https://github.com/zerodha/dungbeetle
A distributed job server built specifically for queuing and executing heavy SQL read jobs asynchronously. Separate out reporting layer from apps. MySQL, Postgres, ClickHouse.
https://github.com/zerodha/dungbeetle
broker-backend database job-queue job-scheduler mysql postgres postgresql reporting sql sql-query workers
Last synced: 7 months ago
JSON representation
A distributed job server built specifically for queuing and executing heavy SQL read jobs asynchronously. Separate out reporting layer from apps. MySQL, Postgres, ClickHouse.
- Host: GitHub
- URL: https://github.com/zerodha/dungbeetle
- Owner: zerodha
- License: mit
- Created: 2018-01-06T15:46:47.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2025-03-13T04:38:19.000Z (over 1 year ago)
- Last Synced: 2025-04-05T20:14:00.406Z (over 1 year ago)
- Topics: broker-backend, database, job-queue, job-scheduler, mysql, postgres, postgresql, reporting, sql, sql-query, workers
- Language: Go
- Homepage:
- Size: 8.72 MB
- Stars: 952
- Watchers: 17
- Forks: 141
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-clickhouse - zerodha/dungbeetle - DungBeetle is a distributed job server for asynchronously queuing and executing heavy SQL read jobs on MySQL, PostgreSQL, and ClickHouse databases, designed to offload report generation and improve application performance. (Language bindings / Golang)
README


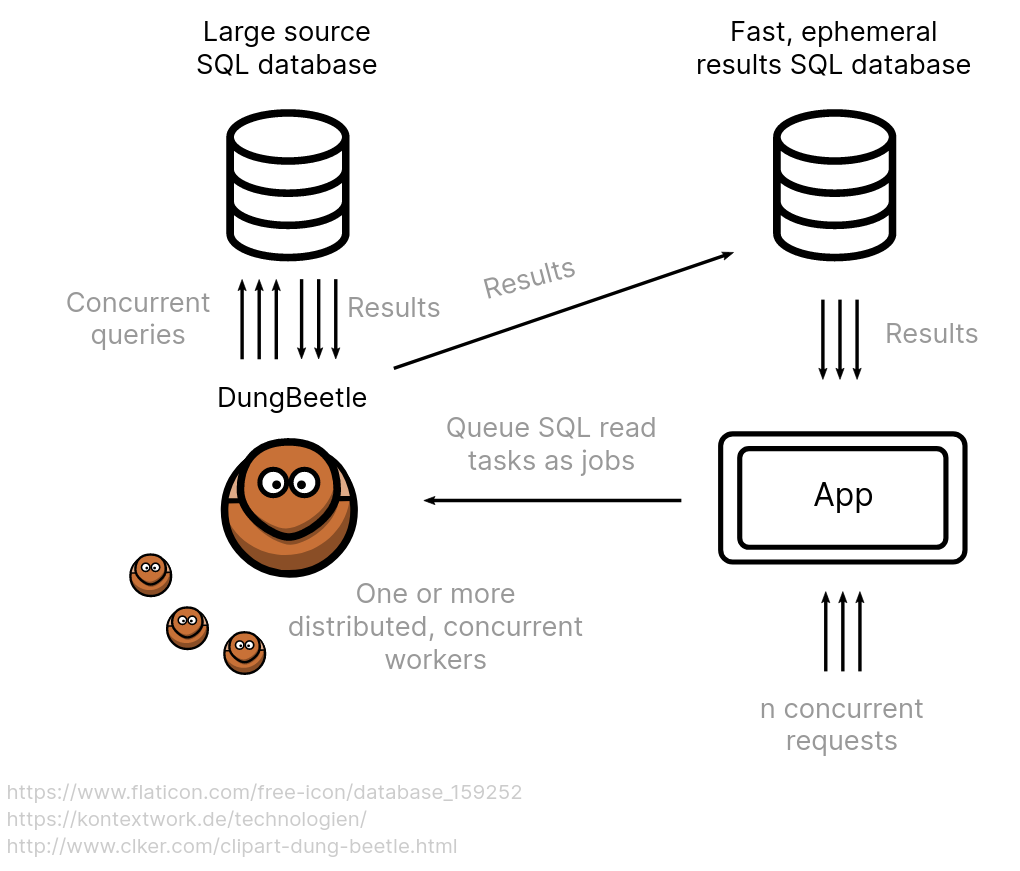
DungBeetle is a lightweight, single binary distributed job server designed for queuing and asynchronously executing large numbers of SQL read jobs (eg: reports) against SQL databases. When the read jobs are executed, the results are written to separate ephemeral results databases (where the results of every job is its own dedicated table), enabling faster retrieval.
A prominent usecase is user facing report generation in applications where requests can be queued and reports returned asynchronously without overloading large source databases.
## Features
- Supports MySQL, PostgreSQL, ClickHouse as source databases.
- Supports MySQL and PostgreSQL as result / cache databases for job results.
