https://github.com/Lupin1998/Awesome-MIM
[Survey] Masked Modeling for Self-supervised Representation Learning on Vision and Beyond (https://arxiv.org/abs/2401.00897)
https://github.com/Lupin1998/Awesome-MIM
List: Awesome-MIM
awesome-list awesome-mim bert computer-vision deep-learning generative-models gpt mae masked-autoencoder masked-image-modeling masked-modeling pre-training representation-learning self-supervised-learning vision-transformer
Last synced: 7 months ago
JSON representation
[Survey] Masked Modeling for Self-supervised Representation Learning on Vision and Beyond (https://arxiv.org/abs/2401.00897)
- Host: GitHub
- URL: https://github.com/Lupin1998/Awesome-MIM
- Owner: Lupin1998
- License: apache-2.0
- Created: 2022-07-30T17:09:35.000Z (almost 3 years ago)
- Default Branch: master
- Last Pushed: 2024-10-07T09:39:17.000Z (9 months ago)
- Last Synced: 2024-10-30T03:42:47.462Z (8 months ago)
- Topics: awesome-list, awesome-mim, bert, computer-vision, deep-learning, generative-models, gpt, mae, masked-autoencoder, masked-image-modeling, masked-modeling, pre-training, representation-learning, self-supervised-learning, vision-transformer
- Language: Python
- Homepage: https://openmixup.readthedocs.io/en/latest/awesome_selfsup/MIM.html
- Size: 6.67 MB
- Stars: 299
- Watchers: 7
- Forks: 14
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Contributing: .github/CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - Awesome-MIM - [Survey] Masked Modeling for Self-supervised Representation Learning on Vision and Beyond ( (Other Lists / Julia Lists)
README
# Awesome Masked Modeling for Self-supervised Vision Represention and Beyond
[](https://awesome.re)  [](https://github.com/Lupin1998/Awesome-MIM/graphs/commit-activity)  
## Introduction
**We summarize awesome Masked Image Modeling (MIM) and relevent Masked Modeling methods proposed for self-supervised representation learning.** *Welcome to add relevant masked modeling paper to our project!*
This project is a part of our **survey on masked modeling methods** ([arXiv](https://arxiv.org/abs/2401.00897)). The list of awesome MIM methods is summarized in chronological order and is on updating. If you find any typos or any missed paper, please feel free to open an issue or send a pull request. Currently, our survey is on updating and here is the [latest version](https://github.com/Lupin1998/Awesome-MIM/blob/master/files/Survey_on_Masked_Modeling_Latest_Version.pdf).
* To find related papers and their relationships, check out [Connected Papers](https://www.connectedpapers.com/), which visualizes the academic field in a graph representation.
* To export BibTeX citations of papers, check out [arXiv](https://arxiv.org/) or [Semantic Scholar](https://www.semanticscholar.org/) of the paper for professional reference formats.

Research in self-supervised learning can be broadly categorized into Generative and Discriminative paradigms. We reviewed major SSL research since 2008 and found that SSL has followed distinct developmental trajectories and stages across time periods and modalities. Since 2018, SSL in NLP has been dominated by generative masked language modeling, which remains mainstream. In computer vision, discriminative contrastive learning dominated from 2018 to 2021 before masked image modeling gained prominence after 2022.
## Table of Contents
- [Awesome Masked Modeling for Self-supervised Vision Represention and Beyond](#awesome-masked-modeling-for-self-supervised-vision-represention-and-beyond)
- [Introduction](#introduction)
- [Table of Contents](#table-of-contents)
- [Fundamental MIM Methods](#fundamental-mim-methods)
- [MIM for Transformers](#mim-for-transformers)
- [MIM with Constrastive Learning](#mim-with-constrastive-learning)
- [MIM for Transformers and CNNs](#mim-for-transformers-and-cnns)
- [MIM with Advanced Masking](#mim-with-advanced-masking)
- [MIM for Multi-Modality](#mim-for-multi-modality)
- [MIM for Vision Generalist Model](#mim-for-vision-generalist-model)
- [Image Generation](#image-generation)
- [MIM for CV Downstream Tasks](#mim-for-cv-downstream-tasks)
- [Object Detection](#object-detection)
- [Video Rrepresentation](#video-rrepresentation)
- [Knowledge Distillation and Few-shot Classification](#knowledge-distillation-and-few-shot-classification)
- [Efficient Fine-tuning](#efficient-fine-tuning)
- [Medical Image](#medical-image)
- [Face Recognition](#face-recognition)
- [Scene Text Recognition (OCR)](#scene-text-recognition-ocr)
- [Remote Sensing Image](#remote-sensing-image)
- [3D Representation Learning](#3d-representation-learning)
- [Depth Estimation](#depth-estimation)
- [Audio and Speech](#audio-and-speech)
- [AI for Science](#ai-for-science)
- [Protein](#protein)
- [Chemistry](#chemistry)
- [Physics](#physics)
- [Neuroscience Learning](#time-series-and-neuroscience-learning)
- [Reinforcement Learning](#reinforcement-learning)
- [Analysis and Understanding of Masked Modeling](#analysis-and-understanding-of-masked-modeling)
- [Survey](#survey)
- [Contribution](#contribution)
- [Related Project](#related-project)
- [Paper List of Masked Image Modeling](#paper-list-of-masked-image-modeling)
- [Project of Self-supervised Learning](#project-of-self-supervised-learning)
## Fundamental MIM Methods

The overview of the basic MIM framework, containing four building blocks with their internal components and functionalities. All MIM research can be summarized as innovations upon these four blocks, i.e., Masking, Encoder, Target, and Head. Frameworks of masked modeling in other modalities are similar to this framework.
### MIM for Transformers
* **Generative Pretraining from Pixels**
*Mark Chen, Alec Radford, Rewon Child, Jeff Wu, Heewoo Jun, David Luan, Ilya Sutskever*
ICML'2020 [[Paper](http://proceedings.mlr.press/v119/chen20s/chen20s.pdf)]
[[Code](https://github.com/openai/image-gpt)]
iGPT Framework

* **An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale**
*Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby*
ICLR'2021 [[Paper](https://arxiv.org/abs/2010.11929)]
[[Code](https://github.com/google-research/vision_transformer)]
ViT Framework

* **BEiT: BERT Pre-Training of Image Transformers**
*Hangbo Bao, Li Dong, Furu Wei*
ICLR'2022 [[Paper](https://arxiv.org/abs/2106.08254)]
[[Code](https://github.com/microsoft/unilm/tree/master/beit)]
BEiT Framework

* **iBOT: Image BERT Pre-Training with Online Tokenizer**
*Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, Tao Kong*
ICLR'2022 [[Paper](https://arxiv.org/abs/2111.07832)]
[[Code](https://github.com/bytedance/ibot)]
iBOT Framework

* **Masked Autoencoders Are Scalable Vision Learners**
*Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick*
CVPR'2022 [[Paper](https://arxiv.org/abs/2111.06377)]
[[Code](https://github.com/facebookresearch/mae)]
MAE Framework

* **SimMIM: A Simple Framework for Masked Image Modeling**
*Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, Han Hu*
CVPR'2022 [[Paper](https://arxiv.org/abs/2111.09886)]
[[Code](https://github.com/microsoft/simmim)]
SimMIM Framework

* **Masked Feature Prediction for Self-Supervised Visual Pre-Training**
*Chen Wei, Haoqi Fan, Saining Xie, Chao-Yuan Wu, Alan Yuille, Christoph Feichtenhofer*
CVPR'2022 [[Paper](https://arxiv.org/abs/2112.09133)]
[[Code](https://github.com/facebookresearch/SlowFast)]
MaskFeat Framework

* **data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language**
*Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli*
ICML'2022 [[Paper](https://arxiv.org/abs/2202.03555)]
[[Code](https://github.com/facebookresearch/fairseq/tree/main/examples/data2vec)]
data2vec Framework

* **Position Prediction as an Effective Pretraining Strategy**
*Shuangfei Zhai, Navdeep Jaitly, Jason Ramapuram, Dan Busbridge, Tatiana Likhomanenko, Joseph Yitan Cheng, Walter Talbott, Chen Huang, Hanlin Goh, Joshua Susskind*
ICML'2022 [[Paper](https://arxiv.org/abs/2207.07611)]
MP3 Framework

* **PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers**
*Xiaoyi Dong, Jianmin Bao, Ting Zhang, Dongdong Chen, Weiming Zhang, Lu Yuan, Dong Chen, Fang Wen, Nenghai Yu*
AAAI'2023 [[Paper](https://arxiv.org/abs/2111.12710)]
[[Code](https://github.com/microsoft/PeCo)]
PeCo Framework

* **MC-SSL0.0: Towards Multi-Concept Self-Supervised Learning**
*Sara Atito, Muhammad Awais, Ammarah Farooq, Zhenhua Feng, Josef Kittler*
ArXiv'2021 [[Paper](https://arxiv.org/abs/2111.15340)]
MC-SSL0.0 Framework

* **mc-BEiT: Multi-choice Discretization for Image BERT Pre-training**
*Xiaotong Li, Yixiao Ge, Kun Yi, Zixuan Hu, Ying Shan, Ling-Yu Duan*
ECCV'2022 [[Paper](https://arxiv.org/abs/2203.15371)]
[[Code](https://github.com/lixiaotong97/mc-BEiT)]
mc-BEiT Framework

* **Bootstrapped Masked Autoencoders for Vision BERT Pretraining**
*Xiaoyi Dong, Jianmin Bao, Ting Zhang, Dongdong Chen, Weiming Zhang, Lu Yuan, Dong Chen, Fang Wen, Nenghai Yu*
ECCV'2022 [[Paper](https://arxiv.org/abs/2207.07116)]
[[Code](https://github.com/LightDXY/BootMAE)]
BootMAE Framework

* **SdAE: Self-distillated Masked Autoencoder**
*Yabo Chen, Yuchen Liu, Dongsheng Jiang, Xiaopeng Zhang, Wenrui Dai, Hongkai Xiong, Qi Tian*
ECCV'2022 [[Paper](https://arxiv.org/abs/2208.00449)]
[[Code](https://github.com/AbrahamYabo/SdAE)]
SdAE Framework

* **MultiMAE: Multi-modal Multi-task Masked Autoencoders**
*Roman Bachmann, David Mizrahi, Andrei Atanov, Amir Zamir*
ECCV'2022 [[Paper](https://arxiv.org/abs/2204.01678)]
[[Code](https://github.com/EPFL-VILAB/MultiMAE)]
MultiMAE Framework

* **SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners**
*Feng Liang, Yangguang Li, Diana Marculescu*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.14540)]
[[Code](https://github.com/cmu-enyac/supmae)]
SupMAE Framework

* **MVP: Multimodality-guided Visual Pre-training**
*Longhui Wei, Lingxi Xie, Wengang Zhou, Houqiang Li, Qi Tian*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2203.05175)]
MVP Framework

* **The Devil is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-Training**
*Hao Liu, Xinghua Jiang, Xin Li, Antai Guo, Deqiang Jiang, Bo Ren*
AAAI'2023 [[Paper](https://arxiv.org/abs/2204.08227)]
Ge2AE Framework

* **ConvMAE: Masked Convolution Meets Masked Autoencoders**
*Peng Gao, Teli Ma, Hongsheng Li, Ziyi Lin, Jifeng Dai, Yu Qiao*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2205.03892)]
[[Code](https://github.com/Alpha-VL/ConvMAE)]
ConvMAE Framework

* **Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking**
*Peng Gao, Renrui Zhang, Rongyao Fang, Ziyi Lin, Hongyang Li, Hongsheng Li, Qiao Yu*
arXiv'2023 [[Paper](https://arxiv.org/abs/2303.05475)]
[[Code](https://github.com/alpha-vl/convmae)]
MR-MAE (ConvMAE.V2) Framework

* **Green Hierarchical Vision Transformer for Masked Image Modeling**
*Lang Huang, Shan You, Mingkai Zheng, Fei Wang, Chen Qian, Toshihiko Yamasaki*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2205.13515)]
[[Code](https://github.com/LayneH/GreenMIM)]
GreenMIM Framework

* **Test-Time Training with Masked Autoencoders**
*Yossi Gandelsman, Yu Sun, Xinlei Chen, Alexei A. Efros*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2209.07522)]
[[Code](https://github.com/yossigandelsman/test_time_training_mae)]
TTT-MAE Framework

* **HiViT: Hierarchical Vision Transformer Meets Masked Image Modeling**
*Xiaosong Zhang, Yunjie Tian, Wei Huang, Qixiang Ye, Qi Dai, Lingxi Xie, Qi Tian*
ICLR'2023 [[Paper](https://arxiv.org/abs/2205.14949)]
HiViT Framework

* **Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation**
*Yixuan Wei, Han Hu, Zhenda Xie, Zheng Zhang, Yue Cao, Jianmin Bao, Dong Chen, Baining Guo*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.14141)]
[[Code](https://github.com/SwinTransformer/Feature-Distillation)]
FD Framework

* **Object-wise Masked Autoencoders for Fast Pre-training**
*Jiantao Wu, Shentong Mo*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.14338)]
ObjMAE Framework

* **Efficient Self-supervised Vision Pretraining with Local Masked Reconstruction**
*Jun Chen, Ming Hu, Boyang Li, Mohamed Elhoseiny*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.00790)]
[[Code](https://github.com/junchen14/LoMaR)]
LoMaR Framework

* **Extreme Masking for Learning Instance and Distributed Visual Representations**
*Zhirong Wu, Zihang Lai, Xiao Sun, Stephen Lin*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.04667)]
ExtreMA Framework

* **BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers**
*Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei*
ArXiv'2022 [[Paper](http://arxiv.org/abs/2208.06366)]
[[Code](https://aka.ms/beit)]
BEiT.V2 Framework

* **MILAN: Masked Image Pretraining on Language Assisted Representation**
*Zejiang Hou, Fei Sun, Yen-Kuang Chen, Yuan Xie, Sun-Yuan Kung*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2208.06049)]
[[Code](https://github.com/zejiangh/milan)]
MILAN Framework

* **Exploring The Role of Mean Teachers in Self-supervised Masked Auto-Encoders**
*Youngwan Lee, Jeffrey Willette, Jonghee Kim, Juho Lee, Sung Ju Hwang*
ICLR'2023 [[Paper](https://arxiv.org/abs/2210.02077)]
RC-MAE Framework

* **Denoising Masked AutoEncoders are Certifiable Robust Vision Learners**
*Quanlin Wu, Hang Ye, Yuntian Gu, Huishuai Zhang, Liwei Wang, Di He*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.06983)]
[[Code](https://github.com/quanlin-wu/dmae)]
DMAE Framework

* **A Unified View of Masked Image Modeling**
*Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.10615)]
[[Code](https://aka.ms/unimim)]
MaskDistill Framework

