10),logging.INFO(20),logging.WARNING(30),logging.ERROR(40),logging.CRITICAL(50)级别,现在可以直接用10 20 30 40 50了,兼容了。
:param is_add_stream_handler: 是否打印日志到控制台
:param is_use_loguru_stream_handler 是否使用 loguru的控制台打印,如果为None,使用 nb_log_config.py的DEFAULUT_IS_USE_LOGURU_STREAM_HANDLER 值。
:param do_not_use_color_handler :是否禁止使用color彩色日志
:param log_path: 设置存放日志的文件夹路径,如果不设置,则取nb_log_config.LOG_PATH,如果配置中也没指定则自动在代码所在磁盘的根目录创建/pythonlogs文件夹,
非windwos下要注意账号权限问题(如果python没权限在根目录建/pythonlogs,则需要手动先创建好)
:param log_filename: 日志文件名字,仅当log_path和log_filename都不为None时候才写入到日志文件。
:param error_log_filename :错误日志文件名字,如果文件名不为None,那么error级别以上日志自动写入到这个错误文件。
:param log_file_size :日志大小,单位M,默认100M
:param log_file_handler_type :这个值可以设置为1 2 3 4 5 6 7,1为使用多进程安全按日志文件大小切割的文件日志
2为多进程安全按天自动切割的文件日志,同一个文件,每天生成一个日志
3为不自动切割的单个文件的日志(不切割文件就不会出现所谓进程安不安全的问题)
4为 WatchedFileHandler,这个是需要在linux下才能使用,需要借助lograte外力进行日志文件的切割,多进程安全。
5 为第三方的concurrent_log_handler.ConcurrentRotatingFileHandler按日志文件大小切割的文件日志,
这个是采用了文件锁,多进程安全切割,文件锁在linux上使用fcntl性能还行,win上使用win32con性能非常惨。按大小切割建议不要选第5个个filehandler而是选择第1个。
6 为作者发明的高性能多进程安全,同时按大小和时间切割的文件日志handler
7 为 loguru的 文件日志记录器
:param mongo_url : mongodb的连接,为None时候不添加mongohandler
:param is_add_elastic_handler: 是否记录到es中。
:param is_add_kafka_handler: 日志是否发布到kafka。
:param ding_talk_token:钉钉机器人token
:param ding_talk_time_interval : 时间间隔,少于这个时间不发送钉钉消息
:param mail_handler_config : 邮件配置
:param is_add_mail_handler :是否发邮件
:param formatter_template :日志模板,如果为数字,则为nb_log_config.py字典formatter_dict的键对应的模板,
1为formatter_dict的详细模板,2为简要模板,5为最好模板。
如果为logging.Formatter对象,则直接使用用户传入的模板。
:type log_level_int :int
:type is_add_stream_handler :bool
:type log_path :str
:type log_filename :str
:type mongo_url :str
:type log_file_size :int
```
log_filename 用于设置是否写入日志文件和写入什么文件中。有的人不看入参文档,就问nb_log为什么不写入日志文件中。
logger和handler是观察者模式,日志记录到哪些地方,是由添加了什么handlers决定的。
### 1.1.c nb_log配置文件的生成和导入。
项目中任意脚本使用nb_log,第一次运行代码时候,会自动在 sys.path[1] 目录下创建 nb_log_config.py文件并写入默认值。
之后nb_log 会自动 import nb_log_config, 如果import到这个模块了,控制台会提示读取了什么文件作为配置文件。
如果是 cmd或者linux运行不是pycharm,需要 设置 PYTHONPATH为项目根目录,这样就能自动在当前项目根目录下生成或者找到 nb_log_config.py了。
用户可以print(sys.path) print(sys.path[1]) 来查看 sys.path[1]的值是什么就知道了。
连PYTHONPATH作用是什么都不知道的python小白,一定要看下面文章 。
[pythonpath作用介绍的文章](https://github.com/ydf0509/pythonpathdemo)
### 1.1.d nb_log配置文件的一些参数说明。
```doctest
