https://github.com/zhuzilin/np_ml
A tool library of classical machine learning algorithms with only numpy.
https://github.com/zhuzilin/np_ml
machine-learning numpy python
Last synced: about 1 year ago
JSON representation
A tool library of classical machine learning algorithms with only numpy.
- Host: GitHub
- URL: https://github.com/zhuzilin/np_ml
- Owner: zhuzilin
- License: mit
- Created: 2018-03-17T08:45:10.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2021-03-03T01:46:11.000Z (over 5 years ago)
- Last Synced: 2025-05-08T21:17:38.685Z (about 1 year ago)
- Topics: machine-learning, numpy, python
- Language: Python
- Homepage:
- Size: 1.24 MB
- Stars: 223
- Watchers: 12
- Forks: 69
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# NP_ML
## Introduction
Classical machine learning algorithms implemented with pure numpy.
The repo to help you understand the ml algorithms instead of blindly using APIs.
## Directory
- [Introduction](#introduction)
- [Directory](#directory)
- [Algorithm list](#algorithm-list)
- [Classify](#classify)
- Perceptron
- K Nearest Neightbor (KNN)
- Naive Bayes
- Decision Tree
- Random Forest
- SVM
- AdaBoost
- HMM
- [Cluster](#cluster)
- KMeans
- Affinity Propagation
- [Manifold Learning](#manifold-learning)
- PCA
- Locally-linear-embedding (LLE)
- [NLP](#nlp)
- LDA
- [Time Series Analysis](#time-series-analysis)
- AR
- [Usage](#usage)
- Installation
- Examples for *Statistical Learning Method*(《统计学习方法》)
- [Reference](#reference)
## Algorithm List
### Classify
- Perceptron
For perceptron, the example used the [UCI/iris dataset](https://archive.ics.uci.edu/ml/datasets/iris). Since the basic perceptron is a binary classifier, the example used the data for versicolor and virginica. Also, since the iris dataset is not linear separable, the result may vary much.


Figure: versicolor and virginica. Hard to distinguish... Right?
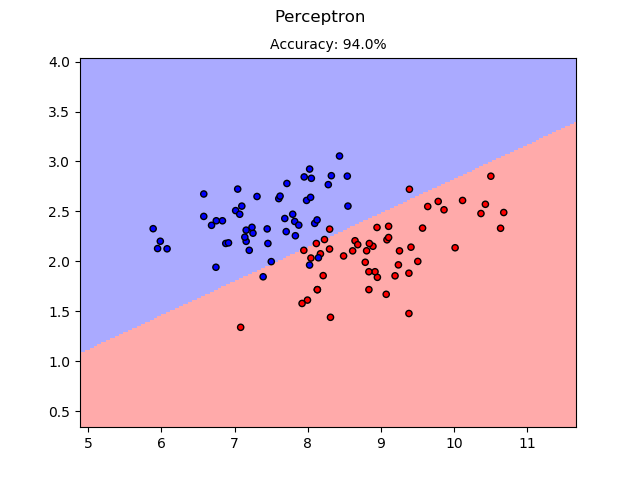
Perceptron result on the Iris dataset.
- K Nearest Neightbor (KNN)
For KNN, the example also used the UCI/iris dataset.
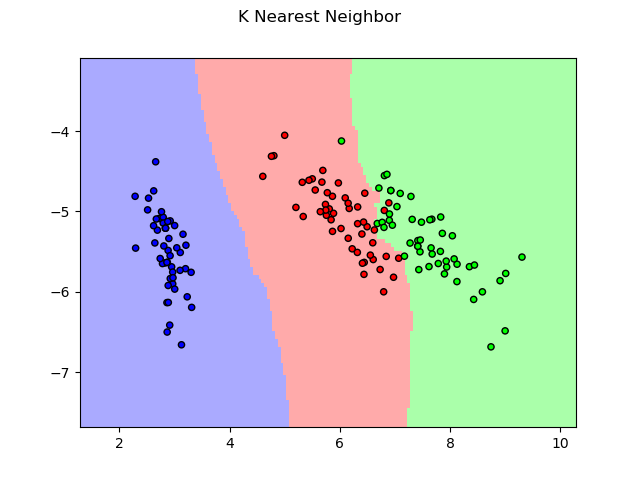
KNN result on the Iris dataset.
