https://github.com/zhiningliu1998/bat
[ICML'24] BAT: 🚀 Boost Class-imbalanced Node Classification with <10 lines of Code | 从拓扑视角出发10行代码改善类别不平衡节点分类
https://github.com/zhiningliu1998/bat
data-augmentation graph-algorithms graph-machine-learning graph-mining imbalanced-data imbalanced-learning machine-learning node-classification
Last synced: about 1 year ago
JSON representation
[ICML'24] BAT: 🚀 Boost Class-imbalanced Node Classification with <10 lines of Code | 从拓扑视角出发10行代码改善类别不平衡节点分类
- Host: GitHub
- URL: https://github.com/zhiningliu1998/bat
- Owner: ZhiningLiu1998
- License: mit
- Created: 2024-05-07T23:09:53.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2024-11-27T22:27:59.000Z (over 1 year ago)
- Last Synced: 2025-05-05T21:13:11.366Z (about 1 year ago)
- Topics: data-augmentation, graph-algorithms, graph-machine-learning, graph-mining, imbalanced-data, imbalanced-learning, machine-learning, node-classification
- Language: Python
- Homepage:
- Size: 122 KB
- Stars: 25
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
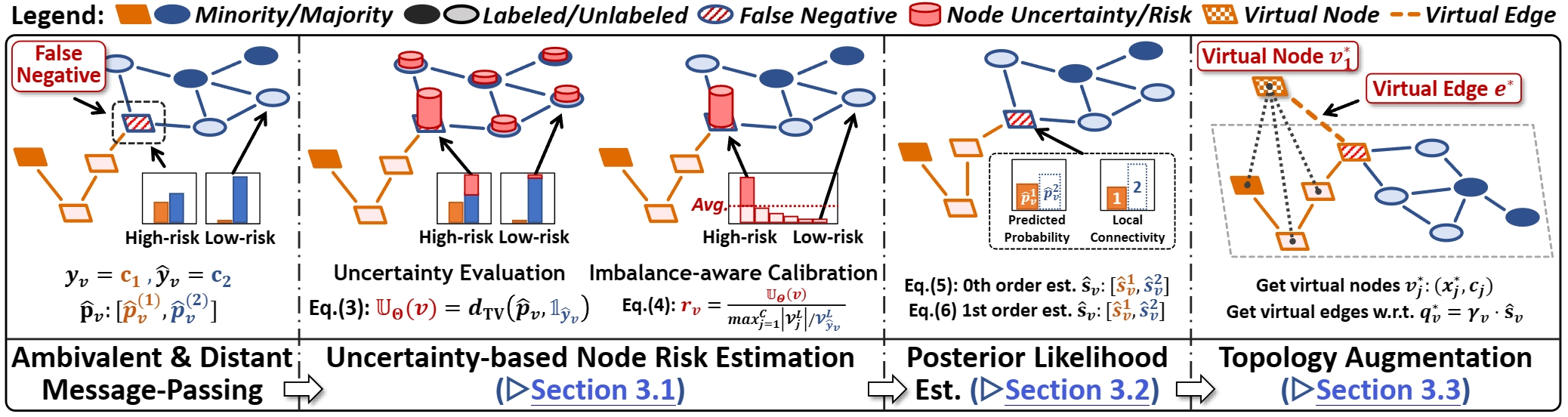





BAT: BAlanced Topological augmentation
"Class-Imbalanced Graph Learning without Class Rebalancing" [ICML'24]
Links: [arXiv] [PDF]
🦇 **BAT** (BAlanced Topological augmentation) is a **lightweight, plug-and-play** augmentation technique for **class-imbalanced node classification**. It mitigates the **class-imbalance bias** introduced by ambivalent and distant message-passing on graph topology with PURE topological manipulation.
Being model-agnostic and orthogonal to class-balancing techniques (e.g., reweighting/resampling), 🦇 **BAT** can be seamlessly integrated with various GNN architectures and BOOST regular class-balancing-based imbalance-handling methods.