# 项目中的print是否自动写入到文件中。值为None则不重定向print到文件中。 自动每天一个文件, 2023-06-30.my_proj.print,生成的文件位置在定义的LOG_PATH
# 如果你设置了环境变量,export PRINT_WRTIE_FILE_NAME="my_proj.print" (linux临时环境变量语法,windows语法自己百度这里不举例),那就优先使用环境变量中设置的文件名字,而不是nb_log_config.py中设置的名字
PRINT_WRTIE_FILE_NAME = Path(sys.path[1]).name + '.print'
# 项目中的所有标准输出(不仅包括print,还包括了streamHandler日志)都写入到这个文件。自动每天一个文件, 2023-06-30.my_proj.std,生成的文件位置在定义的LOG_PATH
# 如果你设置了环境变量,export SYS_STD_FILE_NAME="my_proj.std" (linux临时环境变量语法,windows语法自己百度这里不举例),那就优先使用环境变量中设置的文件名字,,而不是nb_log_config.py中设置的名字
SYS_STD_FILE_NAME = Path(sys.path[1]).name + '.std'
USE_BULK_STDOUT_ON_WINDOWS = False # 在win上是否每隔0.1秒批量stdout,win的io太差了
DEFAULUT_USE_COLOR_HANDLER = True # 是否默认使用有彩的日志。
DEFAULUT_IS_USE_LOGURU_STREAM_HANDLER = False # 是否默认使用 loguru的控制台日志,而非是nb_log的ColorHandler
DISPLAY_BACKGROUD_COLOR_IN_CONSOLE = True # 在控制台是否显示彩色块状的日志。为False则不使用大块的背景颜色。
AUTO_PATCH_PRINT = True # 是否自动打print的猴子补丁,如果打了猴子补丁,print自动变色和可点击跳转。
SHOW_PYCHARM_COLOR_SETINGS = True # 有的人很反感启动代码时候提示教你怎么优化pycahrm控制台颜色,可以把这里设置为False
SHOW_NB_LOG_LOGO = True # 有的人方案启动代码时候打印nb_log 的logo图形,可以设置为False
DEFAULT_ADD_MULTIPROCESSING_SAFE_ROATING_FILE_HANDLER = False # 是否默认同时将日志记录到记log文件记事本中,就是用户不指定 log_filename的值,会自动写入日志命名空间.log文件中。
AUTO_WRITE_ERROR_LEVEL_TO_SEPARATE_FILE = False # 自动把错误error级别以上日志写到单独的文件,根据log_filename名字自动生成错误文件日志名字。
LOG_FILE_SIZE = 1000 # 单位是M,每个文件的切片大小,超过多少后就自动切割
LOG_FILE_BACKUP_COUNT = 10 # 对同一个日志文件,默认最多备份几个文件,超过就删除了。
LOG_PATH = '/pythonlogs' # 默认的日志文件夹,如果不写明磁盘名,则是项目代码所在磁盘的根目录下的/pythonlogs
# LOG_PATH = Path(__file__).absolute().parent / Path("pythonlogs") #这么配置就会自动在你项目的根目录下创建pythonlogs文件夹了并写入。
if os.name == 'posix': # linux非root用户和mac用户无法操作 /pythonlogs 文件夹,没有权限,默认修改为 home/[username] 下面了。例如你的linux用户名是 xiaomin,那么默认会创建并在 /home/xiaomin/pythonlogs文件夹下写入日志文件。
home_path = os.environ.get("HOME", '/') # 这个是获取linux系统的当前用户的主目录,不需要亲自设置
LOG_PATH = Path(home_path) / Path('pythonlogs') # linux mac 权限很严格,非root权限不能在/pythonlogs写入,修改一下默认值。
LOG_FILE_HANDLER_TYPE = 1 # 1 2 3 4 5
"""
LOG_FILE_HANDLER_TYPE 这个值可以设置为 1 2 3 4 5 四种值,
1为使用多进程安全按日志文件大小切割的文件日志,这是本人实现的批量写入日志,减少操作文件锁次数,测试10进程快速写入文件,win上性能比第5种提高了100倍,linux提升5倍
2为多进程安全按天自动切割的文件日志,同一个文件,每天生成一个新的日志文件。日志文件名字后缀自动加上日期。
3为不自动切割的单个文件的日志(不切割文件就不会出现所谓进程安不安全的问题)
4为 WatchedFileHandler,这个是需要在linux下才能使用,需要借助lograte外力进行日志文件的切割,多进程安全。
5 为第三方的concurrent_log_handler.ConcurrentRotatingFileHandler按日志文件大小切割的文件日志,
这个是采用了文件锁,多进程安全切割,文件锁在linux上使用fcntl性能还行,win上使用win32con性能非常惨。按大小切割建议不要选第5个个filehandler而是选择第1个。