* **DILEMMA: Self-Supervised Shape and Texture Learning with Transformers**
*Sepehr Sameni, Simon Jenni, Paolo Favaro*
AAAI'2023 [[Paper](https://arxiv.org/abs/2204.04788)]
DILEMMA Framework

* **i-MAE: Are Latent Representations in Masked Autoencoders Linearly Separable**
*Kevin Zhang, Zhiqiang Shen*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.11470)]
[[Code](https://github.com/vision-learning-acceleration-lab/i-mae)]
i-MAE Framework

* **EVA: Exploring the Limits of Masked Visual Representation Learning at Scale**
*Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, Yue Cao*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.07636)]
[[Code](https://github.com/baaivision/EVA)]
EVA Framework

* **EVA-02: A Visual Representation for Neon Genesis**
*Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, Yue Cao*
CVPR'2024 [[Paper](https://arxiv.org/abs/2303.11331)]
[[Code](https://github.com/baaivision/EVA/tree/master/EVA-02)]
EVA-02 Framework
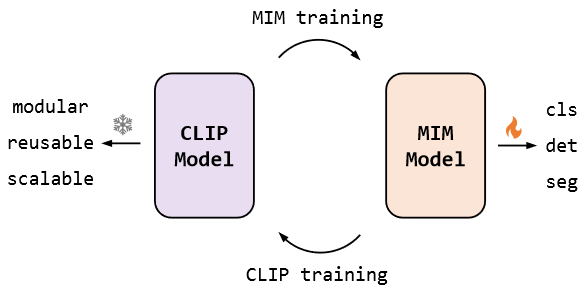
* **Context Autoencoder for Self-Supervised Representation Learning**
*Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, Jingdong Wang*
IJCV'2023 [[Paper](https://arxiv.org/abs/2202.03026)]
[[Code](https://github.com/lxtGH/CAE)]
CAE Framework

* **CAE v2: Context Autoencoder with CLIP Target**
*Xinyu Zhang, Jiahui Chen, Junkun Yuan, Qiang Chen, Jian Wang, Xiaodi Wang, Shumin Han, Xiaokang Chen, Jimin Pi, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2211.09799)]
CAE.V2 Framework

* **FastMIM: Expediting Masked Image Modeling Pre-training for Vision**
*Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Yunhe Wang, Chang Xu*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2212.06593)]
FastMIM Framework

* **Exploring Target Representations for Masked Autoencoders**
*Xingbin Liu, Jinghao Zhou, Tao Kong, Xianming Lin, Rongrong Ji*
ICLR'2024 [[Paper](https://arxiv.org/abs/2209.03917)]
[[Code](https://github.com/liuxingbin/dbot)]
dBOT Framework

* **Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language**
*Alexei Baevski, Arun Babu, Wei-Ning Hsu, and Michael Auli*
ICML'2023 [[Paper](https://arxiv.org/abs/2212.07525)]
[[Code](https://github.com/facebookresearch/fairseq/tree/main/examples/data2vec)]
Data2Vec.V2 Framework

* **Masked autoencoders are effective solution to transformer data-hungry**
*Jiawei Mao, Honggu Zhou, Xuesong Yin, Yuanqi Chang. Binling Nie. Rui Xu*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2212.05677)]
[[Code](https://github.com/Talented-Q/SDMAE)]
SDMAE Framework

* **TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models**
*Sucheng Ren, Fangyun Wei, Zheng Zhang, Han Hu*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2301.01296)]
[[Code](https://github.com/OliverRensu/TinyMIM)]
TinyMIM Framework

* **Disjoint Masking with Joint Distillation for Efficient Masked Image Modeling**
*Xin Ma, Chang Liu, Chunyu Xie, Long Ye, Yafeng Deng, Xiangyang Ji*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2301.00230)]
[[Code](https://github.com/mx-mark/dmjd)]
DMJD Framework

* **Mixed Autoencoder for Self-supervised Visual Representation Learning**
*Kai Chen, Zhili Liu, Lanqing Hong, Hang Xu, Zhenguo Li, Dit-Yan Yeung*
CVPR'2023 [[Paper](https://arxiv.org/abs/2303.17152)]
MixedAE Framework

* **Masked Image Modeling with Local Multi-Scale Reconstruction**
*Haoqing Wang, Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhi-Hong Deng, Kai Han*
CVPR'2023 [[Paper](https://arxiv.org/abs/2303.05251)]
[[Code](https://github.com/Haoqing-Wang/LocalMIM)]
LocalMAE Framework

* **Stare at What You See: Masked Image Modeling without Reconstruction**
*Hongwei Xue, Peng Gao, Hongyang Li, Yu Qiao, Hao Sun, Houqiang Li, Jiebo Luo*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.08887)]
[[Code](https://github.com/OpenPerceptionX/maskalign)]
MaskAlign Framework

* **Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture**
*Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas*
CVPR'2023 [[Paper](https://arxiv.org/abs/2301.08243)]
I-JEPA Framework

* **MOMA: Distill from Self-Supervised Teachers**
*Yuchong Yao, Nandakishor Desai, Marimuthu Palaniswami*
arXiv'2023 [[Paper](https://arxiv.org/abs/2302.02089)]
MOMA Framework

* **PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling**
*Yuan Liu, Songyang Zhang, Jiacheng Chen, Kai Chen, Dahua Lin*
arXiv'2023 [[Paper](https://arxiv.org/abs/2303.02416)]
[[Code](https://github.com/open-mmlab/mmselfsup/tree/dev-1.x/configs/selfsup/pixmim)]
PixMIM Framework

* **Img2Vec: A Teacher of High Token-Diversity Helps Masked AutoEncoders**
*Heng Pan, Chenyang Liu, Wenxiao Wang, Li Yuan, Hongfa Wang, Zhifeng Li, Wei Liu*
arXiv'2023 [[Paper](https://arxiv.org/abs/2304.12535)]
Img2Vec Framework

* **A Closer Look at Self-Supervised Lightweight Vision Transformers**
*Shaoru Wang, Jin Gao, Zeming Li, Xiaoqin Zhang, Weiming Hu*
ICML'2023 [[Paper](https://arxiv.org/abs/2205.14443)]
[[Code](https://github.com/wangsr126/mae-lite)]
MAE-Lite Framework

* **Architecture-Agnostic Masked Image Modeling - From ViT back to CNN**
*Siyuan Li, Di Wu, Fang Wu, Zelin Zang, Stan.Z.Li*
ICML'2023 [[Paper](https://arxiv.org/abs/2205.13943)]
[[Code](https://github.com/Westlake-AI/openmixup)] [[project](https://github.com/Westlake-AI/A2MIM)]
A2MIM Framework

* **Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles**
*Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer*
ICML'2023 [[Paper](https://arxiv.org/abs/2306.00989)]
[[Code](https://github.com/facebookresearch/hiera)]
Hiera Framework

* **The effectiveness of MAE pre-pretraining for billion-scale pretraining**
*Mannat Singh, Quentin Duval, Kalyan Vasudev Alwala, Haoqi Fan, Vaibhav Aggarwal, Aaron Adcock, Armand Joulin, Piotr Dollár, Christoph Feichtenhofer, Ross Girshick, Rohit Girdhar, Ishan Misra*
ICCV'2023 [[Paper](https://arxiv.org/abs/2303.13496)]
WSP Framework

* **Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training**
*Lorenzo Baraldi, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, Andrea Pilzer, Rita Cucchiara*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2306.07346)]
[[Code](https://github.com/aimagelab/mapet)]
MaPeT Framework

* **BIM: Block-Wise Self-Supervised Learning with Masked Image Modeling**
*Yixuan Luo, Mengye Ren, Sai Qian Zhang*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2311.17218)]
* **R-MAE: Regions Meet Masked Autoencoders**
*Duy-Kien Nguyen, Vaibhav Aggarwal, Yanghao Li, Martin R. Oswald, Alexander Kirillov, Cees G. M. Snoek, Xinlei Chen*
ICLR'2024 [[Paper](https://arxiv.org/abs/2306.05411)]
[[Code](https://github.com/facebookresearch/r-mae)]
R-MAE Framework

* **Improving Pixel-based MIM by Reducing Wasted Modeling Capability**
*Yuan Liu, Songyang Zhang, Jiacheng Chen, Zhaohui Yu, Kai Chen, Dahua Lin*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.00261)]
[[Code](https://github.com/open-mmlab/mmpretrain/tree/dev)]
MFM Framework

* **SparseMAE: Sparse Training Meets Masked Autoencoders**
*Aojun Zhou, Yang Li, Zipeng Qin, Jianbo Liu, Junting Pan, Renrui Zhang, Rui Zhao, Peng Gao, Hongsheng Li*
ICCV'2023 [[Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Zhou_SparseMAE_Sparse_Training_Meets_Masked_Autoencoders_ICCV_2023_paper.pdf)]
[[Code](https://github.com/aojunzz/SparseMAE)]
SparseMAE Framework

* **Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting**
*Qidong Huang, Xiaoyi Dong, Dongdong Chen, Yinpeng Chen, Lu Yuan, Gang Hua, Weiming Zhang, Nenghai Yu*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.10315)]
[[Code](https://github.com/shikiw/RobustMAE)]
RobustMAE Framework

* **DeepMIM: Deep Supervision for Masked Image Modeling**
*Sucheng Ren, Fangyun Wei, Samuel Albanie, Zheng Zhang, Han Hu*
arXiv'2023 [[Paper](https://arxiv.org/abs/2303.08817)]
[[Code](https://github.com/oliverrensu/deepmim)]
RobustMAE Framework
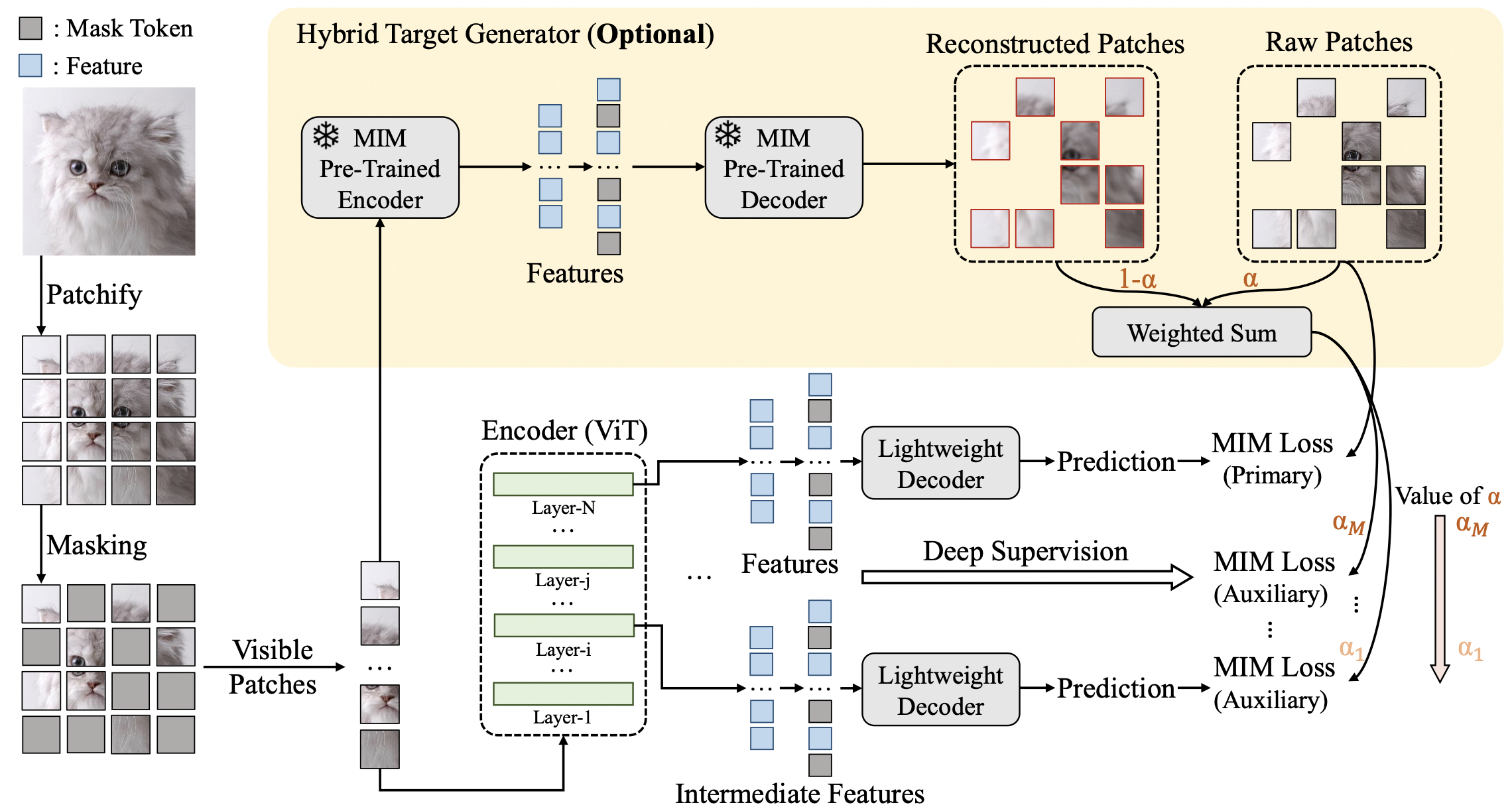
* **Rethinking Patch Dependence for Masked Autoencoders**
*Letian Fu, Long Lian, Renhao Wang, Baifeng Shi, Xudong Wang, Adam Yala, Trevor Darrell, Alexei A. Efros, Ken Goldberg*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2401.14391)]
CrossMAE Framework
)
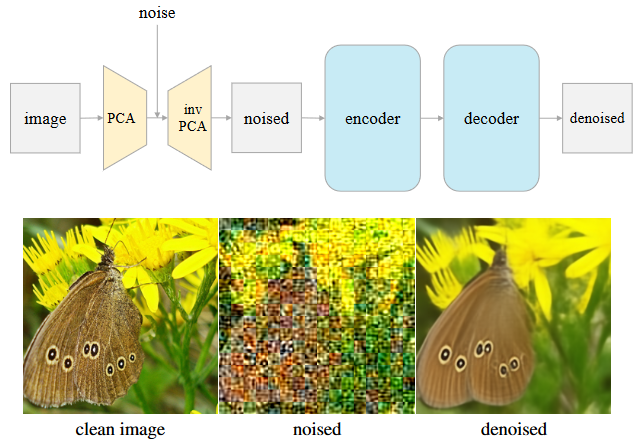
* **Deconstructing Denoising Diffusion Models for Self-Supervised Learning**
*Xinlei Chen, Zhuang Liu, Saining Xie, Kaiming He*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2401.14404)]
l-DAE Framework
* **Denoising Autoregressive Representation Learning**
*Yazhe Li, Jorg Bornschein, Ting Chen*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2403.05196)]
DARL Framework

