https://github.com/yingyuankai/AiSpace
AiSpace: Better practices for deep learning model development and deployment For Tensorflow 2.0
https://github.com/yingyuankai/AiSpace
aispace albert-chinese bert chinese clue cmrc2018 dureader electra ernie lr-finder pretrained-language-model pretrained-models roberta-chinese swa tensorflow2 xlnet
Last synced: 8 months ago
JSON representation
AiSpace: Better practices for deep learning model development and deployment For Tensorflow 2.0
- Host: GitHub
- URL: https://github.com/yingyuankai/AiSpace
- Owner: yingyuankai
- License: apache-2.0
- Created: 2020-01-10T02:21:26.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2023-02-16T04:13:15.000Z (almost 3 years ago)
- Last Synced: 2024-07-31T03:10:13.269Z (over 1 year ago)
- Topics: aispace, albert-chinese, bert, chinese, clue, cmrc2018, dureader, electra, ernie, lr-finder, pretrained-language-model, pretrained-models, roberta-chinese, swa, tensorflow2, xlnet
- Language: Python
- Homepage: https://aispace.readthedocs.io/en/latest/index.html
- Size: 806 KB
- Stars: 26
- Watchers: 4
- Forks: 4
- Open Issues: 24
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-tensorflow-2 - AiSpace: Better practices for deep learning model development and deployment For Tensorflow 2.0
README
# AiSpace



AiSpace provides highly configurable framework for deep learning model development, deployment and
conveniently use of pre-trained models (bert, albert, opt, etc.).
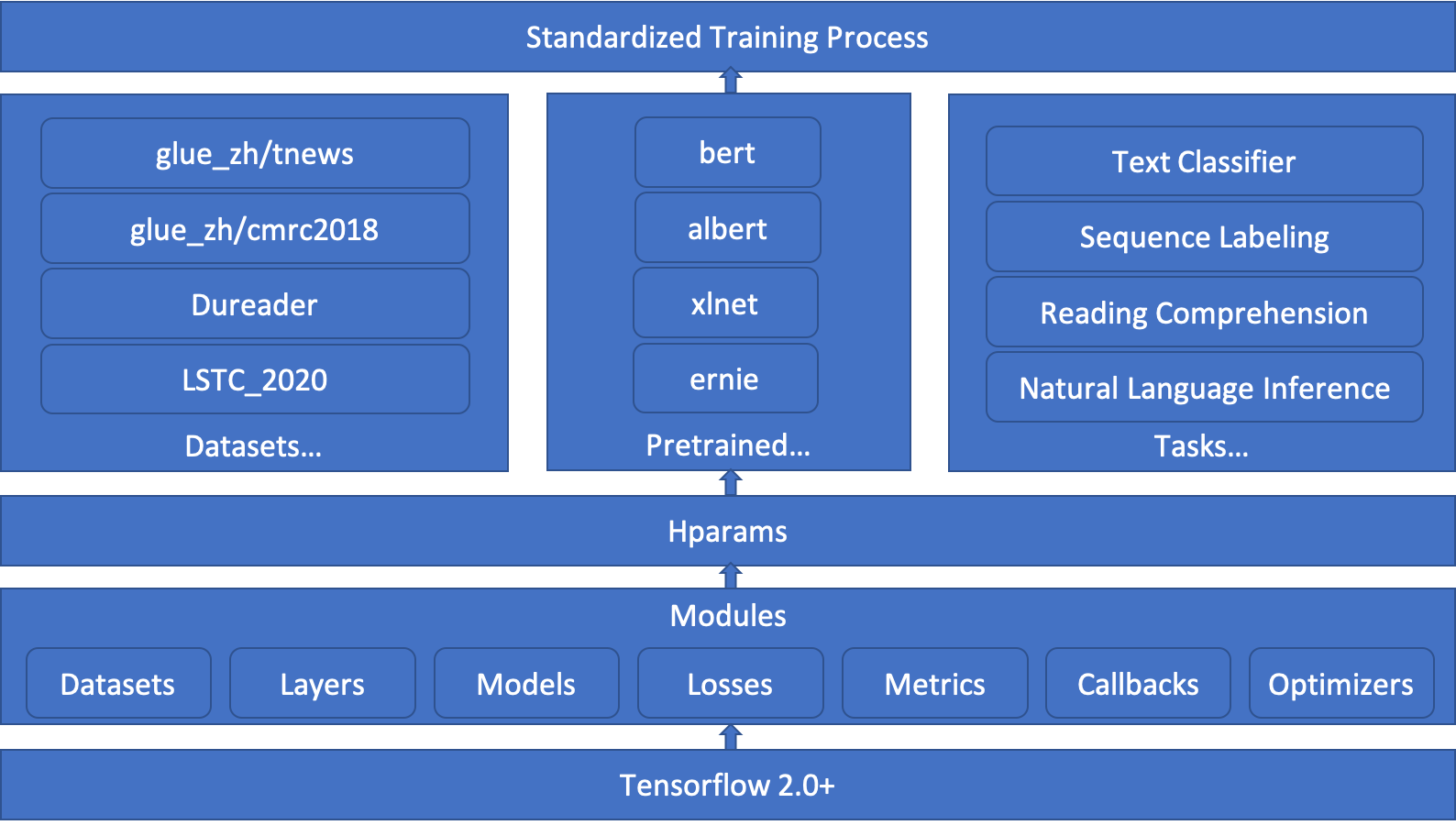
Table of Contents
=================
* [Features](#features)
* [Requirements](#requirements)
* [Instructions](#instructions)
* [Configuration](#Configuration)
