https://github.com/zjrwtx/preference_databuilder
大模型RLHF(ppo奖励模型)训练偏好数据排序助手(支持ollama本地模型)
https://github.com/zjrwtx/preference_databuilder
Last synced: 5 months ago
JSON representation
大模型RLHF(ppo奖励模型)训练偏好数据排序助手(支持ollama本地模型)
- Host: GitHub
- URL: https://github.com/zjrwtx/preference_databuilder
- Owner: zjrwtx
- Created: 2024-05-01T14:09:05.000Z (about 1 year ago)
- Default Branch: main
- Last Pushed: 2024-05-04T10:25:27.000Z (about 1 year ago)
- Last Synced: 2024-05-05T10:23:36.373Z (about 1 year ago)
- Language: Python
- Homepage:
- Size: 63.5 KB
- Stars: 4
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# 概述:
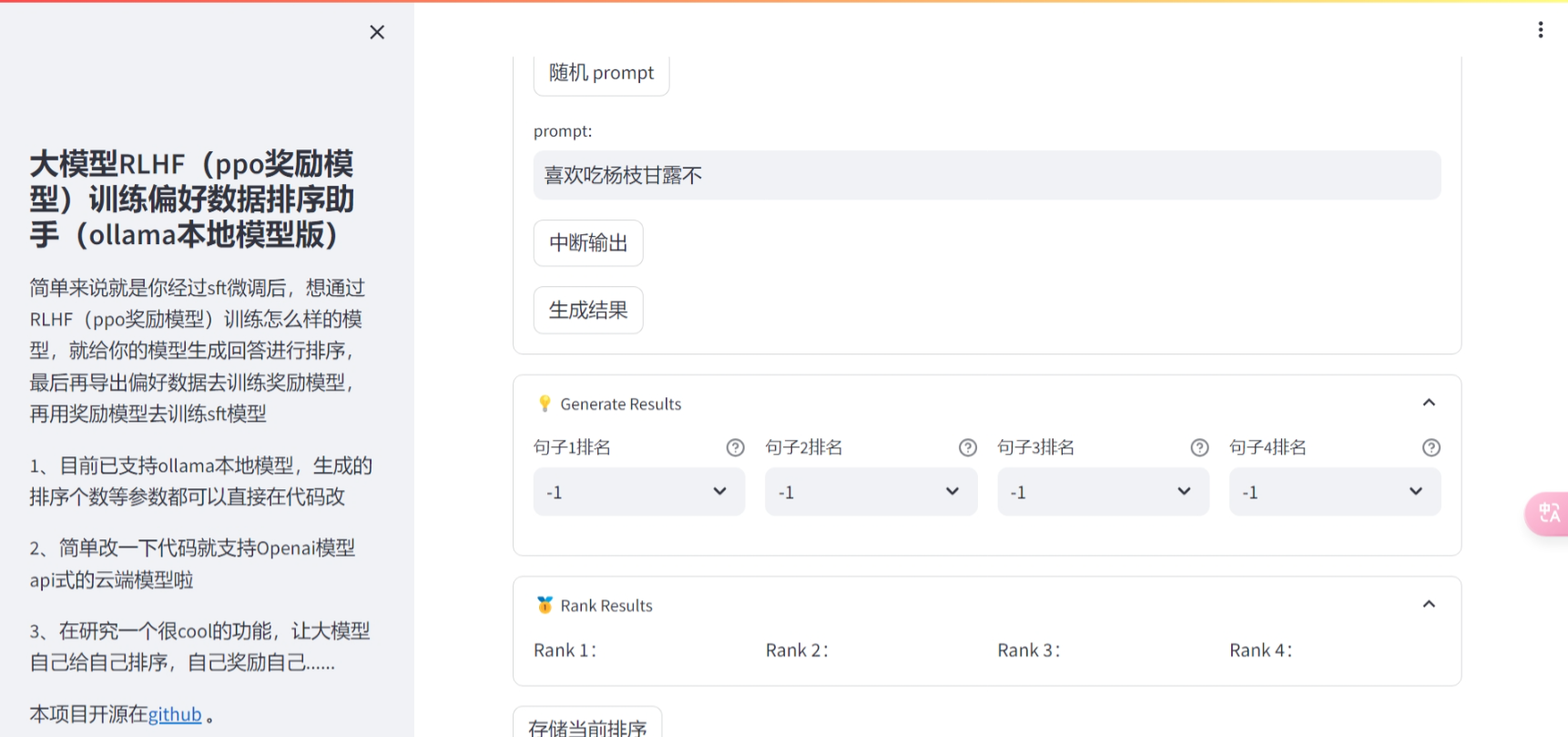
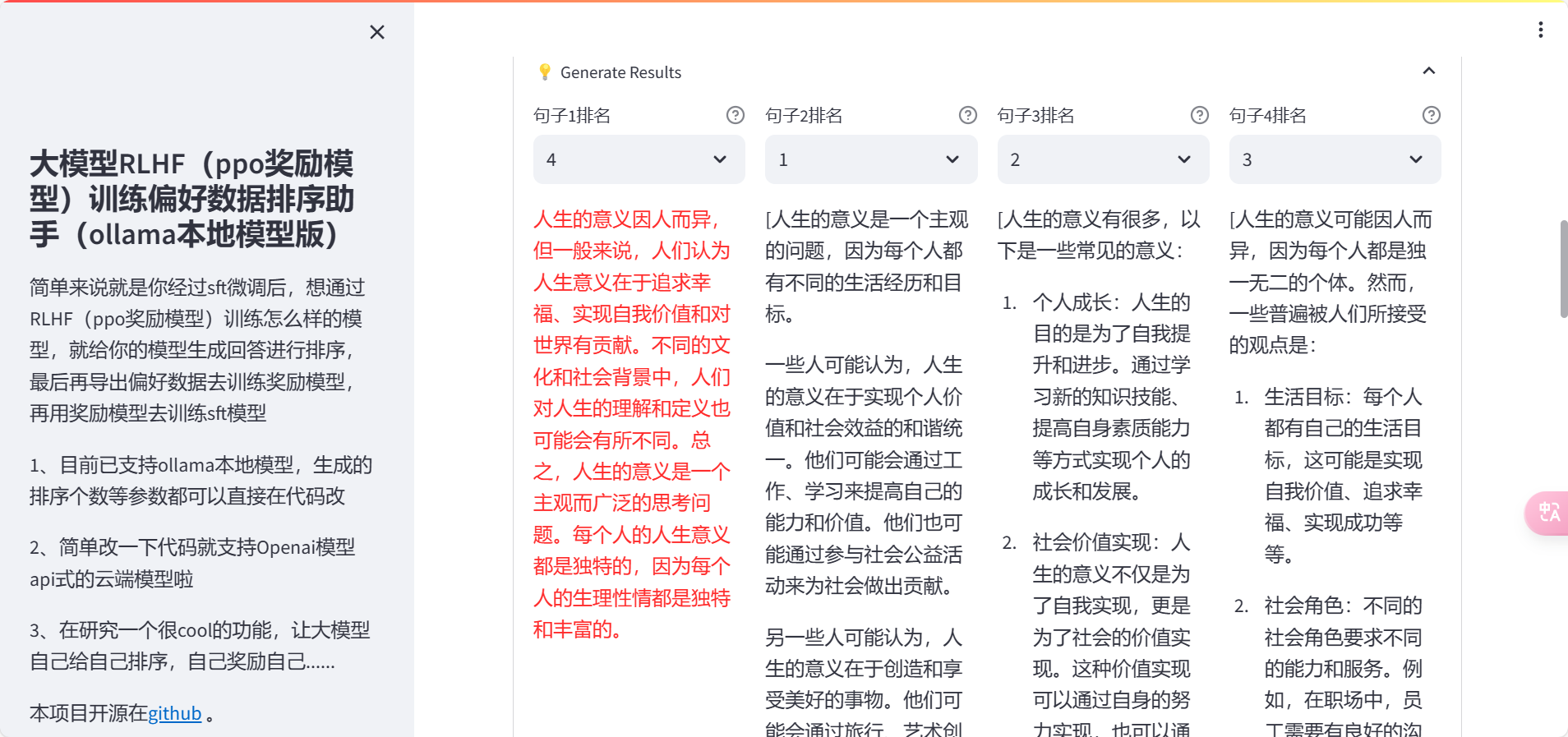
大模型RLHF(ppo奖励模型)训练偏好数据排序助手(支持ollama本地模型)
简单来说就是你经过sft微调后,想通过RLHF(ppo奖励模型)训练怎么样的模型,就给你的模型生成回答进行排序,最后再导出偏好数据去训练奖励模型,再用奖励模型去训练sft模型
