https://github.com/z-bool/Venom-Crawler
毒液爬行器:专为捡洞而生的爬虫神器
https://github.com/z-bool/Venom-Crawler
Last synced: 6 months ago
JSON representation
毒液爬行器:专为捡洞而生的爬虫神器
- Host: GitHub
- URL: https://github.com/z-bool/Venom-Crawler
- Owner: z-bool
- Created: 2023-07-04T00:06:08.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2023-08-17T06:40:19.000Z (over 2 years ago)
- Last Synced: 2024-09-11T03:43:54.831Z (over 1 year ago)
- Language: Go
- Homepage:
- Size: 29.7 MB
- Stars: 186
- Watchers: 4
- Forks: 25
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-hacking-lists - z-bool/Venom-Crawler - 毒液爬行器:专为捡洞而生的爬虫神器 (Go)
README
# Venom-Crawler - 为Venom-Transponder而生的爬虫神器
**郑重声明:文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用,任何人不得将其用于非法用途以及盈利等目的,否则后果自行承担** 。
由于katana不好使,2025.04重新更新


依赖安装
```bash
go mod tidy # go mod依赖加载
cd cmd
go build . #然后把cmd.exe重命名一下就好
```
使用说明
**不再缝合入Gospider原因**:
感觉Katana+Crawlergo的爬行结果以及足够全,再加入Gospider可能会造成时间的大量冗余,个人比较倾向于基于Chromium的爬行结果,参数可靠。
**其他说明**:
此项目目前只从爬虫角度解决URL爬取需求,个人觉得没必要缝合dirsearch,为了防止功能冗余,请配合dirseach使用,在后续开发的扫描器中才是发包量最大的(自动化Fuzz挖洞)。
**功能介绍:**
- 为了使爬虫爬行的URL尽可能全,所以使用Katana+Crawlergo的方法结合获取所有符合的URL,思路是:先由katana爬行,将爬行的最终结果交给Crawlergo再进行二次爬取,使其左脚踩右脚螺旋升天。
- 如果配置`-proxy` 将流量代理给被动环境监听的端口(比如:Venom-Transponder、Xray、w13scan等)
- 这里为了防止爬偏,爬行规则就是输入的URL路径,不会爬行其他域名以及子域名
- Katana和Crawlergo的结果都会单独保存在txt中,并且`result-all.txt` 是去重后的最终结果
```bash
-headless 是否让爬行时候headless结果可见
-chromium 如果在代码执行过程中报查询不到环境中的浏览器, 将Chrome或者Chromium路径填入即可
-headers 爬行要求带入的JSON字符串格式的自定义请求头,默认只有UA
-maxCrawler URL启动的任务最大的爬行个数,这个针对Crawlergo配置
-mode 爬行模式,simple/smart/strict,默认smart,如果simple模式katana不爬取JS解析的路径
-proxy 配置代理地址,支持扫描器、流量转发器、Burp、yakit等
-blackKey 黑名单关键词,用于避免被爬虫执行危险操作,用,分割,如:logout,delete,update
-url 执行爬行的单个URL
