https://github.com/zyayoung/fixjpg
https://github.com/zyayoung/fixjpg
Last synced: 3 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/zyayoung/fixjpg
- Owner: zyayoung
- Created: 2019-10-04T08:39:59.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2019-10-06T15:09:36.000Z (over 5 years ago)
- Last Synced: 2025-01-21T18:15:25.346Z (5 months ago)
- Language: Python
- Size: 409 KB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# FixJPG
## Run (not tested)
```bash
python download.py
mv 表情包 ori
python prepare_data.py
python train.py
python demo.py
```
各种论坛以及即时通讯工具通常会将表情包过分压缩,影响观感。本文参考EDSR(Enhanced Deep Super-Resolution)提出一种简单的表情包修复方法。
## 简介
JPG图像过度压缩后会出现明显的块状和波纹状噪音,本文提供一种修复噪音的方法。

如图,左边的高质量表情包经过压缩后出现了噪音。经过Resnet18网络降噪,表情包的噪音被修复,观感与原图相近,甚至原图中被压缩的痕迹也得到了修复。
单图像超分辨率(SISR)问题已经有了很多研究。图像压缩修复是一个与之类似的问题:SISR重建降低分辨率所丢失的信息,而本文重建图像在过度压缩中丢失的信息。EDSR使用单网络实现图像超分辨率,是*NTIRE 2017*超分辨率挑战的第一名。本文使用与之类似的网络结构以实现图像压缩修复。
[Code](https://github.com/zyayoung/FixJPG)
| Compressed | SRCNN修复 | Resnet18修复 |
| ------------------------------------------------------------------------- | ------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
|  |  |  |
## Related Works
### Resnet
Resnet引入残差框架使得深度网络更容易学习[2]。本文使用修改过的18层无pooling残差网络作为超分辨率基础网络。
### 单图像超分辨率
SRCNN[3]是早期的单图像超分辨率网络。网络输入大小和输出大小除padding外完全一致。训练时将训练图片双立方插值到1/2大小再双立方插值到原大小作为网络输入,原图作为网络输出。使用时需要先将图像双立方插值到2倍大小,再经过网络获得清晰的图像。我们仿照SRCNN的做法,训练时从训练图像中提取出64*64的黑白图像作为网络输入,以加速训练。测试时使用原图像大小。
在JPG压缩修复的问题中,我们不使用双立法插值准备训练数据,而使用高质量的训练图片过度压缩,得到训练样本。
EDSR是较新的单网络超分辨率方法。它移除了残差网络中多余的层,达到了2017年的state-of-the-art[1]。 该文章提出了Residual Module中的Batch Normalization层"消除了范围的灵活性"[1],对超分辨率任务无利。本文中重建图像的任务与超分辨率类似,使用无Batch Normalization的残差网络。
## Proposed Methods
### Data preparation
我们在百度图片中以"表情包"为关键词找到700张图片,并且人工筛选出209张高质量图片作为训练数据集。在训练数据集中,我们对每张图片使用python-pillow进行压缩,并且将图像长边限制在320px,得到网络的输入和输出数据。对于网路输入数据,选择压缩质量10。对于网路输出数据,选择压缩质量100。