### 🌈 **BAT Key Features:**
- 📈 **Scalability**: Linear complexity w.r.t. number of nodes/edges.
- 🔌 **Plug-and-play**: Directly integrates into the training loop with ~10 lines of code.
- 🚀 **Performance**: Up to 46.27% performance boosting and 72.74% predictive bias reduction.
- 🪐 **Versatility**: Work with various GNN backbones ON TOP OF other imbalance-handling techniques.
- 🧑💻 **Ease-of-use**: Unified, concise, and extensible API design. No additional hyperparameter.
### ✂️ **Intergrate [`BatAugmenter`](https://github.com/ZhiningLiu1998/BAT/blob/main/bat.py#L170) (BAT) into your training loop with <10 lines of code:**
```python
from bat import BatAugmenter
augmenter = BatAugmenter().init_with_data(data) # Initialize with graph data
for epoch in range(epochs):
# Augmentation
x, edge_index, _ = augmenter.augment(model, x, edge_index)
y, train_mask = augmenter.adapt_labels_and_train_mask(y, train_mask)
# Original training code
model.update(x, y, edge_index, train_mask)
```
### 🤗 Citing BAT
We appreciate your citation if you find our work helpful!🍻 BibTeX entry:
```bibtex
@misc{liu2024classimbalanced,
title={Class-Imbalanced Graph Learning without Class Rebalancing},
author={Zhining Liu and Ruizhong Qiu and Zhichen Zeng and Hyunsik Yoo and David Zhou and Zhe Xu and Yada Zhu and Kommy Weldemariam and Jingrui He and Hanghang Tong},
year={2024},
eprint={2308.14181},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Usage Example](#usage-example)
- [Python Scripts](#python-scripts)
- [Jupyter Notebook](#jupyter-notebook)
- [Combining BAT with other CIGL baselines](#combining-bat-with-other-cigl-baselines)
- [API reference](#api-reference)
- [class: `BatAugmenter`](#class-bataugmenter)
- [Parameters](#parameters)
- [Methods](#methods)
- [class: `NodeClassificationTrainer`](#class-nodeclassificationtrainer)
- [Methods](#methods-1)
- [Emprical Results](#emprical-results)
- [Experimental Setup](#experimental-setup)
- [BAT brings significant and universal performance BOOST](#bat-brings-significant-and-universal-performance-boost)
- [BAT is robust to extreme class-imbalance](#bat-is-robust-to-extreme-class-imbalance)
- [References](#references)
## Usage Example
### Python Scripts
[`train.py`](https://github.com/ZhiningLiu1998/BAT/blob/main/train.py) provides a simple way to test BAT under different settings: datasets, imbalance types, imbalance ratios, GNN architectures, etc. For example, to test BAT's effectiveness on the Cora dataset with a 10:1 step imbalance ratio using the GCN architecture, simply run:
```bash
python train.py --dataset cora --imb_type step --imb_ratio 10 --gnn_arch GCN --bat_mode all
```
Example Output:
```
================= Dataset [Cora] - StepIR [10] - BAT [dummy] =================
Best Epoch: 97 | train/val/test | ACC: 100.0/67.20/67.50 | BACC: 100.0/61.93/60.55 | MACRO-F1: 100.0/59.65/59.29 | upd/aug time: 4.67/0.00ms | node/edge ratio: 100.00/100.00%
Best Epoch: 67 | train/val/test | ACC: 100.0/65.20/65.00 | BACC: 100.0/60.04/57.70 | MACRO-F1: 100.0/57.21/55.09 | upd/aug time: 3.36/0.00ms | node/edge ratio: 100.00/100.00%
Best Epoch: 131 | train/val/test | ACC: 100.0/66.80/67.90 | BACC: 100.0/63.78/61.71 | MACRO-F1: 100.0/62.26/60.08 | upd/aug time: 3.37/0.00ms | node/edge ratio: 100.00/100.00%
