https://github.com/yunishi3/3D-FCR-alphaGAN
Fully Convolutional Refined Auto Encoding Generative Adversarial Networks for 3D Multi Object Scenes
https://github.com/yunishi3/3D-FCR-alphaGAN
Last synced: about 1 month ago
JSON representation
Fully Convolutional Refined Auto Encoding Generative Adversarial Networks for 3D Multi Object Scenes
- Host: GitHub
- URL: https://github.com/yunishi3/3D-FCR-alphaGAN
- Owner: yunishi3
- Created: 2017-08-26T01:28:26.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2019-01-17T14:45:10.000Z (over 6 years ago)
- Last Synced: 2024-11-03T09:33:31.039Z (6 months ago)
- Language: Python
- Homepage:
- Size: 22.3 MB
- Stars: 103
- Watchers: 9
- Forks: 33
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-gans-and-deepfakes - [github - multi-object-gan-7b7cee4abf80) (Applications using GANs / 3D Object generation)
- gans-awesome-applications - [github - multi-object-gan-7b7cee4abf80) (Applications using GANs / 3D Object generation)
README
# Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes
This repository contains the source code for Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes which is my work at Stanford AI Lab as a visiting scholar.
Special thanks to Christopher Choy and Prof. Silvio Savarese.

### Contents
0. [Introduction](##Introduction)
0. [Dataset](##Dataset)
0. [Models](##Models)
0. [Experiments](##Experiments)
0. [Evaluations](##Evaluations)
0. [Installation](##Installataion)
0. [References](##References)
## Introduction
The generative model utilizing Generative Adversarial Networks or Variational Auto-Encoder is one of the hottest topic in deep learning and computer vision. That doesn’t only enable high quality generation, but also has a lot of possibility for representation learning, feature extraction, and applications to some recognition tasks without supervision using probabilistic spaces and manifolds.
Especially 3D multi object generative models, which allow us to synthesize a variety of novel 3D multi objects and recognize the objects including shapes, objects and layouts, should be an extremely important tasks for AR/VR and graphics fields.
However, 3D generative models are still less developed. Basic generative models of only single objects are published as [1],[2]. But multi objects are not. Therefore I have tried end-to-end 3D multi object generative models using novel generative adversarial network architectures.
## Dataset
I used ground truth voxel data of SUNCG dataset. [3]
http://suncg.cs.princeton.edu/
I modified this dataset as follows.
- Downsized from 240x144x240 to 80x48x80.
- Got rid of trimming by camera angles.
- Chose the scenes that have over 10000 amount of voxels.
As a result, over 185K scenes were gathered which have 12 classes (empty, ceiling, floor, wall, window, chair, bed, sofa, table, tvs, furn, objs).

This dataset is extremely sparse which means around 92% voxels averagely in these scenes are empty class. In addition, this dataset has plenty of varieties such as living rooms, bathrooms, bedrooms, dining rooms, garages etc.
## Models
### Network Architecture
The network architecture of this work is fully convolutional refined auto-encoding generative adversarial networks. This is inspired by 3DGAN[1], alphaGAN[4] and SimGAN[5]. And fully convolutional layer and classifying multi objects are novel architectures as generative models.

This network combined a variational auto-encoder with generative adversarial networks. Also the KL divergence loss of variational auto-encoder is replaced with adversarial auto-encoder using code-discriminator as alphaGAN architectuires[4]. In addition, generated scenes are refined by refiner[5]. In this work, the shape of the latent space is 5x3x5x16 and this is calculated by fully convolutional layer. Fully convolution allows us to extract features more specifically like semantic segmentation tasks. As a result, fully convolution enables reconstruction performance to improve.
Adversarial auto-encoder allows us to loosen the constraint of distributions and treat this distribution as implicit. Also generator is trained to fool discriminator by generative adversarial network. As a result, this architecture enables reconstruction and generation performance to improve. In addition, refiner allows us to smooth the object shapes and put up shapes to be more realistic visually.

#### -Encoder
The basic architecture of encoder is similar to discriminator network of 3DGAN[1]. The difference is the last layer which is 1x1x1 fully convolution.
#### -Generator
The basic architecture of generator is also similar to 3DGAN[1] as above figure. The difference is the last layer which has 12 channels and is activated by softmax. Also, the first layer of latent space is flatten.
#### -Discriminator
The basic architecture of discriminator is also similar to 3DGAN[1]. The difference is the activation layers which are layer normalization.
#### -Code Discriminator
Code discriminator is same as alphaGAN[4] which has 2 hidden layers of 750 dimensions.