### MIM with Constrastive Learning
* **MST: Masked Self-Supervised Transformer for Visual Representation**
*Zhaowen Li, Zhiyang Chen, Fan Yang, Wei Li, Yousong Zhu, Chaoyang Zhao, Rui Deng, Liwei Wu, Rui Zhao, Ming Tang, Jinqiao Wang*
NeurIPS'2021 [[Paper](https://arxiv.org/abs/2106.05656)]
MST Framework

* **Are Large-scale Datasets Necessary for Self-Supervised Pre-training**
*Alaaeldin El-Nouby, Gautier Izacard, Hugo Touvron, Ivan Laptev, Hervé Jegou, Edouard Grave*
ArXiv'2021 [[Paper](https://arxiv.org/abs/2112.10740)]
SplitMask Framework

* **Masked Siamese Networks for Label-Efficient Learning**
*Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2204.07141)]
[[Code](https://github.com/facebookresearch/msn)]
MSN Framework

* **Siamese Image Modeling for Self-Supervised Vision Representation Learning**
*Chenxin Tao, Xizhou Zhu, Gao Huang, Yu Qiao, Xiaogang Wang, Jifeng Dai*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.01204)]
[[Code](https://github.com/fundamentalvision/Siamese-Image-Modeling)]
SIM Framework

* **Masked Contrastive Representation Learning**
*Yuchong Yao, Nandakishor Desai, Marimuthu Palaniswami*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2211.06012)]
MACRL Framework
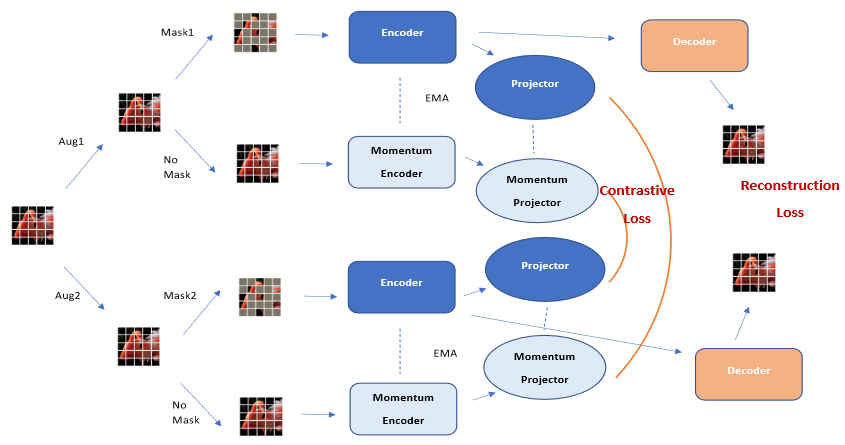
* **Masked Image Modeling with Denoising Contrast**
*Kun Yi, Yixiao Ge, Xiaotong Li, Shusheng Yang, Dian Li, Jianping Wu, Ying Shan, Xiaohu Qie*
ICLR'2023 [[Paper](https://arxiv.org/abs/2205.09616)]
[[Code](https://github.com/TencentARC/ConMIM)]
ConMIM Framework

* **RePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training**
*Luya Wang, Feng Liang, Yangguang Li, Honggang Zhang, Wanli Ouyang, Jing Shao*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2201.06857)]
RePre Framework

* **Masked Siamese ConvNets**
*Li Jing, Jiachen Zhu, Yann LeCun*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.07700)]
MSCN Framework

* **Contrastive Masked Autoencoders are Stronger Vision Learners**
*Zhicheng Huang, Xiaojie Jin, Chengze Lu, Qibin Hou, Ming-Ming Cheng, Dongmei Fu, Xiaohui Shen, Jiashi Feng*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2207.13532)]
[[Code](https://github.com/ZhichengHuang/CMAE)]
CMAE Framework

* **A simple, efficient and scalable contrastive masked autoencoder for learning visual representations**
*Shlok Mishra, Joshua Robinson, Huiwen Chang, David Jacobs, Aaron Sarna, Aaron Maschinot, Dilip Krishnan*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.16870)]
CAN Framework

* **MimCo: Masked Image Modeling Pre-training with Contrastive Teacher**
*Qiang Zhou, Chaohui Yu, Hao Luo, Zhibin Wang, Hao Li*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2209.03063)]
MimCo Framework

* **Contextual Image Masking Modeling via Synergized Contrasting without View Augmentation for Faster and Better Visual Pretraining**
*Shaofeng Zhang, Feng Zhu, Rui Zhao, Junchi Yan*
ICLR'2023 [[Paper](https://openreview.net/forum?id=A3sgyt4HWp)]
[[Code](https://github.com/Sherrylone/ccMIM)]
ccMIM Framework

* **How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders**
*Qi Zhang, Yifei Wang, Yisen Wang*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2210.08344)]
[[Code](https://github.com/zhangq327/U-MAE)]
U-MAE Framework

* **Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Label-Efficient Representations**
*Ziyu Jiang, Yinpeng Chen, Mengchen Liu, Dongdong Chen, Xiyang Dai, Lu Yuan, Zicheng Liu, Zhangyang Wang*
ICLR'2023 [[Paper](https://openreview.net/forum?id=jwdqNwyREyh)]
[[Code](https://github.com/VITA-Group/layerGraftedPretraining_ICLR23)]
Layer Grafted Framework

* **DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions**
*Haochen Wang, Junsong Fan, Yuxi Wang, Kaiyou Song, Tong Wang, Zhaoxiang Zhang*
NeurIPS'2023 [[Paper](https://arxiv.org/abs/2309.03576)]
[[Code](https://github.com/Haochen-Wang409/DropPos)]
DropPos Framework

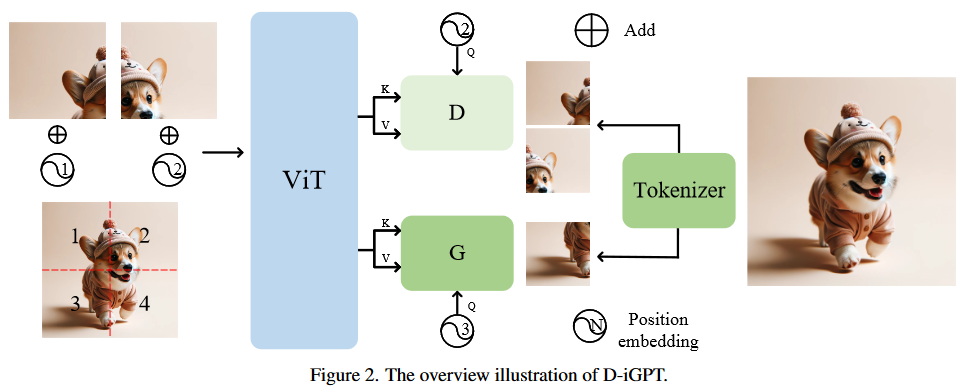
* **Rejuvenating image-GPT as Strong Visual Representation Learners**
*Sucheng Ren, Zeyu Wang, Hongru Zhu, Junfei Xiao, Alan Yuille, Cihang Xie*
arXiv'2023 [[Paper](https://arxiv.org/abs/2312.02147)]
[[Code](https://github.com/OliverRensu/D-iGPT)]
D-iGPT Framework
* **CoMAE: Single Model Hybrid Pre-training on Small-Scale RGB-D Datasets**
*Jiange Yang, Sheng Guo, Gangshan Wu, Limin Wang*
AAAI'2023 [[Paper](https://arxiv.org/abs/2302.06148)]
[[Code](https://github.com/MCG-NJU/CoMAE)]
CoMAE Framework

### MIM for Transformers and CNNs
* **Context Encoders: Feature Learning by Inpainting**
*Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, Alexei A. Efros*
CVPR'2016 [[Paper](https://arxiv.org/abs/1604.07379)]
[[Code](https://github.com/pathak22/context-encoder)]
Context-Encoder Framework

* **Corrupted Image Modeling for Self-Supervised Visual Pre-Training**
*Yuxin Fang, Li Dong, Hangbo Bao, Xinggang Wang, Furu Wei*
ICLR'2023 [[Paper](https://arxiv.org/abs/2202.03382)]
CIM Framework

* **Architecture-Agnostic Masked Image Modeling - From ViT back to CNN**
*Siyuan Li, Di Wu, Fang Wu, Zelin Zang, Stan.Z.Li*
ICML'2023 [[Paper](https://arxiv.org/abs/2205.13943)]
[[Code](https://github.com/Westlake-AI/openmixup)] [[project](https://github.com/Westlake-AI/A2MIM)]
A2MIM Framework
* **Masked Frequency Modeling for Self-Supervised Visual Pre-Training**
*Jiahao Xie, Wei Li, Xiaohang Zhan, Ziwei Liu, Yew Soon Ong, Chen Change Loy*
ICLR'2023 [[Paper](https://arxiv.org/abs/2206.07706)]
[[Code](https://github.com/CoinCheung/MFM)]
MFM Framework

* **MixMAE: Mixed and Masked Autoencoder for Efficient Pretraining of Hierarchical Vision Transformers**
*Jihao Liu, Xin Huang, Jinliang Zheng, Yu Liu, Hongsheng Li*
CVPR'2023 [[Paper](https://arxiv.org/abs/2205.13137)]
[[Code](https://github.com/Sense-X/MixMIM)]
MixMAE Framework

* **Masked Autoencoders are Robust Data Augmentors**
*Haohang Xu, Shuangrui Ding, Xiaopeng Zhang, Hongkai Xiong, Qi Tian*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.04846)]
[[Code](https://github.com/haohang96/mra)]
MRA Framework

* **Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling**
*Keyu Tian, Yi Jiang, Qishuai Diao, Chen Lin, Liwei Wang, Zehuan Yuan*
ICLR'2023 [[Paper](https://arxiv.org/abs/2301.03580)]
[[Code](https://github.com/keyu-tian/spark)]
SparK Framework

* **ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders**
*Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie*
CVPR'2023 [[Paper](https://arxiv.org/abs/2301.00808)]
[[Code](https://github.com/facebookresearch/ConvNeXt-V2)]
ConvNeXt.V2 Framework

* **RevColV2: Exploring Disentangled Representations in Masked Image Modeling**
*Qi Han, Yuxuan Cai, Xiangyu Zhang*
NeurIPS'2023 [[Paper](https://arxiv.org/abs/2309.01005)]
[[Code](https://github.com/megvii-research/RevCol)]
RevCol.V2 Framework

* **Masked Capsule Autoencoders**
*Miles Everett, Mingjun Zhong, Georgios Leontidis*
arXiv'2024 [[Paper](https://arxiv.org/abs/2403.04724)]
MCAE Framework

* **MixMask: Revisiting Masking Strategy for Siamese ConvNets**
*Kirill Vishniakov, Eric Xing, Zhiqiang Shen*
BMVC'2024 [[Paper](https://arxiv.org/abs/2210.11456)]
[[Code](https://github.com/LightnessOfBeing/MixMask)]
MixMask Framework

### MIM with Advanced Masking
* **MST: Masked Self-Supervised Transformer for Visual Representation**
*Zhaowen Li, Zhiyang Chen, Fan Yang, Wei Li, Yousong Zhu, Chaoyang Zhao, Rui Deng, Liwei Wu, Rui Zhao, Ming Tang, Jinqiao Wang*
NeurIPS'2021 [[Paper](https://arxiv.org/abs/2106.05656)]
MST Framework
* **Adversarial Masking for Self-Supervised Learning**
*Yuge Shi, N. Siddharth, Philip H.S. Torr, Adam R. Kosiorek*
ICML'2022 [[Paper](https://arxiv.org/abs/2201.13100)]
[[Code](https://github.com/YugeTen/adios)]
ADIOS Framework

* **What to Hide from Your Students: Attention-Guided Masked Image Modeling**
*Ioannis Kakogeorgiou, Spyros Gidaris, Bill Psomas, Yannis Avrithis, Andrei Bursuc, Konstantinos Karantzalos, Nikos Komodakis*
ECCV'2022 [[Paper](https://arxiv.org/abs/2203.12719)]
[[Code](https://github.com/gkakogeorgiou/attmask)]
AttMask Framework

* **Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality**
*Xiang Li, Wenhai Wang, Lingfeng Yang, Jian Yang*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.10063)]
[[Code](https://github.com/implus/um-mae)]
UnMAE Framework

* **SemMAE: Semantic-Guided Masking for Learning Masked Autoencoders**
*Gang Li, Heliang Zheng, Daqing Liu, Chaoyue Wang, Bing Su, Changwen Zheng*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2206.10207)]
[[Code](https://github.com/ucasligang/semmae)]
SemMAE Framework

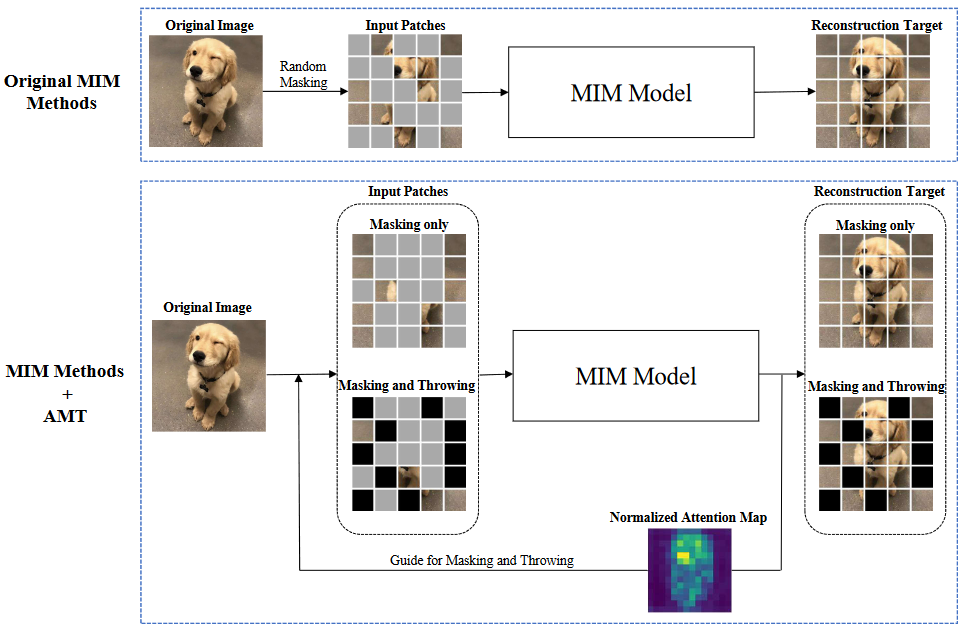
* **Good helper is around you: Attention-driven Masked Image Modeling**
*Zhengqi Liu, Jie Gui, Hao Luo*
AAAI'2023 [[Paper](https://arxiv.org/abs/2211.15362)]
[[Code](https://github.com/guijiejie/AMT)]
AMT Framework
* **Hard Patches Mining for Masked Image Modeling**
*Haochen Wang, Kaiyou Song, Junsong Fan, Yuxi Wang, Jin Xie, Zhaoxiang Zhang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2304.05919)]
[[Code](https://github.com/Haochen-Wang409/HPM)]
HPM Framework