Best Epoch: 60 | train/val/test | ACC: 100.0/66.40/66.30 | BACC: 100.0/61.60/60.74 | MACRO-F1: 100.0/58.04/59.09 | upd/aug time: 3.34/0.00ms | node/edge ratio: 100.00/100.00%
Best Epoch: 151 | train/val/test | ACC: 100.0/63.40/63.70 | BACC: 100.0/58.00/55.99 | MACRO-F1: 100.0/53.57/51.88 | upd/aug time: 3.19/0.00ms | node/edge ratio: 100.00/100.00%
Avg Test Performance (5 runs): | ACC: 66.08 ± 0.70 | BACC: 59.34 ± 0.96 | MACRO-F1: 57.09 ± 1.40
================== Dataset [Cora] - StepIR [10] - BAT [bat1] ==================
Best Epoch: 72 | train/val/test | ACC: 100.0/72.00/72.20 | BACC: 100.0/69.65/68.93 | MACRO-F1: 100.0/66.88/67.10 | upd/aug time: 3.12/4.10ms | node/edge ratio: 100.26/101.43%
Best Epoch: 263 | train/val/test | ACC: 100.0/72.80/71.70 | BACC: 100.0/72.59/69.01 | MACRO-F1: 100.0/72.05/68.70 | upd/aug time: 3.51/4.10ms | node/edge ratio: 100.26/101.75%
Best Epoch: 186 | train/val/test | ACC: 100.0/74.00/73.70 | BACC: 100.0/74.37/73.10 | MACRO-F1: 100.0/71.61/71.04 | upd/aug time: 3.36/4.15ms | node/edge ratio: 100.26/101.56%
Best Epoch: 71 | train/val/test | ACC: 100.0/72.40/72.10 | BACC: 100.0/69.50/67.75 | MACRO-F1: 100.0/68.11/66.80 | upd/aug time: 3.31/4.12ms | node/edge ratio: 100.26/101.55%
Best Epoch: 77 | train/val/test | ACC: 100.0/76.20/77.60 | BACC: 100.0/78.03/77.92 | MACRO-F1: 100.0/75.06/76.42 | upd/aug time: 3.34/4.10ms | node/edge ratio: 100.26/101.58%
Avg Test Performance (5 runs): | ACC: 73.46 ± 0.97 | BACC: 71.34 ± 1.68 | MACRO-F1: 70.01 ± 1.58
```
We can observe great performance gain brought about by BAT:
| Metric | Accuracy | Balanced Accuracy | Macro-F1 Score |
| ------- | -------- | ----------------- | -------------- |
| w/o BAT | 66.08 | 59.34 | 57.09 |
| w/ BAT | 73.46 | 71.34 | 70.01 |
| Gain | +7.38 | +12.00 | +12.92 |
Full argument list of [`train.py`](https://github.com/ZhiningLiu1998/BAT/blob/main/train.py) and descriptions are as follows:
```
--gpu_id | int, default=0
Specify which GPU to use for training. Set to -1 to use the CPU.
--seed | int, default=42
Random seed for reproducibility in training.
--n_runs | int, default=5
The number of independent runs for training.
--debug | bool, default=False
Enable debug mode if set to True.
--dataset | str, default="cora"
Name of the dataset to use for training.
Supports "cora," "citeseer," "pubmed," "cs", "physics".
--imb_type | str, default="step", choices=["step", "natural"]
Type of imbalance to handle in the dataset. Choose from "step" or "natural".
--imb_ratio | int, default=10
Imbalance ratio for handling imbalanced datasets.
--gnn_arch | str, default="GCN", choices=["GCN", "GAT", "SAGE"]
Graph neural network architecture to use. Choose from "GCN," "GAT," or "SAGE."
--n_layer | int, default=3
The number of layers in the GNN architecture.
--hid_dim | int, default=256
Hidden dimension size for the GNN layers.
--lr | float, default=0.01
Initial learning rate for training.
--weight_decay | float, default=5e-4
Weight decay for regularization during training.
--epochs | int, default=2000
The number of training epochs.
--early_stop | int, default=200
Patience for early stopping during training.
--tqdm | bool, default=False
Enable a tqdm progress bar during training if set to True.
