https://github.com/Skylark0924/Awesome-Target-driven-Navigation
Paper and summaries about state-of-the-art robot Target-driven Navigation task
https://github.com/Skylark0924/Awesome-Target-driven-Navigation
List: Awesome-Target-driven-Navigation
cvpr navigation paper robotics visual-representations
Last synced: 6 months ago
JSON representation
Paper and summaries about state-of-the-art robot Target-driven Navigation task
- Host: GitHub
- URL: https://github.com/Skylark0924/Awesome-Target-driven-Navigation
- Owner: Skylark0924
- License: mit
- Created: 2020-12-15T13:40:42.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2022-03-17T08:35:48.000Z (over 3 years ago)
- Last Synced: 2024-05-19T15:00:43.624Z (about 1 year ago)
- Topics: cvpr, navigation, paper, robotics, visual-representations
- Homepage:
- Size: 287 KB
- Stars: 42
- Watchers: 3
- Forks: 5
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ultimate-awesome - Awesome-Target-driven-Navigation - Paper and summaries about state-of-the-art robot Target-driven Navigation task. (Other Lists / Julia Lists)
README
#! https://zhuanlan.zhihu.com/p/338404758
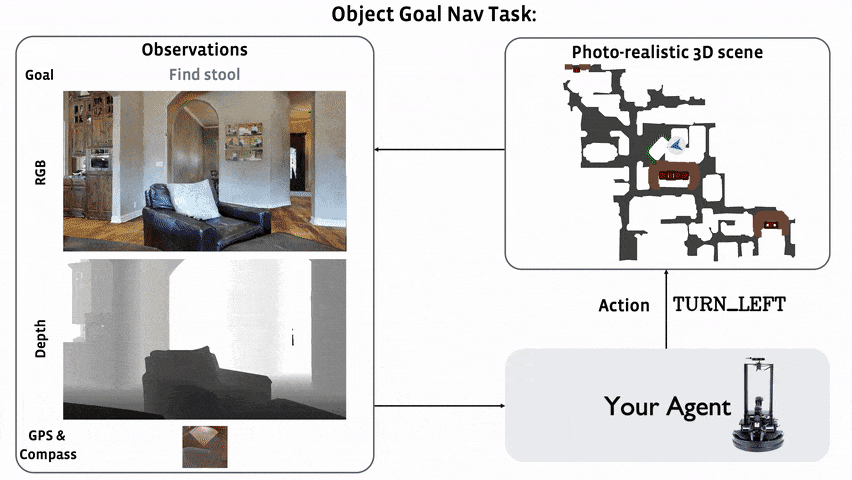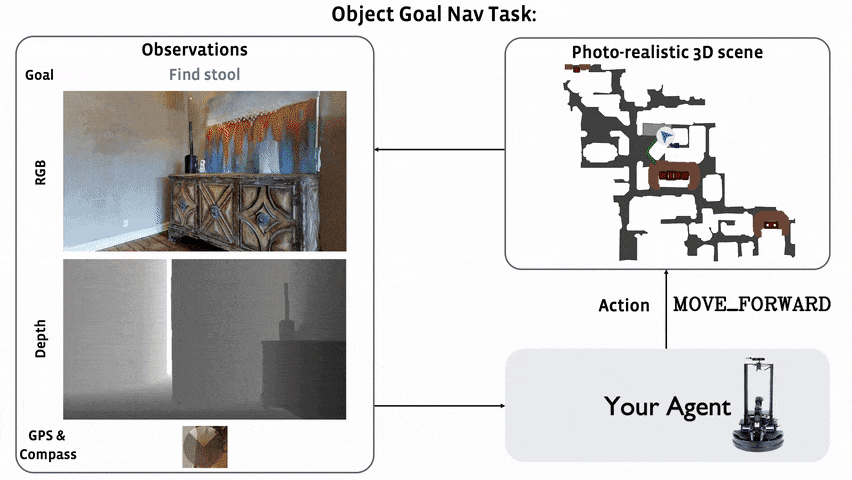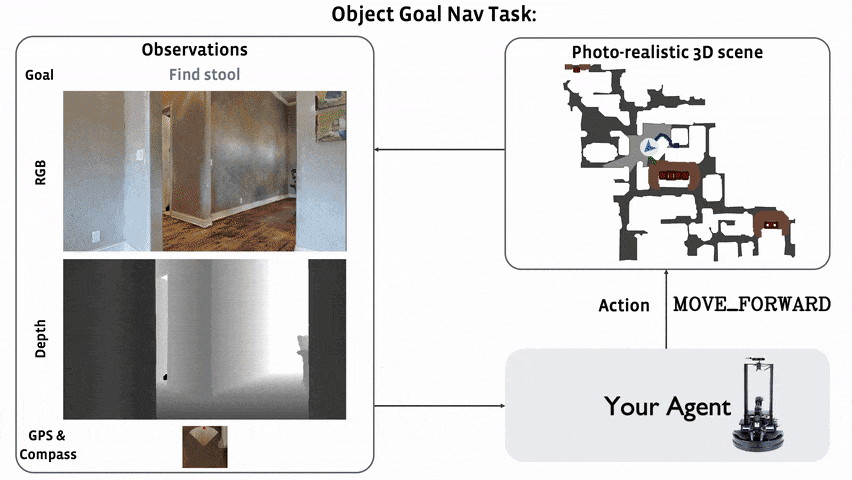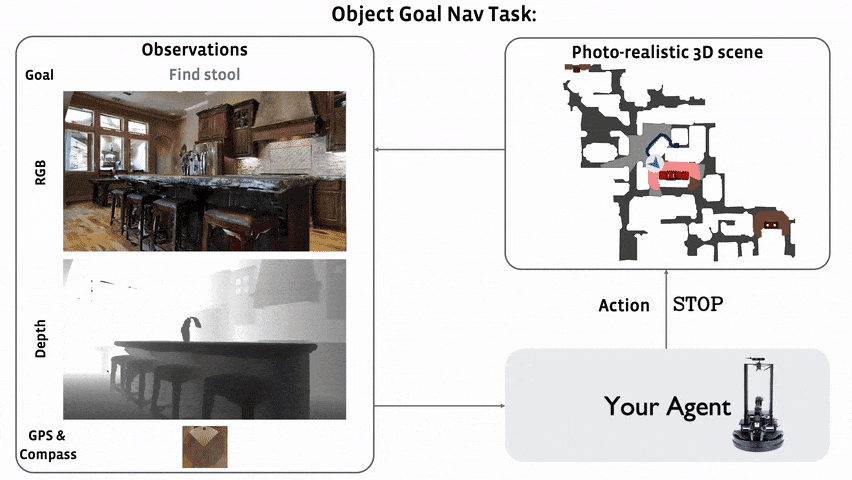
# Awesome Target-driven Navigation 资源汇总
| Alias | Target | Sensor | SLAM | Framework | Dataset | SR | SPL | Note |
| :-------------------: | :-----: | :--: | :----------------------------------------------------------: | :-------: | :-------: | :-------: | :----: | :--: |