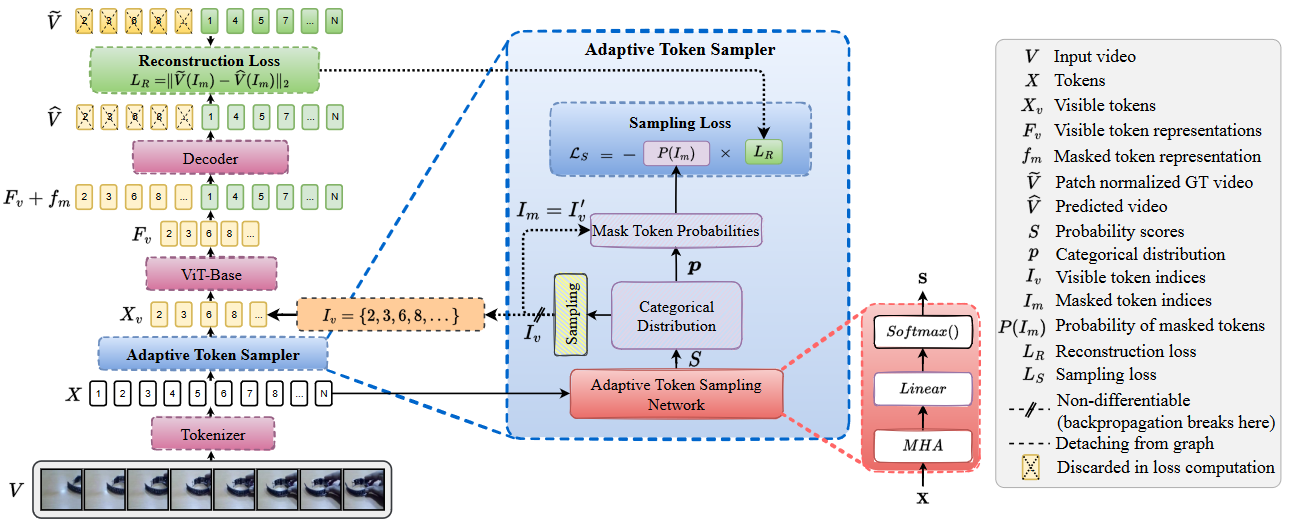
* **AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders**
*Wele Gedara Chaminda Bandara, Naman Patel, Ali Gholami, Mehdi Nikkhah, Motilal Agrawal, Vishal M. Patel*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.09120)]
[[Code](https://github.com/wgcban/adamae)]
AdaMAE Framework
* **Improving Masked Autoencoders by Learning Where to Mask**
*Haijian Chen, Wendong Zhang, Yunbo Wang, Xiaokang Yang*
arXiv'2023 [[Paper](https://arxiv.org/abs/2303.06583)]
AutoMAE Framework

* **Learning with Noisy labels via Self-supervised Adversarial Noisy Masking**
*Yuanpeng Tu, Boshen Zhang, Yuxi Li, Liang Liu, Jian Li, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Cai Rong Zhao*
arXiv'2023 [[Paper](https://arxiv.org/abs/2302.06805)]
[[Code](https://github.com/yuanpengtu/SANM)]
### MIM for Multi-Modality
* **VL-BERT: Pre-training of Generic Visual-Linguistic Representations**
*Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai*
ICLR'2020 [[Paper](https://arxiv.org/abs/1908.08530)]
[[Code](https://github.com/jackroos/VL-BERT)]
VL-BERT Framework

* **MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining**
*Xiaoyi Dong, Jianmin Bao, Yinglin Zheng, Ting Zhang, Dongdong Chen, Hao Yang, Ming Zeng, Weiming Zhang, Lu Yuan, Dong Chen, Fang Wen, Nenghai Yu*
CVPR'2023 [[Paper](https://arxiv.org/abs/2208.12262)]
[[Code](https://github.com/LightDXY/MaskCLIP)]
MaskCLIP Framework

* **Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks**
*Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, Aniruddha Kembhavi*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.08916)]
[[Code](https://arxiv.org/abs/2206.08916)]
Unified-IO Framework

* **Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks**
*Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, Furu Wei*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2208.10442)]
[[Code](https://github.com/microsoft/unilm/tree/master/beit)]
BEiT.V3 Framework

* **Masked Vision and Language Modeling for Multi-modal Representation Learning**
*Gukyeong Kwon, Zhaowei Cai, Avinash Ravichandran, Erhan Bas, Rahul Bhotika, Stefano Soatto*
ICLR'2023 [[Paper](https://arxiv.org/abs/2208.02131)]
MaskVLM Framework

* **Scaling Language-Image Pre-training via Masking**
*Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, Kaiming He*
CVPR'2023 [[Paper](https://arxiv.org/abs/2212.00794)]
FLIP Framework

* **All in Tokens: Unifying Output Space of Visual Tasks via Soft Token**
*Jia Ning, Chen Li, Zheng Zhang, Zigang Geng, Qi Dai, Kun He, Han Hu*
arXiv'2023 [[Paper](https://arxiv.org/abs/2301.02229)]
AiT Framework

* **Attentive Mask CLIP**
*Yifan Yang, Weiquan Huang, Yixuan Wei, Houwen Peng, Xinyang Jiang, Huiqiang Jiang, Fangyun Wei, Yin Wang, Han Hu, Lili Qiu, Yuqing Yang*
ICCV'2023 [[Paper](https://arxiv.org/abs/2212.08653)]
A-CLIP Framework

* **MultiModal-GPT: A Vision and Language Model for Dialogue with Humans**
*Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, Kai Chen*
arXiv'2023 [[Paper](https://arxiv.org/abs/2305.04790)]
[[Code](https://github.com/open-mmlab/Multimodal-GPT)]
MultiModal-GPT Framework
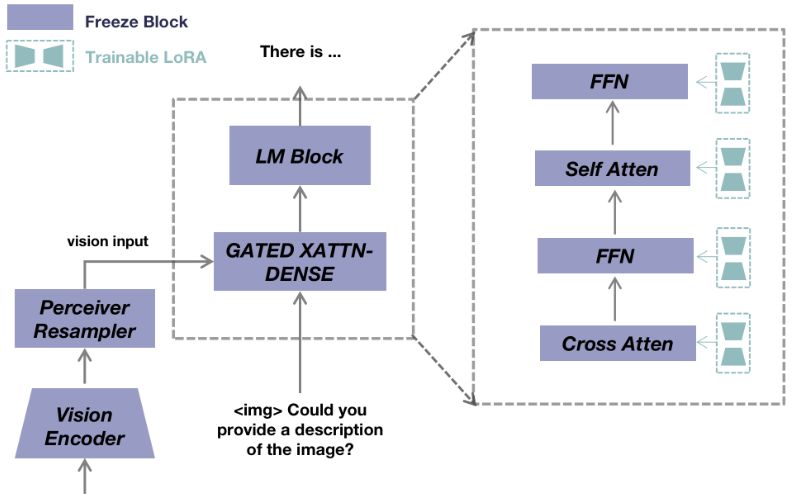
* **VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation**
*Jinguo Zhu, Xiaohan Ding, Yixiao Ge, Yuying Ge, Sijie Zhao, Hengshuang Zhao, Xiaohua Wang, Ying Shan*
arXiv'2023 [[Paper](https://arxiv.org/abs/2312.09251)]
[[Code](https://github.com/ailab-cvc/vl-gpt)]
VL-GPT Framework

* **Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action**
*Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, Aniruddha Kembhavi*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2312.17172)]
[[Code](https://github.com/allenai/unified-io-2)]
Unified-IO 2 Framework

* **Self-Guided Masked Autoencoders for Domain-Agnostic Self-Supervised Learning**
*Johnathan Wenjia Xie, Yoonho Lee, Annie S Chen, Chelsea Finn*
ICLR'2024 [[Paper](https://openreview.net/forum?id=HiYMiZYwkw)]
[[Code](https://github.com/Johnathan-Xie/sma)]
SMA Framework

### MIM for Vision Generalist Model
* **A Generalist Agent**
*Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, Nando de Freitas*
TMLR'2022 [[Paper](https://arxiv.org/abs/2205.06175)]
[[Code](https://github.com/OrigamiDream/gato)]
Gato Framework

* **Scaling Autoregressive Models for Content-Rich Text-to-Image Generation**
*Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, Yonghui Wu*
TMLR'2022 [[Paper](https://openreview.net/forum?id=AFDcYJKhND)]
Parti Framework

* **Images Speak in Images: A Generalist Painter for In-Context Visual Learning**
*Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, Tiejun Huang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2212.02499)]
[[Code](https://github.com/baaivision/Painter)]
Painter Framework

* **InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists**
*Yulu Gan, Sungwoo Park, Alexander Schubert, Anthony Philippakis, Ahmed M. Alaa*
arXiv'2023 [[Paper](https://arxiv.org/abs/2310.00390)]
[[Code](https://github.com/AlaaLab/InstructCV)]
InstructCV Framework

* **InstructDiffusion: A Generalist Modeling Interface for Vision Tasks**
*Zigang Geng, Binxin Yang, Tiankai Hang, Chen Li, Shuyang Gu, Ting Zhang, Jianmin Bao, Zheng Zhang, Han Hu, Dong Chen, Baining Guo*
arXiv'2023 [[Paper](https://arxiv.org/abs/2309.03895)]
InstructDiffusion Framework

* **Sequential Modeling Enables Scalable Learning for Large Vision Models**
*Yutong Bai, Xinyang Geng, Karttikeya Mangalam, Amir Bar, Alan Yuille, Trevor Darrell, Jitendra Malik, Alexei A Efros*
arXiv'2023 [[Paper](https://arxiv.org/abs/2312.00785)]
[[Code](https://yutongbai.com/lvm.html)]
LVM Framework
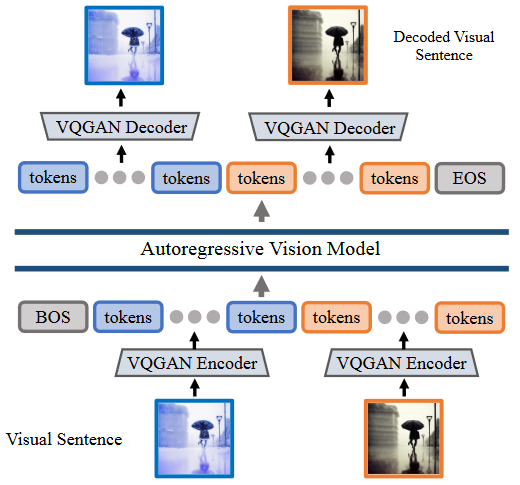
### Image Generation
* **Discrete Variational Autoencoders**
*Jason Tyler Rolfe*
ICLR'2017
[[Paper](https://arxiv.org/abs/1609.02200)]
[[Code](https://github.com/openai/DALL-E)]
* **Neural Discrete Representation Learning**
*Aaron van den Oord, Oriol Vinyals, Koray Kavukcuoglu*
NeurIPS'2017
[[Paper](https://proceedings.neurips.cc/paper/2017/file/7a98af17e63a0ac09ce2e96d03992fbc-Paper.pdf)]
[[Code](https://github.com/ritheshkumar95/pytorch-vqvae)]
* **Theory and Experiments on Vector Quantized Autoencoders (EM VQ-VAE)**
*Aurko Roy, Ashish Vaswani, Arvind Neelakantan, Niki Parmar*
Arxiv'2018
[[Paper](https://arxiv.org/abs/1805.11063)]
[[Code](https://github.com/jaywalnut310/Vector-Quantized-Autoencoders)]
* **DVAE: Discrete Variational Autoencoders with Relaxed Boltzmann Priors**
*Arash Vahdat, Evgeny Andriyash, William G. Macready*
NeurIPS'2018
[[Paper](https://arxiv.org/abs/1805.07445)]
[[Code](https://github.com/xmax1/dvae)]
* **DVAE++: Discrete Variational Autoencoders with Overlapping Transformations**
*Arash Vahdat, William G. Macready, Zhengbing Bian, Amir Khoshaman, Evgeny Andriyash*
ICML'2018
[[Paper](https://arxiv.org/abs/1802.04920)]
[[Code](https://github.com/xmax1/dvae)]
* **Generating Diverse High-Fidelity Images with VQ-VAE-2**
*Ali Razavi, Aaron van den Oord, Oriol Vinyals*
NeurIPS'2019
[[Paper](https://proceedings.neurips.cc/paper/2019/file/5f8e2fa1718d1bbcadf1cd9c7a54fb8c-Paper.pdf)]
[[Code](https://github.com/rosinality/vq-vae-2-pytorch)]
* **Generative Pretraining from Pixels**
*Mark Chen, Alec Radford, Rewon Child, Jeff Wu, Heewoo Jun, David Luan, Ilya Sutskever*
ICML'2020 [[Paper](http://proceedings.mlr.press/v119/chen20s/chen20s.pdf)]
[[Code](https://github.com/openai/image-gpt)]
iGPT Framework
* **Taming Transformers for High-Resolution Image Synthesis**
*Patrick Esser, Robin Rombach, Björn Ommer*
CVPR'2021 [[Paper](https://arxiv.org/abs/2012.09841)]
[[Code](https://github.com/CompVis/taming-transformers)]
VQGAN Framework

* **MaskGIT: Masked Generative Image Transformer**
*Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, William T. Freeman*
CVPR'2022 [[Paper](https://arxiv.org/abs/2202.04200)]
[[Code](https://github.com/google-research/maskgit)]
MaskGIT Framework

* **ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation**
*Han Zhang, Weichong Yin, Yewei Fang, Lanxin Li, Boqiang Duan, Zhihua Wu, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang*
Arxiv'2021
[[Paper](https://arxiv.org/abs/2112.15283)]
[[Project](https://wenxin.baidu.com/wenxin/ernie-vilg)]
* **NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion**
*Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, Nan Duan*
Arxiv'2021
[[Paper](https://arxiv.org/abs/2111.12417)]
[[Code](https://github.com/microsoft/NUWA)]
* **ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis**
*Patrick Esser, Robin Rombach, Andreas Blattmann, Björn Ommer*
NeurIPS'2021
[[Paper](https://openreview.net/pdf?id=-1AAgrS5FF)]
[[Code](https://github.com/CompVis/imagebart)]
[[Project](https://compvis.github.io/imagebart/)]
* **Vector-quantized Image Modeling with Improved VQGAN**
*Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, Yonghui Wu*
ICLR'2022 [[Paper](https://arxiv.org/abs/2110.04627)]
[[Code](https://github.com/lucidrains/DALLE2-pytorch)]
ViT-VQGAN Framework