--bat_mode | str, default="all", choices=["dummy", "pred", "topo", "all"]
Mode of the BAT. Choose from "dummy," "pred," "topo," or "all."
if "dummy," BAT is disabled.
if "pred," BAT is enabled with only prediction-based augmentation.
if "topo," BAT is enabled with only topology-based augmentation.
if "all," will run all modes and report the result for comparison.
```
### Jupyter Notebook
We also provide an example jupyter notebook [train_example.ipynb](https://github.com/ZhiningLiu1998/BAT/blob/main/train_example.ipynb) with more experimental results on:
- 3 Datasets: ['cora', 'citeseer', 'pubmed']
- 3 BAT modes: ['dummy', 'pred', 'topo']
- 4 Imbalance type-rate combinations:
- 'step': [10, 20]
- 'natural': [50, 100]
### Combining BAT with other CIGL baselines
We developed the experiment code that combine BAT and CIGL techniques based on the official implementation of [GraphENS](https://github.com/JoonHyung-Park/GraphENS) and [GraphSMOTE](https://github.com/TianxiangZhao/GraphSmote). The code is available in the `dev` folder, and the main script is [`experiment_example.ipynb`](https://github.com/ZhiningLiu1998/BAT/blob/main/dev/experiment_example.ipynb).
Note: due to the tightly coupled implementation design of many baselines, it would take much effort to decouple them and integrate BAT with different baselines with a clean and concise API. There is much room for improvement in the code design. Please use the dev code as a reference to integrate BAT with other CIGL baselines, and all kinds of feedback are welcome.
## API reference
### class: `BatAugmenter`
https://github.com/ZhiningLiu1998/BAT/blob/main/bat.py#L170
Main class that implements the BAT augmentation algorithm, inheriting from [`BaseGraphAugmenter`](https://github.com/ZhiningLiu1998/BAT/blob/main/bat.py#L11).
```python
class BatAugmenter(BaseGraphAugmenter):
"""
Balanced Topological (BAT) augmentation for graph data.
Parameters:
- mode: str, optional (default: "bat1")
The augmentation mode. Must be one of ["dummy", "bat0", "bat1"].
- 'dummy': no augmentation.
- 'bat0': BAT with 0th order posterior likelihood estimation, linear to #nodes.
- 'bat1': BAT with 1st order posterior likelihood estimation, linear to #edges
and generally performs better (recommended).
- random_state: int or None, optional (default: None)
Random seed for reproducibility.
"""
```
#### Parameters
- `mode`: str, optional (default: "bat1")
- The augmentation mode. Must be one of ["dummy", "bat0", "bat1"].
- 'dummy': no augmentation.
- 'bat0': BAT with 0th order posterior likelihood estimation, linear to #nodes.
- 'bat1': BAT with 1st order posterior likelihood estimation, linear to #edges and generally performs better (recommended).
- `random_state`: int or None, optional (default: None)
- Random seed for reproducibility.
#### Methods
- `init_with_data(data)`: initialize the augmenter with graph data.
- Parameters:
- `data` : PyG data object. Expected attributes: `x`, `edge_index`, `y`, `train_mask`, `val_mask`, `test_mask`.
- Return:
- `self` : TopoBalanceAugmenter
- `augment(model, x, edge_index)`: perform topology-aware graph augmentation.
- Parameters:
- `model` : torch.nn.Module, node classification model
- `x` : torch.Tensor, node feature matrix
- `edge_index` : torch.Tensor, sparse edge index
- Return:
- `x_aug` : torch.Tensor, augmented node feature matrix
- `edge_index_aug`: torch.Tensor, augmented sparse edge index
- `info` : dict, augmentation info
- `adapt_labels_and_train_mask(y, train_mask)`: adapt labels and training mask after augmentation.