#### -Refiner
The basic architecrure of refiner is similar to SimGAN[5] which is composed with 4 Resnet blocks. The number of channels is 32 in order to decrease the memory charge.
### Loss Functions
* Reconstruction loss
&space;-\left(&space;1-\gamma&space;\right)&space;\left(&space;1-x\right)&space;\log&space;\left(&space;1-x_{rec}\right)&space;\right))
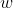 is occupancy normalized weights with every batch to weight the importance of small objects.
is occupancy normalized weights with every batch to weight the importance of small objects. 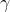 is a hyperparameter which weights the relative importance of false positives against false negatives.
is a hyperparameter which weights the relative importance of false positives against false negatives.
* GAN loss
&space;=-\log&space;\left(&space;D(x)&space;\right)&space;-\log&space;\left(&space;1-D(x_{rec})\right)&space;-\log&space;\left(&space;1-D(x_{gen})\right))
&space;=-\log&space;\left(&space;D(x_{rec})&space;\right)&space;-\log&space;\left(&space;D(x_{gen})&space;\right))
* Distribution GAN loss
&space;=-\log&space;\left(&space;D_{code}(z)&space;\right)&space;-\log&space;\left(&space;1-D_{code}(z_{enc})\right))
&space;=-\log&space;\left(&space;D_{code}(z_{enc})&space;\right))
### Optimization
* Encoder
&space;+\lambda&space;L_{rec}\right))
* Generator and Refiner
&space;\right))
* Discriminator
&space;\right))
* Code Discriminator
&space;\right))
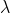 is a hyperparameter which weights the reconstruction loss.
is a hyperparameter which weights the reconstruction loss.
## Experiments
Adam optimizer was used for each of the architectures by learning rate 0.0001.
This network was trained for 75000 iterations except refiner in first, and then refiner was inserted and trained for more 25000 iterations. Batch size was 20 for first training of the base networks and 8 for second training of the refiner.
### Learning curves





### Visualization
#### -Reconstruction
Here are the results of reconstruction using encoder and generator and refiner.

Almost all voxels are reconstructed although small objects have disappeared. Also that shapes are refined by refiner. Numerical evaluations using IoU and mAP are described below.
#### -Generation from normal distribution
Here are the results of generation from normal distribution using generator and refiner.

As above figure, FCR-alphaGAN architecture worked better than standard fully convolutional VAE architecture. But this was not enough to represent realistic scene objects. This is assumed because the encoder was not generalized to the distribution, and the probabilistic space was extremely complicated because of the sparsity of the dataset. In order to solve this problem, the probabilistic space should be isolated to each object and layout.
### Reconstruction Performance
Here are the numerical evaluations of reconstruction performance.
#### -Intersection over Union(IoU)
IoU is defined as [6]. The bar chart describes IoU performances of each class. The line chart describes over-all IoU performances.


#### -mean Average Precision(mAP)
The bar chart and line chart describes same as IoU.


These results give the following considerations.
* Fully convolution enables reconstruction performance to improve even though the number of dimensions are the same.
* AlphaGAN architecture enables reconstruction performance to improve.
## Evaluations
### Interpolation
Here is the interpolation results. Gif image of interpolation is posted on the top of this document.

The latent space walkthrough gives smooth transitions between scenes.
### Interpretation of latent space
The charts below are the 2D represented mapping by SVD of 200 encoded samples. Gray scale gradations are followed to 1D embedding by SVD of centroid coordinates of each scene. Left is fully convolution, right is standard 1D latent vector of 1200 dimension.

The chart of fully convolution follows 1d embedding of centroid coordinates from lower right to upper left. This means fully convolution enables the latent space to be related to spatial contexts compared to standard VAE.
The figures below describe the effects of individual spatial dimensions composed of 5x3x5 as the latent space. The normal distribution noises were given on the individual dimension, and the level of change from original scene is represented by red colors.