- Standalone server that exposes HTTP APIs for managing jobs and groups of jobs (list, post, status check, cancel jobs).
- Reads SQL queries from .sql files and registers them as jobs ready to be queued.
- Supports multi-process, multi-threaded, asynchronous distributed job queueing via a common broker backend (Redis, AMQP etc.)
## Usecase
Consider an application with a very large SQL database. When there are several thousand concurrent users requesting reports from an application connected to it, every second of I/O delay during query execution can bottleneck the application and the database, causing a snowball effect.
Instead, user requests for report generations can be deferred to a job queue in the backend, there by immediately freeing up the frontend application. The reports are presented to users as they're executed (frontend polls the job's status and prevents the user from sending any more queries). DungBeetle server and worker instances also act as traffic control and prevent the primary database from being indundated with requests.
Once the reports are generated (SQL queries finish executing), it's natural for users to further transform the results by slicing, sorting, and filtering, generating additional queries to the primary database. To offset this load, these subsequent queries can be sent to the smaller, much faster results cache database. These results are of course ephemeral and can be thrown away or expired.
## Concepts
#### Task
A task is a named SQL query that is loaded into the server on startup. Tasks are defined in .sql files in the simple [goyesql](https://github.com/knadh/goyesql) format. Such queries are self-contained and produce the desired final output with neatly named columns. They can take arbitrary positional arguments for execution. A task can be attached to one or more specific databases defined in the configuration using the `-- db:` tag. In case of multiple databases, the query will be executed against a random one from the list, unless a specific database is specified in the API request (`db`). A `-- queue:` tag to always route the task to a particular queue, unless it's overriden by the `queue` param when making a job request. A `-- results:` tag specifies the results backend to which the results of a task will be written. If there are multiple result backends specified, the results are written a random one.
Example:
```sql
-- queries.sql
-- name: get_profit_summary
SELECT SUM(amount) AS total, entry_date FROM entries WHERE user_id = ? GROUP BY entry_date;
-- name: get_profit_entries
-- db: db0, other_db
-- queue: myqueue
-- results: my_res_db
SELECT * FROM entries WHERE user_id = ?;
-- name: get_profit_entries_by_date
SELECT * FROM entries WHERE user_id = ? AND timestamp > ? and timestamp < ?;
-- name: get_profit_entries_by_date
-- raw: 1
-- This query will not be prepared (raw=1)
SELECT * FROM entries WHERE user_id = ? AND timestamp > ? and timestamp < ?;
```
Here, when the server starts, the queries `get_profit_summary` and `get_profit_entries` are registered automatically as tasks. Internally, the server validates and prepares these SQL statements (unless `raw: 1`). `?` are MySQL value placholders. For Postgres, the placeholders are `$1, $2 ...`
#### Job
A job is an instance of a task that has been queued to run. Each job has an ID that can be used to track its status. If an ID is not passed explicitly, it is generated internally and returned. These IDs need not be unique, but only a single job with a certain ID can run at any given point. For the next job with the same ID to be scheduled, the previous job has to finish execution. Using non-unique IDs like this is useful in cases where users can be prevented from sending multiple requests for the same reports, like in our usecases.
An application polls with the job ID to check if results are ready for consumption.
#### Results
The results from an SQL query job are written to a result backend (MySQL or Postgres) from where they can be further read or queried. This is configured in the configuration file. The results from a job are written to a new table named after that job, where schema of the results table is automatically generated from the results of the original SQL query. All fields are transformed into one of these types `BIGINT, DECIMAL, TIMESTAMP, DATE, BOOLEAN, TEXT`.
## Installation
A pre-compiled binary can be downloaded from the [releases](https://github.com/zerodha/dungbeetle/releases) page.
### 2) Configure
Copy the `config.toml.sample` file as `config.toml` somewhere and edit the configuration values.
### 3) Setup tasks
Write your SQL query tasks in `.sql` files in the `goyesql` format (as shown in the examples earlier) and put them in a directory somewhere.
### 4) Start the server
```shell
dungbeetle --config /path/to/config.toml --sql-directory /path/to/your/sql/queries
# Run 'dungbeetle --help' to see all supported arguments
```
Starting the server runs a set of workers listening on a default job queue. It also starts an HTTP service on `http://127.0.0.1:6060` which is the control interface. It's possible to run the server without the HTTP interface by passing the `--worker-only` flag.