| [t-SNE](#t-SNE) | Image | RGB | No | ResNet + A3C | AI2THOR | - | - | |
| [SPTM](#SPTM) | Image | RGB | No | DL + Graph | game Doom | 1 | - | |
| [NTS](#NTS) | panoramic image | RGB/RGB | Yes | Graph Construction + Global Policy +
Local Policy | Gibson | 0.55/0.63 | 0.38/0.43 | |
| [PTVN](#PTVN) | panoramic image | RGBD | No | autoencoder + policy model +
goal checking | MP3D | 0.8125 | 0.6614 | |
| | | | | | | | | |
| [CMP](#CMP) | Label | RGB/D | Yes | Encoder-decoder+value iteration | S3DIS + MP3D | 0.638 | 0.228 | |
| [Scene Priors](#Scene_Priors) | Label | RGB | No | GCN+LSTM+A3C | AI2THOR | 0.649 | 0.304 | |
| [VR](#VR) | Label | RGBD | No | CNN+LSTM | Active Vision Dataset (AVD) | 0.54 | - | |
| [SAVN](#SAVN) | Label | RGB | No | ResNet18+GloVe+
LSTM+MAML | AI2THOR | 0.287 | 0.139 | |
| [BRM](#BRM) | Label (Room) | RGBD | No | CNN+Graph+LSTM | House3D | 0.231 | 0.045 | |
| [SF](#SF) | Label | RGBD | No | Situational Fusion | MP3D | 0.44 | - | |
| [ORG](#ORG) | Label | RGB | No | GCN+LSTM+IL+TPN | AI2THOR | 0.607 | 0.385 | |
| [MJOLNIR](#MJOLNIR) | Label | RGB | No | GCN+LSTM+A3C | AI2THOR | 0.50 | 0.209 | |
| [Attention 3D](#Attention_3D) | Image | RGB | No | LSTM A3C+KG+Attention | AI2THOR | 0.419 | 0.072 | |
| [YouTube](#YouTube) | Label | RGB | No | Double DQN | YouTube House Tours Dataset | 0.79 | 0.53 | |
| [SemExp](#SemExp) | Label | RGBD | No | Mask RCNN+Voxel Representation+RL | MP3D | 0.360 | 0.144 |
$^\dagger$ For methods designed for single room navigation, I use the result about a subset of targets whose optimal trajectory length is greater than 5 ($L\ge 5$).