* **Self-supervision through Random Segments with Autoregressive Coding (RandSAC)**
*Tianyu Hua, Yonglong Tian, Sucheng Ren, Michalis Raptis, Hang Zhao, Leonid Sigal*
ICLR'2023 [[Paper](https://arxiv.org/abs/2203.12054)]
RandSAC Framework

* **MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis**
*Tianhong Li, Huiwen Chang, Shlok Kumar Mishra, Han Zhang, Dina Katabi, Dilip Krishnan*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.09117)]
[[Code](https://github.com/lth14/mage)]
MAGE Framework

* **Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation**
*Mengqi Huang, Zhendong Mao, Quan Wang, Yongdong Zhang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2305.13607)]
[[Code](https://github.com/CrossmodalGroup/MaskedVectorQuantization)]
MQ-VAE Framework

* **Towards Accurate Image Coding: Improved Autoregressive Image Generation with Dynamic Vector Quantization**
*Mengqi Huang, Zhendong Mao, Zhuowei Chen, Yongdong Zhang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2305.11718)]
[[Code](https://github.com/CrossmodalGroup/DynamicVectorQuantization)]
DQ-VAE Framework

* **Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment**
*Hao Liu, Wilson Yan, Pieter Abbeel*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2302.00902)]
[[Code](https://github.com/lhao499/language-quantized-autoencoders)]
LQAE Framework

* **SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs**
*Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David A. Ross, Irfan Essa, Yonatan Bisk, Ming-Hsuan Yang, Kevin Murphy, Alexander G. Hauptmann, Lu Jiang*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2306.17842)]
[[Code](https://github.com/google-research/magvit/)]
SPAE Framework

* **Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models**
*Jaewoong Lee, Sangwon Jang, Jaehyeong Jo, Jaehong Yoon, Yunji Kim, Jin-Hwa Kim, Jung-Woo Ha, Sung Ju Hwang*
ICCV'2023 [[Paper](https://arxiv.org/abs/2304.01515)]
TCTS Framework
* **Diffusion Models as Masked Autoencoders**
*Chen Wei, Karttikeya Mangalam, Po-Yao Huang, Yanghao Li, Haoqi Fan, Hu Xu, Huiyu Wang, Cihang Xie, Alan Yuille, Christoph Feichtenhofer*
ICCV'2023 [[Paper](https://arxiv.org/abs/2304.03283)]
[[Code](https://weichen582.github.io/diffmae.html)]
TCTS Framework

* **Masked Diffusion Transformer is a Strong Image Synthesizer**
*Shanghua Gao, Pan Zhou, Ming-Ming Cheng, Shuicheng Yan*
ICCV'2023 [[Paper](https://arxiv.org/abs/2303.14389)]
[[Code](https://github.com/sail-sg/MDT)]
MDT Framework

* **Self-conditioned Image Generation via Generating Representations**
*Tianhong Li, Dina Katabi, Kaiming He*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2312.03701)]
[[Code](https://github.com/LTH14/rcg)]
RCG Framework
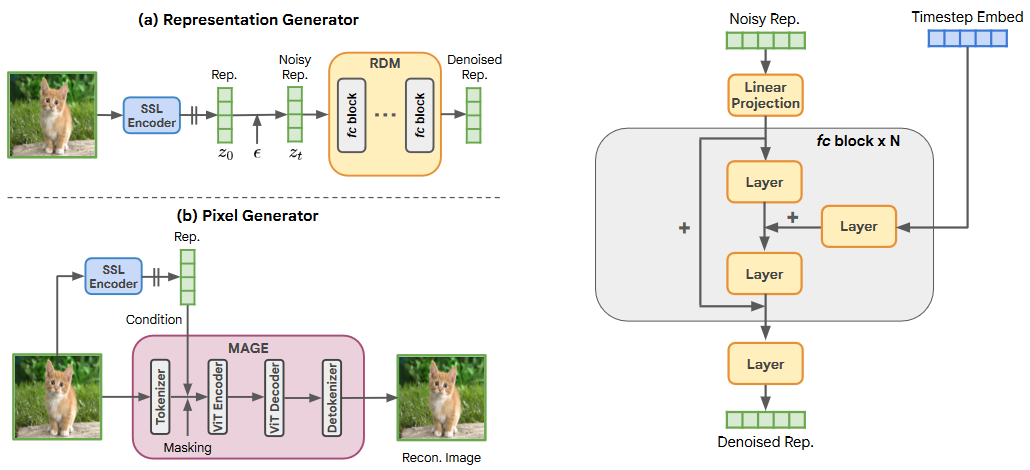
* **OneLLM: One Framework to Align All Modalities with Language**
*Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, Xiangyu Yue*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2312.03700)]
[[Code](https://github.com/csuhan/OneLLM)]
OneLLM Framework
* **MDTv2: Masked Diffusion Transformer is a Strong Image Synthesizer**
*Shanghua Gao, Pan Zhou, Ming-Ming Cheng, Shuicheng Yan*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2303.14389)]
[[Code](https://github.com/sail-sg/MDT)]
MDTv2 Framework

* **Beyond Text: Frozen Large Language Models in Visual Signal Comprehension**
*Lei Zhu, Fangyun Wei, Yanye Lu*
CVPR'2024 [[Paper](https://arxiv.org/abs/2403.07874)]
[[Code](https://github.com/zh460045050/V2L-Tokenizer)]
V2L Framework
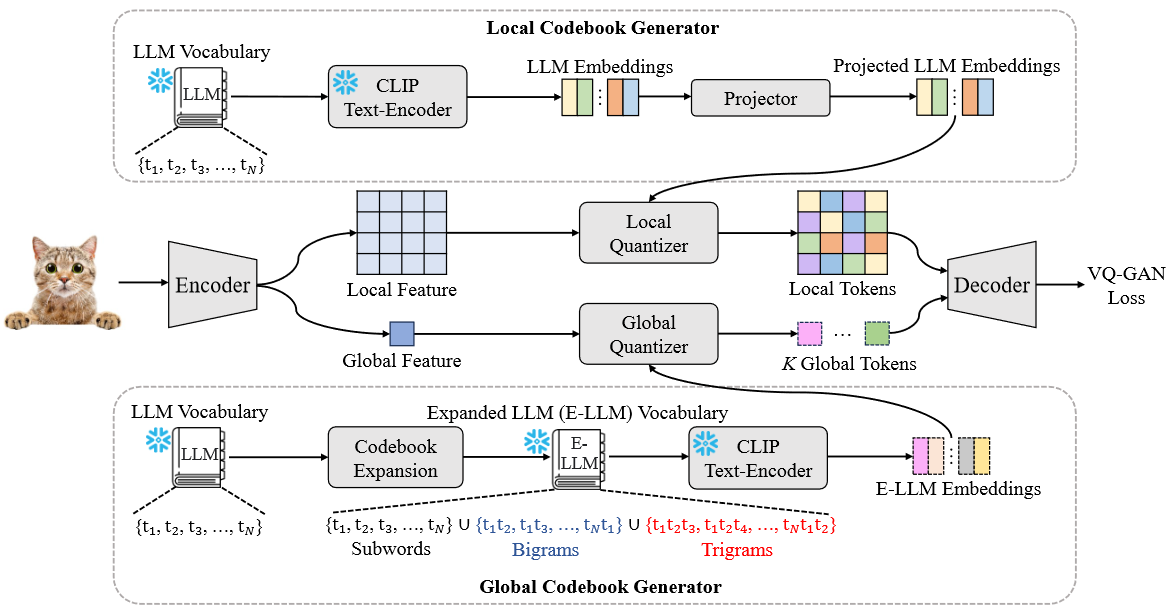
* **Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation**
*Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, Zehuan Yuan*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2406.06525)]
[[Code](https://github.com/FoundationVision/LlamaGen)]
* **Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%**
*Lei Zhu, Fangyun Wei, Yanye Lu, Dong Chen*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2406.11837)]
[[Code](https://github.com/zh460045050/VQGAN-LC)]
VQGAN-LC Framework

## MIM for CV Downstream Tasks
### Object Detection and Segmentation
* **Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection**
*Yuxin Fang, Shusheng Yang, Shijie Wang, Yixiao Ge, Ying Shan, Xinggang Wang*
ICCV'2023 [[Paper](https://arxiv.org/abs/2204.02964)]
[[Code](https://github.com/hustvl/MIMDet)]
MIMDet Framework

* **SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers**
*Guoqiang Jin, Fan Yang, Mingshan Sun, Ruyi Zhao, Yakun Liu, Wei Li, Tianpeng Bao, Liwei Wu, Xingyu Zeng, Rui Zhao*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2303.08481)]
SeqCo-DETR Framework

* **Integrally Pre-Trained Transformer Pyramid Networks**
*Yunjie Tian, Lingxi Xie, Zhaozhi Wang, Longhui Wei, Xiaopeng Zhang, Jianbin Jiao, Yaowei Wang, Qi Tian, Qixiang Ye*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.12735)]
[[Code](https://github.com/sunsmarterjie/iTPN)]
iTPN Framework

* **PiMAE: Point Cloud and Image Interactive Masked Autoencoders for 3D Object Detection**
*Anthony Chen, Kevin Zhang, Renrui Zhang, Zihan Wang, Yuheng Lu, Yandong Guo, Shanghang Zhang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2303.08129)]
[[Code](https://github.com/BLVLab/PiMAE)]
PiMAE Framework

* **Integrally Migrating Pre-trained Transformer Encoder-decoders for Visual Object Detection**
*Yuan Liu, Songyang Zhang, Jiacheng Chen, Zhaohui Yu, Kai Chen, Dahua Lin*
ICCV'2023 [[Paper](https://arxiv.org/abs/2205.09613)]
[[Code](https://github.com/LiewFeng/imTED)]
imTED Framework

* **Masked Retraining Teacher-student Framework for Domain Adaptive Object Detection**
*Zijing Zhao, Sitong Wei, Qingchao Chen, Dehui Li, Yifan Yang, Yuxin Peng, Yang Liu*
ICCV'2023 [[Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Zhao_Masked_Retraining_Teacher-Student_Framework_for_Domain_Adaptive_Object_Detection_ICCV_2023_paper.pdf)]
[[Code](https://github.com/JeremyZhao1998/MRT-release)]
MRT Framework

* **Object Recognition as Next Token Prediction**
*Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, Ser-Nam Lim*
arXiv'2023 [[Paper](https://arxiv.org/abs/2312.02142)]
[[Code](https://github.com/kaiyuyue/nxtp)]
imTED Framework

* **EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything**
*Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra*
CVPR'2024 [[Paper](https://arxiv.org/abs/2312.00863)]
[[Code](https://github.com/yformer/EfficientSAM)]
EfficientSAM Framework

### Video Rrepresentation
* **VideoGPT: Video Generation using VQ-VAE and Transformers**
*Wilson Yan, Yunzhi Zhang, Pieter Abbeel, Aravind Srinivas*
arXiv'2021 [[Paper](https://arxiv.org/abs/2104.10157)]
[[Code](https://github.com/wilson1yan/VideoGPT)]
VideoGPT Framework

* **VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training**
*Zhan Tong, Yibing Song, Jue Wang, Limin Wang*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2203.12602)]
[[Code](https://github.com/MCG-NJU/VideoMAE)]
VideoMAE Framework

* **Masked Autoencoders As Spatiotemporal Learners**
*Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, Kaiming He*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2205.09113)]
[[Code](https://github.com/facebookresearch/SlowFast)]
MAE Framework

* **Less is More: Consistent Video Depth Estimation with Masked Frames Modeling**
*Yiran Wang, Zhiyu Pan, Xingyi Li, Zhiguo Cao, Ke Xian, Jianming Zhang*
ACMMM'2022 [[Paper](https://arxiv.org/abs/2208.00380)]
[[Code](https://github.com/RaymondWang987/FMNet)]
FMNet Framework

* **MaskViT: Masked Visual Pre-Training for Video Prediction**
*Agrim Gupta, Stephen Tian, Yunzhi Zhang, Jiajun Wu, Roberto Martín-Martín, Li Fei-Fei*
CVPR'2022 [[Paper](https://arxiv.org/abs/2206.11894)]
[[Code](https://github.com/agrimgupta92/maskvit)]
MaskViT Framework

* **BEVT: BERT Pretraining of Video Transformers**
*Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, Lu Yuan*
CVPR'2022 [[Paper](https://arxiv.org/abs/2112.01529)]
[[Code](https://github.com/xyzforever/BEVT)]
BEVT Framework

* **MILES: Visual BERT Pre-training with Injected Language Semantics for Video-text Retrieval**
*Yuying Ge, Yixiao Ge, Xihui Liu, Alex Jinpeng Wang, Jianping Wu, Ying Shan, Xiaohu Qie, Ping Luo*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2204.12408)]
[[Code](https://github.com/tencentarc/mcq)]
MILES Framework

* **MAR: Masked Autoencoders for Efficient Action Recognition**
*Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Xiang Wang, Yuehuan Wang, Yiliang Lv, Changxin Gao, Nong Sang*
ArXiv'2022 [[Paper](http://arxiv.org/abs/2207.11660)]
MAR Framework

* **Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders**
*Haosen Yang, Deng Huang, Bin Wen, Jiannan Wu, Hongxun Yao, Yi Jiang, Xiatian Zhu, Zehuan Yuan*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.04154)]
[[Code](https://github.com/happy-hsy/MotionMAE)]
MotionMAE Framework

* **It Takes Two: Masked Appearance-Motion Modeling for Self-supervised Video Transformer Pre-training**
*Yuxin Song, Min Yang, Wenhao Wu, Dongliang He, Fu Li, Jingdong Wang*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.05234)]
MAM2 Framework