* [Pretrained](#Pretrained)
* [Experiments](#experiments)
* [Todos](#Todos)
* [Refs](#Refs)
## Features
* Highly configurable, we manage all hyperparameters with inheritable Configuration files.
* All modules are registerable, including models, dataset, losses, optimizers, metrics, callbacks, etc.
* Standardized process
* Multi-GPU Training
* K-fold cross validation training
* Integrate lr finder
* Integrate multiple pre-trained models, including chinese
* Simple and fast deployment using [BentoML](https://github.com/bentoml/BentoML)
* Integrated Chinese benchmarks [CLUE](https://github.com/CLUEbenchmark/CLUE)
## Requirements
```text
git clone https://github.com/yingyuankai/AiSpace.git
cd AiSpace && pip install -r requirements
```
## Instructions
### Training
```
python -u aispace/trainer.py \
--schedule train_and_eval \
--config_name CONFIG_NAME \
--config_dir CONFIG_DIR \
[--experiment_name EXPERIMENT_NAME] \
[--model_name MODEL_NAME] \
[--gpus GPUS]
```
### Output file structure
The default output path is ***save***, which may has multiple output directories under name as:
```text
{experiment_name}_{model_name}_{dataset_name}_{random_seed}_{id}
```
Where ***id*** indicates the sequence number of the experiment for the same task, increasing from 0.
Take the text classification task as an example, the output file structure is similar to the following:
```
experiment_name: test
model_name: bert_for_classification
dataset_name: glue_zh/tnews
random_seed: 119
id: 0
```
```
test_bert_for_classification_glue_zh__tnews_119_0
├── checkpoint # 1. checkpoints
│ ├── checkpoint
│ ├── ckpt_1.data-00000-of-00002
│ ├── ckpt_1.data-00001-of-00002
│ ├── ckpt_1.index
| ...