- Parameters:
- `y` : torch.Tensor, node label vector
- `train_mask` : torch.Tensor, training mask
- Return:
- `new_y` : torch.Tensor, adapted node label vector
- `new_train_mask` : torch.Tensor, adapted training mask
### class: `NodeClassificationTrainer`
https://github.com/ZhiningLiu1998/BAT/blob/main/trainer.py#L14
Trainer class for node classification tasks, centralizing the training workflow:
- (1) model preparation and selection
- (2) performance evaluation
- (3) BAT data augmentation
- (4) verbose logging.
```python
class NodeClassificationTrainer:
"""
A trainer class for node classification with Graph Augmenter.
Parameters:
-----------
- model: torch.nn.Module
The node classification model.
- data: pyg.data.Data
PyTorch Geometric data object containing graph data.
- device: str or torch.device
Device to use for computations (e.g., 'cuda' or 'cpu').
- augmenter: BaseGraphAugmenter, optional
Graph augmentation strategy.
- learning_rate: float, optional
Learning rate for optimization.
- weight_decay: float, optional
Weight decay (L2 penalty) for optimization.
- train_epoch: int, optional
Number of training epochs.
- early_stop_patience: int, optional
Number of epochs with no improvement to trigger early stopping.
- eval_freq: int, optional
Frequency of evaluation during training.
- eval_metrics: dict, optional
Dictionary of evaluation metrics and associated functions.
- verbose_freq: int, optional
Frequency of verbose logging.
- verbose_config: dict, optional
Configuration for verbose logging.
- save_model_dir: str, optional
Directory to save model checkpoints.
- save_model_name: str, optional
Name of the saved model checkpoint.
- enable_tqdm: bool, optional
Whether to enable tqdm progress bar.
- random_state: int, optional
Seed for random number generator.
"""
```
#### Methods
- `train`: train the node classification model and perform evaluation.
- Parameters:
- `train_epoch`: int, optional. Number of training epochs.
- `eval_freq`: int, optional. Frequency of evaluation during training.
- `verbose_freq`: int, optional. Frequency of verbose logging.
- Return:
- `model`: torch.nn.Module, trained node classification model.
- `print_best_results`: print the evaluation results of the best model.
## Emprical Results
### Experimental Setup
To fully validate **BAT**'s performance and compatibility with existing (graph) imbalance-handling techniques and GNN backbones, we test 6 imbalance-handling methods with 5 popular GNN backbone architectures in our experiments, and apply BAT with them under all possible combinations:
- **Datasets**: Cora, Citeseer, Pubmed, CS, Physics
- **Imbalance-handling techniques**:
- Reweighting [1]
- ReNode [2]
- Oversample [3]
- SMOTE [4]
- GraphSMOTE [5]
- GraphENS [6]
- **GNN backbones**:
- GCN [7]
- GAT [8]
- SAGE [9]
- APPNP [10]
- GPRGNN [11]
- **Imbalance types & ratios**:
- **Step imbalance**: 10:1, 20:1
- **Natural imbalance**: 50:1, 100:1
For more details on the experimental setup, please refer to our paper: https://arxiv.org/abs/2308.14181.