"""
FILTER_WORDS_PRINT = [] # 例如, 你希望消息中包括阿弥陀佛 或者 包括善哉善哉 就不打印,那么可以设置 FILTER_WORDS_PRINT = ['阿弥陀佛','善哉善哉']
```
以上只是部分配置的例子,其他配置在你项目根目录下的 nb_log_config.py中都有默认值,自己按需修改设置。
其他例如日志模板定义,默认日志模板选择什么,都可以在 nb_log_config.py文件中设置。
### 1.1.1e 日志配置文件和get_logger传参的关系。
nb_log_config.py中是设置全局设置,get_logger是针对单个logger对象生成的设置。
例如 nb_log_config.py 中写 FORMATTER_KIND = 4,get_logger 传参 formatter_template=6,那么最终还是使用第6个日志模板。
如果get_logger函数没有传参指定就使用 nb_log_config.py中的配置。
就是说 get_logger 是优先级高的,nb_log_config.py 是优先级低的配置方式。
## 1.2 nb_log功能介绍
### 1.2.1 nb_log 支持日志根据级别自动变彩色
如图:日志彩色符合交通灯颜色认知。绿色是debug等级的日志,天蓝色是info等级日志,
黄色是warnning等级的警告日志,粉红色是error等级的错误日志,血红色是criticl等级的严重错误日志
### 1.2.1b 设置是否需要彩色
nb_log支持自动彩色,也支持关闭背景色块只要颜色,也支持彻底不要颜色所有日志显示为正常黑白颜色。
可以在你项目根目录下自动生成的nb_log_config.py配置文件中修改相关配置,来控制是否需要颜色,或者要颜色但不要大块的背景色块。
```angular2html
如果反对日志有各种彩色,可以设置 DEFAULUT_USE_COLOR_HANDLER = False
如果反对日志有块状背景彩色,可以设置 DISPLAY_BACKGROUD_COLOR_IN_CONSOLE = False
如果想屏蔽nb_log包对怎么设置pycahrm的颜色的提示,可以设置 WARNING_PYCHARM_COLOR_SETINGS = False
如果想改变日志模板,可以设置 FORMATTER_KIND 参数,只带了7种模板,可以自定义添加喜欢的模板
LOG_PATH 配置文件日志的保存路径的文件夹。
```
### 1.2.1c 关于彩色显示效果的最终显示的说明
有的人听说了python显示颜色的博客,例如这种
[python print显示颜色](https://www.cnblogs.com/ping-y/p/5897018.html)
```
python在控制台可以同时显示7种颜色,但是同时显示不出来65536种颜色,pycahrm控制台/win cmd/linux的控制台终端不是浏览器网页,不能显示丰富的65536色模式,
只能暴露7种ansi颜色钩子,显示控制台输出的终端软件一般提供了颜色的自定义设置,例如 pycahrm finashell xhsell
这些软件都可以对ansi颜色自定义65536色模式的颜色代码,
例如nb_log启动时候就打印提示了教用户怎么设置颜色。
例如一件拍摄街道的彩色相片有60多种颜色,在cmd pycahrm终端是不可能同时显示出那么多种颜色的。
例如你想要控制台显示杨幂穿的淡红色衣服的颜色,控制台能做得到吗?当然是能做到得,但不是在python种 用所谓得 \033[ 来设置颜色,
因为软件终端只能识别7种ansi颜色钩子,红色在65536色模式下最起码也有几万种颜色代码,有白浅红色 水红色 大红色 粉红色 红的发紫的红色 红得发黑的红色,
所以你想精确得让控制台显示多种不同的红色,你自己用大脑想想呗,仅仅在python print中 \033就想得到理想的所需的红色,简直是做梦吧。
我说的是要精确控制颜色,不能光靠python的\033[,而是要在python的终端输出软件中设置颜色。例如pycharm xhsell finashell软件中都支持自定义颜色。
所以有些小白用户觉得颜色不好看,让我在配置文件中放开自定义颜色,这是不可行的,颜色最终的显示效果由控制台终端决定,不是所谓的\033能决定的,
例如我就想问 \033后面加什么字母能精确得到桃红色 金黄色 亮绿色这些 ,这么简单的想不到吗?如果控制台自动支持65536种颜色同时显示,那么nb_log可以暴露出来怎么配置颜色。
例如 \033[32 是绿色,但是软件终端中重定义ansi 颜色,可以让你代码的\033[32 显示出1万种不同的绿色,当然也可以让\033[32 绿色但是显示成黄色 紫色啥的,
因为最终渲染颜色效果是由终端决定,不是代码中\033后面数字来决定的。用户需要在软件终端中重新定义颜色,拿pycahrm为例,设置各种想要的颜色30秒钟,配置颜色要不了很久。
```
### 1.2.1d pycharm中精确设置控制台颜色的方式
```
要说明的是,即使是同一个颜色代码在pycahrm不同主题都是颜色显示区别很大的,默认的可能很丑或者由于颜色不好导致文字看不清晰
为了达到我这种色彩效果需要重新设置主题颜色,在控制台输出的第一行就教大家怎么设置颜色了。
也可以按下面设置,需要花30秒设置。
1)使用pycharm时候,建议重新自定义设置pycharm的console里面的主题颜色。