├── deploy # 2. Bentoml depolyment directory
│ └── BertTextClassificationService
│ └── 20191208180211_B6FC81
├── hparams.json # 3. Json file of all hyperparameters
├── logs # 4. general or tensorboard log directory
│ ├── errors.log # error log file
│ ├── info.log # info log file
│ ├── train
│ │ ├── events.out.tfevents.1574839601.jshd-60-31.179552.14276.v2
│ │ ├── events.out.tfevents.1574839753.jshd-60-31.profile-empty
│ └── validation
│ └── events.out.tfevents.1574839787.jshd-60-31.179552.151385.v2
├── model_saved # 5. last model saved
│ ├── checkpoint
│ ├── model.data-00000-of-00002
│ ├── model.data-00001-of-00002
│ └── model.index
└── reports # 6. Eval reports for every output or task
└── output_1_classlabel # For example, text classification task
├── confusion_matrix.txt
├── per_class_stats.json
└── stats.json
```
### Training with resumed model
```
python -u aispace/trainer.py \
--schedule train_and_eval \
--config_name CONFIG_NAME \
--config_dir CONFIG_DIR \
--model_resume_path MODEL_RESUME_PATH \
[--experiment_name EXPERIMENT_NAME] \
[--model_name MODEL_NAME] \
[--gpus GPUS]
```
--model_resume_path is a path to initialization model.
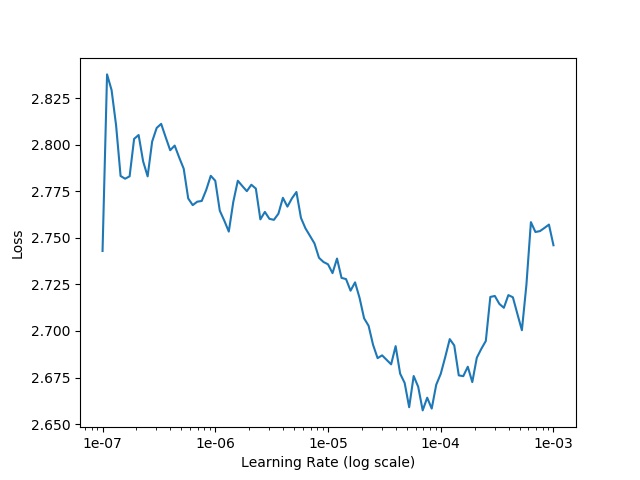
### lr finder
Firstly, use optimizer adma and open lr_finder callback.
```yaml
policy:
name: "base"
optimizer:
name: adam
callbacks:
lr_finder:
switch: true
```
Then run training policy as base.
Lastly, you can find **lr_finder.jpg** in you workspace.
### K-fold cross validation training
Firstly, Replace training default policy form base to:
```yaml
training:
policy:
name: "k-fold"
config:
k: 5
```
The **k** is the number of fold. Your can refer to the configuration file in:
```
./confis/glue_zh/tnews_k_fold.yml
```
Then run training script as usual.
### Average checkpoints
```
python -u aispace/trainer.py \
--schedule avg_checkpoints \
--config_name CONFIG_NAME \
--config_dir CONFIG_DIR \
--prefix_or_checkpoints PREFIX_OR_CHECKPOINGS \
[--ckpt_weights CKPT_WEIGHTS] \
[--experiment_name EXPERIMENT_NAME] \
[--model_name MODEL_NAME] \
[--gpus GPUS]
```
--prefix_or_checkpoints is paths to multiple checkpoints separated by comma.
--ckpt_weights is weights same order as the prefix_or_checkpoints.
### Deployment
Generate deployment files before deployment, you need to specify the model path (--model_resume_path) to be deployed like following.
```
python -u aispace/trainer.py \
--schedule deploy \
--config_name CONFIG_NAME \
--config_dir CONFIG_DIR \
--model_resume_path MODEL_RESUME_PATH \
[--experiment_name EXPERIMENT_NAME] \
[--model_name MODEL_NAME] \
[--gpus GPUS]
```
We use [BentoML](https://github.com/bentoml/BentoML) as deploy tool, so your must implement the ***deploy*** function in your model class.
## Configuration
All the configurations are in ***configs***, in which ***base*** (./configs/default/base.yml) is the most basic, any configuration downstream includes this configuration directly or indirectly.
Before you start, it is best to read this configuration carefully.
