https://github.com/yossef-khaled/arithmetic-expressions-evaluator
A parser for the arithmetic expressions using C# language.
https://github.com/yossef-khaled/arithmetic-expressions-evaluator
automation csharp parser regex
Last synced: 10 months ago
JSON representation
A parser for the arithmetic expressions using C# language.
- Host: GitHub
- URL: https://github.com/yossef-khaled/arithmetic-expressions-evaluator
- Owner: yossef-khaled
- Created: 2020-06-17T15:18:56.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2021-09-01T06:28:15.000Z (almost 5 years ago)
- Last Synced: 2025-04-12T19:46:46.883Z (over 1 year ago)
- Topics: automation, csharp, parser, regex
- Language: C#
- Homepage:
- Size: 986 KB
- Stars: 3
- Watchers: 2
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Arithmetic-expressions-evaluator
A parser for the arithmetic expressions using C# language. It consists of (as the main components):
- Lexer.
- Parser.
- Evaluator.
## Lexer
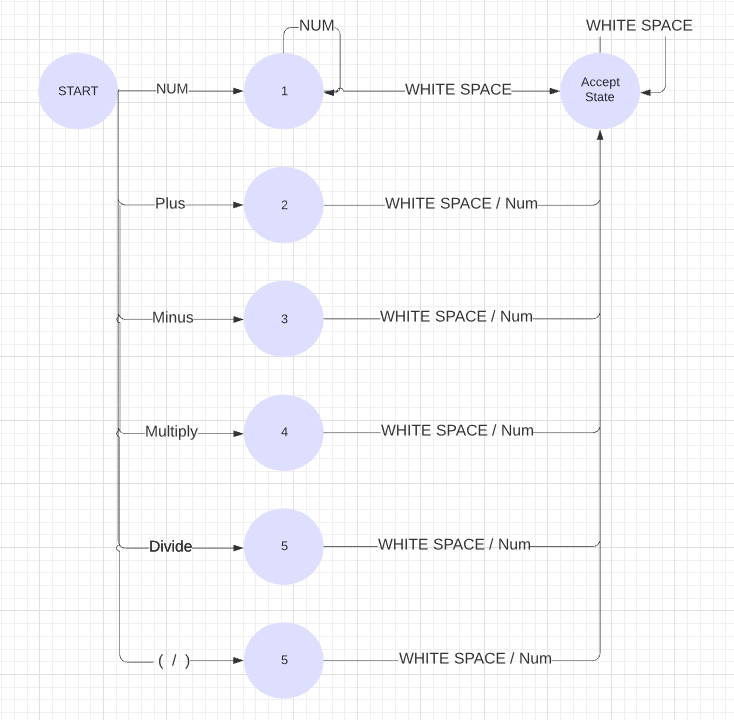
The lexer is implemented in the Lexer.cs file. It's all about dividing the input stream into tokens, each is one type of the following tokens :
- Numbers {0-9}*
- Plus { + }
- Minus { - }
- Multiply { * }
- Divide { / }
- Open Parenthesis { ( }
- Close Parenthesis { ) }
- End Of File { \0 }
- White Space { }*
- Bad Token { $ / @ / ! / % / ^ …. etc}*
These tokens are later implemented as an enum in the SyntaxKind file.
The following DFA represents the lexer, which accepts only these tokens :
## Parser
The parser is all about receiving an array of tokens from the lexer and then construct these tokens as
a tree of nodes. The parser is implemented in the Parser.cs file.