设置方式为 打开pycharm的 file -> settings -> Editor -> Color Scheme -> Console Colors 选择monokai,
并重新修改自定义7个颜色,设置Blue为 0454F3 ,Cyan为 04DCF8 ,Green 为 13FC02 ,Magenta为 ff1cd5 ,red为 F80606 ,yellow为 EAFA04 ,gray 为 FFFFFF ,white 为 FFFFFF 。
如果设置为显示背景色快,由于不同版本的pycahrm或主题,可以根据控制台实际显示设置 White 为 1F1F1F, Black 为 FFFFFF,因为背景色是深色,前景色的文字设置为白色比黑色好。
2)使用xshell或finashell工具连接linux也可以自定义主题颜色,默认使用shell连接工具的颜色也可以。
```
### 1.2.2 nb_log 不仅支持日志变彩色,还支持项目中所有python文件的任意print自动变彩色
```
导入nb_log时候会给内置的 ptint 打猴子补丁,所以用户所有地方的print行为自动发生了变化,重定向到nb_log定义的print了
```
### 1.2.2b print自动化效果转换的好处说明
```
自动转换print效果,再也不怕有人在项目中随意print,导致很难找到是从哪里冒出来的print。
只要import nb_log,项目所有地方的print自动现型并在控制台可点击几精确跳转到print的地方。
在项目里面的几百个文件中疯狂print真的让人很生气,一个run.py运行起来几百个py文件,
每个文件print 七八次,到底自己想看想关心的print是在控制台的哪一行呢,找到老眼昏花都找不到。
比如打印x变量的值,有人是为了省代码直接 print(x),而没有多打几个字母使用print("x的值是:",x),
这样打印出来的x变量,根本无法通过全局查找找到打印x变量是在什么py文件的哪一行。
有人说把之前的print全部用#注释不就好了,那这要全局找找print,一个一个的修改,一个10万行项目,
就算平均100行有一个print关键字,那起码也得有1000个print关键字吧,一个个的修改那要改到猴年马月呢。
只有使用nb_log,才能让一切print妖魔鬼怪自动现形。
另外,在正式项目或工具类甚至做得包里面,疯狂print真的很low,可以参考大神的三方包,从来都没直接print的不存在的,
他们都是用的日志。
日志比print灵活多了,对命名空间的控制、级别过滤控制、模板自定义、能记录到的地方扩展性很强远强过print的只有控制台。
```
### 1.2.2c nb_log 五彩日志的效果截图
[](https://imgse.com/i/pkFSO3V)
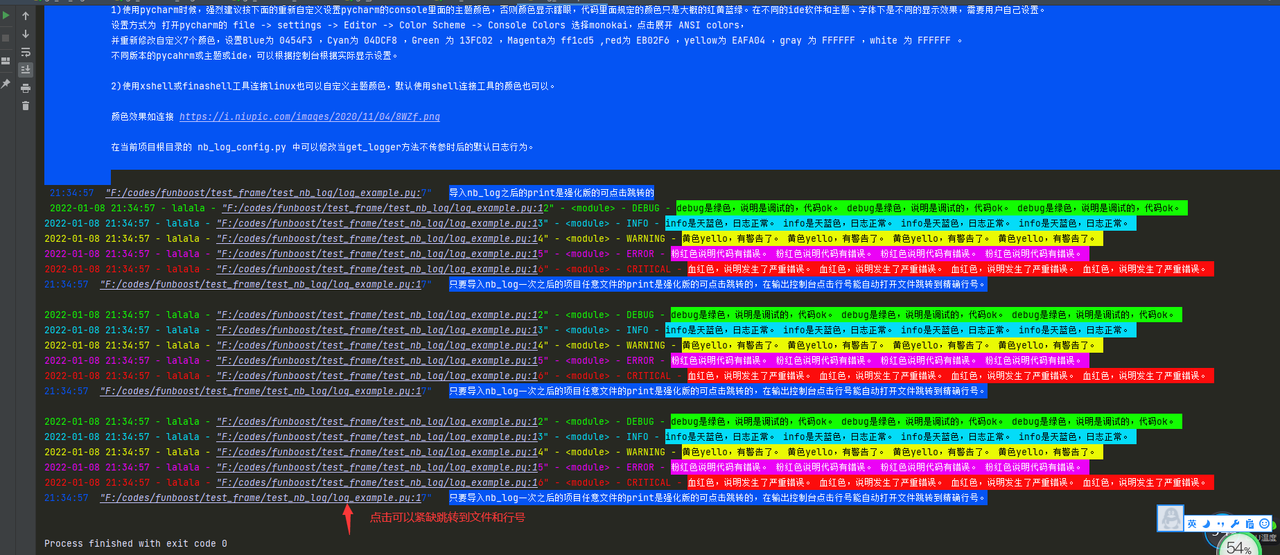
## 1.3 nb_log 支持pycharm控制台点击日志精确跳转到打印日志的文件和行号
[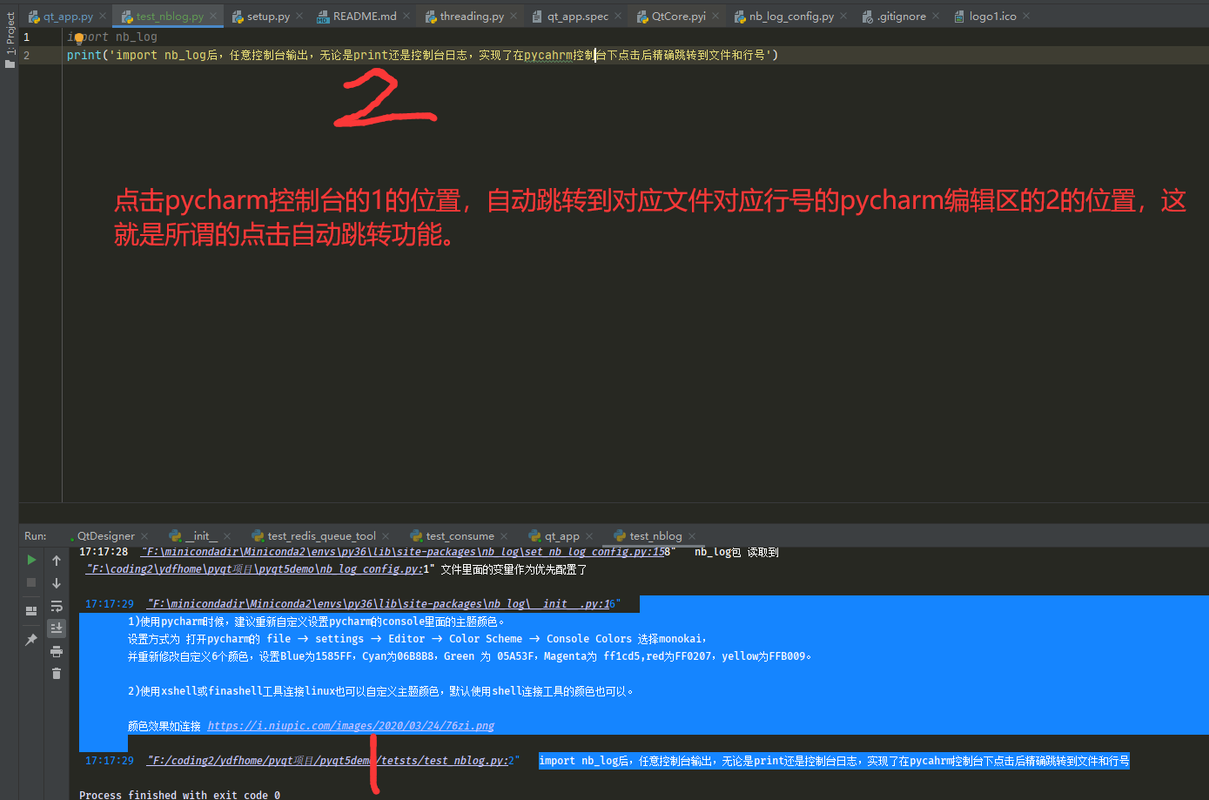](https://postimg.cc/w3WRBF5d)
## 1.4 nb_log是原生logging类型,兼容性 扩展性非常好。
nb_log 是基于python自带的原生logging模块封装的, nb_log.get_logger()生成的日志类型是 原生logging.Logger类型,
所以nb_log包对常用三方包日志兼容性替换芯做到了100%。是否是原生日志非常重要,logbook和loguru都不是python自带的原生日志,
所以和三方包结合或者替换性不好。
```
比如logru和logbook这种三方库,完全重新写的日志,
它里面主要被用户使用的logger变量类型不是python内置Logger类型,
造成logger说拥有的属性和方法有的不存在或者不一致,这样的日志和python内置的经典日志兼容性差,
只能兼容(一键替换logger类型)一些简单的debug info warning errror等方法,。
```
## 1.5 nb_log 能够简单讲日志记录到十几种地方的任意几种的组合。
内置了一键入参,每个参数是独立开关,可以把日志同时记录到10几个常用的地方的任意几种组合,
包括 控制台 文件 钉钉 邮件 mongo kafka es 等等 。
有的人以为日志只能记录到控制台和文件,其实是错的,日志可以记录到很多种地方,日志记录到哪里,是由logger添加了什么handler决定的。
## 1.6 日志命名空间独立,采用了多实例logger,按日志命名空间区分。
```python
"""
命名空间独立意味着每个logger单独的日志界别过滤,单独的控制要记录到哪些地方。
"""
from nb_log import get_logger, LogManager
logger_aa = LogManager('aa').get_logger_and_add_handlers(10, log_filename='aa.log')
logger_bb = get_logger("bb", log_level_int=30, is_add_stream_handler=False, ding_talk_token='your_dingding_token')
logger_cc = get_logger('cc', log_level_int=10, log_filename='cc.log')