This means each spatial dimension is related to generation of each positions by fully convolution.
## Suggestions of future work
#### -Revise the dataset
This dataset is extremely sparse and has plenty of varieties. Floors and small objects are allocated to huge varieties of positions, also some of the small parts like legs of chairs broke up in the dataset becouse of the downsizing. That makes predicting latent space too hard. Therefore, it is an important work to revise the dataset like limitting the varieties or adjusting the positions of objects.
#### -Redefine the latent space
In this work, I defined the latent space with one space which includes all information like shapes and positions of each object. Therefore, some small objects disappeared in the generated models, and a lot of non-realistic objects were generated. In order to solve that, it is an important work to redefine the latent space like isolating it to each object and layout. However, increasing the varieties of objects and taking account into multiple objects are required in that case.
## Installation
This package requires python2.7. If you don't have following prerequisites, you need to download them using pip, apt-get etc before downloading this repository.
Also at least 12GB GPU memory is required.
### Prerequisites
Following is my environment.
* Base
```
- tensorflow 1.12.0
- numpy 1.15.1
- easydict 1.9
```
* -Evaluation
```
- sklearn.metrics 0.19.2
```
* -Visualization
```
- vtk 8.1.2
```
### Download
* Download the repository and go to the directory.
`$ git clone https://github.com/yunishi3/3D-FCR-alphaGAN.git`
`$ cd 3D-FCR-alphaGAN`
* Download and unzip the dataset (It would be 57GB)
`$ wget http://yunishi.s3.amazonaws.com/3D_FCRaGAN/Scenevox.tar.gz`
`$ tar xfvz Scenevox.tar.gz`
### Training
`$ python main.py --mode train`
### Evaluation
If you want to use the pretrained model, you can download the checkpoint files with the following instructions.
* Download and unzip the pretrained checkpoint.
It contains checkpoint10000* as confirmation epoch = 10000.
`$ wget http://yunishi.s3.amazonaws.com/3D_FCRaGAN/Checkpt.tar.gz`
`$ tar xfvz Checkpt.tar.gz`
Or if you want to evaluate your trained model, you can replace confirmation epoch 10000 with another confirmation epoch which you want to confirm.
#### -Evaluate reconstruction performances from test data and make visualization files.
`$ python main.py --mode evaluate_recons --conf_epoch 10000`
After execute, you could get the following files in the eval directory.
- real.npy : Reference models which are chosen as test data.
- reons.npy : Reconstructed models before refine which are encoded and decoded from reference models.
- recons_refine.npy : Reconstrcuted models after refine.
- generate.npy : Generated models from normal distribution before refine.
- generate_refine.npy : Generated models after refine.
- AP(_refine).csv : mean average precision result of this reconstruction models.
- IoU(_refine).csv : Intersection over Union result of this reconstruction models.
#### -Evaluate the interpolation
`$ python main.py --mode evaluate_interpolate --conf_epoch 10000`
After execute, you could get interpolation files like above interpolation results. So many and heavy files would be built.
#### -Evaluate the effect of individual spatial dimensions
`$ python main.py --mode evaluate_noise --conf_epoch 10000`
After execute, you could get noise files like above interpretation of latent space results. So many and heavy files would be built.
### Visualization
In order to visualize the npy files built by evaluation process, you need to use python vtk. Please see the [7] to know the details of this code. I just modified original code to fit the 3D multi object scenes.
* Go to the eval directory.
`$ cd eval`
* Visualize all and save the png files.
`$ python screenshot.py ***.npy`
* Visualize only 1 file.
`$ python visualize.py ***.npy -i 1`
You can change the visualize model using index -i
## References
[1]Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum; Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling; arXiv:1610.07584v1
[2]Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston; Generative and Discriminative Voxel Modeling with Convolutional Neural Networks; arXiv:1608.04236v2
[3]Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser; Semantic Scene Completion from a Single Depth Image; arXiv:1611.08974v1
[4]Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, Shakir Mohamed; Variational Approaches for Auto-Encoding Generative Adversarial Networks; arXiv:1706.04987v1
[5]Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb; Learning from Simulated and Unsupervised Images through Adversarial Training; arXiv:1612.07828v1
[6]Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, Silvio Savarese; 3D-R2N2: A Unified Approach for Single and
Multi-view 3D Object Reconstruction; arXiv:1604.00449v1
[7]https://github.com/zck119/3dgan-release/tree/master/visualization/python