- Naive Bayes
For naive bayes, the example used the [UCI/SMS Spam Collection Dataset](https://www.kaggle.com/uciml/sms-spam-collection-dataset) to do spam filtering.
For this example only, for tokenizing, nltk is used. And the result is listed below:
```
preprocessing data...
100%|#####################################################################| 5572/5572 [00:00<00:00, 8656.12it/s]
finish preprocessing data.
100%|#####################################################################| 1115/1115 [00:00<00:00, 55528.96it/s]
accuracy: 0.9757847533632287
```
We got 97.6% accuracy! That's nice!
And we try two examples, a typical ham and a typical spam. The result show as following.
```
example ham:
Po de :-):):-):-):-). No need job aha.
predict result:
ham
example spam:
u r a winner U ave been specially selected 2 receive 澹1000 cash or a 4* holiday (flights inc) speak to a
live operator 2 claim 0871277810710p/min (18 )
predict result:
spam
```
- Decision Tree
For decision tree, the example used the UCI/tic-tac-toe dataset. The input is the status of 9 block and the result is whether x win.

tic tac toe.
Here, we use ID3 and CART to generate a one layer tree.
For the ID3, we have:
```
root
├── 4 == b : True
├── 4 == o : False
└── 4 == x : True
accuracy = 0.385
```
And for CART, we have:
```
root
├── 4 == o : False
└── 4 != o : True
accuracy = 0.718
```
In both of them, feature_4 is the status of the center block. We could find out that **the center block matters!!!** And in ID3, the tree has to give a result for 'b', which causes the low accuracy.
- Random Forest
- SVM
- AdaBoost
- HMM
For kmeans, we use the [make_blob()](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_blobs.html#sklearn.datasets.make_blobs) function in sklearn to produce toy dataset.
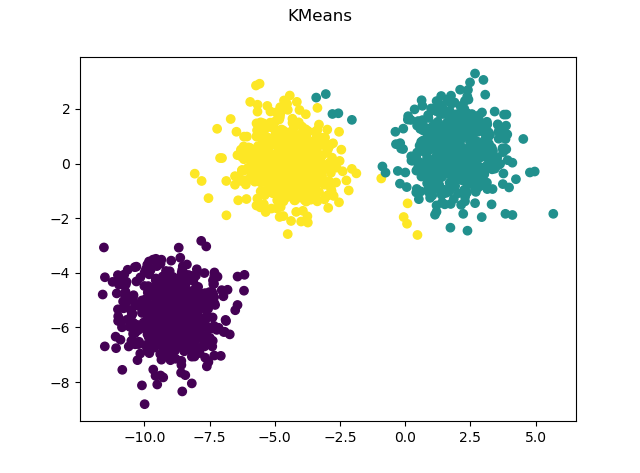
Kmeans result on the blob dataset.
- Affinity Propagation
You can think affinity propagation as an cluster algorithm that generate cluster number automatically.
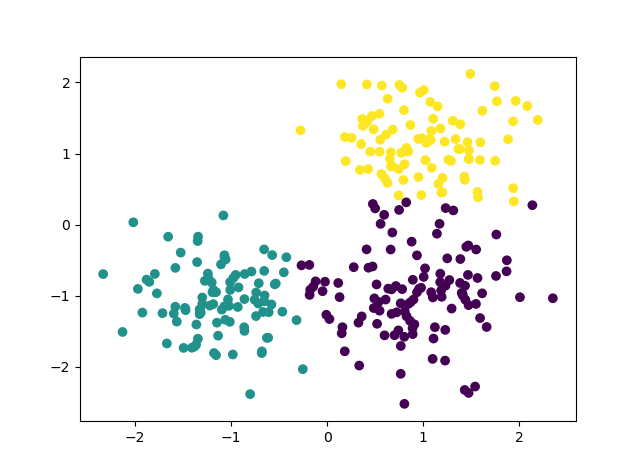
Kmeans result on the blob dataset.
### Manifold Learning
In manifold learning, we all use the simple curve-s data to show the difference between algorithms.
