https://github.com/zsrobinson/musescore-pdf
Convert any Musescore link into a printable PDF
https://github.com/zsrobinson/musescore-pdf
musescore musescore-downloader nextjs pdf puppeteer
Last synced: 11 months ago
JSON representation
Convert any Musescore link into a printable PDF
- Host: GitHub
- URL: https://github.com/zsrobinson/musescore-pdf
- Owner: zsrobinson
- License: mit
- Created: 2023-07-19T06:56:10.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-06-29T12:08:02.000Z (almost 2 years ago)
- Last Synced: 2025-04-05T19:24:37.458Z (about 1 year ago)
- Topics: musescore, musescore-downloader, nextjs, pdf, puppeteer
- Language: TypeScript
- Homepage:
- Size: 609 KB
- Stars: 21
- Watchers: 1
- Forks: 4
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE.txt
Awesome Lists containing this project
README
# Musescore PDF Generator
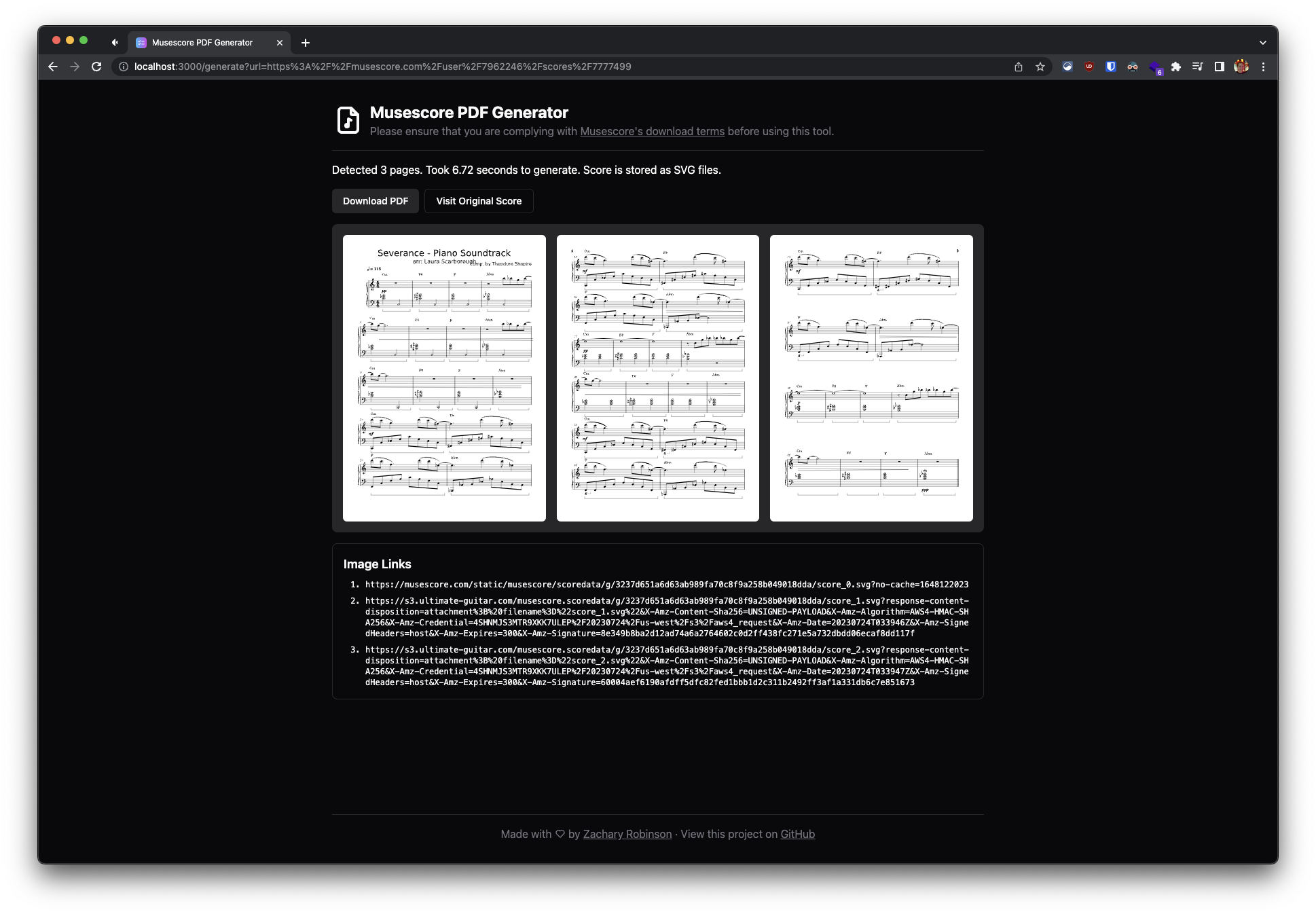
## How to run this tool
First, make sure you have node package manager (NPM) installed on your system. After cloning this repo, run `npm install` and `npm run dev` in the root of the project. Navigate to `http://localhost:3000` in your browser, and enter in the URL of the score from Musescore that you'd like to convert to a PDF. On my machine, it takes about a second per page to load, but your results may vary.
Running `npm run dev` is the quickest way to get up and running, though you'd probably want to actually build the project if you're running this for extended periods of time. The dev script is perfectly good if you just need to fire up the tool to convert a score or two.
## About this project
Musescore's [download terms](https://musescore.com/download-terms) states that "Public Domain and Original scores will remain free to download and print", although this is not the case (at the time of writing this on 2023-07-23). Clicking on the download link for a score that is listed as "Public Domain" will only lead to a screen that asks you to either subscribe or start a free trial. In the interest of ensuring that I'm still able to save these scores, I've created this tool.
Musescore allows anyone to view a score on their website, which means that we can use a tool like [Puppeteer](https://pptr.dev/) to grab the images of each page of score and then convert those into one big PDF. This sounds pretty easy at first, but there were a few roadblocks that I wasn't expected as I went about doing this:
- only the link to the _first_ page is embedded in the HTML response from the server, meaning that we have to use a tool like Puppeteer instead of a simple fetch call to grab the rest of the links after the JavaScript on the page does its magic
- the preview page for a score will only show a handful of pages of the score at any given time depending on how far down you scroll on the page (presumably to save resources on the client), meaning that Puppeteer has to simulate this scrolling and save the image links as it scrolls down
- different scores are encoded in different ways, with some being SVGs of varying widths and others being PNGs, meaning that we have too create different ways to save an image URL as a PDF for these different file formats and detect the best scaling percent for the SVGs
I might create a blog post at some point going into each of these points in a bit more detail, but I think I've gotten this tool to a point where it can work on every score I've thrown at it. As Musescore changes their website, I'm sure that this tool will break at some point. Feel free to submit a PR or reach out to me if this happens, though there's no guarantee I'll be able to work on it.
This project was something I did on the fly while trying to print out a score to practice on the piano. I thought that I'd just be able to print it out with no problem since you're already able to preview the score online with no restrictions, _but I guess I was wrong_. I didn't expect to stay up all night working on this, and then the next few days here and there ironing out the different edge cases, but here we are. Going through all this forced me to learn how to use Puppeteer and deal with PDFs in Node.js, which weren't really things I would have otherwise done.