* **NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion**
*Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, Nan Duan*
ECCV'2022 [[Paper](https://arxiv.org/abs/2111.12417)]
[[Code](https://github.com/microsoft/NUWA)]
NUWA Framework
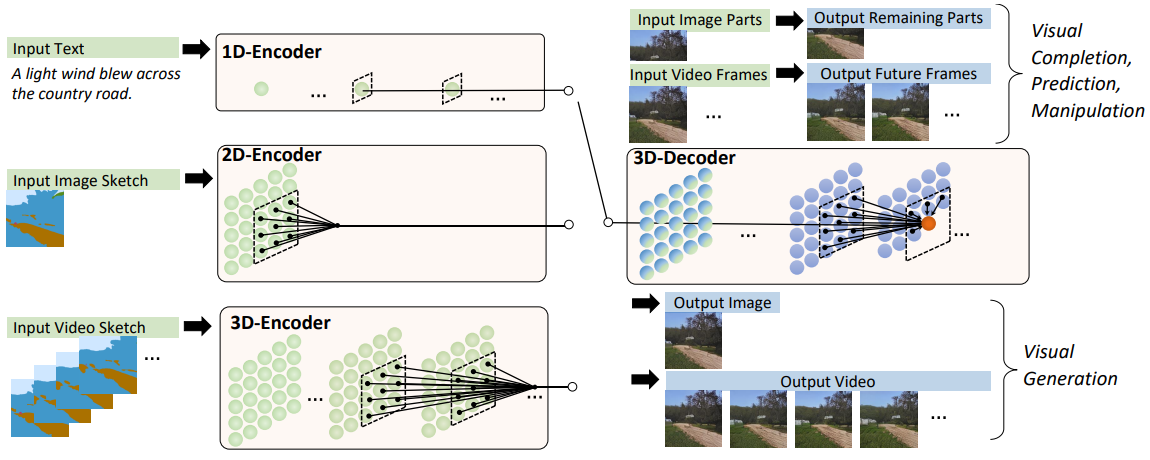
* **MIMT: Masked Image Modeling Transformer for Video Compression**
*Jinxi Xiang, Kuan Tian, Jun Zhang*
ICLR'2023 [[Paper](https://openreview.net/forum?id=j9m-mVnndbm)]
MIMT Framework

* **VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking**
*Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, Yu Qiao*
CVPR'2023 [[Paper](https://arxiv.org/abs/2303.16727)]
[[Code](https://github.com/MCG-NJU/VideoMAE)]
VideoMAE.V2 Framework

* **OmniMAE: Single Model Masked Pretraining on Images and Videos**
*Rohit Girdhar, Alaaeldin El-Nouby, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra*
CVPR'2023 [[Paper](http://arxiv.org/abs/2206.08356)]
[[Code](https://github.com/facebookresearch/omnivore)]
OmniMAE Framework

* **Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning**
*Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Lu Yuan, Yu-Gang Jiang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2212.04500)]
[[Code](https://github.com/ruiwang2021/mvd)]
MVD Framework

* **DropMAE: Masked Autoencoders with Spatial-Attention Dropout for Tracking Tasks**
*Qiangqiang Wu, Tianyu Yang, Ziquan Liu, Baoyuan Wu, Ying Shan, Antoni B. Chan*
CVPR'2023 [[Paper](https://arxiv.org/abs/2304.00571)]
[[Code](https://github.com/jimmy-dq/dropmae)]
DropMAE Framework

* **AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders**
*Wele Gedara Chaminda Bandara, Naman Patel, Ali Gholami, Mehdi Nikkhah, Motilal Agrawal, Vishal M. Patel*
CVPR'2023 [[Paper](https://arxiv.org/abs/2211.09120)]
[[Code](https://github.com/wgcban/adamae)]
AdaMAE Framework

* **MAGVIT: Masked Generative Video Transformer**
*Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, Lu Jiang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2212.05199)]
[[Code](https://github.com/MAGVIT/magvit)]
MAGVIT Framework

* **CMAE-V: Contrastive Masked Autoencoders for Video Action Recognition**
*Cheng-Ze Lu, Xiaojie Jin, Zhicheng Huang, Qibin Hou, Ming-Ming Cheng, Jiashi Feng*
arXiv'2023 [[Paper](https://arxiv.org/abs/2301.06018)]
CMAE-V Framework

* **Siamese Masked Autoencoders**
*Agrim Gupta, Jiajun Wu, Jia Deng, Li Fei-Fei*
NeurIPS'2023 [[Paper](https://arxiv.org/abs/2305.14344)]
[[Code](https://siam-mae-video.github.io/)]
SiamMAE Framework

* **MGMAE: Motion Guided Masking for Video Masked Autoencoding**
*Bingkun Huang, Zhiyu Zhao, Guozhen Zhang, Yu Qiao, Limin Wang*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.10794)]
[[Code](https://github.com/MCG-NJU/MGMAE)]
MGMAE Framework

* **Forecast-MAE: Self-supervised Pre-training for Motion Forecasting with Masked Autoencoders**
*Jie Cheng, Xiaodong Mei, Ming Liu*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.09882)]
[[Code](https://github.com/jchengai/forecast-mae)]
Forecast-MAE Framework
* **Traj-MAE: Masked Autoencoders for Trajectory Prediction**
*Hao Chen, Jiaze Wang, Kun Shao, Furui Liu, Jianye Hao, Chenyong Guan, Guangyong Chen, Pheng-Ann Heng*
ICCV'2023 [[Paper](https://arxiv.org/abs/2303.06697)]
Traj-MAE Framework

* **HumanMAC: Masked Motion Completion for Human Motion Prediction**
*Ling-Hao Chen, Jiawei Zhang, Yewen Li, Yiren Pang, Xiaobo Xia, Tongliang Liu*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.07092)]
[[Code](https://github.com/linghaochan/humanmac)]
HumanMAC Framework

* **SkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training**
*Hong Yan, Yang Liu, Yushen Wei, Zhen Li, Guanbin Li, Liang Lin*
ICCV'2023 [[Paper](https://arxiv.org/abs/2307.08476)]
[[Code](https://github.com/HongYan1123/SkeletonMAE)]
SkeletonMAE Framework

* **Masked Motion Predictors are Strong 3D Action Representation Learners**
*Ling-Hao Chen, Jiawei Zhang, Yewen Li, Yiren Pang, Xiaobo Xia, Tongliang Liu*
ICCV'2023 [[Paper](https://arxiv.org/abs/2302.03665)]
[[Code](https://github.com/maoyunyao/MAMP)]
MAMP Framework

* **GeoMIM: Towards Better 3D Knowledge Transfer via Masked Image Modeling for Multi-view 3D Understanding**
*Jihao Liu, Tai Wang, Boxiao Liu, Qihang Zhang, Yu Liu, Hongsheng Li*
ICCV'2023 [[Paper](https://arxiv.org/abs/2303.11325)]
[[Code](https://github.com/Sense-X/GeoMIM)]
GeoMIM Framework

* **Motion-Guided Masking for Spatiotemporal Representation Learning**
*David Fan, Jue Wang, Shuai Liao, Yi Zhu, Vimal Bhat, Hector Santos-Villalobos, Rohith MV, Xinyu Li*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.12962)]
MGM Framework

* **ModelScope Text-to-Video Technical Report**
*Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, Shiwei Zhang*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2308.06571)]
[[Code](https://modelscope.cn/models/iic/text-to-video-synthesis/summary)]
ModelScopeT2V Framework

* **NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis**
*Chenfei Wu, Jian Liang, Xiaowei Hu, Zhe Gan, Jianfeng Wang, Lijuan Wang, Zicheng Liu, Yuejian Fang, Nan Duan*
NeurIPS'2023 [[Paper](https://arxiv.org/abs/2207.09814)]
[[Code](https://github.com/microsoft/NUWA)]
NUWA-Infinity Framework
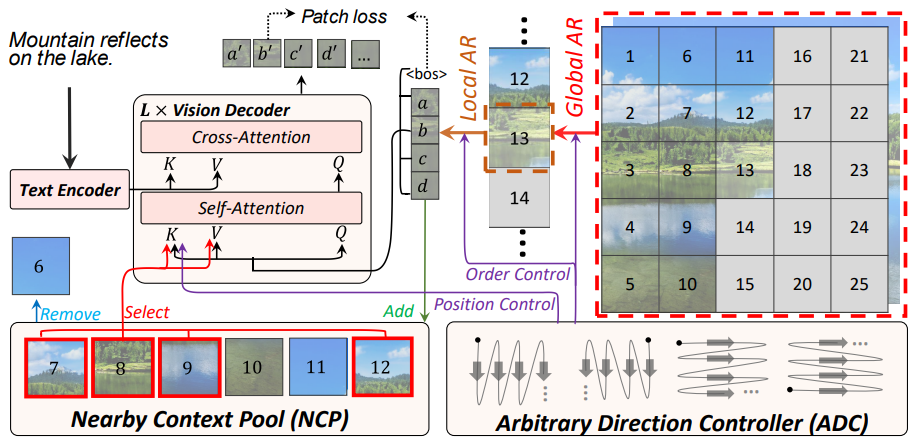
* **NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation**
*Shengming Yin, Chenfei Wu, Huan Yang, Jianfeng Wang, Xiaodong Wang, Minheng Ni, Zhengyuan Yang, Linjie Li, Shuguang Liu, Fan Yang, Jianlong Fu, Gong Ming, Lijuan Wang, Zicheng Liu, Houqiang Li, Nan Duan*
ACL'2023 [[Paper](https://arxiv.org/abs/2303.12346)]
[[Code](https://github.com/microsoft/NUWA)]
NUWA-XL Framework

* **VDT: General-purpose Video Diffusion Transformers via Mask Modeling**
*Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, Mingyu Ding*
ICLR'2024 [[Paper](https://openreview.net/forum?id=Un0rgm9f04)]
[[Code](https://github.com/RERV/VDT)]
VDT Framework

### Knowledge Distillation and Few-shot Classification
* **Generic-to-Specific Distillation of Masked Autoencoders**
*Wei Huang, Zhiliang Peng, Li Dong, Furu Wei, Jianbin Jiao, Qixiang Ye*
CVPR'2023 [[Paper](https://arxiv.org/abs/2302.14771)]
[[Code](https://github.com/pengzhiliang/G2SD)]
G2SD Framework

* **Masked Autoencoders Enable Efficient Knowledge Distillers**
*Yutong Bai, Zeyu Wang, Junfei Xiao, Chen Wei, Huiyu Wang, Alan Yuille, Yuyin Zhou, Cihang Xie*
CVPR'2023 [[Paper](https://arxiv.org/abs/2208.12256)]
[[Code](https://github.com/UCSC-VLAA/DMAE)]
DMAE Framework

* **Mask-guided Vision Transformer (MG-ViT) for Few-Shot Learning**
*Yuzhong Chen, Zhenxiang Xiao, Lin Zhao, Lu Zhang, Haixing Dai, David Weizhong Liu, Zihao Wu, Changhe Li, Tuo Zhang, Changying Li, Dajiang Zhu, Tianming Liu, Xi Jiang*
ICLR'2023 [[Paper](http://arxiv.org/abs/2205.09995)]
MG-ViT Framework
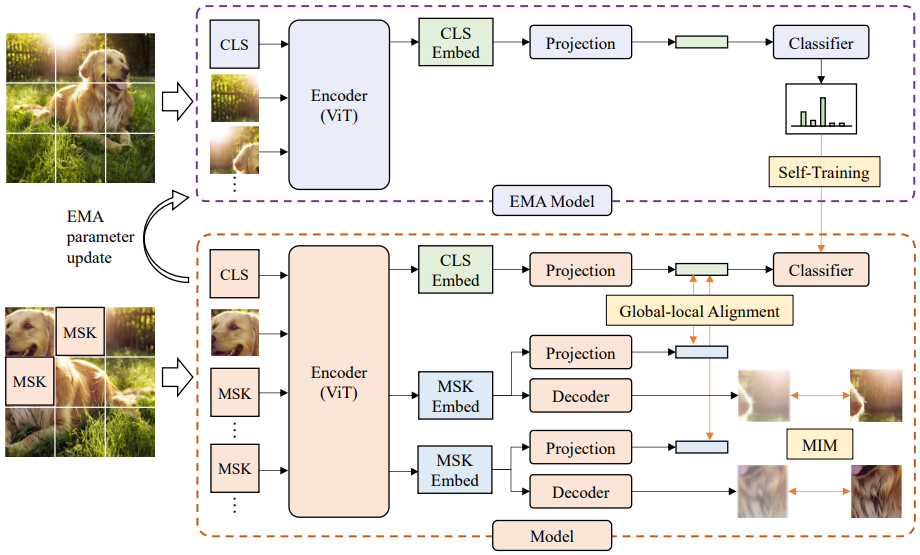
* **Masked Autoencoders Are Stronger Knowledge Distillers**
*Shanshan Lao, Guanglu Song, Boxiao Liu, Yu Liu, Yujiu Yang*
ICCV'2023 [[Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Lao_Masked_Autoencoders_Are_Stronger_Knowledge_Distillers_ICCV_2023_paper.pdf)]
MKD Framework

### Efficient Fine-tuning
* **Masked Images Are Counterfactual Samples for Robust Fine-tuning**
*Yao Xiao, Ziyi Tang, Pengxu Wei, Cong Liu, Liang Lin*
CVPR'2023 [[Paper](https://arxiv.org/abs/2303.03052)]
[[Code](https://github.com/Coxy7/robust-finetuning)]
Robust Finetuning Framework

* **Contrastive Tuning: A Little Help to Make Masked Autoencoders Forget**
*Johannes Lehner, Benedikt Alkin, Andreas Fürst, Elisabeth Rumetshofer, Lukas Miklautz, Sepp Hochreiter*
arXiv'2023 [[Paper](https://arxiv.org/abs/2304.10520)]
[[Code](https://github.com/ml-jku/MAE-CT)]
MAE-CT Framework

* **Masked Autoencoders are Efficient Class Incremental Learners**
*Jiang-Tian Zhai, Xialei Liu, Andrew D. Bagdanov, Ke Li, Ming-Ming Cheng*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.12510)]
[[Code](https://github.com/scok30/mae-cil)]
MAE-CIL Framework

* **MaskMatch: Boosting Semi-Supervised Learning Through Mask Autoencoder-Driven Feature Learning**
*Wenjin Zhang, Keyi Li, Sen Yang, Chenyang Gao, Wanzhao Yang, Sifan Yuan, Ivan Marsic*
arXiv'2024 [[Paper](https://arxiv.org/abs/2405.06227)]
MaskMatch Framework

* **Pseudo Labelling for Enhanced Masked Autoencoders**
*Srinivasa Rao Nandam, Sara Atito, Zhenhua Feng, Josef Kittler, Muhammad Awais*
arXiv'2024 [[Paper](https://arxiv.org/abs/2406.17450)]
SdAE Framework