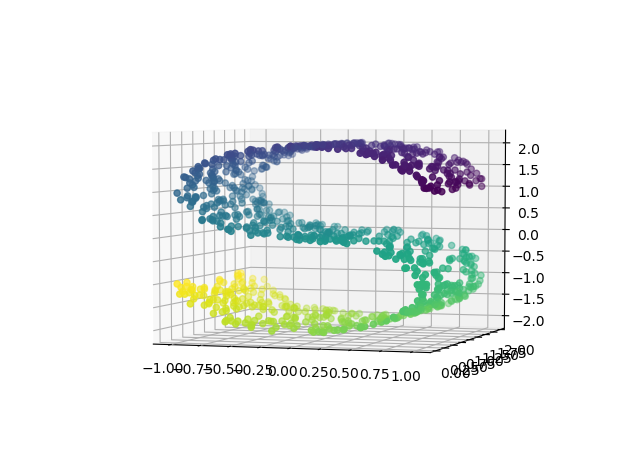
Curve S data.
- PCA
The most popular way to reduce dimension.
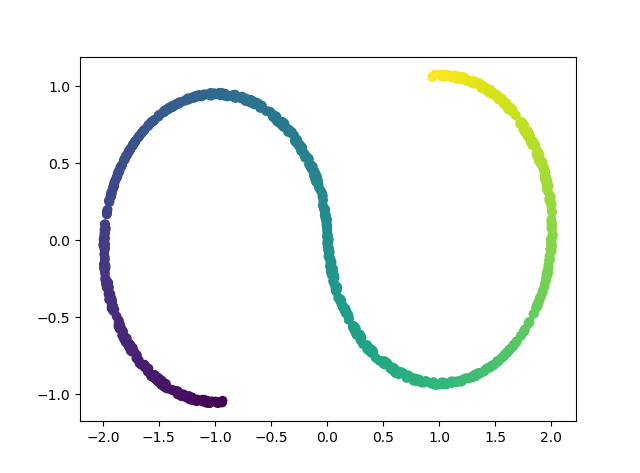
PCA visualization.
- LLE
A manifold learning method using only local information.
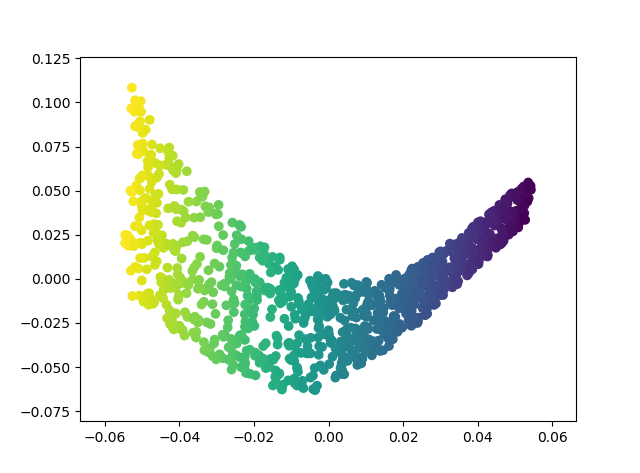
LLE visualization.
### NLP
- LDA
### Time Series Analysis
- AR
If you want to use the visual example, please install the package by:
```
$ git clone https://github.com/zhuzilin/NP_ML
$ cd NP_ML
$ python setup.py install
```
- Examples in section "Algorithm List"
Run the script in NP_ML/example/ . For example:
```
$ cd example/
$ python affinity_propagation.py
```
(Mac/Linux user may face some issue with the data directory. Please change them in the correspondent script).
- Examples for *Statistical Learning Method*(《统计学习方法》)
Run the script in NP_ML/example/StatisticalLearningMethod/ .For example:
```
$ cd example/StatisticalLearningMethod
$ python adaboost.py
```
## Reference
Classical ML algorithms was validated by naive examples in [*Statistical Learning Method*(《统计学习方法》)](https://www.amazon.com/%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95%EF%BC%88%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95-%E7%BB%9F%E8%AE%A1%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86-%E7%AC%AC2%E7%89%88-%E5%85%B12%E6%9C%AC%E5%A5%97%E8%A3%85%EF%BC%89-Chinese-ebook/dp/B01M8KB8FF/ref=sr_1_1?ie=UTF8&qid=1521303280&sr=8-1&keywords=%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95)
Time series models was validated by example in [Bus 41202](http://faculty.chicagobooth.edu/ruey.tsay/teaching/bs41202/sp2017/)
## Something Else
Currently, this repo will only implement algorithms that do not need gradient descent. Those would be arranged in another repo in which I would implement those using framework like pytorch. Coming soon:)