## ImageGoal Navigation
1. **Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning (t-SNE)**
*Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J. Lim, Abhinav Gupta, Li Fei-Fei, Ali Farhadi*
ICRA, 2017. [[Paper\]](https://arxiv.org/abs/1609.05143) [[Website\]](https://prior.allenai.org/projects/target-driven-visual-navigation)
2. **Semi-Parametric Topological Memory for Navigation (SPTM)**
*Nikolay Savinov\*, Alexey Dosovitskiy\*, Vladlen Koltun*
ICLR, 2018. [[Paper\]](https://arxiv.org/pdf/1803.00653.pdf) [[Code\]](https://github.com/nsavinov/SPTM) [[Website\]](https://sites.google.com/view/SPTM)
3. **Neural Topological SLAM for Visual Navigation (NTS)**
*Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, Saurabh Gupta*
CVPR, 2020. [[Paper\]](https://arxiv.org/pdf/2005.12256.pdf) [[Website\]](https://devendrachaplot.github.io/projects/Neural-Topological-SLAM)
4. **Learning Your Way Without Map or Compass: Panoramic Target Driven Visual Navigation (PTVN)**
*David Watkins-Valls, Jingxi Xu, Nicholas Waytowich, Peter Allen*
\[[Paper](https://arxiv.org/pdf/1909.09295.pdf)\]
## LabelGoal Navigation
1. **Cognitive Mapping and Planning for Visual Navigation (CMP)**
*Saurabh Gupta, Varun Tolani, James Davidson, Sergey Levine, Rahul Sukthankar, Jitendra Malik*
CVPR, 2017. [[Paper\]](https://arxiv.org/abs/1702.03920)
Summary
Two key ideas:
- a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task;
- a spatial memory with the ability to plan given an incomplete set of observations about the world.
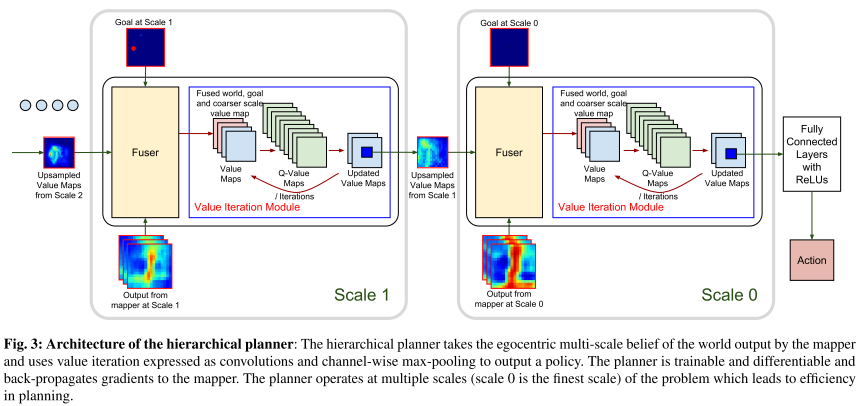
CMP constructs a **top-down belief map** of the world and applies a **differentiable neural net planner** to produce the next action at each time step.
