https://github.com/yuanxiaosc/multiple-relations-extraction-only-look-once
Multiple-Relations-Extraction-Only-Look-Once. Just look at the sentence once and extract the multiple pairs of entities and their corresponding relations. 端到端联合多关系抽取模型,可用于 http://lic2019.ccf.org.cn/kg 信息抽取。
https://github.com/yuanxiaosc/multiple-relations-extraction-only-look-once
bert-model entity-extraction information-extraction joint-models relation-extraction tensorflow-models
Last synced: about 1 year ago
JSON representation
Multiple-Relations-Extraction-Only-Look-Once. Just look at the sentence once and extract the multiple pairs of entities and their corresponding relations. 端到端联合多关系抽取模型,可用于 http://lic2019.ccf.org.cn/kg 信息抽取。
- Host: GitHub
- URL: https://github.com/yuanxiaosc/multiple-relations-extraction-only-look-once
- Owner: yuanxiaosc
- Created: 2019-05-08T09:28:01.000Z (about 7 years ago)
- Default Branch: master
- Last Pushed: 2019-07-25T01:46:43.000Z (almost 7 years ago)
- Last Synced: 2025-04-09T12:06:53.561Z (about 1 year ago)
- Topics: bert-model, entity-extraction, information-extraction, joint-models, relation-extraction, tensorflow-models
- Language: Python
- Homepage: https://yuanxiaosc.github.io/2019/05/28/信息抽取任务相关论文发展脉络/
- Size: 238 KB
- Stars: 347
- Watchers: 9
- Forks: 69
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Multiple-Relations-Extraction-Only-Look-Once
Multiple-Relations-Extraction-Only-Look-Once. Just look at the sentence once and extract the multiple pairs of entities and their corresponding relations.
只用看一次,抽取所有的实体及其**对应的**所有关系。
**input**
```"text": "《逐风行》是百度文学旗下纵横中文网签约作家清水秋风创作的一部东方玄幻小说,小说已于2014-04-28正式发布"```
**output**
```
"spo_list": [{"predicate": "连载网站", "object_type": "网站", "subject_type": "网络小说", "object": "纵横中文网", "subject": "逐风行"}, {"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "清水秋风", "subject": "逐风行"}]
```
## Main principle

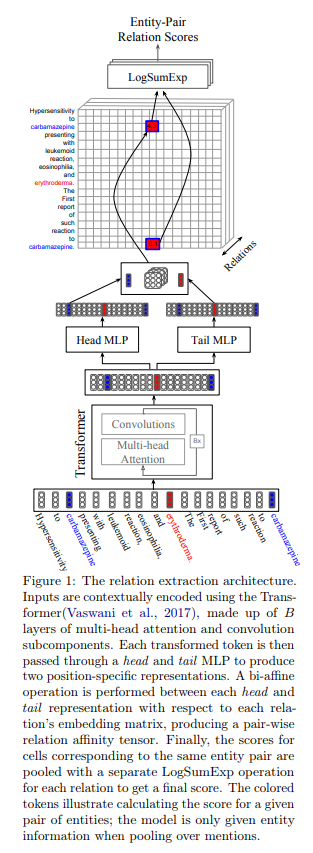
The entity extraction task is converted into a sequence annotation task, and the multi-relationship extraction task is converted into a [multi-head selection task](https://arxiv.org/abs/1804.07847). The token will be sent to the model, and the model will predict the output label, predicate value, and predicate location. Using the bin/read_standard_format_data.py file, the original game data format can be converted into the data format required for the multi-head selection model, as follows:
把实体抽取任务转换成序列标注任务,把多关系抽取任务转换成[多头选择任务](https://arxiv.org/abs/1804.07847)。token会被送入模型,模型会预测输出label、predicate value 和 predicate location。使用bin/read_standard_format_data.py文件可以把原始比赛数据格式转换成多头选择模型所需数据格式,如下所示:
```
+-------+-------+------------+----------------------+--------------------+
| index | token | label | predicate value | predicate location |
+-------+-------+------------+----------------------+--------------------+
| 0 | 《 | O | ['N'] | [0] |
| 1 | 逐 | B-图书作品 | ['连载网站', '作者'] | [12, 21] |
| 2 | 风 | I-图书作品 | ['N'] | [2] |
| 3 | 行 | I-图书作品 | ['N'] | [3] |
| 4 | 》 | O | ['N'] | [4] |
| 5 | 是 | O | ['N'] | [5] |
| 6 | 百 | O | ['N'] | [6] |
| 7 | 度 | O | ['N'] | [7] |
| 8 | 文 | O | ['N'] | [8] |
| 9 | 学 | O | ['N'] | [9] |
| 10 | 旗 | O | ['N'] | [10] |
| 11 | 下 | O | ['N'] | [11] |
| 12 | 纵 | B-网站 | ['N'] | [12] |
| 13 | 横 | I-网站 | ['N'] | [13] |
| 14 | 中 | I-网站 | ['N'] | [14] |
| 15 | 文 | I-网站 | ['N'] | [15] |
| 16 | 网 | I-网站 | ['N'] | [16] |
| 17 | 签 | O | ['N'] | [17] |
| 18 | 约 | O | ['N'] | [18] |
| 19 | 作 | O | ['N'] | [19] |
| 20 | 家 | O | ['N'] | [20] |
| 21 | 清 | B-人物 | ['N'] | [21] |
| 22 | 水 | I-人物 | ['N'] | [22] |
| 23 | 秋 | I-人物 | ['N'] | [23] |
| 24 | 风 | I-人物 | ['N'] | [24] |
| 25 | 创 | O | ['N'] | [25] |
...
+-------+-------+------------+----------------------+--------------------+
```
> [See my blog for more details](https://yuanxiaosc.github.io/2019/05/09/Multiple-Relations-Extraction-Only-Look-Once/)
## Document description
|name|description|
|-|-|
|bert|The feature extractor of the model, where BERT is used as the feature extractor for the model. It can be replaced with other feature extractors, such as BiLSTM and CNN.|
|bin/data_manager.py|Prepare formatted data for the mode.|
|bin/integrated_model_output.py|Organize the output of model prediction into standard data format.|
|bin/read_standard_format_data.py|View formatted data.|
|bin/test_head_select_scores.py|One method for solving the relationship extraction problem: the multi-head selection method.|
|experimental_loss_function|run_multiple_relations_extraction_XXX.py, File under experiment.|
|raw_data||
|produce_submit_json_file.py|Generate entity relationship triples and write them to JSON files.|
|run_multiple_relations_extraction.py|The most basic model for model training and prediction.|
### Need Your Help!
+ Well-designed loss function!
+ https://github.com/bekou/multihead_joint_entity_relation_extraction/issues/11
+ Improve the speed of produce_submit_json_file.py to generate entity relationship files, and change to parallel processing!
**Problem code location**
> run_multiple_relations_extraction.py 531~549 lines!
You can try different experiments (experimental_loss_function/run_multiple_relations_extraction_XXX.py) and share your results.
## Use example
### [2019语言与智能技术竞赛](http://lic2019.ccf.org.cn/kg)
#### 竞赛任务
给定schema约束集合及句子sent,其中schema定义了关系P以及其对应的主体S和客体O的类别,例如(S_TYPE:人物,P:妻子,O_TYPE:人物)、(S_TYPE:公司,P:创始人,O_TYPE:人物)等。 任务要求参评系统自动地对句子进行分析,输出句子中所有满足schema约束的SPO三元组知识Triples=[(S1, P1, O1), (S2, P2, O2)…]。
输入/输出:
(1) 输入:schema约束集合及句子sent
(2) 输出:句子sent中包含的符合给定schema约束的三元组知识Triples
**例子**
输入句子: ```"text": "《古世》是连载于云中书城的网络小说,作者是未弱"```
输出三元组: ```"spo_list": [{"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "未弱", "subject": "古世"}, {"predicate": "连载网站", "object_type": "网站", "subject_type": "网络小说", "object": "云中书城", "subject": "古世"}]}```
#### 数据简介
本次竞赛使用的SKE数据集是业界规模最大的基于schema的中文信息抽取数据集,其包含超过43万三元组数据、21万中文句子及50个已定义好的schema,表1中展示了SKE数据集中包含的50个schema及对应的例子。数据集中的句子来自百度百科和百度信息流文本。数据集划分为17万训练集,2万验证集和2万测试集。其中训练集和验证集用于训练,可供自由下载,测试集分为两个,测试集1供参赛者在平台上自主验证,测试集2在比赛结束前一周发布,不能在平台上自主验证,并将作为最终的评测排名。
### Getting Started
#### Environment Requirements
+ python 3.6+
+ Tensorflow 1.12.0+
#### Step 1: Environmental preparation
+ Install Tensorflow
+ Dowload [bert-base, chinese](https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip), unzip file and put it in ```pretrained_model``` floader.
#### Step 2: Download the training data, dev data and schema files
Please download the training data, development data and schema files from [the competition website](http://lic2019.ccf.org.cn/kg), then unzip files and put them in ```./raw_data/``` folder.
```
cd data
unzip train_data.json.zip
unzip dev_data.json.zip
cd -
```
此处不再提供2019语言与智能技术竞赛_信息抽取原始数据下载,如有疑问可以联系我的邮箱 wangzichaochaochao@gmail.com
There is no longer a raw data download, if you have any questions, you can contact my mailbox wangzichaochaochao@gmail.com
#### Step3: Data preprocessing
```
python bin/data_manager.py
```
> It is currently recommended to use the run_multiple_relations_extraction_MSE_loss.py file instead of the run_multiple_relations_extraction.py file for model and forecasting!
#### Step4: Model training
Run_multiple_relations_extraction_mask_loss.py is recommended.
```
python run_multiple_relations_extraction.py \
--task_name=SKE_2019 \
--do_train=true \
--do_eval=false \
--data_dir=bin/standard_format_data \
--vocab_file=pretrained_model/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=pretrained_model/chinese_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=./output_model/multiple_relations_model/epochs3/
```
#### Step5: Model prediction
```
python run_multiple_relations_extraction.py \
--task_name=SKE_2019 \
--do_predict=true \
--data_dir=bin/standard_format_data \
--vocab_file=pretrained_model/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=output_model/multiple_relations_model/epochs3/model.ckpt-2000 \
--max_seq_length=128 \
--output_dir=./infer_out/multiple_relations_model/epochs3/ckpt2000
```
#### Step6: Generating Entities and Relational Files
```
python produce_submit_json_file.py
```
> You can use other strategies to generate the final entity relationship file for better results. I have written the template code for you (see produce_submit_json_file.py).
## Paper realization
This code is an unofficial implementation of [Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers](https://arxiv.org/abs/1902.01030) and [Joint entity recognition and relation extraction as a multi-head selection problem](https://arxiv.org/abs/1804.07847).