logger_aa.debug('哈哈哈')
# 将会同时记录到控制台和文件aa.log中,只要debug及debug以上级别都会记录。
logger_bb.warning('嘿嘿嘿')
# 将只会发送到钉钉群消息,并且logger_bb的info debug级别日志不会被记录,非常方便测试调试然后稳定了调高界别到生产。
logger_cc.debug('嘻嘻')
# logger_cc的日志会写在cc.log中,和logger_aa的日志是不同的文件。
```
python命名空间非常重要,有的人太笨了,说设置了级别为logging.WARN,但是debug还是被记录,就是因为他牛头不对马嘴,忽视了是对什么命名空间设置的日志级别,debug日志又是什么命名空间的日志打印出来的
搜索一下文档的"命名空间"4个字,文档里面谈了几百次这个概念了,有的人logging基础太差了,令人吐血,需要在nb_log文档来讲,这样导致nb_log文档很长.
## 1.7 对内置looging包打了猴子补丁,使日志永远不会使用同种handler重复记录 ,例如,原生的
```
from logging import getLogger,StreamHandler
logger = getLogger('hi')
getLogger('hi').addHandler(StreamHandler())
getLogger('hi').addHandler(StreamHandler())
getLogger('hi').addHandler(StreamHandler())
logger.warning('啦啦啦')
明明只warning了一次,但实际会造成 啦啦啦 在控制台打印3次。
使用nb_log,对同一命名空间的日志,可以无惧反复添加同类型handler,不会重复记录。
关于重复记录的例子,更惨的例子在文档后面的例子,直接把机器cpu性能耗尽,磁盘弄爆炸。
```
## 1.8 nb_log使用对比原生logging和 loguru 更简单
### 1.8.1 logging 代码方式创建logger对象
```python
import logging
logger = logging.getLogger('my.logger.namespace')
fh = logging.FileHandler('test.log') # 可以向文件发送日志
ch = logging.StreamHandler() # 可以向屏幕发送日志
fm = logging.Formatter('%(asctime)s %(message)s') # 打印格式
fh.setFormatter(fm)
ch.setFormatter(fm)
logger.addHandler(fh)
logger.addHandler(ch)
logger.setLevel(logging.DEBUG) # 设置级别
logger.debug('debug 喜喜')
```
有些人简直是怕了原生logging了,为了创建一个好用的logger对象,代码步骤复杂的吓人,很多人完全没看懂这段代码意义,
因为他是一步步创建观察者handler,给handler设置好看的formattor,给给被观察者添加多个观察者对象。
大部分人不看设计模式,不仅不懂观察者模式,而且没听说观察者模式,所以这种创建logger方式完全蒙蔽的节奏。
其实这样一步步的写代码是为了给用户最大的自由来怎么创建一个所需的logger对象。如果高度封装创建logger过程那是简单了,
但是自定义自由度就下降了。
logging是原生日志,每个三方包肯定使用logging了,为了兼容性和看懂三方包,那肯定是要学习logging的,对logging望而却步,
想投机取巧只使用loguru是行不通的,三方包不会使用loguru,三方包里面各种命名空间的日志,等待用户添加handlers来记录日志,
loguru缺点太大了。
nb_log把logging创建logger封装了,但同时get_logger暴露了很多个入参,来让用户自由自定义logger添加什么handler和设置什么formattor。
所以nb_log有原生logging的普遍兼容性,又使用简单
### 1.8.2 python中 创建logger的第二种方式,logging.config.dictConfig()
```python
import logging
import logging.config
LOGGING_CONFIG = {
"version": 1,
"formatters": {
"default": {
'format':'%(asctime)s %(filename)s %(lineno)s %(levelname)s %(message)s',
},
"plain": {
"format": "%(message)s",
},
},
"handlers": {
"console": {
"class": "logging.StreamHandler",
"level": "INFO",
"formatter": "default",
},
"console_plain": {
"class": "logging.StreamHandler",
"level":logging.INFO,
"formatter": "plain"
},
"file":{
"class": "logging.FileHandler",
"level":20,
"filename": "./log.txt",
"formatter": "default",
}
},
"loggers": {
"console_logger": {
"handlers": ["console"],
"level": "INFO",
"propagate": False,
},
"console_plain_file_logger": {
"handlers": ["console_plain","file"],
"level": "DEBUG",
"propagate": False,
},
"file_logger":{
"handlers": ["file"],
"level": "INFO",
"propagate": False,
}
},
"disable_existing_loggers": True,
}
# 运行测试
logging.config.dictConfig(LOGGING_CONFIG)
logger = logging.getLogger("console_logger")
logger.debug('debug message')
logger.info('info message')
logger.warn('warning message')
logger.error('error message')
logger.critical('critical message')
```
这种方式和上面1.8.1的方式差不多, 但不需要写大量python代码来创建logger对象。
虽然不需要写大量python代码来构建logger对象,但是需要写 LOGGING_CONFIG 字典,
这种字典如果写错了导致配置不生效或者报错,还是很麻烦的。很多人对这个配置完全蒙蔽,不知道什么意思。
先创建formattor,创建文件和控制台handler(当然也可以自定义发送钉钉的handler),handler设置日志过滤级别,handler设置formattor,
不同的handler可以设置不同的formattor,例如同样是 logger.debug("hello world"),可以使文件和控制台记录的这条日志的前缀和字段不一样。
对不同命名空间的logger添加不同的handlers,
例如你只想打印控制台 就 logger = logging.getLogger("console_logger"),然后用这个logger.info(xxx)就可以打印控制台了。
例如你只想打写入文件 就 logger = logging.getLogger("file_logger"),然后用这个logger.info(xxx)就可以打印控制台了。
例如你打写入文件并且打印控制台 就 logger = logging.getLogger("console_plain_file_logger"),然后用这个logger.info(xxx)就可以打印控制台并且同时写入文件了。
对1.8.1和1.8.2不理解造成恐惧,是使大家使用loguru的主要原因。
### 1.8.3 loguru的简单使用
```python
from loguru import logger
logger.add("./log_files/loguru-test1.log", rotation="100000 KB")
logger.info("hello")
```
```
代码是loguru打印控制台和写入文件,和nb_log一样代码少。
甚至如果用户不需要写入文件只需要导入logger就好了,
from loguru import logger
logger.info("hello")
看起来很简单,nb_log还需要 get_logger一下,有的人觉得loguru少写一行代码,直接import就能使用了,所以loguru简单牛逼。
nb_log早就知道有人会这么想了,nb_log也支持导入即可使用。
from nb_log import defaul_logger
defaul_logger.info("hello")
但这样有个弊端,用户想使用什么日志模板,用户希望日志记录到 控制台 文件 钉钉 es中的哪几个地方没法定义。
用户如果想屏蔽a函数里面的日志,但想放开b函数里面的日志,这种不传参/不设置日志命名空间的日志就无能为力做到了。
所以nb_log推荐用户调用get_logger函数来自定义日志,而不是直接import defaul_logger然后所有地方都使用这个 defaul_logger来记录日志。
```
### 1.8.4 nb_log的使用可以比loguru更简单
loguru:
```
from loguru import logger
logger.add("./log_files/loguru-test1.log", rotation="100000 KB")
logger.info("hello")
```
nb_log ,你想简单不想get_loger,你想粗暴的导入就能记录日志到控制台和文件,代码如下:
```
import nb_log
nb_log.debug('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用debug函数,那就满足这种人')
nb_log.info('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用info函数,那就满足这种人')
nb_log.warning('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用warning函数,那就满足这种人')
nb_log.error('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用error函数,那就满足这种人')
nb_log.critical('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用critical函数,那就满足这种人')
```
[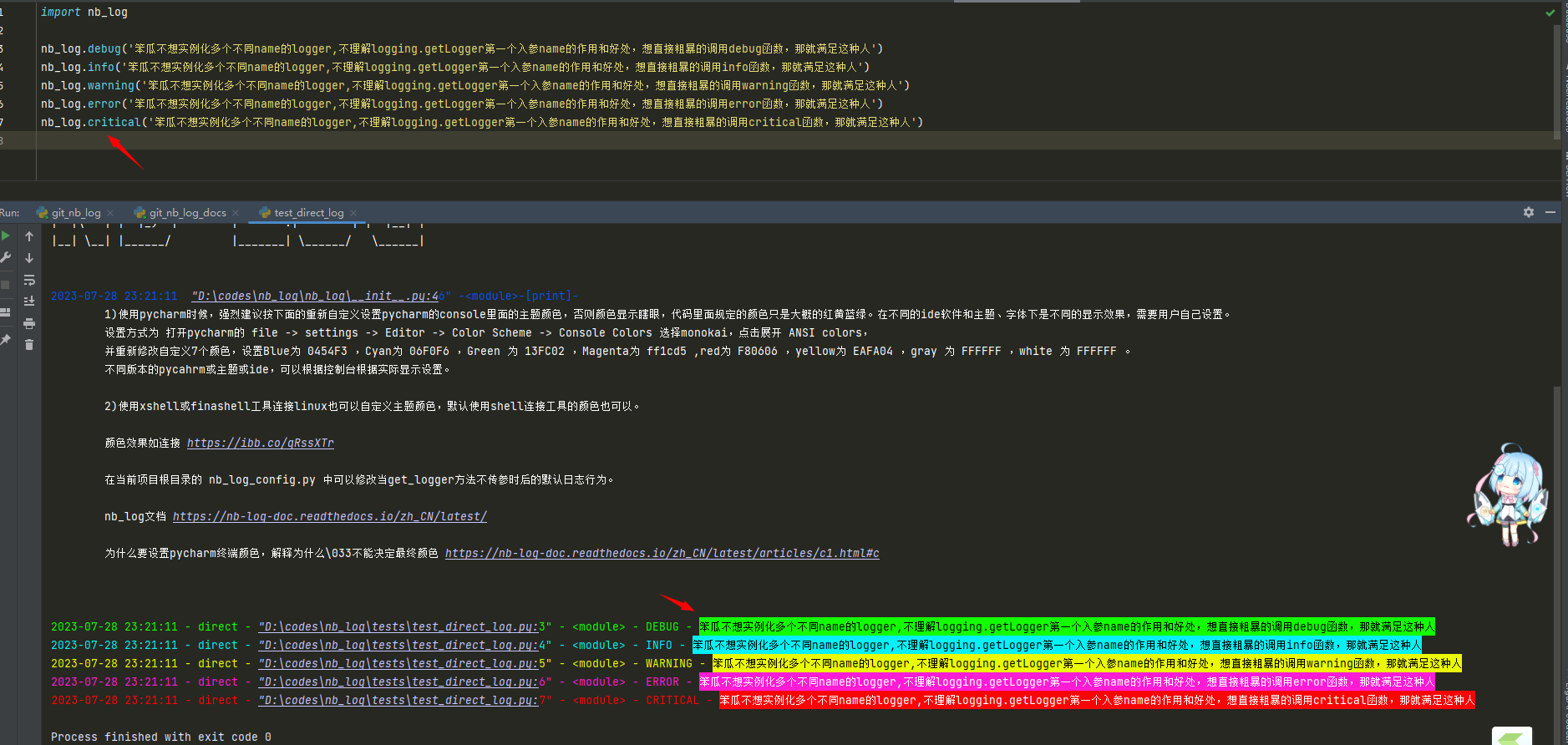](https://imgse.com/i/pPSPUDs)
```
有的笨瓜总是不能理解 logging.getLogger第一个入参name的作用和巨大好处,老是觉得需要实例化生成 logger 对象觉得麻烦,想开箱即用,那就满足这种人。
用from loguru import logger 这种日志,先不同模块或功能的日志设置不同级别,不同的模块写入不同的文件,非常麻烦不优雅。
但有的人完全不理解 日志命名空间的作用,只会抱怨nb_log的例子要他实例化不同name的logger麻烦,那就满足这种人,不用他手动实例化生成不同命名空间的logger。
import nb_log
nb_log.debug('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用debug函数,那就满足这种人')
nb_log.info('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用info函数,那就满足这种人')
nb_log.warning('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用warning函数,那就满足这种人')
nb_log.error('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用error函数,那就满足这种人')
nb_log.critical('笨瓜不想实例化多个不同name的logger,不理解logging.getLogger第一个入参name的作用和好处,想直接粗暴的调用critical函数,那就满足这种人')
loguru的用法是:
from loguru import logger
logger.debug(msg)
nb_log的用法是:
import nb_log
nb_log.debug(msg)
nb_log比loguru少了 from import那不是更简洁了吗?满足这种只知道追求简单的笨瓜。
```
综上所述 nb_log既使用简单,又兼容性高。
## 1.9 内置logging包的日志命名空间是什么
```python
import logging
logger1 = logging.getLogger('aaa')
logger2 = logging.getLogger('aaa')
logger3 = logging.getLogger('bbb')
print('logger1 id: ',id(logger1),'logger2 id: ',id(logger2),'logger3 id: ',id(logger3))
```
运行上面可以发现 logger1和logger2对象是同一个id,logger3对象是另外一个id。
通过不同的日志命名空间,可以设置不同级别的日志显示,设置不同类型的日志记录到不同的文件,是否打印控制台,是否发送邮件 钉钉消息。
有的人到现在还是不知道日志命名空间的作用,对一个大项目的所有的日志只会处理成一种表现行为,悲了个剧。
如果有人说某部分的日志打印啰嗦了,会说把日志级别调高,这是很外行的说法,请问你如何调高日志级别?有的人不懂日志命名空间,那是完全无法调日志界别,
比如1.9中的代码,有的笨瓜把 logger3的 logger3.s
你把日志界别调高了,另一个模块或类或函数里面的日志你希望需要显示debug日志呢,
你只是要屏蔽某些debug日志,
### 1.9.2 看大神和小白是怎么记录flask的请求记录和报错记录的,为什么知道日志 logger 的name 很重要?
#### 1.9.2.a 小白记录flask日志,不知道日志命名空间,脱裤子放屁手写记录日志做无用功
```python
"""
1) 在接口中自己去手写记录请求入参和url,脱裤子放屁
2) 在接口中手写记录flask接口函数报错信息
就算你在框架层面去加日志或者接口加装饰器记录日志,来解决每个接口重复写怎么记录日志,那也是很low,
不懂日志命名空间就重复做无用功,这些记录人家框架早就帮你记录了,只是没加日志 handler,等待用户来加而已
"""
import traceback
from flask import Flask, request
from loguru import logger
app = Flask(__name__)
logger.add('mylog.log')
@app.route('/')
def hello():
logger.info('Received request: %s %s %s', request.method, request.path, request.remote_addr) # 写这行拖了裤子放屁
return 'Hello World!'