### BAT brings significant and universal performance BOOST
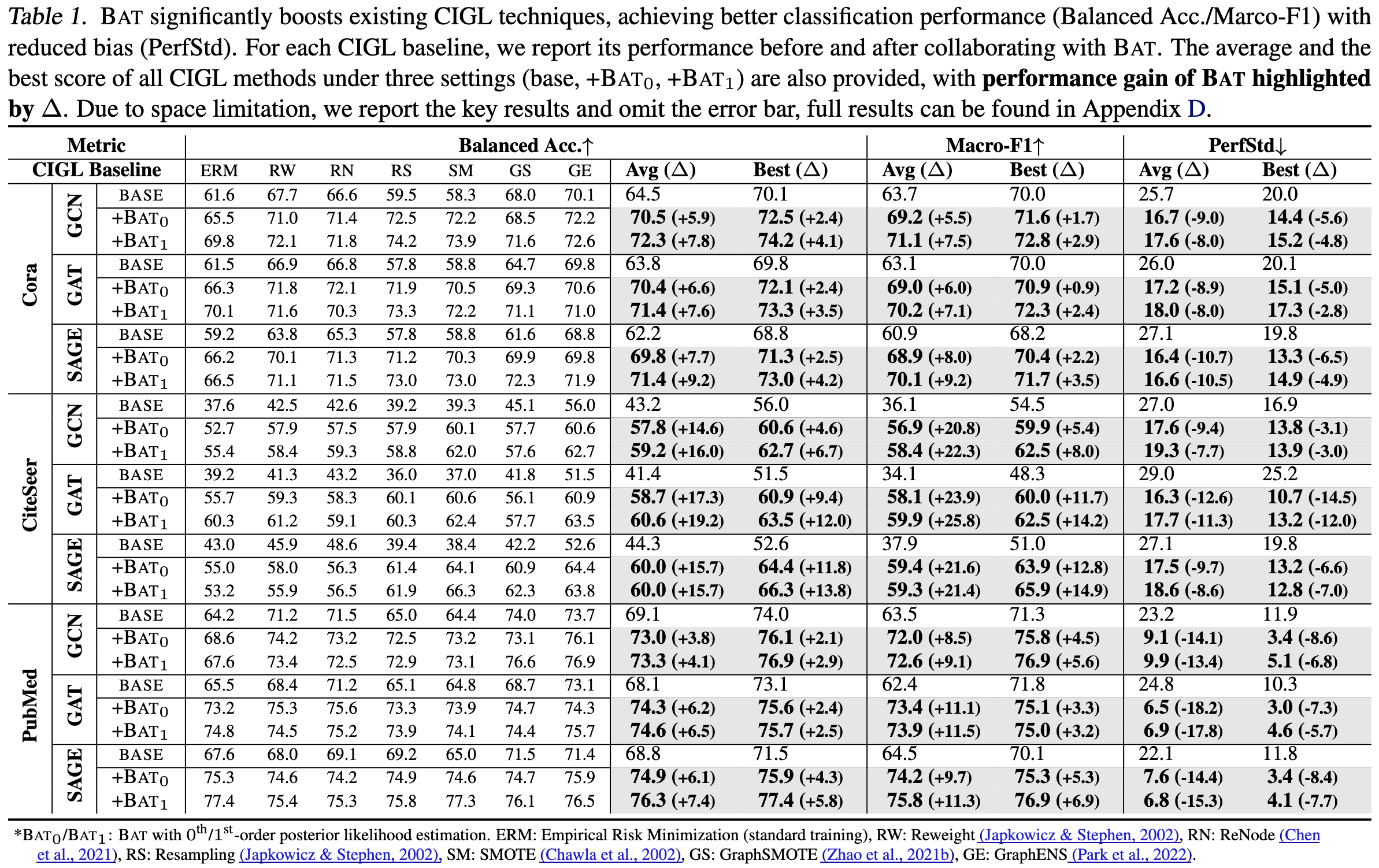
We first report the detailed empirical results of applying **BAT** with 6 IGL baselines and 5 GNN backbones on 3 imbalanced graphs (Cora, CiteSeer, and PubMed) with IR=10 in Table 1. We highlight the improvement brought about by BAT to the average/best test performane of the 6 IGL baselines.
Results show that **BAT brought significant and universal performance boost** to all IGL baselines and GNN backbones. In addition to the superior performance in classification, **BAT** also greatly reduces the model predictive bias.