### Medical Image
* **Self Pre-training with Masked Autoencoders for Medical Image Analysis**
*Lei Zhou, Huidong Liu, Joseph Bae, Junjun He, Dimitris Samaras, Prateek Prasanna*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2203.05573)]
* **Self-distillation Augmented Masked Autoencoders for Histopathological Image Classification**
*Yang Luo, Zhineng Chen, Xieping Gao*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2203.16983)]
* **Global Contrast Masked Autoencoders Are Powerful Pathological Representation Learners**
*Hao Quan, Xingyu Li, Weixing Chen, Qun Bai, Mingchen Zou, Ruijie Yang, Tingting Zheng, Ruiqun Qi, Xinghua Gao, Xiaoyu Cui*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.09048)] [[Code](https://github.com/staruniversus/gcmae)]
* **FreMAE: Fourier Transform Meets Masked Autoencoders for Medical Image Segmentation**
*Wenxuan Wang, Jing Wang, Chen Chen, Jianbo Jiao, Lichao Sun, Yuanxiu Cai, Shanshan Song, Jiangyun Li*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2304.10864)]
* **Masked Image Modeling Advances 3D Medical Image Analysis**
*Zekai Chen, Devansh Agarwal, Kshitij Aggarwal, Wiem Safta, Samit Hirawat, Venkat Sethuraman, Mariann Micsinai Balan, Kevin Brown*
WACV'2023 [[Paper](https://arxiv.org/abs/2204.11716)] [[Code](https://github.com/ZEKAICHEN/MIM-Med3D)]
* **MRM: Masked Relation Modeling for Medical Image Pre-Training with Genetics**
*Qiushi Yang, Wuyang Li, Baopu Li, Yixuan Yuan*
ICCV'2023 [[Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Yang_MRM_Masked_Relation_Modeling_for_Medical_Image_Pre-Training_with_Genetics_ICCV_2023_paper.pdf)] [[Code](https://github.com/CityU-AIM-Group/MRM)]
* **FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders**
*Soumen Basu, Mayuna Gupta, Chetan Madan, Pankaj Gupta, Chetan Arora*
CVPR'2024 [[Paper](https://arxiv.org/abs/2403.08848)] [[Code](https://github.com/sbasu276/FocusMAE)]
### Face Recognition
* **FaceMAE: Privacy-Preserving Face Recognition via Masked Autoencoders**
*Kai Wang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Jiankang Deng, Xinchao Wang, Hakan Bilen, Yang You*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.11090)] [Code](https://github.com/kaiwang960112/FaceMAE)]
### Scene Text Recognition (OCR)
* **MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining**
*Pengyuan Lyu, Chengquan Zhang, Shanshan Liu, Meina Qiao, Yangliu Xu, Liang Wu, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.00311)]
* **DiT: Self-supervised Pre-training for Document Image Transformer**
*Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei*
ACMMM'2022 [[Paper](https://arxiv.org/abs/2203.02378)] [Code](https://github.com/microsoft/unilm/tree/master/dit)]
[[Code](https://github.com/scok30/mae-cil)]
DiT Framework

* **DocMAE: Document Image Rectification via Self-supervised Representation Learning**
*Shaokai Liu, Hao Feng, Wengang Zhou, Houqiang Li, Cong Liu, Feng Wu*
ICME'2023 [[Paper](https://arxiv.org/abs/2304.10341)]
### Remote Sensing Image
* **SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery**
*Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David B. Lobell, Stefano Ermon*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2207.08051)]
* **CMID: A Unified Self-Supervised Learning Framework for Remote Sensing Image Understanding**
*Dilxat Muhtar, Xueliang Zhang, Pengfeng Xiao, Zhenshi Li, Feng Gu*
TGRS'2023 [[Paper](https://arxiv.org/abs/2304.09670)] [[Code](https://github.com/NJU-LHRS/official-CMID)]
* **Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning**
*Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, Trevor Darrell*
ICCV'2023 [[Paper](https://arxiv.org/abs/2212.14532)]
* **SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification**
*Junyan Lin, Feng Gao, Xiaocheng Shi, Junyu Dong, Qian Du*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2311.04442)]
* **On the Transferability of Learning Models for Semantic Segmentation for Remote Sensing Data**
*Rongjun Qin, Guixiang Zhang, Yang Tang*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2310.10490)]
* **Fus-MAE: A cross-attention-based data fusion approach for Masked Autoencoders in remote sensing**
*Hugo Chan-To-Hing, Bharadwaj Veeravalli*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2401.02764)]
* **S2MAE: A Spatial-Spectral Pretraining Foundation Model for Spectral Remote Sensing Data**
*Xuyang Li, Danfeng Hong, Jocelyn Chanussot*
CVPR'2024 [[Paper](https://openaccess.thecvf.com/content/CVPR2024/html/Li_S2MAE_A_Spatial-Spectral_Pretraining_Foundation_Model_for_Spectral_Remote_Sensing_CVPR_2024_paper.html)]
### 3D Representation Learning
* **Pre-Training 3D Point Cloud Transformers with Masked Point Modeling**
*Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, Jiwen Lu*
CVPR'2022 [[Paper](https://arxiv.org/abs/2111.14819)] [[Code](https://github.com/lulutang0608/Point-BERT)]
* **Masked Autoencoders for Point Cloud Self-supervised Learning**
*Yatian Pang, Wenxiao Wang, Francis E.H. Tay, Wei Liu, Yonghong Tian, Li Yuan*
ECCV'2022 [[Paper](https://arxiv.org/abs/2203.06604)] [[Code](https://github.com/Pang-Yatian/Point-MAE)]
* **Masked Discrimination for Self-Supervised Learning on Point Clouds**
*Haotian Liu, Mu Cai, Yong Jae Lee*
ECCV'2022 [[Paper](https://arxiv.org/abs/2203.11183)] [[Code](https://github.com/haotian-liu/MaskPoint)]
* **MeshMAE: Masked Autoencoders for 3D Mesh Data Analysis**
*Yaqian Liang, Shanshan Zhao, Baosheng Yu, Jing Zhang, Fazhi He*
ECCV'2022 [[Paper](http://arxiv.org/abs/2207.10228)]
* **Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds**
*Chen Min, Xinli Xu, Dawei Zhao, Liang Xiao, Yiming Nie, Bin Dai*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.09900)]
* **Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training**
*Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, Hongsheng Li*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2205.14401)]
* **Ponder: Point Cloud Pre-training via Neural Rendering**
*Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, Hongsheng Li*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2301.00157)] [[Code](https://dihuangdh.github.io/ponder)]
* **Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders**
*Renrui Zhang, Liuhui Wang, Yu Qiao, Peng Gao, Hongsheng Li*
CVPR'2023 [[Paper](https://arxiv.org/abs/2212.06785)] [[Code](https://github.com/zrrskywalker/point-m2ae)]
* **GeoMAE: Masked Geometric Target Prediction for Self-supervised Point Cloud Pre-Training**
*Xiaoyu Tian, Haoxi Ran, Yue Wang, Hang Zhao*
CVPR'2023 [[Paper](https://arxiv.org/abs/2305.08808)] [[Code](https://github.com/ZrrSkywalker/I2P-MAE)]
* **VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion**
*Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M. Alvarez, Sanja Fidler, Chen Feng, Anima Anandkumar*
CVPR'2023 [[Paper](https://arxiv.org/abs/2302.12251)] [[Code](https://github.com/NVlabs/VoxFormer)]
* **Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?**
*Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jianjian Sun, Zheng Ge, Li Yi, Kaisheng Ma*
ICLR'2023 [[Paper](https://arxiv.org/abs/2212.08320)] [[Code](https://github.com/tsinghua-mars-lab/geomae)]
* **Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining**
*Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, Li Yi*
ICML'2023 [[Paper](https://arxiv.org/abs/2302.02318)] [[Code](https://github.com/qizekun/ReCon)]
* **MGM: A meshfree geometric multilevel method for systems arising from elliptic equations on point cloud surfaces**
*Grady B. Wright, Andrew M. Jones, Varun Shankar*
ICCV'2023 [[Paper](https://arxiv.org/abs/2204.06154)]
* **PointGPT: Auto-regressively Generative Pre-training from Point Clouds**
*Guangyan Chen, Meiling Wang, Yi Yang, Kai Yu, Li Yuan, Yufeng Yue*
NeurIPS'2023 [[Paper](https://arxiv.org/abs/2305.11487)] [[Code](https://github.com/CGuangyan-BIT/PointGPT)]
* **MATE: Masked Autoencoders are Online 3D Test-Time Learners**
*M. Jehanzeb Mirza, Inkyu Shin, Wei Lin, Andreas Schriebl, Kunyang Sun, Jaesung Choe, Horst Possegger, Mateusz Kozinski, In So Kweon, Kun-Jin Yoon, Horst Bischof*
ICCV'2023 [[Paper](https://arxiv.org/abs/2211.11432)] [[Code](https://github.com/jmiemirza/MATE)]
* **Masked Spatio-Temporal Structure Prediction for Self-supervised Learning on Point Cloud Videos**
*Zhiqiang Shen, Xiaoxiao Sheng, Hehe Fan, Longguang Wang, Yulan Guo, Qiong Liu, Hao Wen, Xi Zhou*
ICCV'2023 [[Paper](https://arxiv.org/abs/2308.09245)] [[Code](https://github.com/JohnsonSign/MaST-Pre)]
MaST-Pre
* **UniPAD: A Universal Pre-training Paradigm for Autonomous Driving**
*Honghui Yang, Sha Zhang, Di Huang, Xiaoyang Wu, Haoyi Zhu, Tong He, Shixiang Tang, Hengshuang Zhao, Qibo Qiu, Binbin Lin, Xiaofei He, Wanli Ouyang*
ICCV'2023 [[Paper](https://arxiv.org/abs/2310.08370)] [[Code](https://github.com/Nightmare-n/UniPAD)]
UniPAD

* **PonderV2: Pave the Way for 3D Foundataion Model with A Universal Pre-training Paradigm**
*Haoyi Zhu, Honghui Yang, Xiaoyang Wu, Di Huang, Sha Zhang, Xianglong He, Tong He, Hengshuang Zhao, Chunhua Shen, Yu Qiao, Wanli Ouyang*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2310.08586)]
[[Code](https://github.com/Pointcept/Pointcept)]
* **NeRF-MAE : Masked AutoEncoders for Self Supervised 3D representation Learning for Neural Radiance Fields**
*Muhammad Zubair Irshad, Sergey Zakahrov, Vitor Guizilini, Adrien Gaidon, Zsolt Kira, Rares Ambrus*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2404.01300)]
[[Code](https://github.com/zubair-irshad/NeRF-MAE)]
* **General Point Model with Autoencoding and Autoregressive**
*Zhe Li, Zhangyang Gao, Cheng Tan, Bocheng Ren, Laurence Tianruo Yang, Stan Z. Li*
CVPR'2024 [[Paper](https://arxiv.org/abs/2310.16861)]
[[Code](https://github.com/gentlefress/GPM)]
### Low-level Vision
* **DegAE: A New Pretraining Paradigm for Low-level Vision**
*Yihao Liu, Jingwen He, Jinjin Gu, Xiangtao Kong, Yu Qiao, Chao Dong*
CVPR'2023 [[Paper](https://openaccess.thecvf.com/content/CVPR2023/html/Liu_DegAE_A_New_Pretraining_Paradigm_for_Low-Level_Vision_CVPR_2023_paper.html)]
[[Code](https://github.com/lyh-18/DegAE_DegradationAutoencoder/)]
* **LM4LV: A Frozen Large Language Model for Low-level Vision Tasks**
*Boyang Zheng, Jinjin Gu, Shijun Li, Chao Dong*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2405.15734)]
[[Code](https://github.com/bytetriper/LM4LV)]
### Depth Estimation
* **MeSa: Masked, Geometric, and Supervised Pre-training for Monocular Depth Estimation**
*Muhammad Osama Khan, Junbang Liang, Chun-Kai Wang, Shan Yang, Yu Lou*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2310.04551)]
UniPAD

## Audio and Speech
* **wav2vec: Unsupervised Pre-training for Speech Recognition**
*Steffen Schneider, Alexei Baevski, Ronan Collobert, Michael Auli*
ArXiv'2019 [[Paper](https://arxiv.org/abs/1904.05862)] [[Code](https://github.com/pytorch/fairseq)]
* **vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations**
*Alexei Baevski, Steffen Schneider, Michael Auli*
ArXiv'2019 [[Paper](https://arxiv.org/abs/1910.05453)] [[Code](https://github.com/pytorch/fairseq)]
* **wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations**
*Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli*
NeurIPS'2020 [[Paper](https://arxiv.org/abs/2006.11477)] [[Code](https://github.com/pytorch/fairseq)]
* **HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units**
*Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed*
TASLP'2021 [[Paper](https://arxiv.org/abs/2106.07447)] [[Code](https://github.com/pytorch/fairseq)]
* **MAM: Masked Acoustic Modeling for End-to-End Speech-to-Text Translation**
*Junkun Chen, Mingbo Ma, Renjie Zheng, Liang Huang*
ArXiv'2021 [[Paper](https://arxiv.org/abs/2010.11445)]
* **MAE-AST: Masked Autoencoding Audio Spectrogram Transformer**
*Alan Baade, Puyuan Peng, David Harwath*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2203.16691)] [[Code](https://github.com/AlanBaade/MAE-AST-Public)]
* **Masked Spectrogram Prediction For Self-Supervised Audio Pre-Training**
*Dading Chong, Helin Wang, Peilin Zhou, Qingcheng Zeng*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2204.12768)] [[Code](https://github.com/wanghelin1997/maskspec)]
* **Masked Autoencoders that Listen**
*Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, Christoph Feichtenhofer*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2207.06405)] [[Code](https://github.com/facebookresearch/audiomae)]
* **Contrastive Audio-Visual Masked Autoencoder**
*Yuan Gong, Andrew Rouditchenko, Alexander H. Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, James Glass*
ICLR'2023 [[Paper](https://arxiv.org/abs/2210.07839)]
* **Audiovisual Masked Autoencoders**
*Mariana-Iuliana Georgescu, Eduardo Fonseca, Radu Tudor Ionescu, Mario Lucic, Cordelia Schmid, Anurag Arnab*
ICCV'2023 [[Paper](https://arxiv.org/abs/2210.07839)]
Framework