### Usage
| Method | URI | |
|--------|------------------------|-------------------------------------------------|
| GET | /tasks | Returns the list of registered SQL tasks |
| POST | /tasks/{taskName}/jobs | Schedules a job for a given task |
| GET | /jobs/{jobID} | Returns the status of a given job |
| GET | /jobs/queue/{queue} | Returns the list of all pending jobs in a queue |
| POST | /groups | Schedule a group of jobs |
| GET | /groups/{groupID} | Get the status of a job group and its jobs |
| DELETE | /jobs/{jobID} | Deletes a pending job from the queue and immediately cancels its execution and frees the thread. Send a query param "purge=true" to delete completed jobs. Only the Go PostgreSQL driver cancels queries mid execution. MySQL server will keep continuing to execute the query. For MySQL, it's important to set `max_execution_time`. |
| DELETE | /groups/{groupID} | Deletes a pending job from the queue and immediately cancels its execution and frees the thread. Send a query param "purge=true" to delete completed jobs. Only the Go PostgreSQL driver cancels queries mid execution. MySQL server will keep continuing to execute the query. For MySQL, it's important to set `max_execution_time` |
POST requests accept raw JSON bodies. The JSON params are listed below.
| Job param | | |
|---------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---|
| `job_id` *string* | (Optional) Alphanumeric ID for the job. Can be non-unique. If this is not passed, the server generates and returns one | |
| `queue` *string* | (Optional) Queue to send the job to. Only workers listening on this queue will receive the jobs. | |
| `eta` *string* | (Optional) Timestamp (`yyyy-mm-dd hh:mm:ss`) at which the job should start. If this is not provided, the job is queued immediately. | |
| `retries` *int* | (Optional) The number of times a failed job should be retried. Default is 0 | |
| ~~`ttl`~~ *int* | (Optional) TTL for the results in the results backend for this particular job. This is NOT supported by the default SQL DB result backend | |
| `args[]` *[]string* | (Optional) The positional argument to pass to the SQL query in the task being executed. This can be passed multiple times, one for each argument | |
| Group param | | |
|---------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---|
| `group_id` *string* | (Optional) Alphanumeric ID for the group of jobs. Can be non-unique. If this is not passed, the server generates and returns one | |
| `concurrency` *int* | (Optional) Number of jobs to run concurrently in the group
##### Schedule a job
```shell
$ curl localhost:6060/tasks/get_profit_entries_by_date/jobs -H "Content-Type: application/json" -X POST --data '{"job_id": "myjob", "args": ["USER1", "2017-12-01", "2017-01-01"]}'
{"status":"success","data":{"job_id":"myjob","task_name":"get_profit_entries_by_date","queue":"sqljob_queue","eta":null,"retries":0}}
```
##### Schedule a group of jobs
Sometimes, it's necessary to schedule a group of jobs and perform an action once they're all complete. Group jobs here run concurrently and independent of each other. The group state can be polled to figure out if all the jobs in it have finished executing.
```shell
$ curl localhost:6060/groups -H "Content-Type: application/json" -X POST --data '{"group_id": "mygroup", "concurrency": 3, "jobs": [{"job_id": "myjob", "task": "get_profit_entries_by_date", "args": ["USER1", "2017-12-01", "2017-01-01"]}, {"job_id": "myjob2", "task": "get_profit_entries_by_date", "args": ["USER1", "2017-12-01", "2017-01-01"]}]'
{"status":"success","data":{"group_id":"mygroup","jobs":[{"job_id":"myjob","task":"test1","queue":"sqljob_queue","eta":null,"retries":0},{"job_id":"myjob2","task":"test2","queue":"sqljob_queue","eta":null,"retries":0}]}}
```
##### Check a job's status
```shell
$ curl localhost:6060/jobs/myjob
{"status":"success","data":{"job_id":"myjob","status":"SUCCESS","results":[{"Type":"int64","Value":2}],"error":""}}~
# `Results` indicates the number of rows generated by the query.
```
## Advanced usage
### Multiple queues, workers, and job distribution
It's possible to run multiple workers on one or more machines that run different jobs with different concurrency levels independently of each other using different queues. Not all of these instances need to expose the HTTP service and can run as `--worker-only`. This doesn't really make a difference as long as all instances connect to the same broker backend. A job posted to any instance will be routed correctly to the right instances based on the `queue` parameter.
Often times, different queries have different priorities of execution. Some may need to return results faster than others. The below example shows two DungBeetle servers being run, one with 30 workers and one with just 5 to process jobs of different priorities.
```shell
# Run the primary worker + HTTP control interface
dungbeetle --config /path/to/config.toml --sql-directory /path/to/sql/dir \
--queue "high_priority" \
--worker-name "high_priority_worker" \
--worker-concurrency 30
# Run another worker on a different queue to handle low priority jobs
dungbeetle --config /path/to/config.toml --sql-directory /path/to/sql/dir \
--queue "low_priority" \
--worker-name "low_priority_worker" \
--worker-concurrency 5 \
--worker-only
# Send a job to the high priority queue.
$ curl localhost:6060/tasks/get_profit_entries_by_date/jobs -H "Content-Type: application/json" --data '{"job_id": "myjob", "queue": "high_priority", "args": ["USER1", "2017-12-01", "2017-01-01"]}'
# Send another job to the low priority queue.
$ curl localhost:6060/tasks/get_profit_entries_by_date/jobs -H "Content-Type: application/json" --data '{"job_id": "myjob", "queue": "low_priority"}'
```
## Go API client
`github.com/zerodha/dungbeetle/client` package can be used as a Go HTTP API client for DungBeetle.
## License
Licensed under the MIT License.