### Model
本文提出两种可用于JPG压缩修复的网络结构:
#### SRCNN
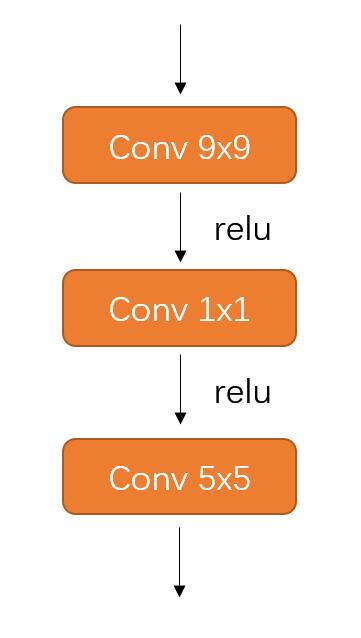
使用SRCNN中提出的网络结构:
Conv(64 kernals, 9x9) -> relu -> Conv(32 kernals, 1x1) -> relu -> Conv(1 kernal, 5x5)
#### Resnet18
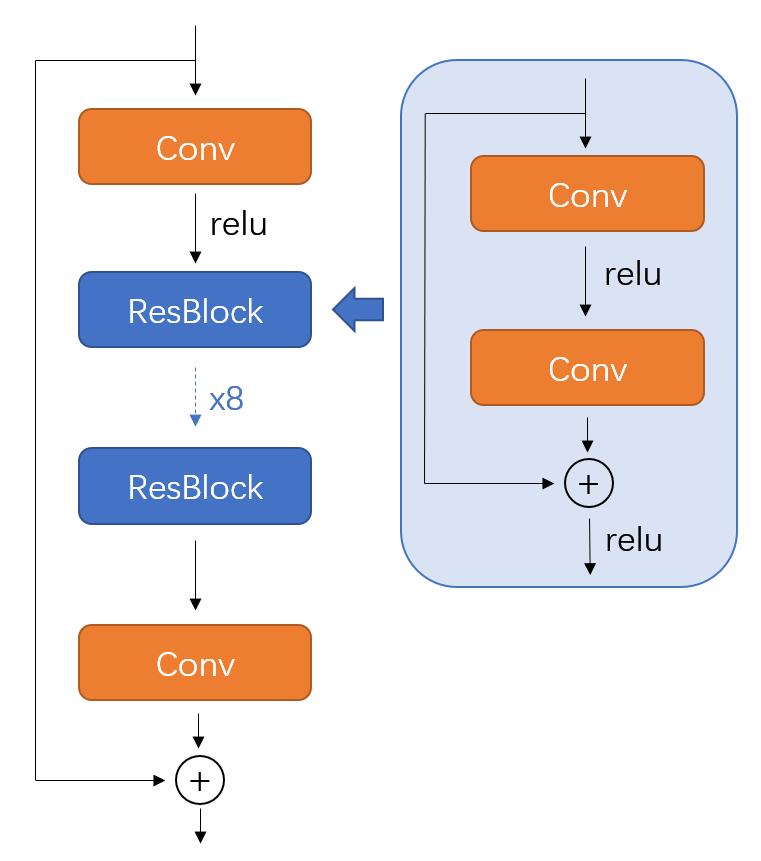
使用类似EDSR的设计,去除resnet18的stride,保留8个同样的ResBlock。保留了最后的add层,以迫使网络习得由JPG压缩所产生的噪音。网络共18个卷积层。如图所示,ResBlock与EDSR中略有不同,保留了最后的relu层。除可根据上下文推断的情况外,所有卷积均为3x3, 64filters。
### Training
由于训练表情包多数以黑白为主,训练时先将图片转为灰度图,再从中截出64*64的部分图片送入网络,使用Adam优化器keras默认参数,batchsize=256,训练24epochs。
### Inference
对于黑白图片直接通过网络得到修复后的图像。对于彩色图片,每个通道分别通过网络后,合并得到修复后的图像。可对输出图像再次进入网络,可能会得到更清晰的图像。
## Experiments
使用两种网络在训练集上测试图像修复效果
| | Raw | SRCNN | Resnet18 |
| ------- | ------------------------------------------------------------------------- | ------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
| PSNR | 27.52 | 30.00 | 31.31 |
| Sample1 |  |  |  |
| Sample2 |  |  |  |
| Sample3 |  |  |  |
| Sample3 |  |  |  |
| Sample4 |  |  |  |
Table 1: Average PSNR of Reconstruction on the 209-Image Dataset
| SRCNN | Resnet18 |
| ---------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------- |
|  |  |
|  |  |
|  |  |
|  |  |
|  |  |
Table 2: Comparison between Two Models. From top to down: Raw image, fixed image, Residual (noise).
## Reference
1. B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, "Enhanced Deep Residual Networks for Single Image Super-Resolution," *2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)*, 2017.
2. K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition," *2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)*, 2016.
3. C. Dong, C. C. Loy, K. He, and X. Tang. "Learning a deep convolutional network for image super-resolution," *Proceedings of European Conference on Computer Vision (ECCV)*, 2014.