* **Masked Autoencoders with Multi-Window Local-Global Attention Are Better Audio Learners**
*Sarthak Yadav, Sergios Theodoridis, Lars Kai Hansen, Zheng-Hua Tan*
ICLR'2024 [[Paper](https://arxiv.org/abs/2306.00561)]
* **Masked Audio Generation using a Single Non-Autoregressive Transformer**
*Alon Ziv, Itai Gat, Gael Le Lan, Tal Remez, Felix Kreuk, Jade Copet, Alexandre Défossez, Gabriel Synnaeve, Yossi Adi*
ICLR'2024 [[Paper](https://openreview.net/forum?id=Ny8NiVfi95)]
[[Code](https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT/)]
## AI for Science
### Protein
* **Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences**
*Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, Rob Fergus*
PNAS'2020 [[Paper](https://www.pnas.org/doi/pdf/10.1073/pnas.2016239118)]
[[Code](https://github.com/facebookresearch/esm)]
* **Transformer protein language models are unsupervised structure learners**
*Roshan Rao, Joshua Meier, Tom Sercu, Sergey Ovchinnikov, Alexander Rives*
bioRxiv'2020 [[Paper](https://www.biorxiv.org/content/10.1101/2020.12.15.422761)]
[[Code](https://github.com/facebookresearch/esm)]
* **Language models enable zero-shot prediction of the effects of mutations on protein function**
*Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu, Alexander Rives*
bioRxiv'2021 [[Paper](https://www.biorxiv.org/content/10.1101/2022.04.10.487779)]
[[Code](https://github.com/facebookresearch/esm)]
* **Learning inverse folding from millions of predicted structures**
*Chloe Hsu, Robert Verkuil, Jason Liu, Zeming Lin, Brian Hie, Tom Sercu, Adam Lerer, Alexander Rives*
ICML'2022 [[Paper](https://www.biorxiv.org/content/10.1101/2022.04.10.487779)]
[[Code](https://github.com/facebookresearch/esm)]
* **Evolutionary-scale prediction of atomic level protein structure with a language model**
*Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Salvatore Candido, Alexander Rives*
bioRxiv'2022 [[Paper](https://www.biorxiv.org/content/10.1101/2022.07.20.500902v3)]
[[Code](https://github.com/facebookresearch/esm)]
* **ProteinBERT: A universal deep-learning model of protein sequence and function**
*Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Salvatore Candido, Alexander Rives*
Bioinformatics'2022 [[Paper](https://academic.oup.com/bioinformatics/article/38/8/2102/6502274)]
[[Code](https://github.com/nadavbra/protein_bert)]
* **Foldseek: fast and accurate protein structure search**
*Michel van Kempen, Stephanie S. Kim, Charlotte Tumescheit, Milot Mirdita, Johannes Söding, Martin Steinegger*
Nature'2023 [[Paper](https://www.biorxiv.org/content/10.1101/2022.02.07.479398v2)]
[[Code](https://github.com/steineggerlab/foldseek)]
* **SaProt: Protein Language Modeling with Structure-aware Vocabulary**
*Jin Su, Chenchen Han, Yuyang Zhou, Junjie Shan, Xibin Zhou, Fajie Yuan*
ICLR'2024 [[Paper](https://www.biorxiv.org/content/10.1101/2023.10.01.560349v2)]
[[Code](https://github.com/westlake-repl/SaProt)]
* **MAPE-PPI: Towards Effective and Efficient Protein-Protein Interaction Prediction via Microenvironment-Aware Protein Embedding**
*Lirong Wu, Yijun Tian, Yufei Huang, Siyuan Li, Haitao Lin, Nitesh V Chawla, Stan Z. Li*
ICLR'2024 [[Paper](https://arxiv.org/abs/2402.14391)]
[[Code](https://github.com/lirongwu/mape-ppi)]
* **VQDNA: Unleashing the Power of Vector Quantization for Multi-Species Genomic Sequence Modeling**
*Siyuan Li, Zedong Wang, Zicheng Liu, Di Wu, Cheng Tan, Jiangbin Zheng, Yufei Huang, Stan Z. Li*
ICML'2024 [[Paper](https://arxiv.org/abs/2405.10812)]
* **Learning to Predict Mutation Effects of Protein-Protein Interactions by Microenvironment-aware Hierarchical Prompt Learning**
*Lirong Wu, Yijun Tian, Haitao Lin, Yufei Huang, Siyuan Li, Nitesh V Chawla, Stan Z. Li*
ICML'2024 [[Paper](https://arxiv.org/abs/2405.10348)]
[[Code](https://github.com/lirongwu/prompt-ddg)]
### Chemistry
* **Mole-BERT: Rethinking Pre-training Graph Neural Networks for Molecules**
*Jun Xia, Chengshuai Zhao, Bozhen Hu, Zhangyang Gao, Cheng Tan, Yue Liu, Siyuan Li, Stan Z. Li*
ICLR'2023 [[Paper](https://openreview.net/forum?id=jevY-DtiZTR)]
[[Code](https://github.com/junxia97/Mole-BERT)]
* **VQMAE: Surface-VQMAE: Vector-quantized Masked Auto-encoders on Molecular Surfaces**
*Fang Wu, Stan Z. Li*
ICML'2024 [[Paper](https://github.com/smiles724/VQMAE)]
### Physics
* **W-MAE: Pre-trained weather model with masked autoencoder for multi-variable weather forecasting**
*Xin Man, Chenghong Zhang, Jin Feng, Changyu Li, Jie Shao*
arXiv'2023 [[Paper](https://arxiv.org/abs/2304.08754)]
[[Code](https://github.com/gufrannn/w-mae)]
* **Masked Autoencoders are PDE Learners**
*Anthony Zhou, Amir Barati Farimani*
arXiv'2024 [[Paper](https://arxiv.org/abs/2403.17728)]
## Time Series and Neuroscience Learning
* **Neuro-BERT: Rethinking Masked Autoencoding for Self-Supervised Neurological Pretraining**
*Di Wu, Siyuan Li, Jie Yang, Mohamad Sawan*
JBHI'2024 [[Paper](https://doi.org/10.1109/JBHI.2024.3415959)]
[[Code](https://github.com/Westlake-AI/OpenBioSeq)]
Neuro-BERT (neuro2vec)

* **Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI**
*Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu*
ICLR'2024 [[Paper](https://openreview.net/forum?id=QzTpTRVtrP)]
LaBraM

* **Neuroformer: Multimodal and Multitask Generative Pretraining for Brain Data**
*Antonis Antoniades, Yiyi Yu, Joseph Canzano, William Wang, Spencer LaVere Smith*
ICLR'2024 [[Paper](https://arxiv.org/abs/2311.00136)]
[[Code](https://github.com/woanderer/Neuroformer)]
Neuroformer
* **VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters**
*Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, Chenghao Liu*
ArXiv'2024 [[Paper](https://arxiv.org/abs/2408.17253)]
[[Code](https://github.com/keytoyze/visionts)]
## Reinforcement Learning
* **Mask-based Latent Reconstruction for Reinforcement Learning**
*Tao Yu, Zhizheng Zhang, Cuiling Lan, Yan Lu, Zhibo Chen*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2201.12096)]
* **Masked Contrastive Representation Learning for Reinforcement Learning**
*Jinhua Zhu, Yingce Xia, Lijun Wu, Jiajun Deng, Wengang Zhou, Tao Qin, Tie-Yan Liu, Houqiang Li*
TPAMI'2023 [[Paper](https://ieeexplore.ieee.org/document/9779589)]
[[Code](https://github.com/teslacool/m-curl)]
* **SMART: Self-supervised Multi-task pretrAining with contRol Transformers**
*Yanchao Sun, Shuang Ma, Ratnesh Madaan, Rogerio Bonatti, Furong Huang, Ashish Kapoor*
ICLR'2023 [[Paper](https://arxiv.org/abs/2301.09816)]
## Tabular Data
* **ReMasker: Imputing Tabular Data with Masked Autoencoding**
*Tianyu Du, Luca Melis, Ting Wang*
ICLR'2024 [[Paper](https://openreview.net/forum?id=KI9NqjLVDT)]
* **MCM: Masked Cell Modeling for Anomaly Detection in Tabular Data**
*Jiaxin Yin, Yuanyuan Qiao, Zitang Zhou, Xiangchao Wang, Jie Yang*
ICLR'2024 [[Paper](https://openreview.net/forum?id=lNZJyEDxy4)]
## Analysis and Understanding of Masked Modeling
* **Demystifying Self-Supervised Learning: An Information-Theoretical Framework**
*Yao-Hung Hubert Tsai, Yue Wu, Ruslan Salakhutdinov, Louis-Philippe Morency*
ICLR'2021 [[Paper](https://arxiv.org/abs/2006.05576)]
* **A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks**
*Nikunj Saunshi, Sadhika Malladi, Sanjeev Arora*
ICLR'2021 [[Paper](https://arxiv.org/abs/2010.03648)]
* **Predicting What You Already Know Helps: Provable Self-Supervised Learning**
*Jason D. Lee, Qi Lei, Nikunj Saunshi, Jiacheng Zhuo*
NeurIPS'2021 [[Paper](https://arxiv.org/abs/2008.01064)]
* **How to Understand Masked Autoencoders**
*Shuhao Cao, Peng Xu, David A. Clifton*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2202.03670)]
* **Masked prediction tasks: a parameter identifiability view**
*Bingbin Liu, Daniel Hsu, Pradeep Ravikumar, Andrej Risteski*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2202.09305)]
* **Revealing the Dark Secrets of Masked Image Modeling**
*Zhenda Xie, Zigang Geng, Jingcheng Hu, Zheng Zhang, Han Hu, Yue Cao*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.13543)]
* **Architecture-Agnostic Masked Image Modeling - From ViT back to CNN**
*Siyuan Li, Di Wu, Fang Wu, Zelin Zang, Kai Wang, Lei Shang, Baigui Sun, Hao Li, Stan.Z.Li*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.13943)]
* **On Data Scaling in Masked Image Modeling**
*Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Yixuan Wei, Qi Dai, Han Hu*
CVPR'2023 [[Paper](https://arxiv.org/abs/2206.04664)]
* **Towards Understanding Why Mask-Reconstruction Pretraining Helps in Downstream Tasks**
*Jiachun Pan, Pan Zhou, Shuicheng Yan*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2206.03826)]
* **An Empirical Study Of Self-supervised Learning Approaches For Object Detection With Transformers**
*Gokul Karthik Kumar, Sahal Shaji Mullappilly, Abhishek Singh Gehlot*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2205.05543)] [[Code](https://github.com/gokulkarthik/deformable-detr)]
* **Understanding Masked Image Modeling via Learning Occlusion Invariant Feature**
*Xiangwen Kong, Xiangyu Zhang*
ArXiv'2022 [[Paper](http://arxiv.org/abs/2208.04164)] [[Code](https://github.com/zhangq327/u-mae)]
* **How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders**
*Qi Zhang, Yifei Wang, Yisen Wang*
NeurIPS'2022 [[Paper](https://arxiv.org/abs/2210.08344)] [[Code](https://github.com/zhangq327/U-MAE)]
* **i-MAE: Are Latent Representations in Masked Autoencoders Linearly Separable**
*Kevin Zhang, Zhiqiang Shen*
ArXiv'2022 [[Paper](https://arxiv.org/abs/2210.11470)]
* **Understanding Masked Autoencoders via Hierarchical Latent Variable Models**
*Lingjing Kong, Martin Q. Ma, Guangyi Chen, Eric P. Xing, Yuejie Chi, Louis-Philippe Morency, Kun Zhang*
CVPR'2023 [[Paper](https://arxiv.org/abs/2306.04898)] [[Code](https://github.com/martinmamql/mae_understand)]
* **Evaluating Self-Supervised Learning via Risk Decomposition**
*Yann Dubois, Tatsunori Hashimoto, Percy Liang*
ICML'2023 [[Paper](https://arxiv.org/abs/2302.03068)] [[Code](https://github.com/yanndubs/ssl-risk-decomposition)]
* **Regeneration Learning: A Learning Paradigm for Data Generation**
*Xu Tan, Tao Qin, Jiang Bian, Tie-Yan Liu, Yoshua Bengio*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2301.08846)]
## Survey
* **A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond**
*Chaoning Zhang, Chenshuang Zhang, Junha Song, John Seon Keun Yi, Kang Zhang, In So Kweon*
IJCAI'2023 [[Paper](https://arxiv.org/abs/2208.00173)]
* **Masked Autoencoders in Computer Vision: A Comprehensive Survey**
*Zexian Zhou, Xiaojing Liu*
IEEE Access'2023 [[Paper](https://ieeexplore.ieee.org/document/10278410)]
* **Masked Modeling for Self-supervised Representation Learning on Vision and Beyond**
*Siyuan Li, Luyuan Zhang, Zedong Wang, Di Wu, Lirong Wu, Zicheng Liu, Jun Xia, Cheng Tan, Yang Liu, Baigui Sun, Stan Z. Li*
ArXiv'2023 [[Paper](https://arxiv.org/abs/2401.00897)] [[Code](https://github.com/Lupin1998/Awesome-MIM)]
## Contribution
Feel free to send [pull requests](https://github.com/Lupin1998/Awesome-MIM/pulls) to add more links with the following Markdown format. Note that the abbreviation, the code link, and the figure link are optional attributes.
```markdown
* **TITLE**
*AUTHER*
PUBLISH'YEAR [[Paper](link)] [[Code](link)]
ABBREVIATION Framework

```
The main maintainer is Siyuan Li ([@Lupin1998](https://github.com/Lupin1998)). We thank all contributors for `Awesome-MIM`, and current contributors include:

## Citation
If you find this repository and our survey helpful, please consider citing our paper:
```
@article{Li2023MIMSurvey,
title={Masked Modeling for Self-supervised Representation Learning on Vision and Beyond},
author={Siyuan Li and Luyuan Zhang and Zedong Wang and Di Wu and Lirong Wu and Zicheng Liu and Jun Xia and Cheng Tan and Yang Liu and Baigui Sun and Stan Z. Li},
journal={ArXiv},
year={2023},
volume={abs/2401.00897},
}
```
## Related Project
### Paper List of Masked Image Modeling
- [Awesome-Masked-Autoencoders](https://github.com/EdisonLeeeee/Awesome-Masked-Autoencoders): A collection of literature after or concurrent with Masked Autoencoder (MAE).
- [awesome-MIM](https://github.com/ucasligang/awesome-MIM): Reading list for research topics in Masked Image Modeling.
- [Awesome-MIM](https://github.com/Westlake-AI/openmixup/blob/main/docs/en/awesome_selfsup/MIM.md): Awesome list of masked image modeling methods for self-supervised visual representation.
- [awesome-self-supervised-learning](https://github.com/jason718/awesome-self-supervised-learning): A curated list of awesome self-supervised methods.
### Project of Self-supervised Learning
- [unilm](https://github.com/microsoft/unilm): Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities.
- [OpenMixup](https://github.com/Westlake-AI/openmixup): CAIRI Supervised, Semi- and Self-Supervised Visual Representation Learning Toolbox and Benchmark.
- [MMPretrain](https://github.com/open-mmlab/mmpretrain): OpenMMLab self-supervised pre-training toolbox and benchmark.
- [solo-learn](https://github.com/vturrisi/solo-learn): A library of self-supervised methods for visual representation learning powered by Pytorch Lightning.
- [VISSL](https://github.com/facebookresearch/vissl): FAIR's library of extensible, modular and scalable components for SOTA Self-Supervised Learning with images.
- [lightly](https://github.com/lightly-ai/lightly): A python library for self-supervised learning on images.
- [Fairseq](https://github.com/facebookresearch/fairseq): Facebook AI Research Sequence-to-Sequence Toolkit written in Python.