[大模型RLHF(ppo奖励模型)训练偏好数据排序助手(ollama本地模型版)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1P1421675z/?spm_id_from=333.999.0.0)
本项目遵循GPL许可证,欢迎贡献代码或提出改进建议。项目地址:
[https://github.com/zjrwtx/preference_databuilder](https://github.com/zjrwtx/preference_databuilder)
1、克隆到本地
```git
git clone https://github.com/zjrwtx/preference_databuilder.git
```
2、安装依赖
```git
poetry install
```
3、配置ollama环境与模型或云端模型
4、复制.env.example文件为.env 填写大模型的环境变量等
5、streamlit run main.py
欢迎贡献。请先 fork 仓库,然后提交一个 pull request 包含你的更改。
agi_isallyouneed

## X(推特)正经人王同学:[https://twitter.com/zjrwtx](https://twitter.com/zjrwtx)
本项目遵循GPL许可证,欢迎贡献代码或提出改进建议。项目地址:[https://github.com/zjrwtx/preference_databuilder](https://github.com/zjrwtx/preference_databuilder)
非商业用途:本项目的所有源代码和相关文档仅限于非商业用途。任何商业用途均被严格禁止。
出处声明:任何个人或实体在修改、分发或使用本项目时,必须清楚地标明本项目的原始来源,并且保留原始作者的版权声明。
# 特别感谢
代码参考:
[https://github.com/HarderThenHarder/transformers_tasks](https://github.com/HarderThenHarder/transformers_tasks)