**Network architecture**
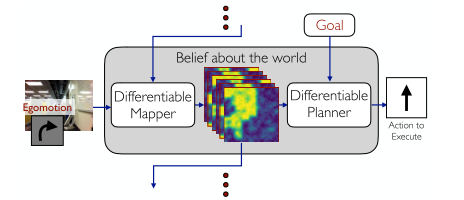
**Architecture of the mapper**
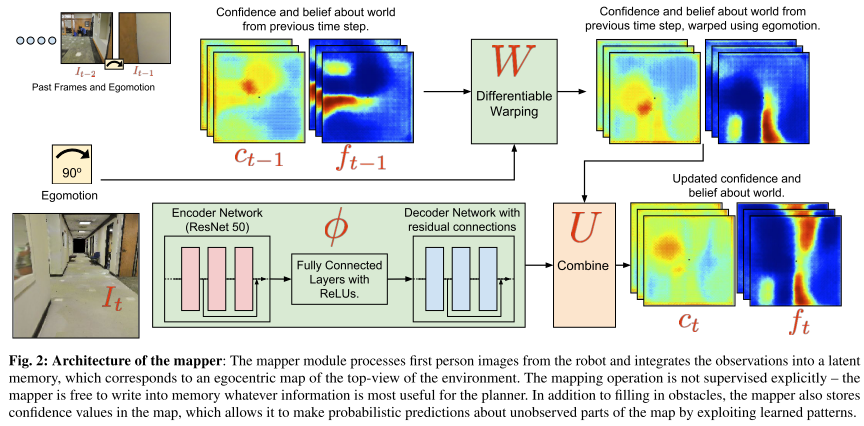
**Architecture of the hierarchical planner**
2. **Visual Semantic Navigation using Scene Priors (Scene Priors)**
*Wei Yang, Xiaolong Wang, Ali Farhadi, Abhinav Gupta, Roozbeh Mottaghi*
ICLR, 2019. [[Paper\]](https://arxiv.org/abs/1810.06543)
Summary
They address navigation to **novel objects** or navigating in **unseen scenes** using **scene priors**, like human does.
**Scene Priors**
**Architecture**
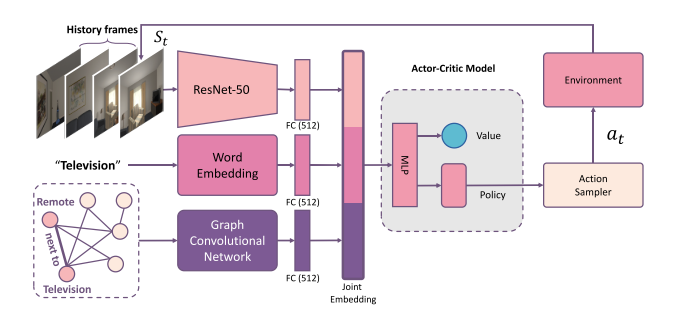
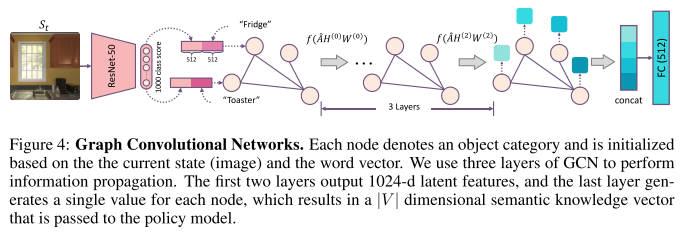
**GCN for relation graph embedding**
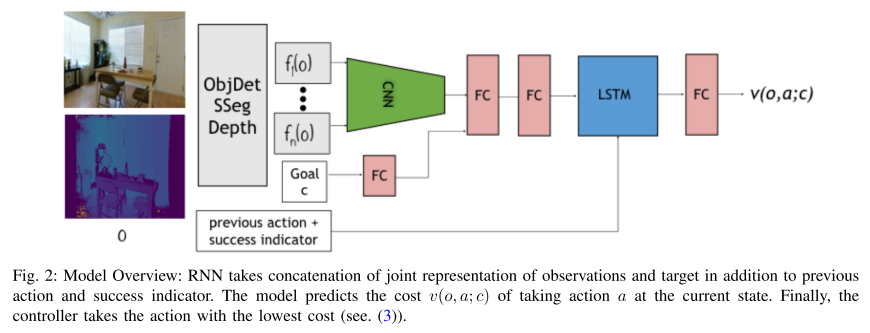
3. **Visual Representations for Semantic Target Driven Navigation (VR)**
*Arsalan Mousavian, Alexander Toshev, Marek Fiser, Jana Kosecka, Ayzaan Wahid, James Davidson*
ICRA, 2019. [[Paper\]](https://arxiv.org/pdf/1805.06066.pdf) [[Code\]](https://github.com/arsalan-mousavian/Navigation)
Summary
This paper focuses on finding a good **visual representation.**
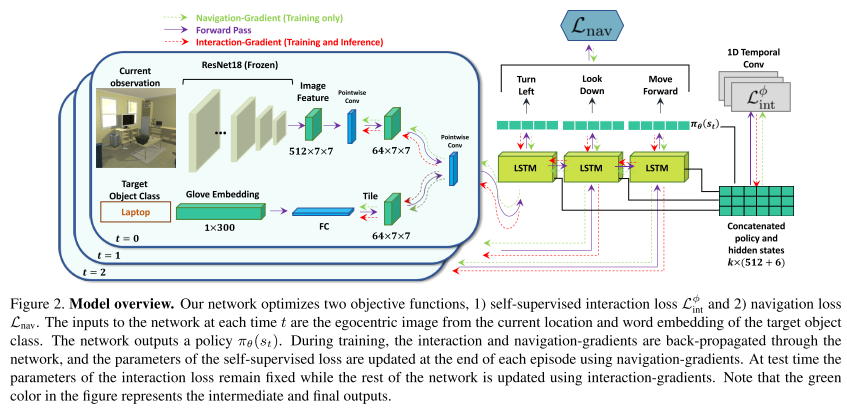
4. **Learning to Learn How to Learn: Self-Adaptive Visual Navigation using Meta-Learning (SAVN)**
*Mitchell Wortsman, Kiana Ehsani, Mohammad Rastegari, Ali Farhadi, Roozbeh Mottaghi*
CVPR, 2019. [[Paper\]](https://arxiv.org/abs/1812.00971) [[Code\]](https://github.com/allenai/savn) [[Website\]](https://prior.allenai.org/projects/savn)
Summary
This paper uses **Meta-reinforcement learning** to construct an interaction loss for self-adaptive visual navigation.