We used the following CFG (Context Free Grammer) to derive our expressions:
- E → E + T | T
- T → T * F | F
- F → (E) | Number
After converting the CFG to be LL(1) the following is our new grammer:
- E → T E’
- E’→ + T E’ | ε
- T → F T’
- T’→ *F T’ | ε
- F → (E) | num
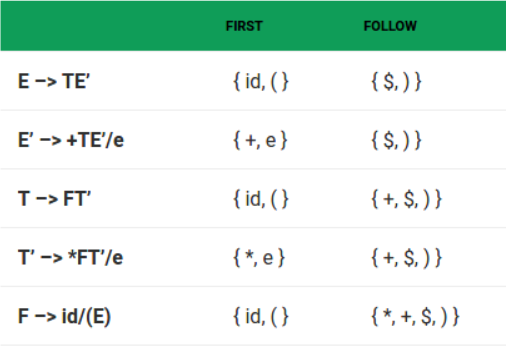
#### Computing the first and follow :
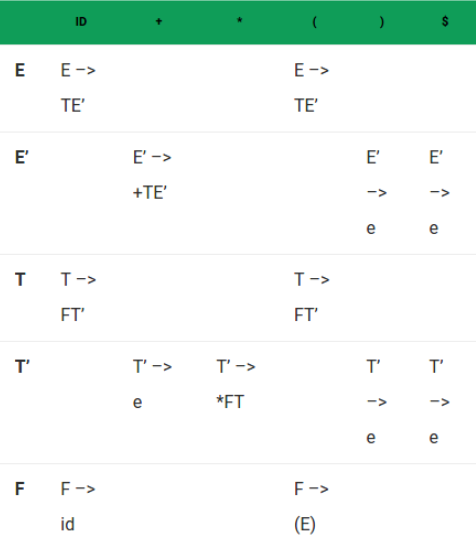
#### Calculating parsing table :
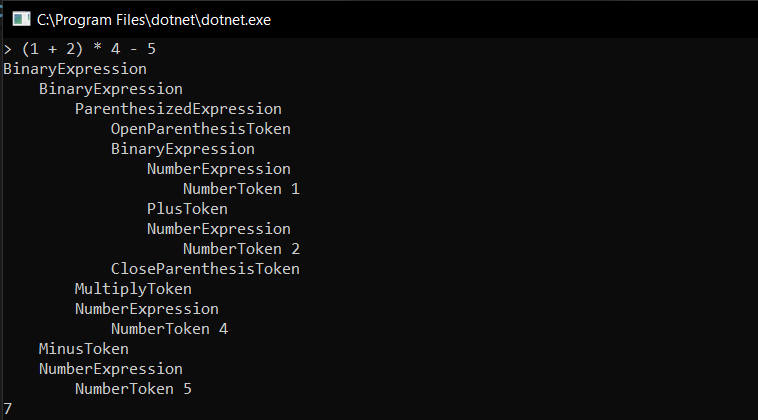
This “SyntaxTree” class represents the tree that the parser will return. It has a root, a list of diagnostics for errors, and an end of file.
It will be something like this :
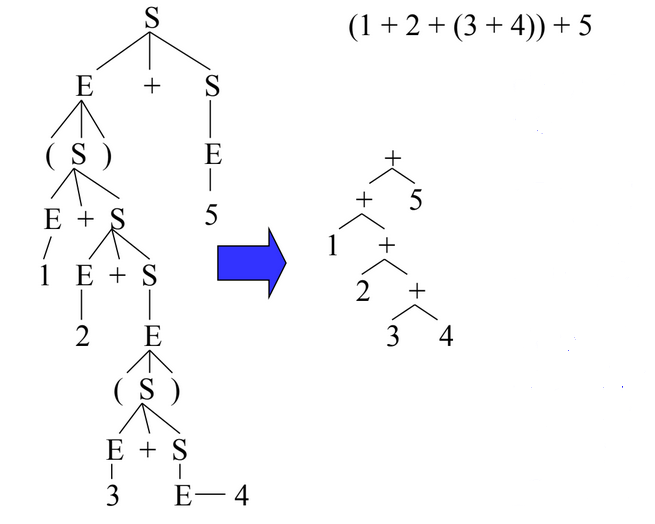
> **Note:** the parser is using **recursive descent** to parse the stream input.
## Evaluator
The evaluator is where we calculate the result starting from the tree. It takes the root of the tree that the parser passes. It walks over all the nodes and when it reaches the leaves of the tree, it goes up the tree calculating the result till it goes through the whole stream.
The evaluator is implemented in the Evaluator.cs file.
Finally, at the end, "Pretty Print" function (which is not that pretty) will output the result and the tree into the console as follow: