https://github.com/yuanzhoulvpi2017/rust4senvec
convert sentence to vector by nlp transformers model in Rust
https://github.com/yuanzhoulvpi2017/rust4senvec
bert nlp rust sentence-embeddings transformers-bert
Last synced: 12 months ago
JSON representation
convert sentence to vector by nlp transformers model in Rust
- Host: GitHub
- URL: https://github.com/yuanzhoulvpi2017/rust4senvec
- Owner: yuanzhoulvpi2017
- Created: 2022-12-22T01:31:08.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2023-01-07T10:53:31.000Z (over 3 years ago)
- Last Synced: 2024-11-08T00:23:24.261Z (over 1 year ago)
- Topics: bert, nlp, rust, sentence-embeddings, transformers-bert
- Language: Jupyter Notebook
- Homepage:
- Size: 21.5 KB
- Stars: 8
- Watchers: 3
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: readme.md
Awesome Lists containing this project
README
## 注意
运行的时候,要用:`cargo run --release`,而不是简单的`cargo run`
## 背景
sentence embedding,或者叫sentence2vector,本质上是将文本转换成向量。
之前做过sentence-transformers转onnx的,结合python的fastapi做推理的。之前还做过对sentence-transformers按照模型需求分开推理加速的。
[https://www.zhihu.com/question/424133076/answer/2292331019](https://www.zhihu.com/question/424133076/answer/2292331019)
[https://zhuanlan.zhihu.com/p/474396066](https://zhuanlan.zhihu.com/p/474396066)
但是这些其实都是基于python环境的,而且模型对外的web端,使用的是fastapi(这个包在python语言里面算是效率很高了,但是在所有的语言中,效率很低)。
对于线上的环境,我们总是希望在有限的硬件资源下,提高机器的使用率占比。
因此,很多人就会在使用C++语言来做推理。也有的会使用trition(好像是这么拼写的)结合网络层RPC来做对外的服务开放。
但是我不会C++、我不会RPC,我也不会trition,另外,我也不想将模型导出onnx(就是嫌弃麻烦),另外,我还嫌弃python慢、我还嫌弃fastapi慢。
那怎么办?
那么这里分享我的解决方法:使用rust来做句子转向量功能。
## 句子转向量的三个步骤
如果不太清楚,可以看看我这个回答:
[https://www.zhihu.com/question/510987022/answer/2778610483](https://www.zhihu.com/question/510987022/answer/2778610483)
### 1. 将文本通过tokenizer转换成`input_id`、`attention_mask`等
你如果对transfromers包很熟悉的话,你有没有注意到它的tokenizer里面有一个`fast_tokenizer=True`参数?
官网说,这个参数为True的时候,tokenizer会快一点。
其实本质上是因为,当使用`fast_tokenizer`的时候,python会调用rust版本的tokenizer来做推理。
而rust这种底层编程语言会比python快很多。
### 2. 将`input_id`、`attention_mask`放入我们的bert模型中获得`output`
其实就是放入bert模型中推理,计算得到`last_hidden_states`,`outputs`之类的。这个具体看源码即可,比如:
```python
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
```
但是如果下游任务不同,输出的肯定也是不一样的,就拿sentence embedding来说,最后返回的就是一个Tensor。(如果这步骤看不懂,可以看看我上面的链接)。
### 3. 将上面的`output`通过web端来返回给接口调用方
一般在python里面,大家都会使用fastapi、flask之类的,但是这个玩意和C++、rust语言的web库比起来,差远了。
就拿排行榜来说,fastapi排名249名,而C++、rust都在top10的水平。
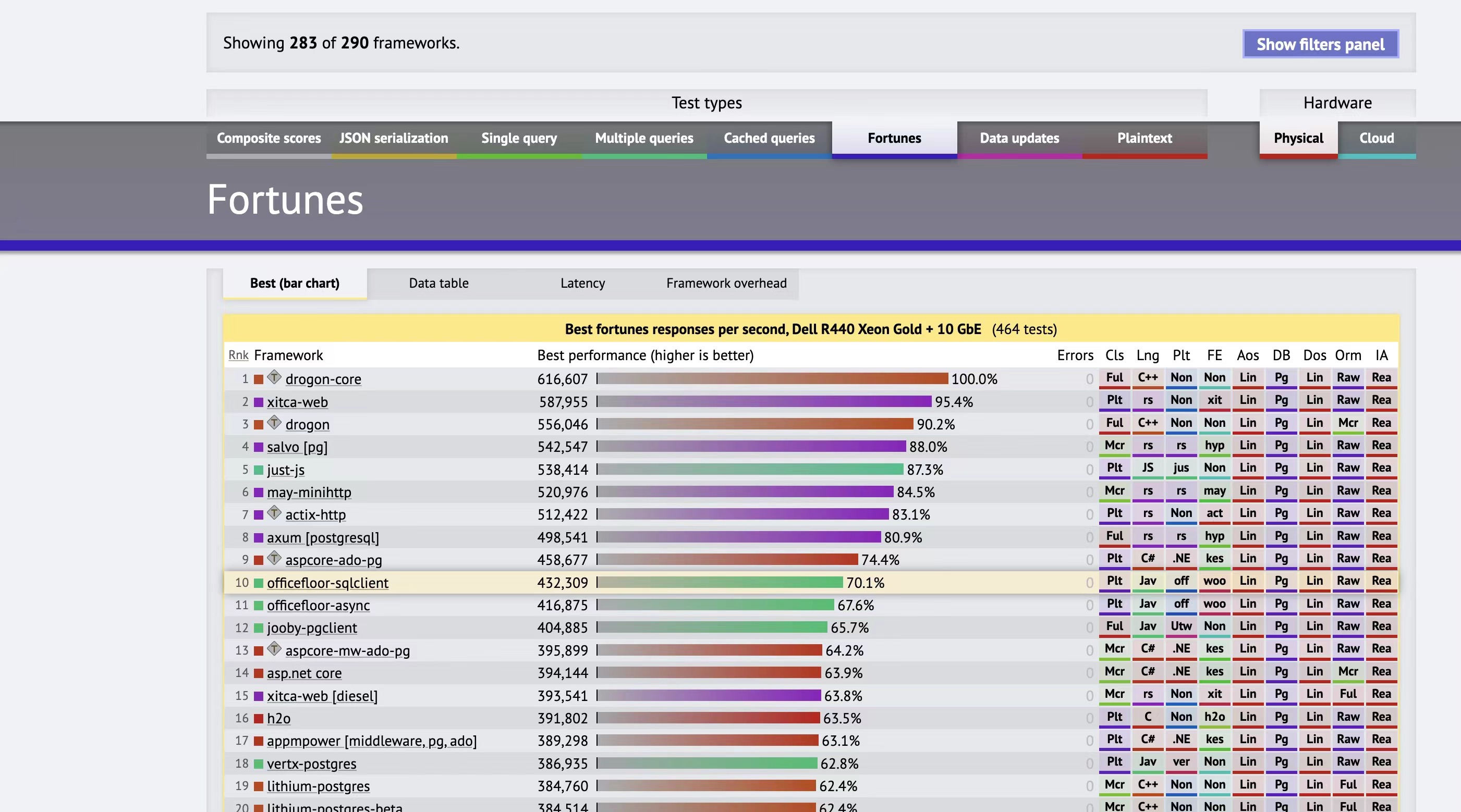
具体可以看这个链接,有详细的性能排行榜
[https://www.techempower.com/benchmarks/#section=data-r21](https://www.techempower.com/benchmarks/#section=data-r21)
## 小结
在上面三个步骤中,我们思考rust语言对应的解决办法。
1. 第一步的问题,通过`tokenizer`库来解决了。[https://docs.rs/tokenizers/latest/tokenizers/](https://docs.rs/tokenizers/latest/tokenizers/)
2. 第三步的问题,解决方法太多了。随便挑。
那么第二步里面的模型推理怎么解决?
其实已经有了,那就是`tch-rs`包可以来解决了。
# rust推理部分详解
## `tch-rs`包介绍
众所周知,pytorch是有C++版本的,pytorch也是有python版本的。而且pytorch本身就是C++写的。
那么`tch-rs`就可以理解成给rust语言写的pytorch。
## `jit` module
我们的pytorch训练完成之后,可以保存为`.bin`格式文件、也可保存为`.pt`、`.jit`格式的问题。
别的语言,只要拿到上面任意的格式文件,基本上都可以通过`torch::jit::Cmodule`模块进行加载。
那么rust也是可以的。
需要注意的是:rust的`tch-rs`模块加载模型的时候,你这个模型的输出只能为Tensor。不能为别的数据格式。(这个是重点)
## 使用python对模型 加载导出等
接下来主要是使用python来对模型进行加载,导入导出等功能。
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
from typing import Tuple, Optional, List
from torch import nn
from transformers import BertPreTrainedModel
```
### 1. 加载一个预训练模型bert
创建模型需要的tokneizer后的东西
```python
# step1 load bert model (such as tokenizer a text, and get tokens_tenosr, segements)
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
```
### 2. sentence2vector模型
这里随便写了一个文本转向量的模型。
`forward`返回的是一个Tensor,这个需要注意。
```python
# step2 costom my bert model
class Mybert4Sentence(BertPreTrainedModel):
# copy code from class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.Tensor:
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
return pooled_output
```
### 3. 把上面的模型,通过jit模式导出,并且保存
注意这里的`traced_bert.pt`模型的路径。后面在rust里面要用到。
```python
# step 3 load model and save model to .pt file
model2 = Mybert4Sentence.from_pretrained("bert-base-uncased", torchscript=True)
traced_model = torch.jit.trace(model2, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### 4. 再在python里面加载模型,看看输出的对不对
```python
# step 4 load .pt file then check it
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
loaded_model(*dummy_input).shape
loaded_model(*dummy_input)[:, :10]
```
到这里基本上python部分已经做完了。
接下来到rust部分。
## rust部分
### `tch-rs`依赖
`tch-rs`需要`libtorch`添加到环境变量中,具体的添加方式,可以看我之前的文章(或者`tch-rs`介绍)
[https://zhuanlan.zhihu.com/p/589055479](https://zhuanlan.zhihu.com/p/589055479)
与此同时,对应的项目创建等细节也都不需要再考虑。
直接到`src/main.rs`部分。
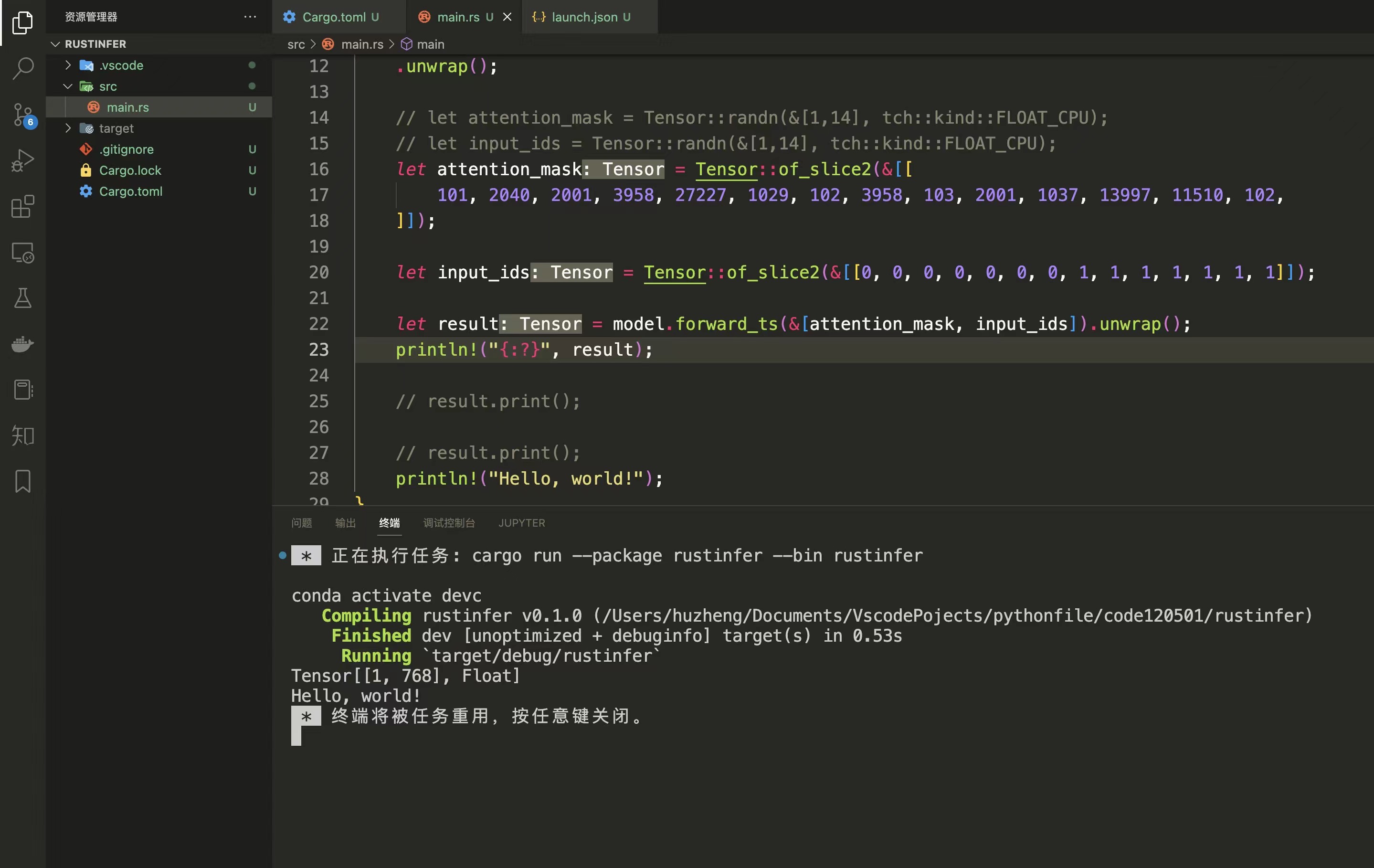
### 具体main.rs代码
这里需要注意`traced_bert.pt`的路径。
```rust
use tch::jit;
use tch::Tensor;
fn main() {
// load model which generate from `trans_model.py` file
let model = jit::CModule::load(
"./traced_bert.pt",
)
.unwrap();
// just generate a small attention_mask and input_ids
let attention_mask = Tensor::of_slice2(&[[
101, 2040, 2001, 3958, 27227, 1029, 102, 3958, 103, 2001, 1037, 13997, 11510, 102,
]]);
let input_ids = Tensor::of_slice2(&[[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]]);
// infer model by use `forward_ts` method
let result = model.forward_ts(&[attention_mask, input_ids]).unwrap();
// show the result
println!("{:?}", result);
result.slice(1, 0, 10, 1).print();
println!("Hello, world!");
```
最后跑通就会发现,计算的数值和python是一模一样的。
## 结束
到这里,基本上就结束了。剩下的各个部分,只需要像是拼积木一样搭建起来就可以了。一个完整的rust做sentence embedding就可以实现了。
# 最后
## rsut难么?
我感觉rust大部分代码其实写起来和python差不多,但是有些东西确实难,比如生命周期之类的。
但是我感觉网上很多算法工程师,其实python代码写的都坑坑巴巴的,如果用rust来做,估计是会要了他们老命。
因此,如果你连pytorch、transformers等优秀的包都不会用,还是别学rust了。
## 为什么不用rust-bert?
感觉rust-bert想做rust语言里面的transformers包(python的)。但是感觉路还能长,而且python版本的transformers用起来已经非常简单了。
不用rust-bert来做,是因为感觉rust-bert客制化程度还不够,而且感觉封装好多东西,太麻烦了。
## 上面的可以用在c++中么?
其实,python导出`.pt`文件,我觉得肯定是可以用在c++的libtorch里面的。
但是,tokenizer有C++版本的么?这个我不清楚,不太能回答。
## rust和C++比较?
这个真没办法比较,而且说出来很容易被一些Rust极端脑残粉攻击。只能说哪个好用用哪个~
# 更多
1. 具体细节都会定时更新,可以查看这个文章[https://zhuanlan.zhihu.com/p/589444069](https://zhuanlan.zhihu.com/p/589444069)
2. 或者直接关注我[https://www.zhihu.com/people/fa-fa-1-94](https://www.zhihu.com/people/fa-fa-1-94)