Your can use ***includes*** field to load other configurations, then the current configuration inherits the configurations and overrides the same configuration fields. Just like class inheritance, a function of the same name in a subclass overrides a function of the parent class.
The syntax is like this:
merge configuration of bert_huggingface into current.
```yaml
includes:
- "../pretrain/bert_huggingface.yml" # relative path
```
## Datasets
|Dataset|Info|Ref|
|---|---|---|
|glue_zh/afqmc|Ant Financial Question Matching Corpus(蚂蚁金融语义相似度)|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/tnews|TNEWS 今日头条中文新闻(短文)分类|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/iflytek|IFLYTEK' 长文本分类|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/cmnli|CMNLI 语言推理任务|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/copa|COPA 因果推断-中文版|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/wsc|WSC Winograd模式挑战中文版|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/csl|CSL 论文关键词识别|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/cmrc2018|Reading Comprehension for Simplified Chinese 简体中文阅读理解任务|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/drcd|繁体阅读理解任务|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/chid|成语阅读理解填空 Chinese IDiom Dataset for Cloze Test|https://github.com/CLUEbenchmark/CLUE|
|glue_zh/c3|中文多选阅读理解|https://github.com/CLUEbenchmark/CLUE|
|Dureader/robust|首个关注阅读理解模型鲁棒性的中文数据集|https://aistudio.baidu.com/aistudio/competition/detail/49|
|Dureader/yesno|一个以观点极性判断为目标任务的数据集|https://aistudio.baidu.com/aistudio/competition/detail/49|
|LSTC_2020/DuEE_trigger|从自然语言文本中抽取事件并识别事件类型|https://aistudio.baidu.com/aistudio/competition/detail/32|
|LSTC_2020/DuEE_role|从自然语言文本中抽取事件元素|https://aistudio.baidu.com/aistudio/competition/detail/32|
## Pretrained
We have integrated multiple pre-trained language models and are constantly expanding。
|Model|#Model|#Chinese model|Download manually?|Refs|Status|
|---|---|---|---|---|---|
|bert|13|1|no|[transformers](https://github.com/huggingface/transformers)|Done|
|albert|8|0|no|[transformers](https://github.com/huggingface/transformers)|Done|
|albert_chinese|9|9|yes|[albert_zh](https://github.com/brightmart/albert_zh)|Done|
|bert_wwm|4|4|yes|[Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm)|Done|
|xlnet|2|0|no|[transformers](https://github.com/huggingface/transformers)|Processing|
|xlnet_chinese|2|2|yes|[Chinese-PreTrained-XLNets](https://github.com/ymcui/Chinese-PreTrained-XLNets)|Done|
|ernie|4|2|yes|[ERNIE](https://github.com/PaddlePaddle/ERNIE)|Done|
|NEZHA|4|4|yes|[NEZHA](https://github.com/huawei-noah/Pretrained-Language-Model)|Done|
|TinyBERT|-|-|-|[TinyBERT](https://github.com/huawei-noah/Pretrained-Language-Model)|Processing|
|electra_chinese|4|4|yes|[Chinese-ELECTR](https://github.com/ymcui/Chinese-ELECTRA)|Done|
For those models that need to be downloaded manually, download, unzip them and modify the path in the corresponding configuration.
Some pre-trained models don't have tensorflow versions, I converted them and made them available for download。
|Model|Refs|tf version|
|---|---|---|
|ERNIE_Base_en_stable-2.0.0|[ERNIE](https://github.com/PaddlePaddle/ERNIE)|[baidu yun](https://pan.baidu.com/s/142YNWLrQhO5hxvq2eCxs5g)|
|ERNIE_stable-1.0.1|[ERNIE](https://github.com/PaddlePaddle/ERNIE)|[baidu yun](https://pan.baidu.com/s/15y-1B7rBW7USIvixIRqXrw)|
|ERNIE_1.0_max-len-512|[ERNIE](https://github.com/PaddlePaddle/ERNIE)|[baidu yun](https://pan.baidu.com/s/1B-gehcnVDnNQIAr6m2dPjg)|
|ERNIE_Large_en_stable-2.0.0|[ERNIE](https://github.com/PaddlePaddle/ERNIE)|[baidu yun](https://pan.baidu.com/s/1hUT9X4K7PL5ETysq2mz0IA)|
## Examples
We have implemented some tasks in the [CLUE](https://github.com/CLUEbenchmark/CLUE) (The Chinese General Language Understanding Evaluation (GLUE) benchmark).
Please refer to [Examples Doc](https://aispace.readthedocs.io/en/latest/examples.html).
Take ***glue_zh/tnews*** as an example:
Tnews is a task of Chinese GLUE, which is a short text classification task from ByteDance.
Run Tnews classification
```
python -u aispace/trainer.py \
--experiment_name test \
--model_name bert_for_classification \
--schedule train_and_eval \
--config_name tnews \
--config_dir ./configs/glue_zh \
--gpus 0 1 2 3 \
```
Specify different pretrained model, please change ***includes*** and ***pretrained.name*** in config file.
|Model|Accuracy|Macro_precision|Macro_recall|Macro_f1|
|---|---|---|---|---|
|bert-base-chinese-huggingface|65.020|64.987|62.484|63.017|
|albert_base_zh|62.160|62.514|59.267|60.377|
|albert_base_zh_additional_36k_steps|61.760|61.723|58.534|59.273|
|albert_small_zh_google|62.620|63.819|58.992|59.387|
|albert_large_zh|61.830|61.980|59.843|60.200|
|albert_tiny|60.110|57.118|55.559|56.077|
|albert_tiny_489k|61.130|57.875|57.200|57.332|
|albert_tiny_zh_google|60.860|59.500|57.556|57.702|
|albert_xlarge_zh_177k|63.380|63.603|60.168|60.596|
|albert_xlarge_zh_183k|63.210|**67.161**|59.220|59.599|
|chinese_wwm|64.000|62.747|64.509|63.042|
|chinese_wwm_ext|65.020|65.048|62.017|62.688|
|chinese_roberta_wwm_ext|64.860|64.819|63.275|63.591|
|chinese_roberta_wwm_large_ext|65.700|62.342|61.527|61.664|
|ERNIE_stable-1.0.1|**66.330**|66.903|63.704|64.524|
|ERNIE_1.0_max-len-512|66.010|65.301|62.230|62.884|
|chinese_xlnet_base|65.110|64.377|**64.862**|64.169|
|chinese_xlnet_mid|66.000|66.377|63.874|**64.708**|
|chinese_electra_small|60.370|60.223|57.161|57.206|
|chinese_electra_small_ex|59.900|58.078|55.525|56.194|
|chinese_electra_base|60.500|60.090|58.267|58.909|
|chinese_electra_large|60.500|60.362|57.653|58.336|
|nezha-base|58.940|57.909|55.650|55.630|
|nezha-base-wwm|58.800|60.060|54.859|55.831|
**NOTE**: The hyper-parameters used here have not been fine-tuned.
## Todos
- More complete and detailed documentation;
- More pretrained models;
- More evaluations of [CLUE](https://github.com/CLUEbenchmark/CLUE);
- More Chinese dataset;
- Support Pytorch;
- Improve the tokenizer to make it more versatile;
- Build AiSpace server, make it can train and configure using UI.
## Contact Author
Mail: yingyuankai@aliyun.com
Wechat: woshimoming1991
## Citing
```
@misc{AiSpace,
author = {yuankai ying},
title = {AiSpace: Highly configurable framework for deep learning model development and deployment},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/yingyuankai/AiSpace}},
}
```
## Refs
- [transformers](https://github.com/huggingface/transformers)
- [UER-py](https://github.com/dbiir/UER-py)
- [Huawei pretrained models](https://github.com/huawei-noah/Pretrained-Language-Model)