-urlTxtPath 如果需求是批量爬行URL,那需要将URL写入txt,然后放txt路径
-encodeUrlWithCharset 是否对URL进行编码,Crwalergo的功能但katana跑完的结果走Crawlergo后也会被编码
-depth 爬行深度,默认3
```
**不联动其他工具:**
```bash
.\Venom.exe -urlTxtPath .\text.txt
.\Vebom.exe -url https://www.sf-express.com
```
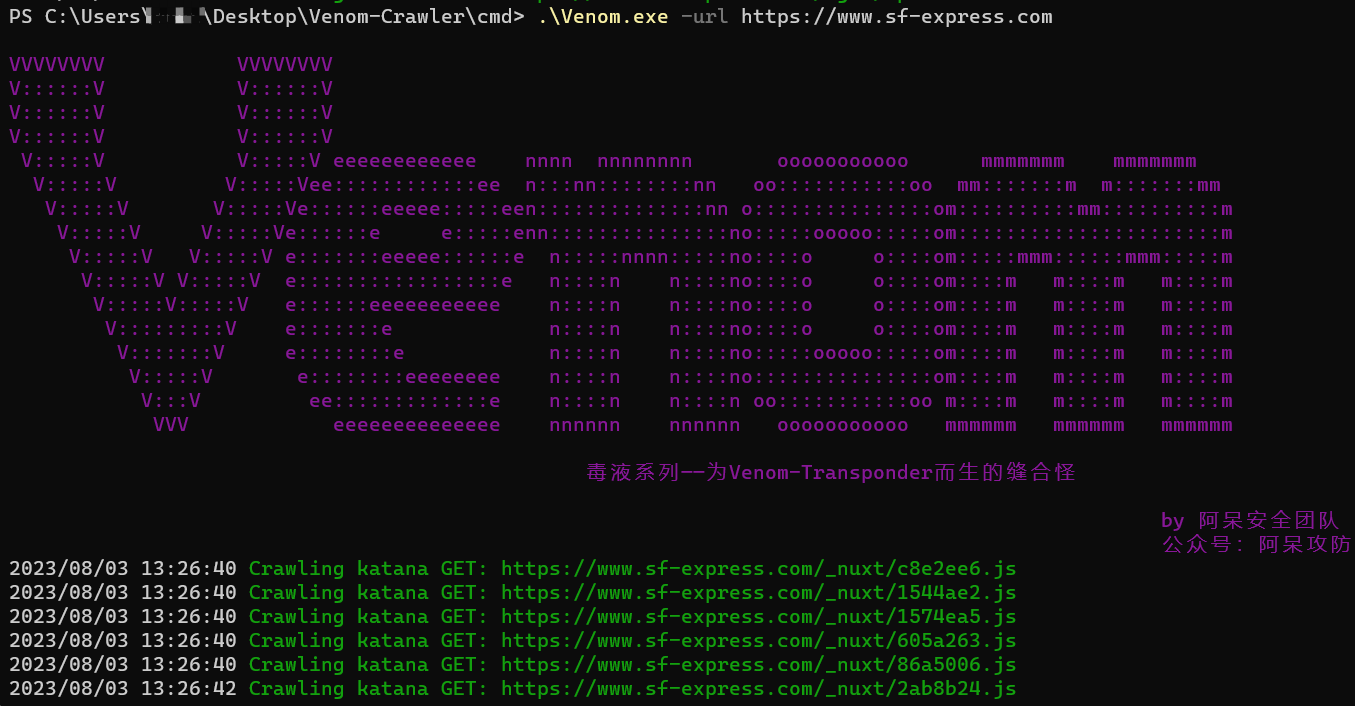
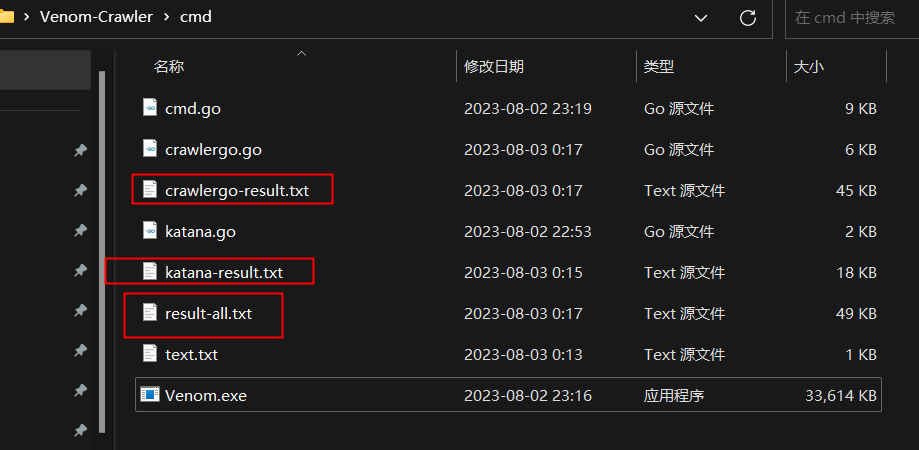
**联动其他工具:**
```bash
.\Venom.exe -urlTxtPath .\text.txt -proxy http://127.0.0.1:9090
.\Vebom.exe -url https://www.sf-express.com -proxy http://127.0.0.1:9090
```
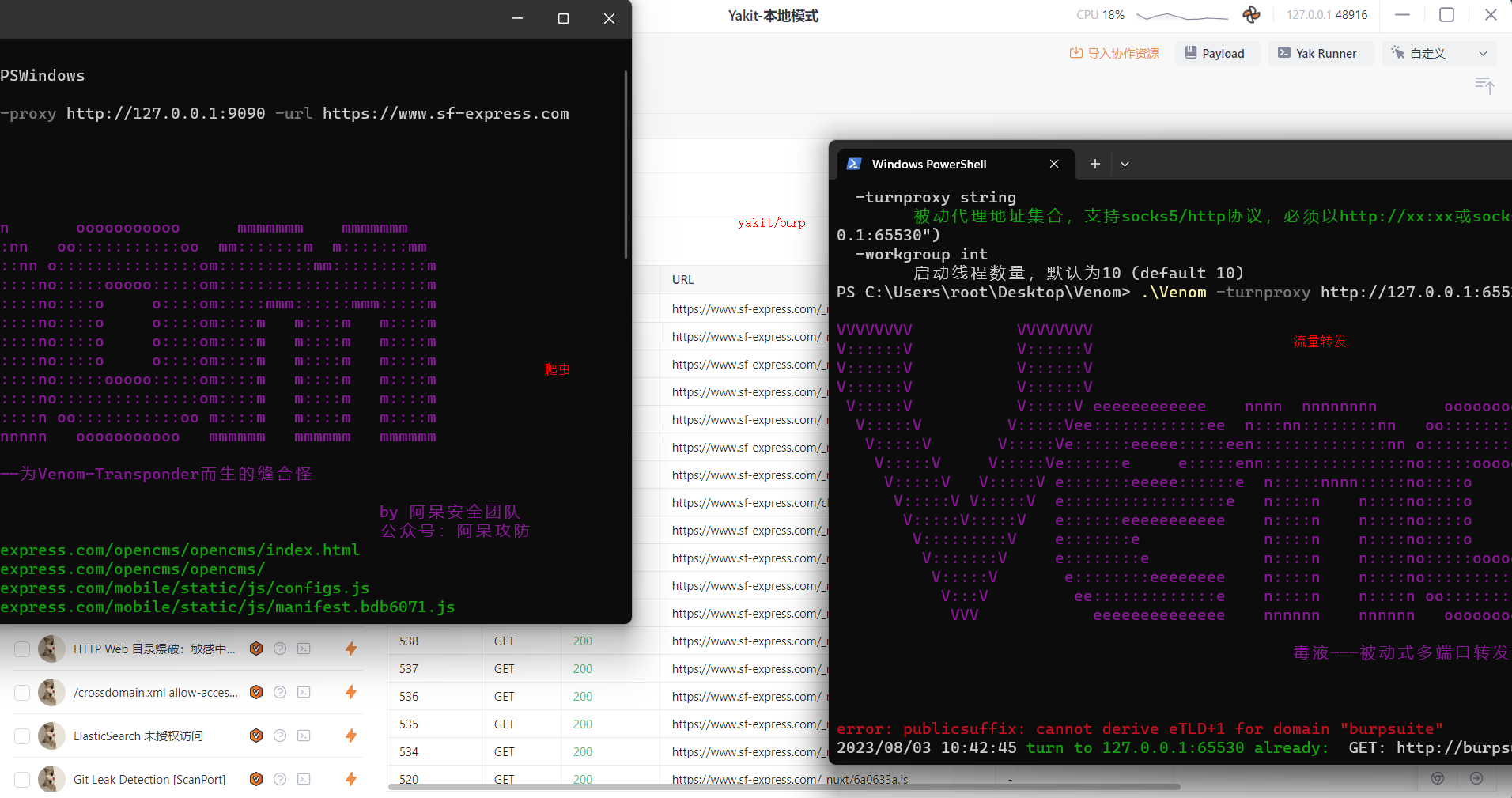
上图的使用思路将,爬虫爬取的URL通过Proxy代理转发给流量转发器,再由流量转发器转发给代理工具/漏扫。
如果想在爬取过程中查看爬行效果的话,可以在命令后面带上`-headless` 就会启动浏览器界面。
这还不开启捡洞模式???
注意事项
`浏览器上下文创建错误:exec: "google-chrome": executable file not found in %path%` :
说明浏览器没有安装或者`%path%` 环境里面没有chromium的地址(用edge/chrome/chromium都可以解决)。
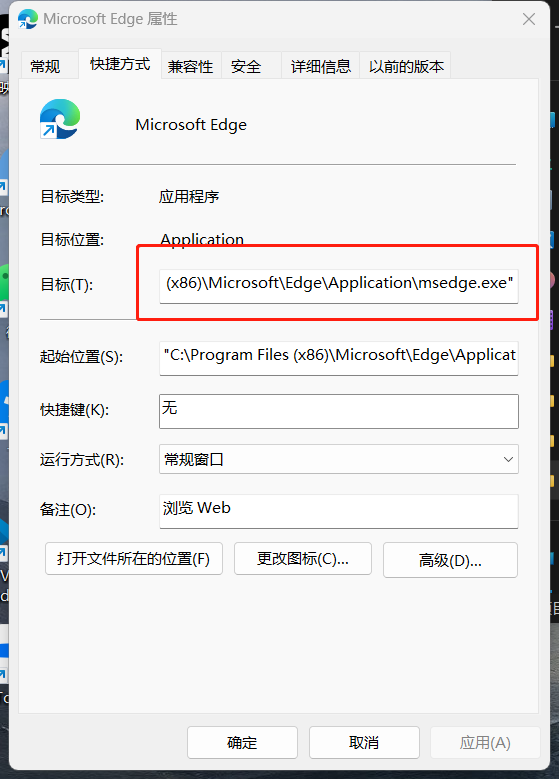
这里搭配`-chromium`参数即可。
技术交流