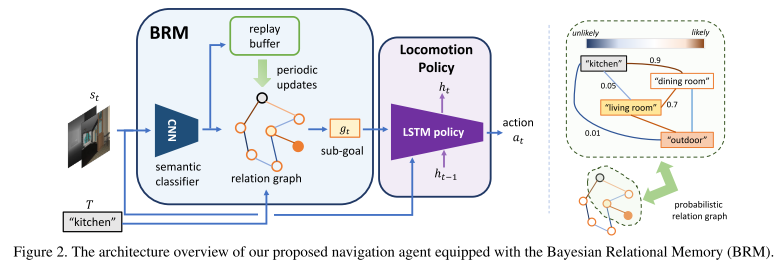
5. **Bayesian Relational Memory for Semantic Visual Navigation (BRM)**
*Yi Wu, Yuxin Wu, Aviv Tamar, Stuart Russell, Georgia Gkioxari, Yuandong Tian*
ICCV, 2019. [[Paper\]](https://arxiv.org/abs/1909.04306) [[Code\]](https://github.com/jxwuyi/HouseNavAgent)
Summary
Construct a probabilistic relation graph to learn the relationship or a topological memory of house layout.
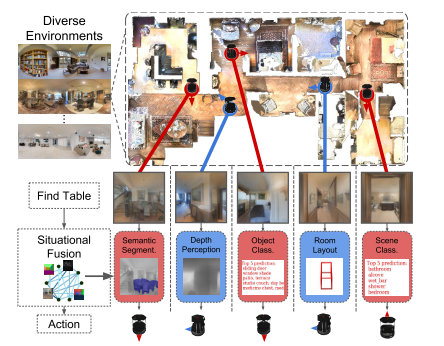
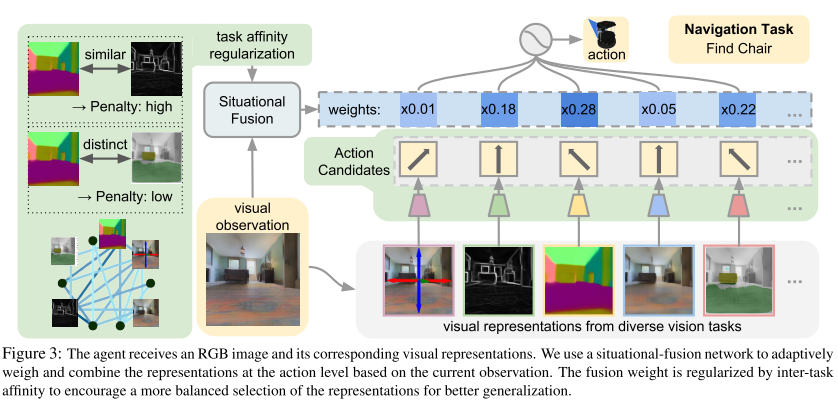
6. **Situational Fusion of Visual Representation for Visual Navigation (SF)**
*William B. Shen, Danfei Xu, Yuke Zhu, Leonidas J. Guibas, Li Fei-Fei, Silvio Savarese*
ICCV, 2019. [[Paper\]](https://arxiv.org/abs/1908.09073)
Summary
This paper aims at fusing multiple visual representations, such as Semantic Segment, Depth Perception, Object Class, Room Layout and Scene Class.
They develop an action-level representation fusion scheme, which predicts an action candidate from each representation and adaptively consolidate these action candidates into the final action.
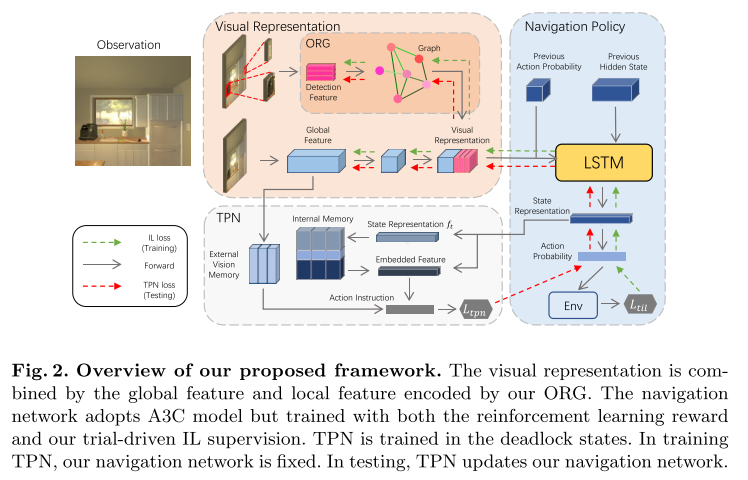
7. **Learning Object Relation Graph and Tentative Policy for Visual Navigation (ORG)**
*Heming Du, Xin Yu, Liang Zheng*
ECCV, 2020. [[Paper\]](https://arxiv.org/abs/2007.11018)
Summary
Aiming to learn informative visual representation and robust navigation policy, this paper proposes three complementary techniques, **object relation graph** (ORG), **trial-driven imitation learning** (IL), and a memory-augmented **tentative policy network** (TPN).
- ORG improves visual representation learning by integrating object relationships;
- Both Trial-driven IL and TPN underlie robust navigation policy, in- structing the agent to escape from deadlock states, such as looping or being stuck;
- IL is used in training, TPN for testing.
8. **Target driven visual navigation exploiting object relationships (MJOLNIR)**
*Yiding Qiu, Anwesan Pal, Henrik I. Christensen*
arxiv, 2020. [[Paper\]](http://arxiv.org/abs/2003.06749)
Summary
They present Memory-utilized Joint hierarchical Object Learning for Navigation in Indoor Rooms (MJOLNIR)1, a target-driven visual navigation algorithm, which considers the inherent relationship between target objects, along with the more salient parent objects occurring in its surrounding.
**MJOLNIR architecture**
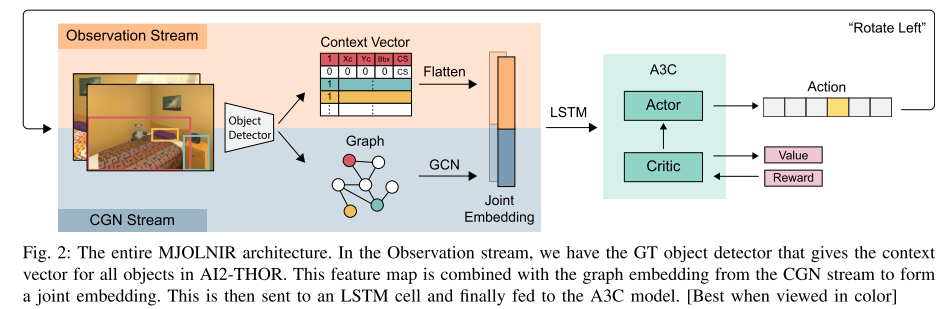
**The novel CGN architecture**
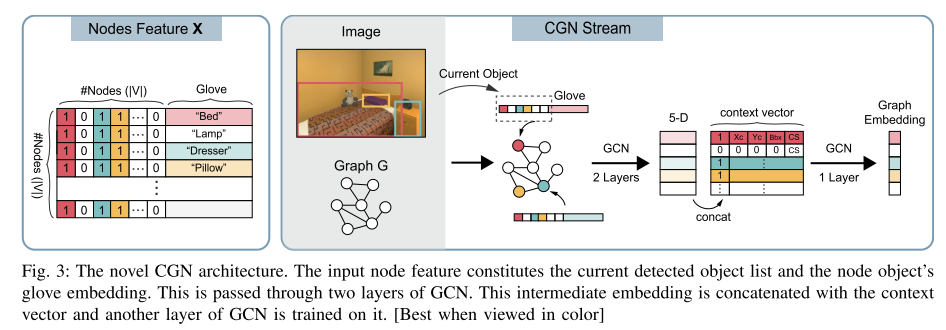
9. **Improving Target-driven Visual Navigation with Attention on 3D Spatial Relationships (Attention 3D)**
*Yunlian Lv, Ning Xie, Yimin Shi, Zijiao Wang, and Heng Tao Shen*
arxiv, 2020. [[Paper\]](http://arxiv.org/abs/2005.02153)
Summary
To address the **generalization and automatic obstacle avoidance** issues, we incorporate two designs into classic DRL framework: attention on 3D knowledge graph (KG) and target skill extension (TSE) module.
- visual features and 3D spatial representations to learn navigation policy;
- TSE module is used to generate sub-targets which allow agent to learn from failures.
**Framework**
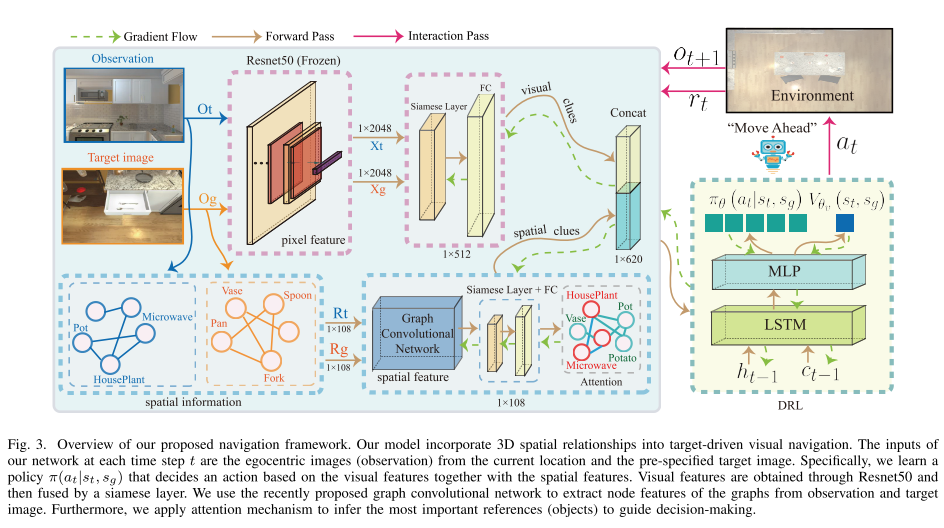
**3D spatial representations**
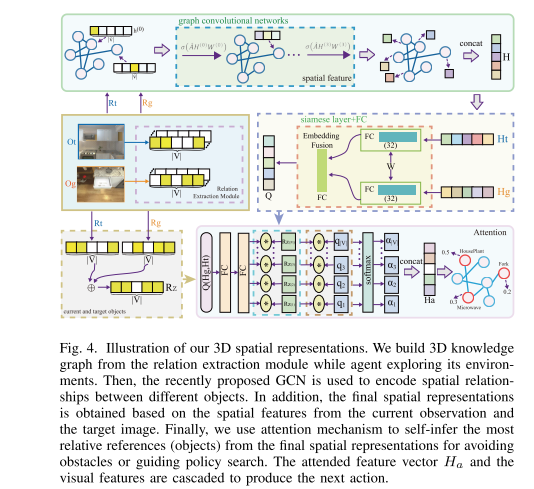
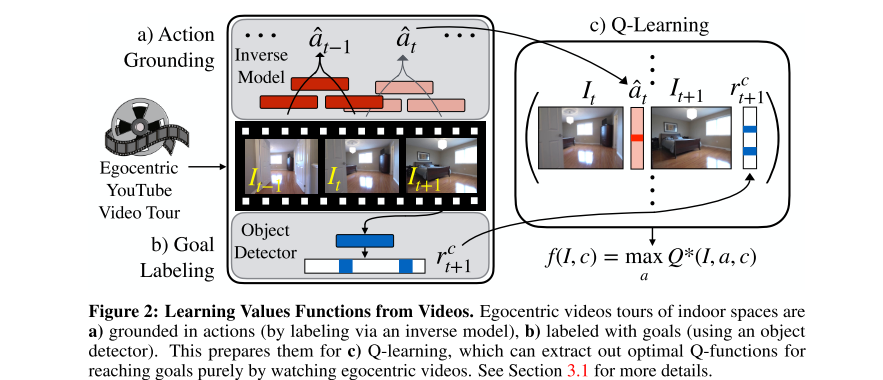
10. **Semantic Visual Navigation by Watching YouTube Videos (YouTube)**
*Matthew Chang, Arjun Gupta, Saurabh Gupta*
arXiv, 2020. [[Paper\]](https://arxiv.org/pdf/2006.10034.pdf) [[Website\]](https://matthewchang.github.io/value-learning-from-videos/)
Summary
This paper **learns and leverages such semantic cues** for navigating to objects of interest in novel environments, **by simply watching YouTube videos**. They believe that these priors can improve efficiency for navigation in novel environments.
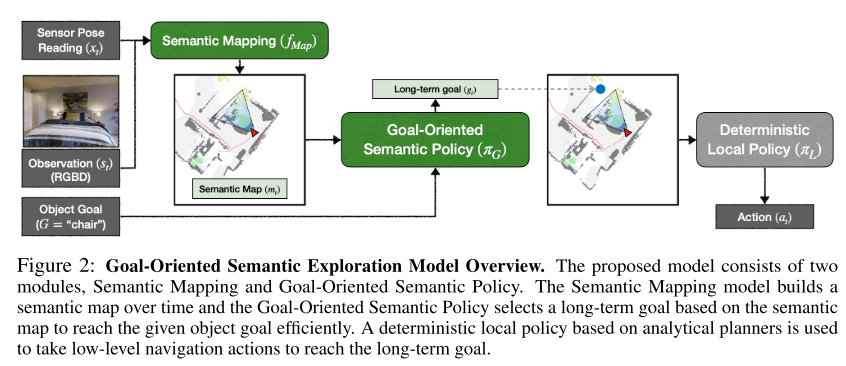
11. **Object Goal Navigation using Goal-Oriented Semantic Exploration (SemExp)**
*Devendra Singh Chaplot, Dhiraj Gandhi, Abhinav Gupta\*, Ruslan Salakhutdinov*
arXiv, 2020. [[Paper\]](https://arxiv.org/pdf/2007.00643.pdf) [[Website\]](https://devendrachaplot.github.io/projects/semantic-exploration)
**Win CVPR2020 Habitat ObjectNav Challenge**
Summary
They propose a modular system called, ‘**Goal- Oriented Semantic Exploration (SemExp)**’ which builds an episodic semantic map and uses it to explore the environment efficiently based on the goal object category.
- It builds top-down metric maps, which adds extra channels to encode semantic categories explicitly;
- Instead of using a coverage maximizing goal-agnostic exploration policy based only on obstacle maps, we train a goal-oriented semantic exploration policy which learns semantic priors for efficient navigation.
**Framework**
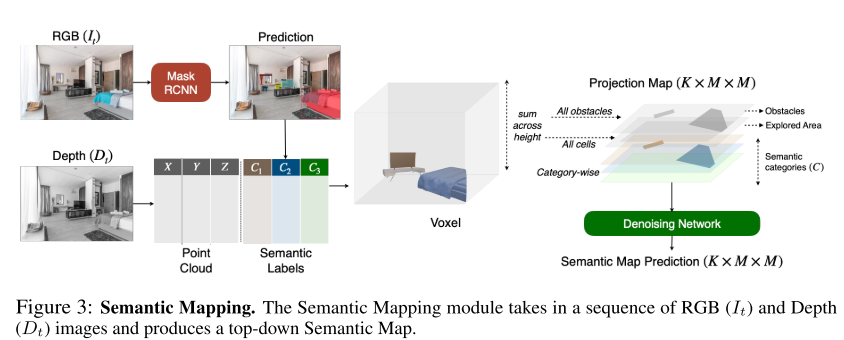
**Semantic Mapping**
12. **ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects**
*Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, Erik Wijmans*
arXiv, 2020. [[Paper\]](https://arxiv.org/abs/2006.13171)
Summary
**This paper is not a research paper.** They summarize the ObjectNav task and introduce popular datasets (Matterport3D, AI2-THOR) and Challenges (Habitat 2020 Challenge Habitat, RoboTHOR 2020 Challenge RoboTHOR).
---
知乎没法显示Summary部分的折叠和表格内部跳转,还不支持目录,格式真的太丑了,**再次请求支持完整版的 Markdown + HTML!!**
[@知乎小管家](https://www.zhihu.com/people/zhihuadmin)
欢迎移步 Github 观看正常版,**记得 Fork & Star 哦!**
[Awesome-Target-driven-Navigation/Skylark0924](https://github.com/Skylark0924/Awesome-Target-driven-Navigation)