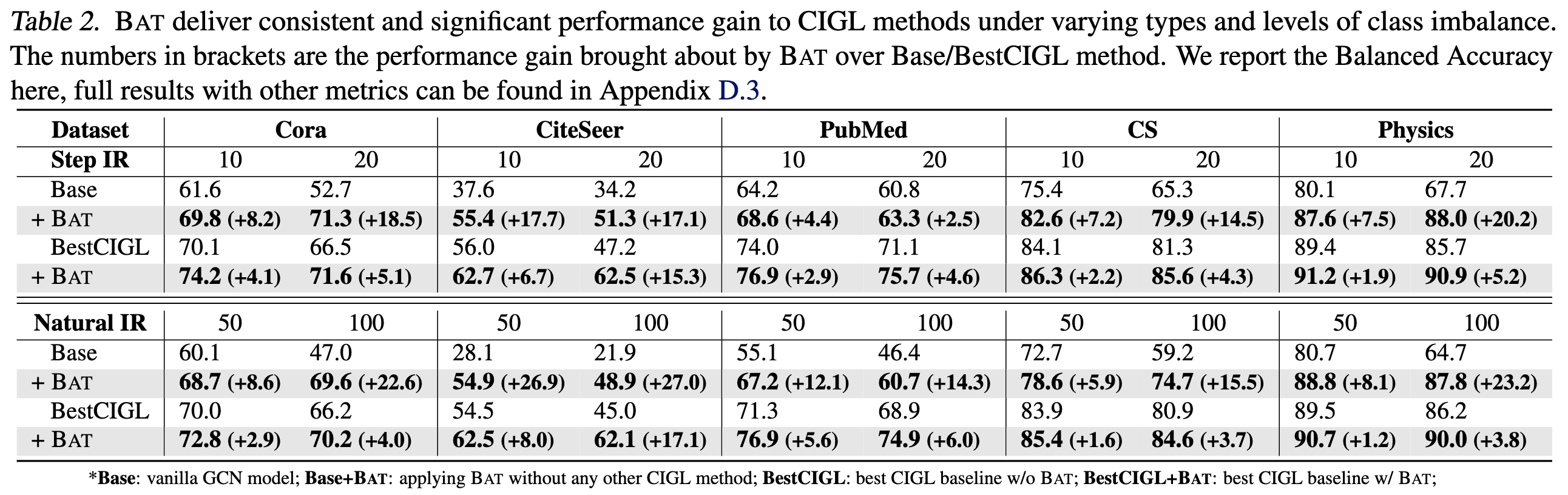
### BAT is robust to extreme class-imbalance
We now test **BAT**'s robustness to varying types of extreme class-imbalance. In this experiment, we consider a more challenging scenario with IR = 20, as well as the natural (long-tail) class imbalance that is commonly observed in real-world graphs with IR of 50 and 100. Datasets from (*CS, Physics*) are also included to test **BAT**'s performance on large-scale tasks. Results show that **BAT** consistently demonstrates superior performance in boosting classification and reducing predictive bias.
Please refer to our paper: https://arxiv.org/abs/2308.14181 for more details.
## References
| # | Reference |
| ---- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| [1] | Nathalie Japkowicz and Shaju Stephen. The class imbalance problem: A systematic study. Intelligent data analysis, 6(5):429–449, 2002. |
| [2] | Deli Chen, Yankai Lin, Guangxiang Zhao, Xuancheng Ren, Peng Li, Jie Zhou, and Xu Sun. Topology-imbalance learning for semi-supervised node classification. Advances in Neural Information Processing Systems, 34:29885–29897, 2021. |
| [3] | Nathalie Japkowicz and Shaju Stephen. The class imbalance problem: A systematic study. Intelligent data analysis, 6(5):429–449, 2002. |
| [4] | Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002. |
| [5] | Tianxiang Zhao, Xiang Zhang, and Suhang Wang. Graphsmote: Imbalanced node classification on graphs with graph neural networks. In Proceedings of the 14th ACM international conference on web search and data mining, pages 833–841, 2021. |
| [6] | Joonhyung Park, Jaeyun Song, and Eunho Yang. Graphens: Neighbor-aware ego network synthesis for class-imbalanced node classification. In International Conference on Learning Representations, 2022. |
| [7] | Max Welling and Thomas N Kipf. Semi-supervised classification with graph convolutional networks. In J. International Conference on Learning Representations (ICLR 2017), 2016. |
| [8] | Petar Veliˇckovi ́c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018. |
| [9] | Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017. |
| [10] | Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv preprint arXiv:1810.05997, 2018. |
| [11] | Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. Adaptive universal generalized pagerank graph neural network. arXiv preprint arXiv:2006.07988, 2020. |