@app.route('/api2')
def api2():
logger.info('Received request: %s %s %s', request.method, request.path, request.remote_addr)
try:
1 / 0 # 故意1/0 报错
return '2222'
except Exception as e:
logger.error(f'e {traceback.format_exc()}') # 写这行拖了裤子放屁
if __name__ == '__main__':
app.run()
```
#### 1.9.2.b 知道日志命名空间的大神记录flask日志,完全不需要手写记录日志
```python
"""
这个代码里面没有手写任何怎么记录flask的请求和flask异常到日志,但是可以自动记录.
这就是大神玩日志,懂命名空间.
这才是正解, werkzeug 命名空间加上各种handler,
只要请求接口,就可以记录日志到控制台和文件werkzeug.log了,
这里的flask的app的name写的是myapp ,flask框架生成的日志命名空间复用app.name,
所以给myapp加上handler,那么flask接口函数报错,就可以自动记录堆栈报错到 myapp.log 和控制台了.
"""
from flask import Flask, request
import nb_log
app = Flask('myapp')
nb_log.get_logger('werkzeug', log_filename='werkzeug.log')
nb_log.get_logger('myapp', log_filename='myapp.log')
@app.route('/')
def hello():
# 接口中无需写日志记录请求了什么url和入参
return 'Hello World!'
@app.route('/api2')
def api2():
# 接口中无需写日志记录报什么错了
1 / 0
return '2222'
if __name__ == '__main__':
app.run(port=5002)
```
```
从上面的对比可以看出,不懂日志命名空间有多么low,天天做无用功记录日志
```
有人问我是怎么知道要记录 werkzeug 和 myapp 这两个日志命名空间的日志?
```
这个不是我耍赖先百度了,然后才知道要记录 werkzeug,完全不需要耍赖
nb_log.get_logger(name=None) 可以记录任意三方包模块的一切日志命名空间的日志,
先让name=None,由于控制台的模板加了name字段,所以可以看到是什么命名空间打印的日志,然后就知道要记录哪些命名空间的日志了.
```
## 1.10 nb_log比logurur有10胜
[nb_log比logurur有10个优点方面](https://nb-log-doc.readthedocs.io/zh_CN/latest/articles/c6.html)
## 1.10.b nb_log 新增支持loguru包来记录日志,原汁原味的loguru
get_logger 传参 is_use_loguru_stream_handler=True 或者 nb_log_config.py 设置 DEFAULUT_IS_USE_LOGURU_STREAM_HANDLER = True,那么就是使用loguru来打印控制台。
get_logger 传参 log_file_handler_type=7 或者 nb_log_config.py 设置 LOG_FILE_HANDLER_TYPE = 7,那么就使用loguru的文件日志handler来写文件。
通过nb_log操作logurur很容易实现 a函数的功能写入a文件,b函数的功能写入b文件。
代码如下:
```python
import time
import nb_log
logger = nb_log.get_logger('name1', is_use_loguru_stream_handler=True, log_filename='testloguru_file111.log',log_file_handler_type=7)
logger2 = nb_log.get_logger('name2', is_use_loguru_stream_handler=True, log_filename='testloguru_file222.log',log_file_handler_type=7)
for i in range(10000000000):
logger.debug(f'loguru debug 111111')
logger2.debug(f'loguru debug 222222')
logger.info('loguru info 111111')
logger2.info('loguru info 222222')
logger.warning('loguru warn 111111')
logger2.warning('loguru warn 22222 ')
logger.error('loguru err 1111111')
logger2.error('loguru err 2222222')
logger.critical('loguru critical 111111')
logger2.critical('loguru caritical 222222')
time.sleep(1)
import requests
# 通过这样,给相应命名空间加上loguru的handler,使loguru能自动记录django flask requests urllib3的logging日志,
# 直接使用loguru来记录三方库的日志很难,但使用nb_log的loguru模式来实现记录第三方库的logging日志,却非常简单.
nb_log.get_logger('urllib3', is_use_loguru_stream_handler=True)
requests.get('http://www.baidu.com')
time.sleep(100000)
```
之前有人还是质疑怀疑nb_log不如loguru,现在nb_log完全支持了 loguru,那还有什么要质疑的。
就如同有人怀疑funboost框架,那么funboost就增加支持celery整体作为broker,完全使用celery的调度核心来执行函数,还比亲自操作celery简单很多。
作者一直是包容三方框架的,说服不了你,就兼容第三方包。
## 1.11 关于nb_log日志级别设置,看文档9.5 章节。
要精通python logging.getLogger第一个入参意义,非常非常重要。
[关于nb_log日志级别设置](https://nb-log-doc.readthedocs.io/zh_CN/latest/articles/c9.html#id2)
## 1.20 完整readthedocs文档地址
[nb_log readthedocs文档链接](https://nb-log-doc.readthedocs.io/zh_CN/latest)
[nb_log 源码链接](https://github.com/ydf0509/nb_log)
